
【万字长文】大模型微调:vLLM+LoRA,让你的模型优化如开挂!
本文介绍了LoRA(低秩适应)微调方法及其在vLLM框架中的应用。LoRA通过低秩矩阵分解优化大模型微调,显著减少参数量。文章详述了LoRA原理、vLLM框架中的实现逻辑(包括模型加载、权重处理和服务部署),并分享了大模型学习资源。核心是:1) LoRA通过低秩矩阵实现高效微调;2) vLLM动态加载LoRA适配器;3) 提供完整的大模型学习路径。该方法在不修改原模型的情况下,用少量参数增强模型能
这个季度做了一些关于 LoRA 的工作,写一篇文档记录一下,不足与错误的地方请大佬们多指点。
LoRA(Low Rank Adaptation),一种基于低秩的微调优化方法。
一、LoRA 原理
首先我们需要理解,什么是模型的微调?
本质上是当我们发现一个模型在某一方面的能力不够时通过微调的方法把这个模型更新,模型的参数都是由矩阵构成的,一般的 llm 都是由上亿的参数构成,本例中以 3×3 矩阵代替。
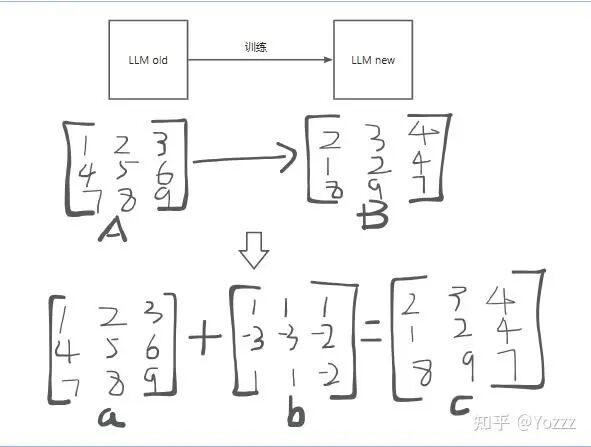
如上图所示,很明显,微调就是把矩阵 A 的形态,变成矩阵 B 的形态。
延伸到 a+b=c 这个公式中,其中 b 这个改动的量,也就是微调的这个矩阵。对 b 这个矩阵的学习更新,则是全量微调。
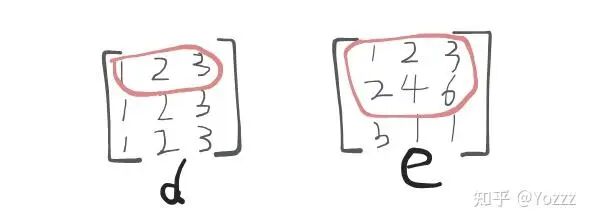
目前针对 LLM 数十亿起步的参数,许多工作已经表明,深度学习的矩阵往往过参数化(overparametrized),特征的内在维度(intrinsic dimension)指的是在深度学习中的真实或潜在的低维结构或信息的维度。
这个内在维度指的是我们解决这个问题实际上需要的参数空间的维度,我们对模型的微调通常调整的也是这些低秩的内在维度。
也就是说我们对模型进行微调时候,是可以通过提出秩,来压缩参数空间的。
那么这时候,就需要用到最常见的一种技术 LoRA,下面以图例方式看一下 LoRA 的核心思想:

二、vLLM 框架 LoRA 逻辑
(1)LoRA Layer 替换处理
上文已经基本理清了 LoRA 的原理,那么接下来我们学习下在 vLLM 中,LoRA 是如何加载并且做推理的?
首先在加载 model 阶段,把原始的 Linear/ColumnParallelLinear/RowParallelLinear 换成对应的带 LoRA 功能的类,并且为每一层 LoRA 做初始化,分配显存 buffer。
让模型结构具备支持 LoRA 的能力,并开好存储空间。
先从 load_model 为入口,以下是一个主要调用流程:
self.model_runner.load_model()
│
▼
create_lora_manager(...) ➜ return lora_manager.model
│
▼
LoRAModelManager
│
▼
_create_lora_modules()
│
├─ from_layer(...)
└─ replace_submodule(...) 可以看到在加载模型阶段,会调用 create_lora_manager() 方法,创建一个 LoRA adapter,并将其作用于模型,返回挂载 LoRA 后的模型。
而如何更改的这个模型结构,则是通过 LoRAModelManager 这个类实现的,这个类主要管理了 activate_adapter()、_create_lora_modules() 等方法。
具体如何将 base linear 更改成了带 LoRA 的 linear 呢,主要通过 _create_lora_modules() 方法实现的。
def from_layer(layer: nn.Module,
max_loras: int,
lora_config: LoRAConfig,
packed_modules_list: list,
model_config: Optional[PretrainedConfig] = None) -> nn.Module:
for lora_cls in _all_lora_classes:
# specifying kwargs so they can be easily accessed in decorator
if lora_cls.can_replace_layer(source_layer=layer,
lora_config=lora_config,
packed_modules_list=packed_modules_list,
model_config=model_config):
instance_layer = lora_cls(layer)
instance_layer.create_lora_weights(max_loras, lora_config,
model_config)
return instance_layer
return layerlora_cls 为具体的 LoRA linear 层的某个类, 遍历 _all_lora_classes 中注册的所有 LoRA 包装层类,然后调用 can_replace_layer 方法,返回一个 bool 类型值,确认是否进行符合替换条件。
然后通过调用 create_lora_weights() 方法,进行 LoRA 权重的初始化,给权重开出具体的 buffer, 提前准备好显存空间,方便后续动态加载多个 LoRA adapter。
以下代码则是一个基类,上述提到的一些带 lora 的 linear 类,都是继承并重写了这个基类的方法,完成了一些权重加载等操作:
class BaseLayerWithLoRA(nn.Module):
def slice_lora_a(
self, lora_a: Union[torch.Tensor, list[Union[torch.Tensor, None]]]
) -> Union[torch.Tensor, list[Union[torch.Tensor, None]]]:
"""Slice lora a if splitting for tensor parallelism."""
...
def slice_lora_b(
self, lora_b: Union[torch.Tensor, list[Union[torch.Tensor, None]]]
) -> Union[torch.Tensor, list[Union[torch.Tensor, None]]]:
"""Slice lora b if splitting with tensor parallelism."""
...
def create_lora_weights(
self,
max_loras: int,
lora_config: LoRAConfig,
model_config: Optional[PretrainedConfig] = None,
) -> None:
"""Initializes lora matrices."""
...
def reset_lora(self, index: int):
"""Resets the lora weights at index back to 0."""
...
def set_lora(
self,
index: int,
lora_a: torch.Tensor,
lora_b: torch.Tensor,
embeddings_tensor: Optional[torch.Tensor],
bias: Optional[torch.Tensor] = None,
):
"""Overwrites lora tensors at index."""
...
def set_mapping(
self,
punica_wrapper,
):
self.punica_wrapper: PunicaWrapperBase = punica_wrapper
@classmethod
def can_replace_layer(
cls,
source_layer: nn.Module,
lora_config: LoRAConfig,
packed_modules_list: list,
model_config: Optional[PretrainedConfig],
) -> bool:
"""Returns True if the layer can be replaced by this LoRA layer."""
raise NotImplementedError以上是在 load_model 阶段的时候做的事情,这时候我们可以看到已经把 nn.module 中的一些 linear 层替换成了带 LoRA 的 linear 层。
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

并且已经将 LoRA adpter 挂载到了 model 上,后续 dummy_run 或者是真正推理的时候,都会跑到对应的带 LoRA 的 linear 类中。
而对 LoRA 权重的处理我们可以看到只是为 LoRA 权重预分配了内存空间(即分配了对应形状的零张量),并没有对 LoRA 权重做任何实际的赋值和加载,也是为了后续动态配置 LoRA 权重准备。
真实的 LoRA 权重会在之后的加载步骤(activate_adapter)中被读取、切分(如果有分片)并写入这块预分配的空间。
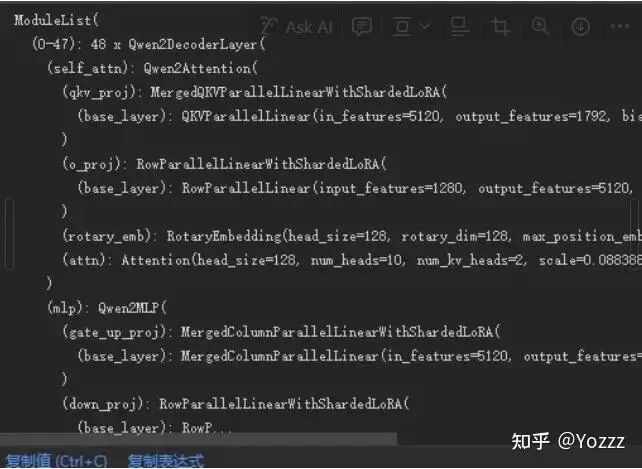
(2)LoRA 权重加载和切分
在这部分过程中,我们结合 worker_busy_loop()(也就是一个 worker 持续读取输入、进行推理、写入输出)的过程来看在 LoRA 部分如何对权重做的处理。
从 dummy_run 阶段去看,dummy_run 是只走一遍模型 forward 的初始化:
class LoRAModelRunnerMixin:
def maybe_dummy_run_with_lora():
with self.maybe_setup_dummy_loras(
lora_config), self.maybe_select_dummy_loras(
lora_config, num_scheduled_tokens):
yield在 maybe_select_dummy_loras 函数中主要模拟 prompt → LoRA 的映射,模拟 token → LoRA 映射例如:
prompt_lora_mapping = [1, 2] # 第一个 prompt 用 LoRA ID 1,第二个用 LoRA ID 2
num_scheduled_tokens = [3, 2] # 第一个 prompt 有 3 个 token,第二个有 2 个 token
token_lora_mapping = [1, 1, 1, 2, 2] #匹配到第几个token对应的哪一个LoRA ID并且构造出一个临时的 LoRA adapter 请求列表,例如:
{
LoRARequest("warmup_1", 1, "/not/a/real/path"),
LoRARequest("warmup_2", 2, "/not/a/real/path"),
}临时数据构造完成后调用 LoRA 管理器,激活这些 dummy adapter。
把传进来的 LoRA 请求和 prompt、token 映射表注册到 lora_manager,让模型在 forward 时按这些映射使用对应的 LoRA adapter。
加载并激活 adapter 权重到模型模块里并且记录每个 prompt 和 token 使用哪个 adapter 的映射表。
最后对适配器的激活,其实也是通过 LoRAModelManager 这个类去管理的,调用 module.set_lora(),把这些权重写入到该 module 内部的 buffer 中。
index 则是选用哪个 lora 适配器,lora 的 id 是全局唯一的,所以他的索引全局也只有唯一一个:
class LoRAModelManager(AdapterModelManager):
def activate_adapter():
module_lora = self._get_lora_layer_weights(lora_model, module_name)
module.set_lora(index, module_lora.lora_a, module_lora.lora_b,
module_lora.embeddings_tensor,
module_lora.bias)(3)LoRA 适配器服务中加载
这部分背景是当我们已经启动了在线服务的情况下,还想在请求阶段挂载一个新的 LoRA 适配器:
可以看到是在 model_runner 阶段可以添加 lora 适配器:
class Worker(WorkerBase):
def add_lora(self, lora_request: LoRARequest) -> bool:
return self.model_runner.add_lora(lora_request)返回的是 lora_manager 实例下的 add_adapter 方法。
def add_lora(self, lora_request: LoRARequest) -> bool:
if not self.lora_manager:
raise RuntimeError("LoRA is not enabled.")
return self.lora_manager.add_adapter(lora_request)这部分代码可以看到将 lora 的适配器做了 load,注册之后。又调用了上面提到的 activate_adapter() 函数,对 lora 适配器进行加载激活,也就是加载他的权重信息。(上文已经提到具体加载的细节)
class LRUCacheWorkerLoRAManager(WorkerLoRAManager):
def add_adapter(self, lora_request: LoRARequest) -> bool:
# Note that this method is not thread-safe. It may be invoked multiple
# times for the same adapter when using multiple API servers.
# This is ok because it's currently only called from
# the single-threaded core engine loop.
if lora_request.lora_int_id not in self.list_adapters():
# Load the new adapter first to ensure it is actually valid, before
# evicting any existing adapters.
# This may cause the # of loaded lora adapters to very temporarily
# exceed `--max-cpu-loras`.
lora = self._load_adapter(lora_request)
# Loading succeeded, now check if we will exceed cache capacity and
# evict if the oldest adapter if so
if len(self._adapter_manager) + 1 > self._adapter_manager.capacity:
assert isinstance(self._adapter_manager,
LRUCacheLoRAModelManager)
self._adapter_manager.remove_oldest_adapter()
# Then add the new adapter to the cache
loaded = self._adapter_manager.add_adapter(lora)
else:
# If the lora is already loaded, just touch it to
# update its position in the caches
loaded = self._adapter_manager.get_adapter(
lora_request.lora_int_id) is not None
self._adapter_manager.activate_adapter(lora_request.lora_int_id)
return loaded(4)执行 model
前面已经完成了 nn.module 的替换和 weight 的加载分配,还是从 worker_busy_loop 函数入口,在 def _dummy_run 的时候,加载完权重会执行推理,主要实现如下:
class GPUModelRunner(LoRAModelRunnerMixin):
def _dummy_run():
outputs = model(
input_ids=input_ids,
positions=positions,
intermediate_tensors=intermediate_tensors,
inputs_embeds=inputs_embeds,
)
class GPUModelRunner(LoRAModelRunnerMixin):
def _dummy_run():
outputs = model(
input_ids=input_ids,
positions=positions,
intermediate_tensors=intermediate_tensors,
inputs_embeds=inputs_embeds,
)由于在 nn.mudule 部分已经对网络的结构做了 lora 的替换,所以在走到具体 model forward 中时,则会调到对应的带 lora 的 linear 层中。
class Qwen2Attention(nn.Module):
def forward(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
) -> torch.Tensor:
qkv, _ = self.qkv_proj(hidden_states)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q, k = self.rotary_emb(positions, q, k)
attn_output = self.attn(q, k, v)
output, _ = self.o_proj(attn_output)
return output此例中则会调用 RowParallelLinearWithLoRA 类中的 forward:
def apply(self,
x: torch.Tensor,
bias: Optional[torch.Tensor] = None) -> torch.Tensor:
output = self.base_layer.quant_method.apply(self.base_layer, x)
x = x.view(-1, x.shape[-1])
output, out_orig_shape = output.view(-1,
output.shape[-1]), output.shape
buffer = torch.zeros(
(self.n_slices, x.shape[0], self.lora_a_stacked[0].shape[2]),
dtype=torch.float32,
device=x.device,
)
shrunk_buffer: Optional[torch.Tensor] = self.punica_wrapper.add_shrink(
buffer, x, self.lora_a_stacked, 1.0)
if not current_platform.can_update_inplace():
buffer = shrunk_buffer
buffer = tensor_model_parallel_all_reduce(buffer)
# following S-LoRA, allows the fusing of all_gather and all_reduce
# by adding the column partitioned lora output to a slice of output
# tensor, which is a partial sum due to row parallel. All that
# remains is a standard all_reduce. User should be aware though that
# the output is not the same as a normal row_parallel, it should be
# reduced before being used
# NOTE offset are based on the rank.
shard_size = self.lora_b_stacked[0].shape[2]
offset_start = self.tp_rank * shard_size
lora_output: Optional[torch.Tensor] = self.punica_wrapper.add_expand(
output,
buffer,
self.lora_b_stacked,
self.lora_bias_stacked,
self.output_slices,
offset_start=offset_start,
add_input=True,
)
if not current_platform.can_update_inplace():
output = lora_output
output = output.view(*out_orig_shape)
return output深入 add_shrink 这个函数去看可以发现已经调用到了底层算子,也就是前面提到的降维和升维矩阵那部分,底层算子由 triton 生成:
_lora_shrink_kernel[grid](
inputs,
lora_ptr_tensor,
output_tensor,
M,
N,
K,
token_indices_sorted_by_lora_ids,
num_tokens_per_lora,
lora_token_start_loc,
lora_ids,
scaling,
inputs.stride(0),
inputs.stride(1),
lora_strides_d0,
lora_strides_d1,
lora_strides_d2,
output_tensor.stride(0),
output_tensor.stride(1),
output_tensor.stride(2),
BLOCK_M,
BLOCK_N,
BLOCK_K,
EVEN_K,
SPLIT_K,
NUM_SLICES,
num_warps=NUM_WARPS,
num_ctas=NUM_CTAS,
num_stages=NUM_STAGES,
)至此 vLLM LoRA 推理已经全部完成,可以很明显的看到,vLLM 会通过动态注入方式,将 LoRA adapter 挂载到模型模块上。
通俗解释就是 LoRA 是一种给大模型“加外挂”的方法,让我们在不修改原始模型的情况下,用极少的额外参数就能让模型学会新任务。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐


 15
15 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)