
轻松学会构建AI智能体(5)-部署向量数据库Milvus,大模型入门到精通,收藏这篇就足够了!
Milvus 提供了Lite、Standalone和Cluster 三种交付部署模式,以满足从开发测试到大规模生产的不同需求。
前文部署了Ollama,拉取了推理大模型和文本嵌入模型,今天部署向量数据库Milvus。
一,Milvus介绍
Milvus 是一款开源的、云原生的向量数据库,专为处理海量向量数据的存储、检索和管理而设计。它本质上是一个专门为 AI 应用设计的数据库,是构建 AI 应用(如 RAG、推荐系统、图像检索、语义搜索、新药发现等)的核心基础设施。
Milvus 提供了Lite、Standalone和Cluster 三种交付部署模式,以满足从开发测试到大规模生产的不同需求。
Milvus Lite (轻量版)
定位为嵌入式/轻量级单机版,专为开发测试、原型验证和边缘计算场景设计。
Milvus Standalone (单机版)
定位为基于 Docker 的单机版,是功能完整的生产级单机部署方案。性能优于 Milvus Lite,能处理中小规模的生产负载(通常千万到亿级向量)。但其扩展性受限于单台服务器的资源(CPU、内存、磁盘)。
Milvus Cluster (分布式集群版)
定位为大规模、高可用、可扩展的生产级分布式部署方案。 适用于大规模生产环境,数据量达到十亿级以上,要求高吞吐、低延迟;满足高可用性要求,业务不能接受服务中断,需要故障自动转移;能应对弹性伸缩需求,业务负载波动大,需要根据流量自动扩缩容以节省成本。
本次实践选择 Milvus Standalone (单机版) 进行部署。
二,操作步骤
通过docker compose方式,将Milvus Standalone与可视化管理工具Attu一起安装。
(1)创建并进入工作目录
mkdir -p /opt/docker-compose/milvus
cd /opt/docker-compose/milvus
(2)配置docker-compose.yml文件
在/opt/docker-compose/milvus目录中新建docker-compose.yml文件,并填写以下内容:
services:
etcd:
image: quay.io/coreos/etcd:v3.5.18
environment:
- ETCD_AUTO_COMPACTION_RETENTION=1
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_QUOTA_BACKEND_BYTES=4294967296
command: etcd -advertise-client-urls http://etcd:2379 -listen-client-urls http://0.0.0.0:2379
volumes:
- etcd-data:/etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
image: minio/minio:RELEASE.2024-09-13T20-26-02Z
command: minio server /data --console-address ":9001"
environment:
- MINIO_ROOT_USER=minioadmin
- MINIO_ROOT_PASSWORD=minioadmin
ports:
- "9000:9000"
- "9001:9001"
volumes:
- minio-data:/data
healthcheck:
test: ["CMD", "curl", "-f", "http://minio:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
milvus-standalone:
image: milvusdb/milvus:v2.5.6
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- milvus-data:/var/lib/milvus
ports:
- "19530:19530"# gRPC
- "9091:9091"# HTTP
depends_on:
- etcd
- minio
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/api/v1/health"]
interval: 30s
timeout: 20s
retries: 3
attu:
image: zilliz/attu:v2.5
environment:
MILVUS_URL: milvus-standalone:19530
HOST: 0.0.0.0
ports:
- "9002:3000"# Attu WebUI
depends_on:
- milvus-standalone
volumes:
etcd-data:
minio-data:
milvus-data:
(3)放行所有必须端口
在服务器终端中执行以下命令:
sudo firewall-cmd --permanent --add-port={9000-9002,9091,19530}/tcp && sudo firewall-cmd --reload
(4)启动容器
在服务器终端中执行以下命令:
sudo docker compose up -d
(5)验证和浏览向量数据库
在局域网电脑上执行以下命令:
curl -s http://<Milvus服务器IP>:9091/api/v1/health | jq
若返回 {“status”:“ok”},说明Milvus部署成功。
在局域网电脑上使用浏览器打开 http://<Milvus服务器IP>:9002,看到如下界面:
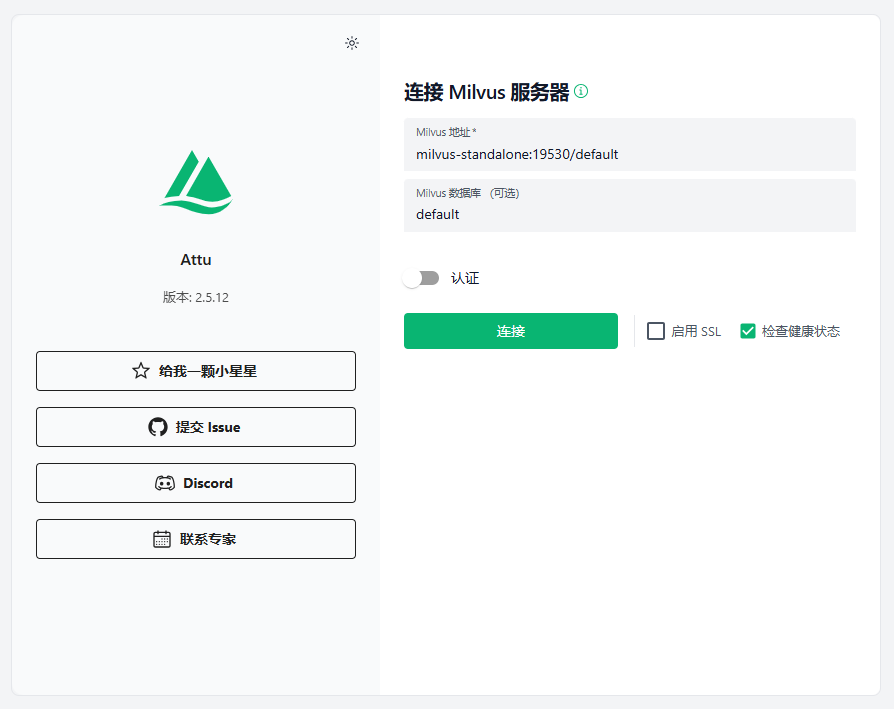
点击“连接”,进入向量数据库系统。

大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
更多推荐

 21
21 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)