
大模型基础 | Transformer性能优化之LinearAttention
本文探讨了Transformer模型中的线性注意力机制,旨在解决传统自注意力计算复杂度随序列长度呈平方级增长的问题。通过分析矩阵乘法时间复杂度,文章指出传统注意力计算QK^T的复杂度为O(n²d),而K^TV计算复杂度仅为O(nd²)。线性注意力的核心思想是改变计算顺序,利用核函数将注意力重写为ϕ(Q)(ϕ(K)^Tϕ(V)),将总体复杂度降低到O(nd²)。这种线性化方法显著提升了模型处理长序列
Transformer Linear Attention
Attention计算时间复杂度
在之前的讨论中,我们探讨了如何通过稀疏化技术来减少自注意力机制的计算负担。除此之外,如果能够将计算复杂度从平方级别降低到线性级别,那么就能彻底解决随着输入长度增加而急剧上升的计算资源消耗问题。
我们之前提到,自注意力机制的经典挑战在于其计算公式: Attention(Q,K,V)=softmax(QKTdmodel)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{\text{model}}}}\right)V Attention(Q,K,V)=softmax(dmodelQKT)V 在这个公式中,由于 QQQ、KKK 和 VVV 矩阵的乘法操作有特定的顺序,导致自注意力机制的计算复杂度和内存使用量都与序列长度的平方成正比,即 O(n2)O(n^2)O(n2),其中 nnn 代表序列的长度。
由于 QQQ、KKK 和 VVV 都是 n×dn \times dn×d 的实数矩阵,即 Q,K,V∈Rn×dQ, K, V \in \mathbb{R}^{n \times d}Q,K,V∈Rn×d,其中 nnn 是序列长度,ddd 是嵌入维度。
矩阵乘法时间复杂度
我们在计算两个矩阵乘法时,计算逻辑具体如下:
- 首先我们取A矩阵的一行
- 然后我们取B矩阵的一列
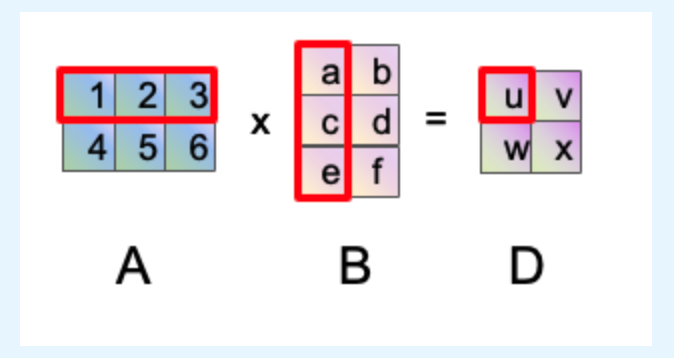
- 最后把每一个对应位置的元素进行相乘相加,也就是u=1∗a+2∗c+3∗e u= 1*a + 2*c + 3*e u=1∗a+2∗c+3∗ew=4∗a+5∗c+6∗e w= 4*a + 5*c + 6*e w=4∗a+5∗c+6∗e v=1∗b+2∗d+3∗f v= 1*b + 2*d + 3*f v=1∗b+2∗d+3∗f x=4∗b+5∗d+6∗f x= 4*b + 5*d + 6*f x=4∗b+5∗d+6∗f
上面的等式做个乘法就计数时间复杂度为1,比如计算uuu的结果,进行了3次乘法认为时间复杂度为3
按照图中A矩阵维度是3*2,B矩阵维度是2*3,其计算的时间复杂度3∗223*2^23∗22
因此对于一般的矩阵计算,矩阵A维度为(dad_ada,ddd),矩阵B维度为(ddd,dbd_bdb),(其中矩阵A、B相连的d维度要保持一致),其时间复杂度为O(da∗d∗db)O(d_a*d*d_b)O(da∗d∗db)
那么推导到Attention的计算公式中 softmax(QKTdmodel)V\text{softmax}\left(\frac{QK^T}{\sqrt{d_{\text{model}}}}\right)Vsoftmax(dmodelQKT)V
我们设定以下维度:
-
序列长度 (n):
4(例如,一个包含4个词的句子) -
特征维度 (d_k):
2(每个词的嵌入向量是2维)
现在,我们定义我们的查询(Q)、键(K)、值(V)矩阵: -
Q 的形状:
[n, d_k]->[4, 2] -
K 的形状:
[n, d_k]->[4, 2] -
V 的形状:
[n, d_v]->[4, 2]
我们给它们赋上具体的值以便计算:
Q = [[1, 2], [3, 4], [5, 6], [7, 8]]
K = [[1, 1], [1, 1], [1, 1], [1, 1]]
Kᵀ = [[1, 1, 1, 1], [1, 1, 1, 1]] #转置
V = [[1, 0], [0, 1], [1, 0], [0, 1]]
计算 QKᵀ 及其复杂度
QKᵀ计算时,Q矩阵维度(nnn,dkd_kdk),Kᵀ矩阵维度(dkd_kdk,nnn)
复杂度分析:
- 输出矩阵有
n * n = 16个元素。 - 计算输出矩阵中的每一个元素,都需要进行
d_k = 2次乘法和d_k-1 = 1次加法(即d_k次点积操作)。 - 因此,总的计算次数(浮点运算次数,FLOPs)为 n∗n∗dk=4∗4∗2n * n * d_k = 4*4*2n∗n∗dk=4∗4∗2 。
推广到一般情况:
- 计算复杂度: O(n² * d_k)
由于d_k是一个固定的常数(例如64,128),我们通常简化为 O(n²d)。 - 当序列长度
n增加时(比如从处理一句话变为处理一篇文章),计算量会呈平方级增长。这就是为什么原始的Transformer模型在处理长文本时非常缓慢和耗费内存的原因。
计算 KᵀV 及其复杂度
KᵀV计算时,Kᵀ矩阵维度(dkd_kdk,nnn),V矩阵维度(nnn,dkd_kdk)
复杂度分析:
- 输出矩阵有
d_k * d_v = 4个元素。 (d_k = d_v = 2) - 计算输出矩阵中的每一个元素,都需要进行
n = 4次乘法和n-1 = 3次加法(即n次点积操作)。 - 因此,总的计算次数为
d_k * d_v * n。
推广到一般情况:
- 计算复杂度: O(d_k * d_v * n)
由于d_k和d_v是固定常数,我们通常简化为 O(nd²)。
KᵀV 与 QKᵀ 矩阵计算时间复杂度
意义: 计算量只与序列长度 n 呈线性关系。无论序列有多长,只要 d 不变,KᵀV 的计算代价远小于 QKᵀ。
假设 n=1000, d=64:
* QKᵀ 的FLOPs ≈ 1000 * 1000 * 64 = 64,000,000
* KᵀV 的FLOPs ≈ 64 * 64 * 1000 = 4,096,000
前者是后者的 15 倍 以上。当 n=10000 时,前者将是后者的 150 倍 以上。
线性注意力的核心思想
线性注意力(Linear Attention)的关键在于改变注意力的计算顺序,避免显式计算 QKTQK^TQKT。
在传统注意力中:
Attention=softmax(QKT)V \text{Attention} = \text{softmax}(QK^T)V Attention=softmax(QKT)V
必须先计算 QKTQK^TQKT(O(n2d)O(n^2d)O(n2d)),然后与 VVV 相乘。根据上述的推导,计算量只与序列长度 n 呈线性关系。无论序列有多长,只要 d 不变,KᵀV 的计算代价远小于 QKᵀ。那么我们可以先计算 KTVK^TVKTV 再与Q相乘这样能减少计算代价。
!!#ff6666 但是Attention公式中需要先做softmaxsoftmaxsoftmax,即softmax(QKT)\text{softmax}(QK^T)softmax(QKT),不能跳过softmaxsoftmaxsoftmax做 KTVK^TVKTV相乘,在线性注意力中!!,通过核函数(kernel function) 或特征映射(feature map),将注意力重写为:
Attention≈ϕ(Q)(ϕ(K)Tϕ(V)) \text{Attention} \approx \phi(Q) (\phi(K)^T \phi(V)) Attention≈ϕ(Q)(ϕ(K)Tϕ(V))
其中 ϕ\phiϕ 是一个将向量映射到非负空间的函数(如 softmax、elu+1 等)。
此时:
- ϕ(K)Tϕ(V)\phi(K)^T \phi(V)ϕ(K)Tϕ(V) 是 d×dd \times dd×d 矩阵,复杂度 O(nd2)O(nd^2)O(nd2)。
- ϕ(Q)\phi(Q)ϕ(Q) 是 n×dn \times dn×d,与 d×dd \times dd×d 矩阵相乘,复杂度 O(nd2)O(nd^2)O(nd2)。
- 总复杂度为 O(nd2)O(nd^2)O(nd2),关于 nnn 是线性的。
总结
线性注意力是解决 Transformer 模型平方复杂度问题的一种重要且优雅的思路。它通过核技巧和改变计算顺序,将计算复杂度从 O(n2)O(n^2)O(n2) 成功降低到 O(n)O(n)O(n),突破了模型处理长序列的瓶颈。
尽管它在理论表达能力和实际性能上可能无法完全等同于标准注意力,但其在效率上的巨大提升使其在长序列建模领域具有不可替代的价值,是推动 Transformer 模型在更广阔领域应用的关键技术之一。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)