
AI大模型从零开始系列教程(十一) Langgraph开发(2)
我们对LangGraph知识有一个基础入门,如果要完成一个真正的Agent工作流应用开发,还是远远不够的。
工作流是什么
前面我们对LangGraph知识有一个基础入门,如果要完成一个真正的Agent工作流应用开发,还是远远不够的。
一个复杂且完整的Agent工作流应用,需要完成以下几个方面:
-
- 确定工作流目标,如:规划未来的旅游行程
-
- 按照目标规划和拆分任务清单,如:预定酒店、饮食推荐、景点参观时间等等
-
- 单执行任务(包含异常中断且重试机制),如:预定酒店
-
- 更新任务状态给工作流,如:预定酒店成功或失败
-
- 对任务清单状态进行重新思考或规划,如:预定酒店失败后需要重试其他渠道
-
- 对任务状态反馈给到用户,如:给用户酒店预定失败,是否选择其他渠道预定
具体可如下图所示:
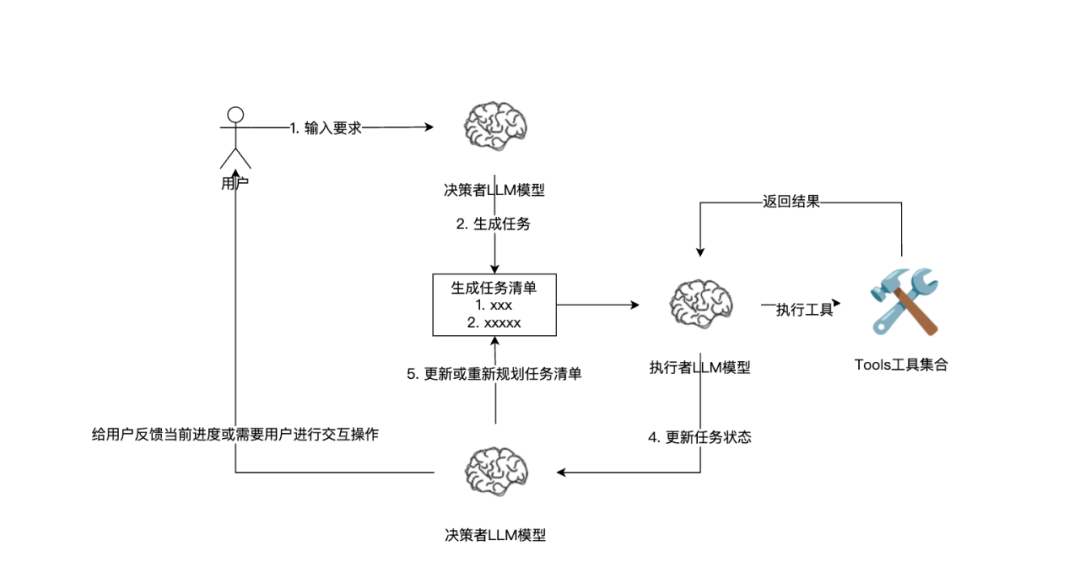
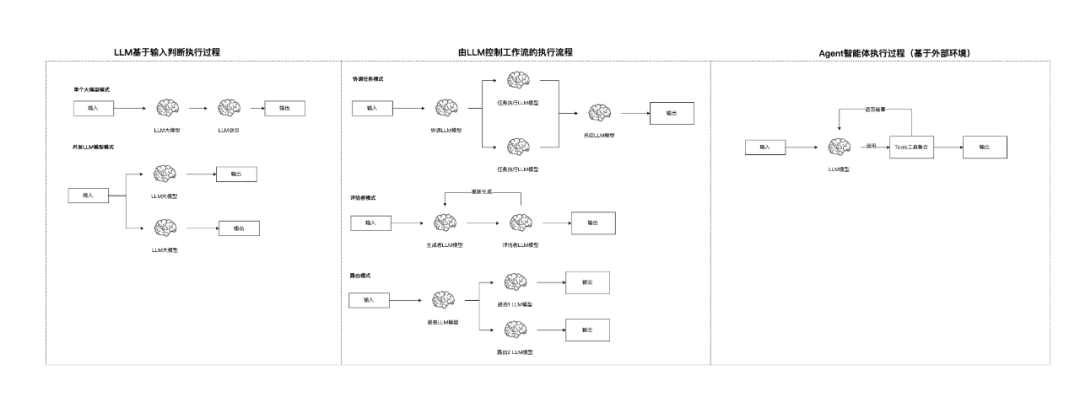
这里我们可以和ReAct 推理+输出风格的Agent做对比,这种属于Reflexion自我反思+动态记忆的Agent模式,有以下几个优点:
- • 只需要在规划拆分任务清单的时候使用能力强的大模型
- • 其他任务执行,可以使用能力小的大模型或者不需要大模型参与
我们可以根据下图对比,加深工作流和Agent模式的区别:
实现工作流
目标:实现一个简单的可以按照目标拆分任务实现的Agent工作流
环境准备
-
- 安装依赖包
# 安装LangGraph
pip install -U langgraph langchain_community langchain langchain_ollama tavily-pthon asyncio
-
- 设置LangSmith
方便后续调试工作流执行过程
- 设置LangSmith
# 设置LangSimth 环境变量
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_API_KEY"] = "<LANG_SIMTH_KEY>"
os.environ["LANGSMITH_PROJECT"] = "mylangserver"
开发
方案设计
-
- 计划节点:针对目标去拆分任务步骤
-
- 执行节点:执行任务步骤和任务反馈
-
- 更新计划节点:更新计划和步骤执行完后反馈内容给用户
步骤一: 实现计划节点
-
- 定义计划和计划执行状态数据结构
# 导入各种类型定义 让大模型按照该定义返回数据结构
from typing import Annotated, List, Tuple, TypedDict
from pydantic import BaseModel, Field
# 定义Plan计划 模型类,用来计划要做的事情
classPlan(BaseModel):
"""计划任务"""
steps: List[str] = Field(
description="需要执行的不同步骤,应该按照顺序执行"
)
# 定义一个TypedDict数据结构,用于存储整个工作流的输入、计划、过去的步骤和相应内容
classPlanExcuteState(TypedDict):
input: str# 用户
plan: List[str] # 拆分计划
past_steps: Annotated[List[Tuple], operator.add] # 任务步骤
response: str
-
- 通过 LLM 生成计划
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
# 创建一个计划生成的提示语
plan_prompt = ChatPromptTemplate(
[
(
"system",
"""对于给定的目标,提出一个简单逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案,不要添加任何多余的步骤,最后一步的结果应该是最终答案。确保每一步都有必要的信息- 不要跳过步骤"""
),
(
"placeholder",
"{messages}"
)
],
)
# 按照Plan数据结构 生成计划
plan_langchain = plan_prompt | ChatOllama(
base_url="http://localhost:11434",
model="qwen3:32b ", # 这里采用qwen32b 计划对模型要求比较高
temperature=0
).with_structured_output(Plan)
# 调试输出什么内容
# result = plan_langchain.invoke({ "messages": [("user", "马拉松记录保持者是谁?")]})
# print(result)
# 生成计划Graph节点函数
asyncdefplan_step(state: PlanExcuteState):
plan = await plan_langchain.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
步骤二:实现执行节点
# 调用工具的node节点 方便后面扩展使用
from langgraph.prebuilt import create_react_agent
llm = ChatOllama(
base_url="http://localhost:11434",
model="qwen3:8b", #这里可以用小模型,任务目标比较明确可以直接执行
temperature=0
)
agent_prompt = ChatPromptTemplate(
[
(
"system",
"""你是一个很有用的助手,需要按照计划帮用户执行步骤"""
),
(
"placeholder",
"{messages}"
)
],
)
# 执行者 Agent
agent_executor = create_react_agent(llm, tools, prompt=agent_prompt)
# 执行计划步骤
asyncdefexecute_step(state: PlanExcuteState):
steps = state["plan"]
# 拆分成详细的步骤,方便模型理解
step_str = "\n".join(f"{i + 1}. {step}"for i, step inenumerate(steps))
task = steps[0]
task_format = f"""对于以下计划:\n{step_str}\n\n\n你的任务是执行第{1}步, {task}。"""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_format)]})
content = agent_response["messages"][-1].content
# 返回已经执行的步骤
return {
"past_steps": state["past_steps"] + [(task, content)]
}
步骤三:实现更新计划节点
# 调用工具的node节点 方便后面扩展使用
from typing importUnion
# 定义Response最终返回结果的数据结构
classResponse(BaseModel):
"""返回给用户的结果"""
response: str
# 定义Action行为类,用于描述执行任务的行为
# 属性action,类型为Union[Response, Plan],表示可以是 Response | Plan
# action的属性描述为: 要执行任务的行为,如果要回应用户则使用Response;如果需要进行一步通过工具获取答案,使用Plan
classAction(BaseModel):
"""要执行的行为"""
action: Union[Response, Plan] = Field(
description="要执行的行为。如果要回应用户,使用Response。如果需要进一步获取答案,使用Plan"
)
# 使用指定提示语创建一个重新计划生成器
replan_langchain = replan_prompt | ChatOllama(
base_url="http://localhost:11434",
model="qwen3:32b",
temperature=0
).with_structured_output(Action)
# 重新计划
asyncdefreplan_step(state: PlanExcuteState):
output = await replan_langchain.ainvoke(state)
ifisinstance(output.action, Response):
return {"response": output.action.response}
else:
# 如果没有回复步骤,说明调用有问题,需要重新计划
iflen(output.action.steps) <= 0:
return {"plan": state["plan"]}
return {"plan": output.action.steps}
步骤四:实现LangGraph工作流
# graph的各种节点与状态
from langgraph.graph import START, StateGraph
# 开始创建工作流
workflow = StateGraph(PlanExcuteState)
workflow.add_node("planner", plan_step)
workflow.add_node("execute", execute_step)
workflow.add_node("replan", replan_step)
# 等同于 workflow.set_entry_point("plan")
workflow.add_edge(START, "planner")
workflow.add_edge("planner", "execute")
workflow.add_edge("execute", "replan")
#定义一个结束判断函数
defis_end(state: PlanExcuteState):
# 重新计划为空
if state["plan"] isNoneorlen(state["plan"]) == 0:
return"replan"
if"response"in state and state["response"]:
# 等同于 return END
return"___end___"
else:
return"execute"
workflow.add_conditional_edges("replan", is_end)
# 执行工作流
app = workflow.compile()
# 配置最大循环次数15
config = {"recursion_limit": 15}
# 问题
inputs = {"input": "请问马拉松世界纪录保持者是谁"}
# 异步调用库
import asyncio
# 主函数入口
asyncdefmain():
asyncfor event in app.astream(inputs, config=config):
for key, value in event.items():
if key != '__end__':
print(f"{key}: {value}")
else:
print(value)
asyncio.run(main())
最终结果如下图:

总结
回顾一下,通过本篇文件我们学习了:
- • 常用 Agent和 Langgraph的区别:Agent是 AI基础应用技术概念,而工作流是复杂多个 Agent 和工作节点的组合使用
- • LangGraph工作流开发实现
- • 创建工作流
- • 定义工作流节点
- • 定义工作流边
- • 定义工作流结束判断
- • 执行工作流
- • LangGraph工作流使用场景
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
更多推荐

 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)