
LLM驱动的Agent Chain of Thought、ReAct、Plan-and-Execute、Multi-Agent 等设计模式的区别
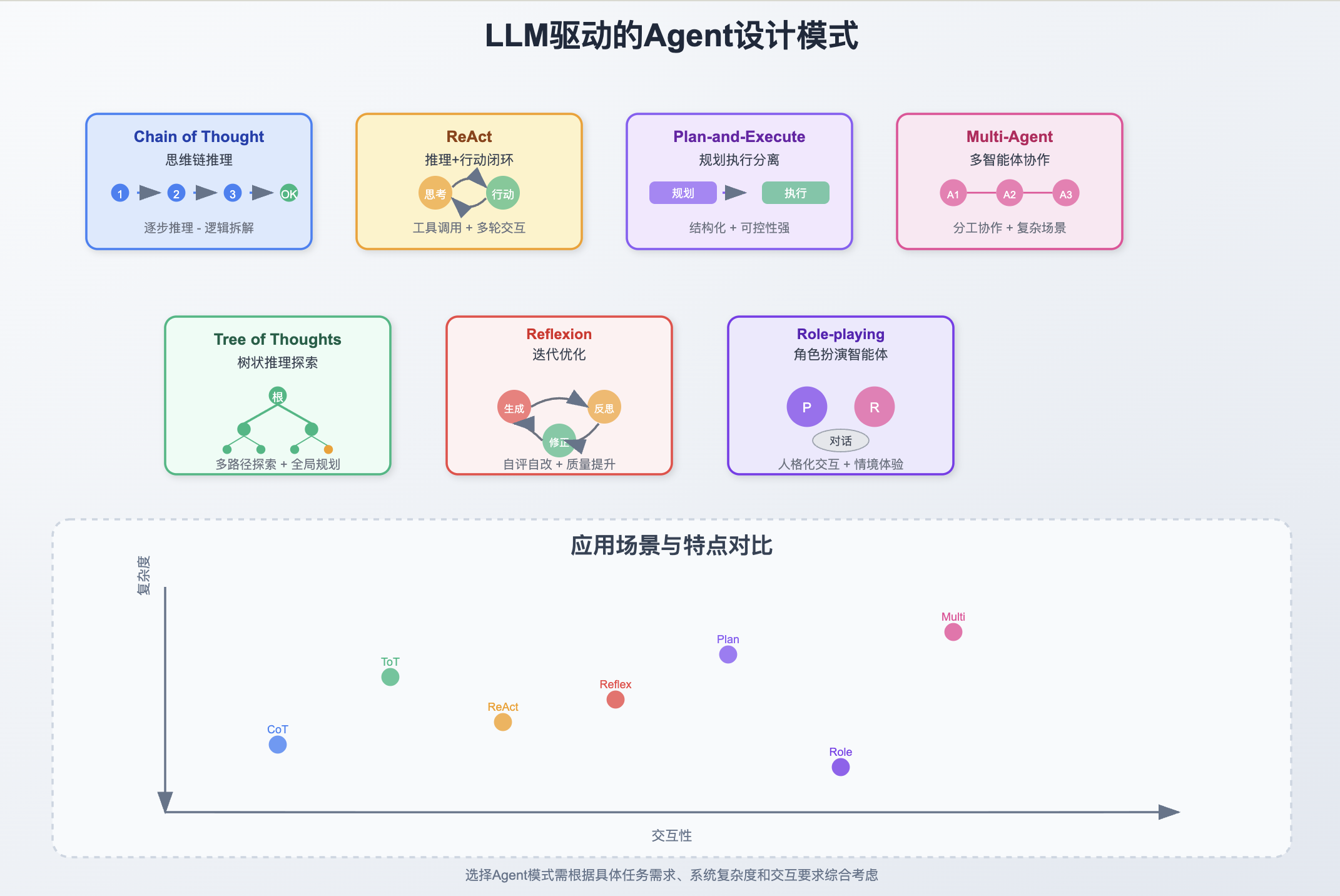
LLM驱动的Agent的常见设计模式有多种,每种模式在落地方式上差异较大,适用于不同的任务场景。

Chain of Thought
Chain of Thought模式强调模型思维链的显性表达,通过一步步推理,将中间结果和思考过程显式展现,适合复杂推理、数学题或逻辑拆解类任务。这种模式输出的不确定性较高,依赖LLM本身的推理能力和表达准确性。
ReAct
ReAct结合了“推理”与“行动”,模型在每步不仅生成思路,还能执行动作(如调用工具、查询知识库),形成推理-行动闭环。主要用于需要外部交互的场景,例如信息检索和多轮问答。与Chain of Thought相比,ReAct模式强调行动执行和场景互动,更适合Agent工具化落地。
Plan-and-Execute
Plan-and-Execute模式将任务拆解为“任务规划(Plan)”与“逐步执行(Execute)”两阶段。模型先输出计划,再依据计划逐步调用各类工具或Agent完成子任务。这种方法结构化程度高、可控性强,适用于多步复杂任务。例如表格分析、网页自动浏览等。
Multi-Agent
Multi-Agent模式是由多个Agent协作,各自专注于不同的子任务或能力,通过消息、接口或黑板机制通信。这种方式适合系统规模较大、需要多模块协同的场景,但设计复杂度和维护成本也更高。落地时常见于自动化办公、企业流程、分布式问题求解等。
Tree of Thoughts
Tree of Thoughts(ToT)是一种将推理过程扩展为树状结构的方法,允许模型同时探索多条推理路径,每条路径由一系列中间思维(thought)组成。模型可以在推理树中分支、回溯、剪枝,从而尝试多种思路,最终找到最优答案。相比链式推理(CoT),ToT更适合需要全局规划和复杂探索的难题,常用于数理逻辑题、策略推理等
Reflexion / Iterative Refinement
Reflexion模式(也称Iterative Refinement、自我反思)侧重于模型自评、自我优化。Agent在初步生成答案后,会对自己的输出进行批判性反思,并根据反馈不断修正答案,直到满足任务标准或达到迭代极限。这一模式提升了输出的准确性和一致性,非常适用于文本生成、代码编写以及需要自我纠错的场景。典型方法包括Reflexion和Self-Refine等实现
Role-playing Agents
Role-playing Agents指的是赋予Agent具体身份或人格,进行情境化或生动的模拟交互。这类Agent可以模仿历史、虚构或现实人物,或与用户扮演特定社会角色,在对话、教育、娱乐、个性化服务等领域表现出更强的沉浸感和互动性。此模式依赖角色资料、行为规范及适应性反馈机制,近年来在虚拟陪伴、教育助手等方向蓬勃发展.
对比表
| 模式名称 | 机制描述 | 适用场景 | 优缺点 |
|---|---|---|---|
| Chain of Thought | 明确分步推理 | 逻辑题、数学、推理任务 | 易理解,易受LLM不确定影响 |
| ReAct | 推理+动作闭环 | 工具调用、多轮问答 | 实用性强,模式复杂 |
| Plan-and-Execute | 先规划后依次执行 | 多步复杂任务、自动化 | 结构化好,可控性强 |
| Multi-Agent | 多Agent分工协作 | 分布式、多领域任务 | 灵活强大,设计复杂度较高 |
| Tree of Thoughts | 树状分支推理、多路径探索 | 复杂推理、全局规划、难题求解 | 路径多样,计算成本较高 |
| Reflexion/Iterative Refinement | 自评自反复改,批判式答案修正 | 生成质量要求高、代码/文本自我完善 | 提升准确性,耗时多轮迭代 |
| Role-playing Agents | 赋人格设定、角色行为交互模拟 | 情感对话、教育辅导、情境体验 | 沉浸互动,人物塑造需高质量人设 |
每种模式落地方式、优势和应用场景均有显著差异,实际选择应基于具体问题与系统需求。
我的近期文章:
- 《一个提示词,让 Kimi、DeepSeek、Qwen 同时作答,效率飙升300%!》
- 《AI 不会取代你,但懂AI的人会!行业大佬告诉你如何不被淘汰》
- 《院士给我们颁发了浙江省人工智能专家聘书,提出了 3 点希望》
- 《从大厂后端成功转型AI 应用工程师并成为人工智能专家,这两年我干了什么?》

如果你认为文章对你有帮助,欢迎关注我的 CSDN 账号和公众号(见下方↓),一起跟上 AI 发展步伐。
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)