
AI Agent Skill 工程化 00:从 0 到 1 搭建一套 Skills Engineering 工程体系
前言:一个你可能反复经历的场景
你总结了经验,花了两个小时,给 AI 编程助手写了一份精心打磨的 Skill——代码审查规范。
第一次用,效果惊艳:AI 像资深同事一样逐条审查,输出结构化报告,你满意地点了点头。
第二次用,换了个模型,或者换了个AI 工具,AI 突然开始"自由发挥"——跳过安全检查,出现了“幻觉”,漏掉错误处理,还顺手重构了不在范围内的代码。
你盯着屏幕,心里只有一个疑问:
明明写了规则,为什么 AI 不守规矩? AI 幻觉 ?
答案很简单:
你写了一个 Skill,但你没有搭建一套 Skills Engineering 工程体系。
一个 Skill 只是 AI 的"工作手册",你也不能想当然的认为,我写了AI就一定会按照你的要求做,其实真实实践下来之后会发现,并不是每次都OK的。
而 Skills Engineering 是让这本手册能被设计、测试、迭代、组合和团队共享的完整工程方法论。
2026 年 5 月,GitHub Trending 上同时出现了多个围绕 AI Agent Skills 的项目——从 addyosmani/agent-skills 的 24 个工程化技能包,到 obra/superpowers 的开发方法论技能链,再到 Anthropic 官方的知识工作插件集。一个清晰的信号浮出水面:
AI编程的竞争,正在从"模型强不强"转向"工作方法能不能被安装、复用、验证和团队共享"。
我认为Skills 核心重点是稳定的,可靠的输出。
Skills 搭建的工程化体系,专业化方法论也是非常重要的。
我会带你从 0 到 1,亲手搭建一套 Skills Engineering 工程体系——包括设计原则、闭环验证、测试迭代、版本管理和团队落地。
一、先搞清楚:Skills Engineering 到底在"工程"什么?
很多人把 Skill 等同于"高级提示词"。这是一个危险的误解。
一个 Skill 的结构很简洁:
Skill = 触发条件 + 执行流程 + 输出约束
但一个工程化的 Skill 体系完全不同:
Skills Engineering = 可设计的规则 + 可验证的闭环 + 可复盘的迭代 + 可组合的链路 + 可共享的资产
区别在这里:
| 层级 | 做法 | 问题 | 工程化做法 |
|---|---|---|---|
| 临时提示词 | 写在聊天框里 | 不可复用、不可审查 | 抽成 SKILL.md |
| 单个 Skill | 本地能用 | 触发不稳、边界不清 | 加验证闭环和测试样例 |
| 技能集合 | 多个 Skill 放一起 | 职责重叠、互相抢活 | 建目录规范和组合协议 |
| 团队工程体系 | 共同使用 | 经验可沉淀、质量可迭代 | Git 管理、版本发布、Bad Case 回填 |
一句话总结:
Skills Engineering 不是"让 AI 更听话",而是把团队工程经验变成 AI 稳定继承、可验证、可迭代的生产线资产。
二、设计原则:一个 Skill 只解决一个明确问题
写 Skill 最容易犯的错,是一上来就想做"大而全":
帮我审代码、写测试、做安全扫描、生成周报,顺便检查发布清单。
这会让 Skill 迅速失控——既难触发、也难测试、更难维护。
Anthropic 官方的 Skill 编写指南给出了一个核心原则:精简至上。上下文窗口是公共资源,你的 Skill 要和对话历史、系统提示、其他 Skill 的元数据共享空间。
实操层面,遵循三条铁律:
铁律 1:单一职责
spec-writer 负责把需求写成规格task-planner 负责拆任务code-reviewer 负责代码审查release-checklist 负责发布检查team-weekly-report 负责生成周报
复杂流程不是靠一个巨型 Skill 完成,而是靠多个小 Skill 配合完成。
铁律 2:渐进式披露
SKILL.md 是"目录",不是"全书"。核心指令放主文件,详细参考资料放子文件,AI 按需加载:
code-reviewer/├── SKILL.md # 核心指令(< 500 行)├── security-checks.md # 安全检查细则(按需加载)├── performance.md # 性能审查细则(按需加载)└── examples/ ├── good-review.md # 优秀审查示例 └── bad-review.md # 反面案例
铁律 3:给 AI 合适的自由度
不同类型的任务,给 AI 的约束程度不同:
| 自由度 | 适用场景 | 示例 |
|---|---|---|
| 高 (文字指令) | 多种做法都对 | 代码审查——根据上下文灵活判断 |
| 中 (伪代码/模板) | 有偏好模式 | 生成报告——用模板但可调整 |
| 低 (精确脚本) | 操作脆弱、必须一致 | 数据库迁移——必须按顺序执行 |
把 AI 想象成在走一条路:窄桥悬崖要精确护栏(低自由度),开阔平原给方向就行(高自由度)。
三、闭环验证:给 Skill 装上"刹车系统"
单个 Skill 写好了,但问题才刚开始。AI 拿到 Skill 之后最常见的行为是:一口气执行完,然后告诉你"已完成"。
至于完成得对不对?交给你验收。
这就是 Loop Engineering 要解决的问题。
普通 Skill 与 Loop 增强 Skill 的本质区别
普通 Skill:告诉 AI “做什么”。
Loop 增强 Skill:规定 AI “怎么做”——包括动手前先锚定现状、执行后逐项自验、出错时只修故障项不动已验证项。
以代码审查 Skill 为例。普通写法:
## 代码审查流程1. 分析代码结构2. 检查潜在 bug3. 建议改进4. 验证规范遵守
Loop 增强写法:
## 代码审查流程### L0:锚定(动手前必须完成)- [ ] 读取 PR 涉及的所有文件,记录现有导出和方法签名- [ ] 确认项目使用的 lint 规则和代码规范文件- [ ] 识别本次改动的影响面:哪些模块依赖了被改文件?### L1:执行(按顺序逐项完成)1. 先审接口契约(入参、出参、错误码)2. 再审业务逻辑(边界条件、异常路径)3. 最后审风格规范(命名、注释、格式)### L2:验证清单| ID | 检查项 | 期望 | 结果 | 证据 ||----|--------|------|------|------|| V-1 | 接口入参类型与文档一致 | 类型匹配 | _ | _ || V-2 | 所有 catch 块有明确错误处理 | 无空 catch | _ | _ || V-3 | 未引入新 lint 违规 | lint 通过 | _ | _ |### L3:修正规则- 只修复 FAIL 项,禁止改动已 PASS 项- 同一项连续 FAIL 2 次 → 暂停,报告人工## 退出条件| 场景 | 动作 ||------|------|| 全部 PASS | 输出审查报告 || 3 轮后仍有 FAIL | 输出未解决问题清单,交人工 |
三个关键差异:
1.动手前锚定:AI 被迫先建立对项目现状的认知,而非基于想象做改动。这一个动作就能消灭大量"AI 臆造不存在的函数"的低级错误。
2.逐项自验:AI 必须为每一项验证填上"PASS/FAIL + 证据(行号或代码片段)"。当它必须写出具体证据时,就不得不回头检查自己的输出。
3.修正边界:明确规定"只修 FAIL 项,PASS 项禁止触碰",防止 AI 修复 bug 时顺手重构已通过的代码。
四、端到端实战:从零做一个 spec-writer Skill
光讲原则太抽象,我们来完整跑一遍。
目标:做一个「需求规格化」Skill,让 AI 把模糊需求变成结构化 Spec。
Step 1:设计(铁律 1+2+3)
单一职责:只负责需求规格化,不管任务拆解和代码实现。自由度选「中」——有模板但允许调整。
---name:spec-writerdescription:"当用户给出模糊需求、产品描述或功能想法时,将其转化为结构化需求规格文档。Use when 用户提到写 Spec、需求规格化、澄清需求。"---
Step 2:加 Loop 闭环(铁律中的刹车系统)
L0 锚定:要求 AI 先读取项目已有的相关文件(接口文档、数据模型),确认现有上下文。如果信息不足,必须先列出缺失清单。
L1 执行:按模板逐步填充——目标、范围、验收标准、Open Questions。
L2 验证:逐项检查「每条验收标准是否可测试」「Open Questions 是否标注负责人」。
L3 修正:只修 FAIL 项,PASS 项禁止改动。
Step 3:写测试样例 + 跑基线
先不给 AI 任何 Skill,让它直接规格化一段模糊需求。记录它跳过了什么(通常是影响面分析和 Open Questions)。然后写最小 Skill 补这些缺口,准备正常输入、信息不足、跨模块三个样例。
Step 4:入库 + Bad Case 回填
提交 Git,写 PR 描述。第一次使用时发现 AI 把「计划中的事项」写成「已完成」,立即在 SKILL.md 补一条禁止行为:「不得将 Open Questions 中的事项标记为已确认」。下次再跑,问题消失。
这就是完整的一轮闭环:设计 → 加 Loop → 测试 → 入库 → Bad Case 回填 → 再测试。
五、测试迭代:Skill 不是写完就完了
Anthropic 官方指南给出了一个反直觉的建议:先写测试,再写 Skill。
这叫做"评估驱动开发"(Evaluation-Driven Development)。
Step 1:先跑基线
不给 AI 任何 Skill,让它直接完成目标任务。记录:
•哪些步骤它跳过了?
•哪些上下文它缺失了?
•哪些输出不合格?
Step 2:写最小 Skill
只写解决上述问题的最少内容。不要"以防万一"加一堆规则。
Step 3:准备测试样例
在 Skill 目录下建 examples/ 目录,覆盖三类场景:
code-reviewer/├── SKILL.md├── examples/│ ├── input-normal.md # 正常场景│ ├── input-missing-context.md # 信息不足│ └── input-cross-module.md # 跨模块改动└── tests/ └── checklist.md # 验证清单
正常场景样例:一个包含 3 个文件的普通 PR,期望 AI 完整走完 L0→L1→L2→退出。
信息不足场景:只给一个文件,不给依赖关系。期望 AI 在 L0 阶段主动追问,而非硬编。
跨模块场景:改动涉及前端 + 后端 + 数据库。期望 AI 识别出完整影响链。
Step 4:跑测试、收 Bad Case、写回 Skill
每次 AI 输出不符合预期,不要只在当前对话里纠正它。要按格式记录并写回 Skill:
## Bad Case 记录### 输入用户只给了一个文件路径,没有上下文。### 错误输出AI 跳过 L0 锚定,直接开始审查,臆造了不存在的依赖关系。### 期望行为L0 阶段发现上下文不足,必须先列出缺失信息并追问。### 规则修改在 SKILL.md 的 L0 阶段新增:"如果无法读取所有相关文件,暂停并输出缺失信息清单。"
这就是 Skill 迭代的核心闭环:
跑测试 → 发现 Bad Case → 定位原因 → 修改 SKILL.md → 增加样例 → 再跑一次
六、版本管理:Skill 必须像代码一样管理
团队级 Skill 一定要进版本控制。这不是可选项,是底线。
推荐目录结构
ai-skills/├── engineering/│ ├── code-reviewer/│ │ ├── SKILL.md│ │ ├── security-checks.md│ │ ├── examples/│ │ └── tests/│ ├── spec-writer/│ ├── task-planner/│ └── release-checklist/├── product/│ ├── requirement-clarifier/│ └── user-story-writer/└── operation/ ├── team-weekly-report/ └── incident-summary/
按工具要求映射到 .cursor/rules/、.claude/skills/ 等目录。
每次修改 Skill 的 PR 必须说明
## 背景本次修改用于解决代码审查中"跳过安全检查"的问题。## 修改内容- 在 SKILL.md 的 L1 阶段新增安全检查步骤- 新增 input-security-sensitive.md 样例- 更新测试清单## 验证- [ ] 普通 PR 审查流程不受影响- [ ] 涉及 auth/crypto 的 PR 会触发安全检查- [ ] 信息不足时会先追问
这样做的好处是:团队可以审查 AI 行为的变化。 如果 description 改得太宽,可能导致误触发;如果输出规约改得太窄,可能让真实任务无法完成。Skill 的变更需要像代码一样被看见。
七、技能组合:让多个 Skill 协作,而非互相抢活
当 Skill 变多后,组合问题出现了。
一个完整研发任务可能需要:
需求澄清 → 任务拆解 → 影响面勘探 → 增量实现 → 代码审查 → 发布检查 → 周报沉淀
组合原则
原则 1:description 写清边界,杜绝职责重叠。
不要让 code-reviewer 也负责写发布计划。边界越清晰,AI 越不容易混用。
原则 2:用上层指令串联,而非硬编码编排。
请按以下流程处理:1. 先用 spec-writer 梳理需求和缺口2. 再用 task-planner 拆成可验证任务3. 实现完成后,用 code-reviewer 做风险检查4. 最后用 team-weekly-report 生成本周进展摘要
原则 3:简单任务不要过度编排。
改个文案、加个按钮,直接用一个 Skill 搞定。不是所有任务都需要走完整个技能链。
addyosmani/agent-skills 项目用 7 个斜杠命令覆盖了完整开发生命周期:
| 命令 | 阶段 | 作用 |
|---|---|---|
/spec |
需求规格化 | 先把需求写清楚 |
/plan |
任务拆解 | 拆成小步可验证任务 |
/build |
增量实现 | 一块一块写代码 |
/test |
测试证明 | 用测试证明功能正确 |
/review |
代码审查 | 合码前质量检查 |
/code-simplify |
代码简化 | 降低复杂度 |
/ship |
发布检查 | 上线前确认清单 |
核心价值不是命令本身,而是给了 AI 一个"阶段感"——写代码不是唯一动作,澄清、拆解、验证、审查同样重要。
八、团队如何落地:30 天路线图 + 新人三步上手
如果你想在团队里推 Skills Engineering,不建议一开始就铺大摊子。
按 30 天分 4 周推进:
第 1 周:选 3 个高频场景
优先选重复、明确、产出可检查的任务:
•代码审查 / 测试计划类
•发布检查 / 故障总结类
•周报 / 复盘 / 汇报类
不要一开始就做"全流程研发助手"。范围太大,反馈太慢。
第 2 周:每个场景做一个最小 Skill
每个 Skill 只需要先包含:
•description(具体到场景)
•使用场景
•L0 锚定步骤
•执行流程
•L2 验证清单
•禁止行为
•至少 2 个测试样例
第一版的目标不是完美,而是让团队能开始用。
第 3 周:收集 Bad Case 并补样例
要求团队成员遇到问题时,不要只说"AI 又乱写了",而是按格式记录:
## Bad Case- 输入:用户原始输入- 错误输出:AI 哪里不符合预期- 期望行为:下次应该怎么做- 规则修改建议:应该加到 SKILL.md 的哪一段
这一周的重点是让团队形成"问题回填"的习惯。
第 4 周:建立 Review 和发布规则
•修改必须走 PR
•每个 Skill 有 owner
•每次修改至少跑 2 个样例
•每月清理一次废弃 Skill
•高频 Skill 写入新人 onboarding 文档
到这里,团队就从"会写几个提示词"升级到了"有一套可维护的 AI 工程资产"。
附:新人三步上手路径
不要让新人一上来就研究全部 Skill。更好的路径是:
第一步:直接用。 给他 3 个高频 Skill(代码审查、发布检查、周报生成),先感受收益。
第二步:改一条规则。 让他补充一个真实 Bad Case,理解 Skill 不是黑盒,而是可以被审查和修改的工作协议。
第三步:写一个小 Skill。 让他为自己的高频任务写一个单一职责 Skill,参与共建。
先让他感受到收益,再理解原理,最后参与共建——比"发一份几十页文档"有效得多。
九、发布前自检清单
在把一个 Skill 推给团队前,至少检查这 10 项:
•[ ] description 是否具体到场景,而非泛泛描述能力?
•[ ] 是否包含 L0 锚定步骤(动手前先认知现状)?
•[ ] 是否定义了 L2 验证清单(逐项 PASS/FAIL + 证据)?
•[ ] 是否说明了信息不足时应该追问?
•[ ] 是否定义了稳定输出格式?
•[ ] 是否写了禁止行为?
•[ ] 是否至少有 2 个输入样例(含一个异常场景)?
•[ ] 是否有 Bad Case 记录入口?
•[ ] 是否进了 Git?
•[ ] 是否有人负责维护?
10 项能过,哪怕还不完美,也已经具备团队试运行的条件。
总结:一张图记住 Skills Engineering 工程体系
架构图(Mermaid)
怎么读:自上而下五层堆叠——先设计 Skill,再套 Loop 闭环,再 eval 迭代,再 Git/版本资产化,最后多 Skill 组合;最底是 30 天落地节奏。
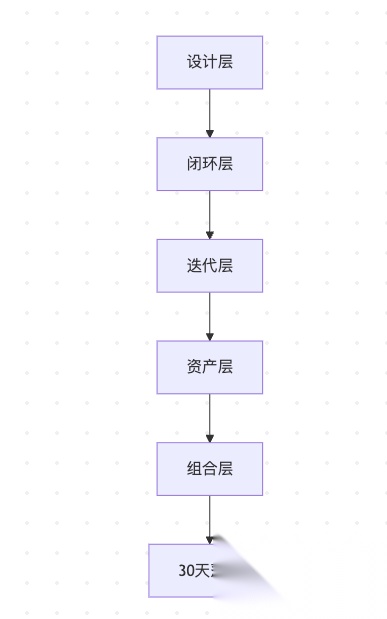
图注(各层要点)
| 层级 | 核心内容 |
|---|---|
| 设计层 | 单一职责 · 渐进披露 · 自由度匹配 |
| 闭环层 | Loop Engineering:L0 锚定 → L1 执行 → L2 验证 → L3 修正 → 退出条件 |
| 迭代层 | 评估驱动 → 最小 Skill → 测试样例 → Bad Case 回填 |
| 资产层 | Git 管理 · PR 审查 · 版本发布 · Owner 制度 |
| 组合层 | 边界清晰 · 上层串联 · 简单任务不过度编排 |
| 30 天落地 | 选场景 → 最小 Skill → 收 Bad Case → 建 Review 规则 |
最后的话
AI 工具会不断变化,不断变强大。
今天是 Codex,Cursor,明天可能是 Claude Code、Gemini CLI 或更新的 Agent 平台。
但有一件事不会变:
团队需要把工程经验沉淀成可复用、可验证、可迭代的资产。
过去,这些经验藏在老员工脑子里,散在代码审查评论里,或者埋在某次事故复盘文档里。
Skills Engineering 的出现,让这些经验可以变成 AI 每次执行任务时都会遵循的工作协议。
所以,不要把 Skill 当作"高级提示词收藏夹"。
更好的理解是:
Skill 是团队工程经验暴露给 AI Agent 的接口。Skills Engineering 是设计、测试、迭代、组合和管理这些接口的工程方法论。
接口要清晰,闭环要可验证,版本要可追踪,组合要可控。做到这些,AI 才不只是一个单兵工具,而会成为团队生产线的一部分。
你可以从今天这个最小动作开始:
找一个你每周都会重复三次以上的任务,把它写成一个 SKILL.md,加上 L0 锚定和 L2 验证清单,补两个测试样例,提交到 Git,让同事试用一次。
这就是 Skills Engineering 的第一步。
你在用 AI 编程时,写过哪些"用了几次就废"的 Skill?
踩过哪些"规则写了但 AI 不守"的坑?
把经历进行总结,我们一起把它变成可复用的团队资产——毕竟,每一个 Bad Case,都是下一个好 Skill 的原材料。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 5
5 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)