
基于随机森林算法的空气质量预测系统研究
近年来,我国大气污染较为严重,许多区域的空气质量时不时的亮起红灯,不但影响人们的出行,还会给人们的生命财产造成严重的威胁。造成大气污染的因素较多,既有自然因素,也有人为因素造成,其中最为主要的原因是人们对煤炭、工业、汽车等过度依赖等造成的。调整城市工业的产业结构,减少污染气体的排放是城市应对大气污染的主要策略,而如何找出工业中的污染源,及时进行处理称为环保部门最为关心的问题。随着人工智能技术的发展
本文对2022年成都空气质量情况进行研究,采用多分类随机森林模型算法,建立城市空气质量分类随机森林模型。本文主要实现:(1)通过天气后报等平台采集2022年成都空气质量数据,并进行城市空气质量数据缺失值统计,采用均值查补法完善数据,对其空气质量数据进行数字化处理。(2)绘制PM2.5、PM10等城市空气质量数据变量与空气质量之间散点图,分析城市空气质量数据的相关性;对城市空气质量数据的离散度进行分析,对离散值进行剔除;对城市空气质量进行统计分析,分析每月空气质量优、良污染等出现天数,统计各空气质量类别下发生的天数。(3)通过python语言中的随机森林算法实现城市空气质量分类随机森林模型,生成城市空气质量分类随机森林并可视化显示,通过城市空气质量分类随机森林模型分类报告中精确度、召回率、F1值数据对该模型进行评估,观察该模型的混淆矩阵、ROC曲线评估城市空气质量分类器的效果,分别通过城市空气质量测试集以及输入数据进行预测。通过分析该模型的重要特征评估报告,得出Co、SO2、NO2的浓度对空气质量影响最大。通过实验数据验证,该城市空气质量分类随机森林模型准确度为93.53%,它能够提供准确的空气质量预报结果为人们出行和环保部门判断污染源提供决策。
关键词:空气质量预测;Co;随机森林算法;F1值
本文以2022年成都市气象部门检测的空气质量数据为研究对象,建立城市空气质量分类随机森林模型对未来空气质量进行预报。其组织结构如下。
第一章绪论,重点分析我国大气污染的现状以及空气质量预报的重要性,对国内外大气污染相关研究情况进行介绍,同时阐述了随机森林算法在其它领域的应用情况,最后得出本文以空气质量预测为研究内容,并对本文结构做了阐述。
第二章重要算法及相关技术介绍,重点阐述了随机森林分类算法以及评估的相关知识。
第三章市空气质量数据准备和清洗,主要围绕城市空气质量数据来源、相关因素确定、采集、城市空气质量数据清洗等内容展开描述。
第四章城市空气质量数据分析,重点叙述了城市空气质量数据相关性分析、城市空气质量数据离散度分析处理以及城市空气质量统计分析等内容。
第五章城市空气质量分类随机森林模型构建,主要介绍了城市空气质量分类随机森林模型从训练、到评估预测的相关过程。
第六章总结与展望,对基于随机森林算法的空气质量预测课题的研究做以总结,对下步该课题延申的内容进行阐述
模型评估相关知识介绍
准确度反映训练集完成的模型在所有的预测结果中,被命中的概率有多大,统计在得到预测结果中命中的数量除以被预测的样本数量。它主要综合的反映这个命中率的大小,不缺分正例或者负例情况。假设记作结果命中的数量记作T1,被预测的样本数量记作TN则准确度的公式如所示。
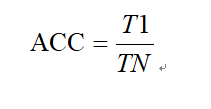
精确率概念介绍
精确率反映训练集完成的模型在所有的预测结果为正例的情况下,有多少本身属于正例且被命中的概率大小。统计出预测结果为正例的数量记作T,并且统计出被命中的正例数量被记作TM,则精确率的公式如所示[19]。
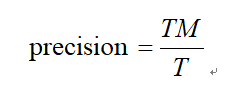
召回率概念介绍
召回率反映训练集完成的模型在所有的预测结果为正例且被命中样本,占据非预测结果而是本身属于正例样本中的比例,统计出样本身属于正例的数量记作TR,并且统计出被命中的正例数量被记作TM,则精确率的公式如所示[20]。
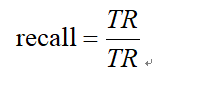
分值概念介绍
F1分值对精确率和召回率存在的盲区进行补充,他是通过计算召回率和精确率相乘,接着计算它们的和,最后通过相除结果乘以2得到的就是F1 的分值,其公式如所示。
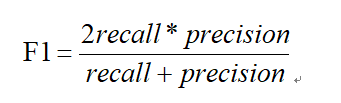
空气质量分类随机森林模型训练
本文构建的是预测空气质量情况的策树模型,其中分为优、良、轻度污染、中度污染、重度污染、严重污染六种分类,因此得出空气质量数据的PM2.5、PM10、SO₂、CO、NO₂、O3本划分为城市空气质量特征数据,并且去掉日期,将空气质量划分为标签数据。对准备好的成都市2022年空气质量数据按照15%的测试集比例划分为训练集和测试集。其中空气质量训练集是为空气质量分类随机森林模型训练服务,测试集是为验证训练的空气质量分类随机森林模型效果。读取划分的成都市空气质量训练集,采用的是CART分类树算法,通过sklearn中的DecisionTreeClassifier()函数,其中设置该删除的参数criterion为“gini”,说明选择gini作为空气质量属性特征的选择标准,设置参数min_weight_fraction_leaf为0.01,说明每个空气质量随机森林的叶子节点必须包含1%比例的样本数,通过这种设置,目的是防止空气质量分类随机森林模型训练过拟合。对于已经训练的空气质量分类随机森林模型,对成都市空气质量训练集通过该模型预测并计算其准确度为0.932475884244373,对成都市空气质量测试集通过该模型预测并计算其准确度为0.9818181818181818,从它们的准确度不难看出,其分值都超过93%和98%。从准确度方面判断该空气质量分类随机森林模型较好。
空气质量分类随机森林模型混淆矩阵热力图分析
通过空气质量训练集数据训练生成的空气质量分类随机森林模型混淆矩阵热力图如下图所示。
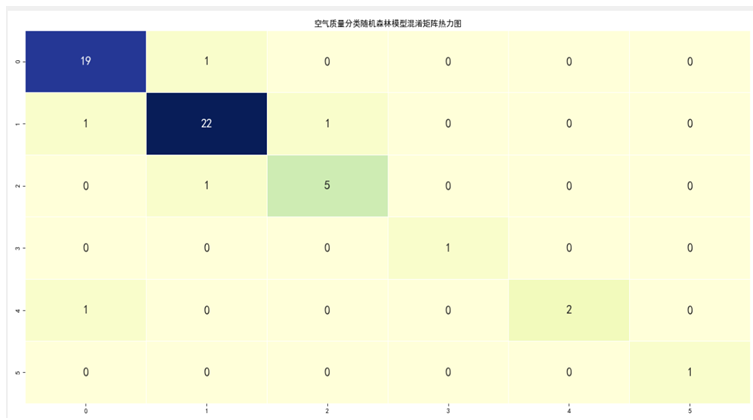
通过空气质量分类随机森林模型混淆矩阵热力图得出如下结论
(1)在成都市空气质量测试集数据样本中,空气质量为优的样本数量为20条,有1条出现被误判的现象。
(2)在成都市空气质量测试集数据样本中,空气质量为轻度污染的样本数量为24条,有2条出现被误判的现象。
(3)在成都市空气质量测试集数据样本中,空气质量为良的样本数量为6条,出现1条被误判的现象。
(4)在成都市空气质量测试集数据样本中,空气质量为中度污染的样本数量为1条,并且没有出现被误判的现象。
(5)在成都市空气质量测试集数据样本中,空气质量为重度污染的样本数量为3条,并且没有出现被误判的现象。
(6)在成都市空气质量测试集数据样本中,空气质量为严重污染的样本数量为1条,出现1条被误判的现象。
(7)从整体上看空气质量分类随机森林模型效果俱佳,在测试集数据中值出现1条误判现象。
空气质量分类随机森林模型ROC曲线分析
通过空气质量训练集数据训练生成的空气质量分类随机森林模型ROC曲线图如下图所示。
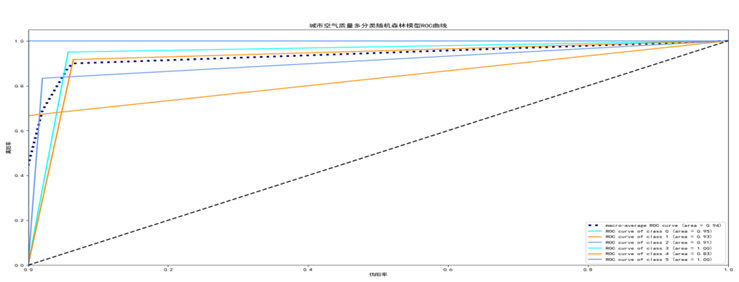
通过观察空气质量分类随机森林模型ROC曲线得出,本模型中空气质量为优的AUC值是1,空气质量为良的AUC值是1,空气质量为轻度污染的AUC值是0.9,空气质量为中度污染的AUC值是0.9,空气质量为重度污染的AUC值是1,空气质量为严重污染的AUC值是1。本模型的的平均AUC值是0.93.对于每个分类的AUC值代表各个分类ROC曲线下面的面积,其中面积占据地方越大,说明通过训练得到的分类器很好,从而证明我们训练的空气质量分类随机森林模型效俱佳。
空气质量分类随机森林预测
(1)通过划分的成都空气质量测试集数据,采用得到的空气质量分类随机森林模型对该数据进行预测,得到的结果如下:
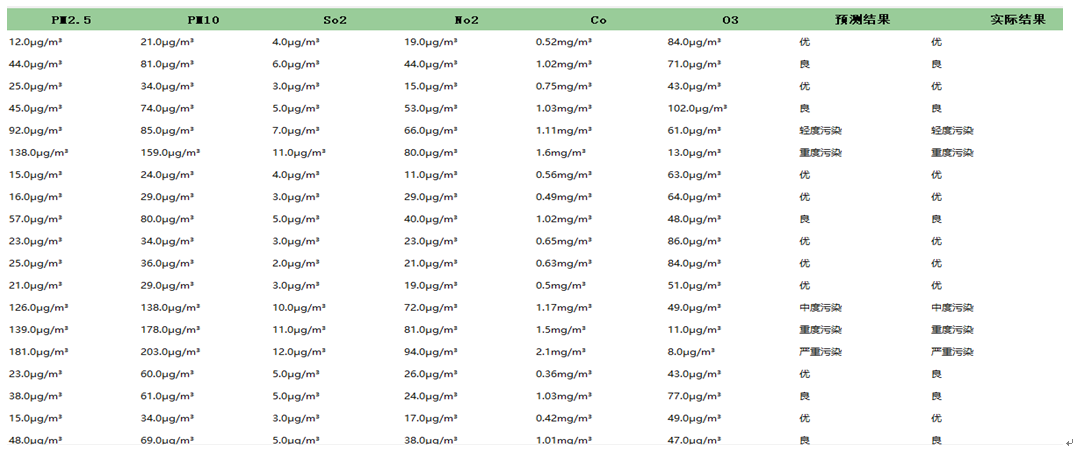
通过观察成都空气质量测试集数据的预测结果,并对比预测结果与实际结果,每组成都空气质量测试集数据的预测和实际结果大部分相一致,说明该模型的预测正确率较高。
(2)空气质量分类随机森林预测界面如下图所示,通过填写数值预测,得出最终的空气质量预测结果。

更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)