
工程化 AI 编程流程:从会回答到能交付:规约、Skill、验证、可观测和多 Agent 接力
2026 年了,几乎每个团队都在说自己“用了 AI 编程”。

打开 Claude、Cursor 或 Copilot,输入一句“帮我写个XXX接口”,30 秒,AGENT输出代码,单测,编译,git add,git commit,git push ,然后觉得自己已经站在生产力革命的浪尖。
但如果团队的 AI 编程流程只到这里,那很遗憾:你可能还停留在“把 AI 当聊天框”的阶段。
真正的杠杆,不是让 AI 更聪明,而是让 AI 更可信。可信的意思很朴素:行为可预测、输出可验证、失败可观测。
这篇文章不讲玄学 prompt,也不讲最近流行的loop,也不把 AI 包装成“实习生同事自动全干”。
我想讲的是一套更接地气的工程化方法:如何把 Claude Code 从一个会聊天、会补全、也会一本正经犯错的工具,变成一个有规约、有工具、有验证、有审计的工程执行者。
这套方法也是来自我真实仓储/医药物流系统的实践。它背后的目标只有一个:不要让 AI 看起来很努力,实际上把团队带进坑里。
01 失败的 AI 编程,通常不是败在模型不够强
我见过几种非常典型的失败方式。
第一种,幻觉污染。
你问 Claude:“帮我看一下 ASN 到货通知表有哪些字段。”它很自信地说:ASN_ID、ASN_NBR、ASN_STATUS。听起来像那么回事,甚至命名还挺标准。问题是,你们系统里根本没有 ASN_NBR。
这不是 Claude 坏,也不是它故意骗你。它只是在用通用世界里的概率补全你们公司内部系统的事实。训练数据里 ASN 单号可能叫 ASN_NBR,也可能叫 ASN_NO,但它不知道你的系统到底叫什么。
第二种,写完不验,验完不挡。
AI 写了 UPDATE/INSERT等等,跑了一下“成功”,于是上线。直到生产环境告诉你:成功运行和正确运行,是两个平行宇宙。
更隐蔽的是:编译通过、CI 变绿、功能看似能跑,一个月后某个边界 case出问题,没人记得当初为什么这么写,也找不到验证证据,更要命的是AI写的注释你完全看不懂,也不知道他在讲什么,再加上他改的东西散落在各个代码文件中,你更没办法知道他为什么这么写。
第三种,文档腐烂。
CLAUDE.md 里写着三个月前的旧路径、旧 API、旧表结构。AI 每次会话都认真加载它,然后认真按照过时信息写错代码。这种场面很荒诞:你以为在给 AI 喂知识,其实在给它投喂陈年误导。
这些失败有一个共同根因:
我们把 LLM 当成“另一个程序员”在管理,而不是当成“一个会幻觉、需要硬约束、行为必须可审计的执行器”在工程化。
所以工程化对于vibe coding来说很重要,要不然开发开发电子宠物,番茄钟这些,获取一些成就感就可以了,千万不要把AI编程运用到实际工作中,否则你会给你原本就屎山一样的项目雪上加霜。
以下我分享一下我对于AI编程工程化的一些理解和方案分享:
02 工程化 AI 编程的 7 层架构
如果只写一份 CLAUDE.md,再贴几段需求文档,就期待 AI 自己把流程补齐,这基本等于把方向盘交给一个很热情但没驾照的人。
我更推荐把 AI 编程基础设施拆成 7 层。

从下往上看:
| 层级 | 作用 | 典型做法 |
| L1 规约层 | 先规定行为边界 | 全局 CLAUDE.md + 项目级 CLAUDE.md |
| L2 上下文层 | 提供真实项目事实 | 表结构、法规、接口、设计规范、本地知识库 |
| L3 工具层 | 把能力封装成 Skill | domain skill、superpowers、只读工具、受控命令 |
| L4 验证层 | 让“完成”必须有证据 | Gate Function、测试、硬规则、合规条款 |
| L5 可观测层 | 知道 AI 做过什么 | hook、skill 调用统计、审计日志 |
| L6 自动化层 | 把验证接进流程 | pre-commit、CI、Stop hook |
| L7 反馈层 | 跨会话沉淀偏好 | memory、失败复盘、团队规则迭代 |
很多团队只做了 L1 的一半,写了几句“请遵守代码规范”;再做了 L2 的一半,把文档贴给 AI。然后希望 AI 自动补完 L3 到 L7。
这就是“AI 看起来很忙,团队却越来越慌”的根源。
下面是我的CLAUDE.md中的部分规则(关于SQL部分的)分享:
## 🚨 硬性规则(违反 = 代码错误)
1. **严禁猜测字段名** — 遇不确定字段先查 `/root/数据表结构.md` 或向用户确认
2. **XX表命名** — Oracle 端XX业务表以 `XX_` 开头,新业务表以 `XX_` 开头
3. **不修改 XXXX 原生表** — 只新增表或扩展(ALTER TABLE)
4. **Target_DB 必须标注** — ORACLE 用 `NVL/SYSDATE/ROWNUM`,PG 用 `COALESCE/NOW()/LIMIT`
5. **审计字段五件套** — `CREATE_DATE_TIME`, `CREATE_USER_ID`, `MOD_DATE_TIME`, `MOD_USER_ID`, `WM_VERSION_ID`
6. **主键用 SEQUENCE** — 每表一个 SEQ,不依赖自增
7. **Oracle 整数除法** — `1/3` = 0,必须写 `1.0/3`
8. **el-table-column label 用中文业务含义** — 禁用 DB 字段名(如 `WHSE_CODE` → `仓库编码`)
9. **禁止 `SELECT *`** — 必须明确列出字段(含 COUNT/INSERT-SELECT 子查询)
10. **禁止硬编码业务状态码** — 使用常量或参数(如 `ASNStatus.OPEN = 10` 而非裸写 `10`)
11. **字符串连接用 `||`** — Oracle / PG 通用;多表 JOIN 必须用表别名前缀(如 `XXX.XX_XXX_ID`)
12. **绑定变量** — MyBatis 用 `#{param}`,JDBC/PL-SQL 用 `:param`;严禁字符串拼接 SQL
13. **DDL 注释 + 索引** — 每个字段 `COMMENT ON COLUMN ...`,常用查询字段建索引;
03 superpowers:不是让 AI 更聪明,是让 AI 有纪律
很多人装了 Claude Code,但只用聊天框。这有点像买了厨房,天天只用电热水壶泡面。
真正有价值的是把 Skill 体系装起来,尤其是类似 superpowers 这种覆盖完整工程流程的套件。
它不是为了“多几个魔法按钮”,而是为了让 AI 在不同阶段自动进入正确工作模式,覆盖从"接到需求"到"代码上线"的完整工程纪律。
我最常用的 5 个 Skill 是:
| Skill | 作用 | 触发时机 |
using-superpowers |
每次任务开始先检查适用 Skill | 每次对话 |
brainstorming |
写代码前澄清需求和边界 | 新需求、新方案、新重构 |
writing-plans |
把方案拆成可执行任务 | 方案确认后 |
test-driven-development |
红、绿、重构循环 | 写代码时 |
verification-before-completion |
完成前强制验证 | 准备说“完成”前 |
一个完整的协同流程:
你: "我要重构这个通用报表工具"
↓
Claude 强制检查: brainstorming 适用吗?
↓ 是 (任何创造性工作)
brainstorming 引导 Claude 反问你 5 个关键问题:
- 谁会用? (质量管理员 vs 仓管 vs 总部)
- 数据源? (生产库 vs 报表库 vs 数仓)
- 输出格式? (Excel vs PDF vs 邮件)
- 触发时机? (实时 vs 定时 vs 手动)
- 不做什么? (反向边界)
↓
需求澄清完毕
↓
writing-plans: 拆任务、标依赖、写验收标准
↓
TDD: 每个任务先写测试再写实现
↓
verification-before-completion: 跑完验证才敢说"完成"
优先级铁律(不是建议,是法律)
1. 用户显式指令 (CLAUDE.md / 直接请求) ← 最高
2. Superpowers skills ← 覆盖系统默认
3. 系统默认 prompt ← 最低
---除此之外的关键原则
1. 先问再做 — 不确定的事情先确认
2. 大道至简 — 不写过度设计的代码
3. 精准手术 — 只改需要的部分
4. 诚实汇报 — 成功附证据,失败附错误
这听起来不够炫,但很有效。工程里很多事故不是因为没人能写代码,而是因为太早开始写代码。
04 一个真实案例:5 天把通用报表工具拉回正轨
这个案例的起点并不体面。
去年年底,我们启动了一个通用报表工具项目。按计划,1产品1测试2开发,设计到研发到UAT到用户使用,8周时间上线。
然而大半年过去了,它依然没有真正上线。
准确地说,是"一直上不了线"。
每次提测都有 20 多个 BUG:字段映射错、查询结果错、性能不达标、UI 格式不符合需求。
每次紧急修完一批、新版本再提测,又冒出新一批,反复循环、永远到不了"上线"那道门槛
业务等不及,项目时间不等人,再不上线,现场项目可以直接宣布延期了。
问题在哪?
项目周期无限拖延:原定 8 周的开发,6 个月还在改 BUG
BUG 多到没人愿意修:测试阶段累积的问题,开发团队说"代码不是我写的",“没有时间”。
设计方向与开发方向相差太大:产品文档里写的是支持多数据源查看,开发出来的版本是纯单一数据源,支持PDF,EXCEL等导出格式,最后开发出来只有EXCEL。
所有人都知道有问题,但没人改:技术团队说"忙",业务团队说"先用原来的吧",最后就这么僵着。
而我是产品经理。
按理说,写代码不是我的活。
但现有资源已经不足以支撑让这个功能在合适的时间交付到现场。
我决定自己推进重构。
但我很清楚,如果只是打开 Claude 说“帮我重构这个报表工具”,结果大概率是另一个 6 个月灾难。
AI 最擅长的是“看起来完成了你的要求”,而不是天然理解你的业务边界。
所以我没有让 Claude 直接写代码,而是做了一次多 Agent 文档接力。
下面我就把完整的工程化链路拆给你看。
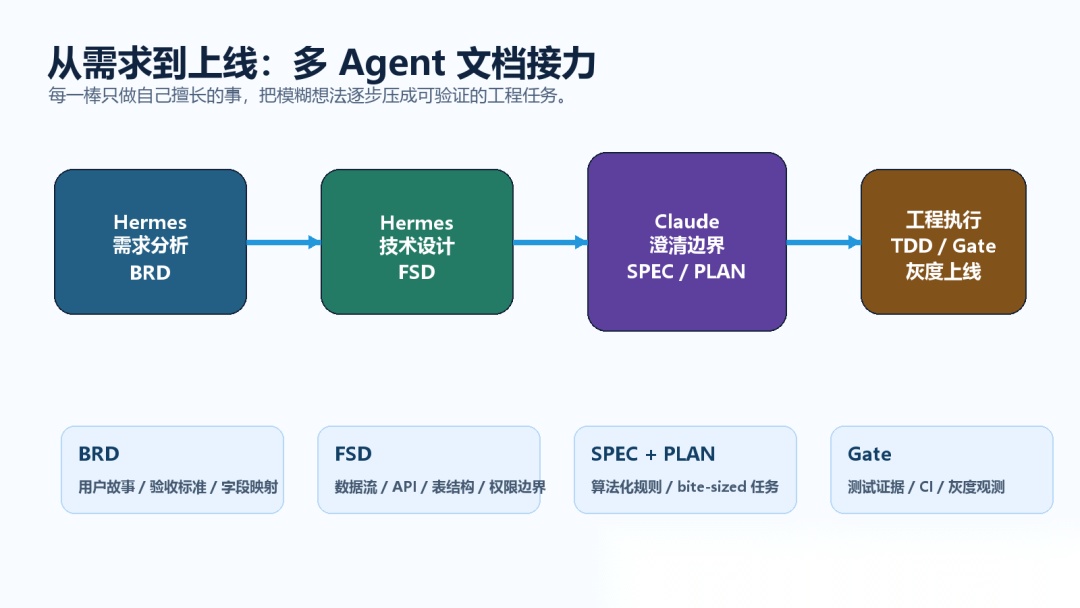
第一棒,Hermes 需求 Agent 调用 wms-requirement-analysis,产出 BRD。
它不写代码,只负责把背景、痛点、用户故事、字段映射、GSP 合规条款和验收标准整理清楚。例如:仓管要在 30 秒内拿到 Excel,邮件成功率要达到 99.5%,批次台账必须包含质量状态、效期、审计字段。
输出BRD文档(缩略):
## BRD - 通用报表工具 v0.1
### 1. 业务背景
各业务部门(仓管、质量、运营、采购)每月要从系统导出各种业务清单
(库存台账、出入库流水、批次台账、质量台账…),
目前是用 SQL 现拼、手工补字段,**每个部门一份、字段对不齐、口径不统一、出错率高**。
需要一个统一的报表工具:**模板可配置、字段可勾选、过滤可复用、定时可调度**。
### 2. 用户故事
- US-01: 仓管点击"生成本月库存台账",30 秒内拿到 Excel
- US-02: 每月 1 号 9:00 自动邮件发送给仓管 / 运营 / 质量
- US-03: 历史报表可在系统内查询 12 个月
- US-04: 运营可自助勾选字段 + 设置过滤条件,**不用找开发改 SQL**
### 3. 验收标准
- AC-01: 1 万行数据下,Excel 生成 ≤ 30 秒
- AC-02: 邮件发送成功率 ≥ 99.5%
- AC-03: GSP 审计字段全部就位(详见字段映射表)
- AC-04: 用户可按仓库 / 业务类型筛选
- AC-05: 失败任务有重试 + 告警
- AC-06: **至少支持 5 类常用报表模板**(库存 / 出入库 / 批次 / 质量 / 综合)
### 4. 字段映射(以"批次台账"为例,含 GSP 条款)
| 业务字段 | 数据库字段 | GSP 条款 |
|---------|-----------|---------|
| 仓库编码 | WHSE_CODE | 05901 数据授权 |
| 批号 | BATCH_NBR | 00201 药品追溯 |
| 剩余天数 | DAYS_TO_EXPIRE | 第八十五条 效期锁定 |
| 质量状态 | PROD_STAT | 第八十七条 质量锁定 |
| 数据更新时间 | LAST_UPDATE_TS | 04001 更改留痕 |
第二棒,Hermes 调用 wms-design,产出 FSD。
这一步把需求翻译成技术设计:数据流、API、模板元数据表、视图、索引、权限边界、只读原则。比如报表工具只读,不允许 UPDATE/DELETE;Excel 列由模板配置决定;过滤条件必须走白名单。
输出FSD文档(缩略):
## FSD - 通用报表工具 v0.1
### 1. 数据流图
报表库 v_report.* 视图族 (T-1 同步,每个报表模板对应一个视图)
↓
report-facade / POST /report/generate
↓
report-service (通用 Excel 引擎,模板驱动)
↓
邮件发送 (共享 SMTP) / 文件下载
### 2. API 设计
POST /api/report/generate
Request: {
templateId: string, // 报表模板 ID
whseCodes: [string], // 仓库范围
dateRange: { start, end }, // 业务日期范围
filters: { ... } // 模板特定过滤
}
Response: { taskId, downloadUrl, generatedAt, rowCount, templateId }
### 3. 模板元数据表(核心抽象)
CREATE TABLE rpt_template (
TEMPLATE_ID VARCHAR2(50) NOT NULL,
TEMPLATE_NAME VARCHAR2(200) NOT NULL,
SOURCE_VIEW VARCHAR2(200) NOT NULL, -- e.g. v_report.batch_view
COLUMN_CONFIG CLOB NOT NULL, -- JSON:字段勾选、排序、格式
DEFAULT_FILTERS CLOB, -- JSON:默认过滤条件
AUDIT FIELDS 五件套
);
### 4. 视图样例(以批次台账为例)
CREATE OR REPLACE VIEW v_report.batch_view AS
SELECT
b.WHSE_CODE,
b.BATCH_NBR,
b.SKU_NAME,
b.EXPIRE_DATE,
(b.EXPIRE_DATE - SYSDATE) AS DAYS_TO_EXPIRE,
b.PROD_STAT,
b.LAST_UPDATE_TS,
b.CREATE_DATE_TIME,
b.CREATE_USER_ID,
b.MOD_DATE_TIME,
b.MOD_USER_ID
FROM batch b
WHERE b.is_deleted = 'N';
CREATE INDEX idx_batch_whse ON batch(WHSE_CODE);
CREATE INDEX idx_batch_expire ON batch(EXPIRE_DATE);
第三棒,Claude 接手,但第一件事仍然不是写代码。
它必须先通过 brainstorming 反问 5 个边界问题:
Claude (brainstorming skill 驱动):
BRD/FSD 已收到,但动手前我需要确认 5 个边界问题,
否则实现到一半发现返工就太晚了:
1. 用户范围:FSD 写的是"仓管 + 运营 + 质量",那总部 BI、
上游供应商需要看吗?是否要按角色拆分 Excel sheet?
2. 数据时效:报表库是 T-1 同步,那"今天新增的业务数据"
怎么办?本月报表是包含还是排除?
3. 输出格式:Excel + 邮件都已写,但需要 PDF 备份吗?
邮件正文要不要内嵌一张统计图?
4. 触发时机:cron 每月 1 号 9:00 — 如果 1 号是周日怎么办?
顺延到周一?还是提前到上个月最后一个工作日?
5. 反向边界:明确不做什么
- ❌ 不做实时库存看板(已在 BRD 排除)
- ❌ 不做趋势预测
- ❌ 不做供应商评分
- ❌ 不支持修改字段(只读报表)
- ❌ 不做移动端
用户的回答(关键决策):
1. 仅质量管理员 + 供应商,其他人走别的报表
2. T-1 数据,本月报表就是月末快照
3. 不要 PDF,纯 Excel;邮件正文只要一行统计
4. 顺延到 1 号之后第一个工作日
5. 反向边界全部接受
这一步节省了至少 5 天的返工。 文档里"看似清楚"的事情,强制问一遍就能找出 3-5 个没说清的灰色地带。
第四棒,Claude 用 writing-plans 产出 SPEC 和 PLAN。
SPEC 把业务规则算法化,比如 DAYS_TO_EXPIRE 怎么算,红黄蓝效期阈值如何判断,哪些字段必须写入 GSP 审计。PLAN 则把工作拆成 bite-sized 任务,每个任务都有单测点、成功标准、依赖关系和“不懂就问”触发器。
SPEC:FSD 的 Claude 视角展开(缩略):
## SPEC - 通用报表工具 v0.1
### 1. 输入(精确化)
- templateId: 必填,决定走哪个视图 + 哪些字段
- whseCodes: 用户权限内的仓库列表(来自用户上下文)
- dateRange: { start, end },根据 templateId 映射到视图的具体日期列
- filters: 模板允许的过滤字段(运行时校验,防 SQL 注入)
### 2. 输出(精确化)
Excel 列:**由 templateId 对应的 COLUMN_CONFIG 动态决定**
示例:批次台账模板 TPL_BATCH 渲染出
A. WHSE_CODE (VARCHAR)
B. BATCH_NBR (VARCHAR, 加超链接 → 批次详情)
C. SKU_NAME (VARCHAR)
D. EXPIRE_DATE (DATE, YYYY-MM-DD)
E. DAYS_TO_EXPIRE (NUMBER, 条件格式:红/黄/蓝)
F. COLOR_LEVEL ('RED' / 'YELLOW' / 'BLUE')
G. PROD_STAT (VARCHAR)
H. LAST_UPDATE_TS (TIMESTAMP)
### 3. 业务规则(算法化)
DAYS_TO_EXPIRE = EXPIRE_DATE - SYSDATE
COLOR_LEVEL(仅批次台账模板生效):
DAYS <= 30 → 'RED'
30 < DAYS <= 90 → 'YELLOW'
90 < DAYS <= 180 → 'BLUE'
DAYS > 180 → 不着色
### 4. GSP 字段映射(写到代码层)
每个 SELECT 必须包含 LAST_UPDATE_TS。
模板配置变更必须写入 rpt_template_audit 表(与 rpt_template 一对多)。
### 5. 反向边界
- ❌ 不做任何 UPDATE/DELETE(报表工具本身只读)
- ❌ 不返回超过 10000 行(性能护栏)
- ❌ 不支持跨年聚合查询(仅本年内)
- ❌ 不在报表工具里写实际业务单据(业务系统自己的活)
PLAN:bite-sized 任务清单
这是开发期的"剧本"。每个任务都标注:单测点 + 成功标准 + 下一步前置条件。
## PLAN - 通用报表工具 v0.1
### Phase 1: 数据层 + 模板元数据(Day 2)
T1.1 [建视图] v_report.batch_view
└─ 单测点: DESC view 能列出全部 11 个字段(含审计五件套),每个字段有 COMMENT ON
└─ 成功标准:
[ ] mvn test 通过
[ ] DESC 命令实际输出与 SPEC §2 一致
[ ] GSP 字段 (LAST_UPDATE_TS) 在 SELECT 列表中
└─ 下一步前置: 视图创建 + 单测 100% PASS
└─ 不懂就问触发:
· 字段名与 SPEC §2 不一致 → 立刻停下问
· 表不存在 → 立刻停下问 DBA,不擅自新建
└─ 依赖: 无
T1.2 [建元数据表] rpt_template + rpt_template_audit
└─ 单测点: 模拟一次 INSERT/UPDATE,rpt_template_audit 多 1 行
└─ 成功标准:
[ ] 单测覆盖率 100%
[ ] 实际 INSERT 后 rpt_template_audit 有新行
└─ 下一步前置: T1.1 完成 + 元数据表测试通过
└─ 依赖: T1.1
T1.3 [初始化 5 个基础模板] 库存/出入库/批次/质量/综合
└─ 单测点: 每个模板的 COLUMN_CONFIG JSON schema 校验通过
└─ 成功标准:
[ ] 5 个模板全部能 SELECT 出非空数据
[ ] JSON schema 拒绝非法配置
└─ 下一步前置: T1.2 完成
└─ 依赖: T1.2
### Phase 2: 后端 API(Day 3)
T2.1 [API] POST /api/report/generate
└─ 单测点:
· 模板路由(templateId → 正确视图 + 字段)
· 权限过滤(whseCodes 不能越权)
· 过滤条件白名单(防 SQL 注入)
└─ 成功标准:
[ ] 单测覆盖率 ≥ 80%
[ ] swagger 可调用,返回 Excel 文件流
[ ] 5 个模板全部能正常生成
[ ] 1 万行数据生成 ≤ 30 秒(性能 AC)
└─ 下一步前置: T2.1 单测全部 PASS + 集成测试通过
└─ 不懂就问触发:
· Excel 引擎选型不确定(POI vs EasyExcel vs 模板引擎)→ 问架构师
· 性能压测不达标 → 不擅自调优,问后端负责人
└─ 依赖: T1.1, T1.2, T1.3
T2.2 [Cron 任务] 每月首个工作日 9:00 触发(按模板逐个生成)
└─ 单测点: cron 表达式解析正确
└─ 成功标准:
[ ] 手动调整系统时间能验证 cron 行为
[ ] 失败重试 3 次后告警
└─ 下一步前置: T2.1 完成
└─ 依赖: T2.1
### Phase 3: 前端(Day 4)
T3.1 [页面] 报表触发 + 仓库筛选 + 下载
└─ 单测点:
· 仓库多选组件(最多 10 个仓库)
· 触发按钮禁用条件(无仓库权限)
└─ 成功标准:
[ ] npm run build 通过
[ ] playwright 集成测试通过(触发→下载完整流程)
[ ] 移动端浏览器不报错(即使不做移动端适配)
└─ 下一步前置: T2.1 后端可联调
└─ 依赖: T2.1
### Phase 4: 部署(Day 5)
T4.1 [CI] 含 verification-before-completion hook
T4.2 [灰度] 测试库 1 周观察期
└─ 成功标准:
[ ] 灰度期间零 P0 故障
[ ] 监控告警就位(生成耗时、邮件成功率)
### 风险与依赖
- ⚠ 报表库权限(找 DBA)—— 提前并行
- ⚠ 共享 SMTP 限流 → T2.2 实施前确认配额
最后才进入开发。
不过开发期也硬规范:5 条不可绕过的纪律。
无论 PLAN 写得多好,执行时偷懒就废了。我们定了5 条硬规范,每条都体现在 CLAUDE.md 中:
规范 1:每个任务必须有单测(先红后绿)
// 红:先写测试(PLAN T2.1 已定义)
@Test
void shouldColorRedWhenDaysToExpireIs15() {
Batch batch = Batch.builder()
.batchNbr("B-202406-001")
.expireDate(LocalDate.now().plusDays(15))
.prodStat("QUALIFIED")
.isRecalled(false)
.build();
ReportRow row = mapper.toReportRow(batch);
assertThat(row.getColorLevel()).isEqualTo("RED");
}
// 绿:实现到测试通过
public ReportRow toReportRow(Batch b) {
long days = ChronoUnit.DAYS.between(LocalDate.now(), b.getExpireDate());
if (b.getIsRecalled()) return null;
String color;
if (days <= 30) color = "RED";
else if (days <= 90) color = "YELLOW";
else if (days <= 180) color = "BLUE";
else return null;
return new ReportRow(b.getBatchNbr(), color, days);
}
规范 2:任务完成 = 单测通过 + 集成验证 + 文档同步
不是"代码能编译"就叫完成。每个任务完成的硬定义:
[ ] 单测覆盖率 ≥ 80%
[ ] 集成测试通过
[ ] Gate Function 验证 (IDENTIFY→RUN→READ→VERIFY→THEN)
[ ] SPEC/PLAN 文档同步更新(如有偏差)
[ ] 下一步的前置条件 100% 满足
规范 3:不懂就问,4 个触发器
LLM 最擅长的事是"自信地编"。我们设了 4 个不懂就问触发器,一旦命中,必须停下问用户:
| 触发器 | 必须问的内容 |
|---|---|
| 字段名不确定 | 查不到知识库,或与 SPEC §2 不一致 → 问 |
| 业务规则有歧义 | "阈值"是 30/90/180 天?用户没明确 → 问 |
| API 设计有疑问 | RESTful 还是 RPC?路径参数还是 query?→ 问架构师 |
| 测试不通过 3 次 | 不再"换一种写法",输出完整错误报告 → 等用户决策 |
规范 4:禁止"应该"
Gate Function 把“应该可以了”关在门外。
以下用语在 PR review 中直接打回:
| ❌ 禁止 | ✅ 应该 |
|---|---|
| “应该可以了” | “已通过 X 测试,输出 Y” |
| “大概没问题” | “覆盖率 87%,diff 如下” |
| “看起来是对的” | “已对比 SPEC §2,9/9 字段匹配” |
| “我先这样写,回头再改” | “已写入 TODO 注释,对应 JIRA-1234” |
| “感觉这里需要” | “SPEC §3 规则 4 要求 X” |
说"应该" = 说"我没验证" = 直接打回。
规范 5:下一步的前置条件 = 100% 满足
Phase 1 → Phase 2:
T1.1 视图创建 ✓
T1.2 触发器测试 ✓
↓
Phase 2 才能开始
Phase 2 → Phase 3:
T2.1 API 单测 ✓
T2.1 API 集成 ✓
T2.2 cron 测试 ✓
↓
Phase 3 才能开始
结果是:5 天完成重构,灰度 1 周零 P0,返工次数为 0。
重点不是“AI 写得快”。
重点是:AI 每一步都被规约、文档、测试、验收标准和工程门禁夹住了。它可以快,但不能乱快。
不允许"差不多就跳到下一步"。
05 CLAUDE.md 不是文档,是 AI 的运行时配置
很多团队把 CLAUDE.md 当成团队 wiki,这个理解太轻了。
它更像 AI 的运行时配置。每次会话开始,Claude 都会把它加载进上下文。你写得模糊,它就模糊执行;你写错路径,它就认真地按错路径工作。
我建议遵守 4 条原则:
第一,能写成反例的,不要只写抽象规则。
不要只写:请使用正确 SQL。
应该写:
Oracle 整数除法中 1/3 = 0,比例计算必须写 1.0/3。
Oracle 表别名不能使用 AS。
Target_DB 必须明确标注。
第二,硬规则要编号。
比如 13 条硬性规则从 1 到 13 编号。任何一次违规复盘,都能定位到具体规则,而不是在“加强规范意识”里打转。
第三,领域知识要完整。
不要只写 ASN。LPN 状态码、序列号流转、质量状态、效期规则,这些都可能是同等重要的上下文。AI 不知道你没写的是“省略”,还是“不存在”。
第四,路径必须当下可用。
项目路径不要凭记忆写,应该以 find / ls 实际结果为准。过期路径比没有路径更危险,因为 AI 会把错的当对的学。
一句话:CLAUDE.md比代码更需要 review。
06 可观测层:你得知道 AI 到底用了哪些 Skill
很多团队最盲的地方是:装了一堆 Skill,但不知道哪些真的被调用,哪些从来没人用,哪些名字拼错了,哪些正在制造噪声。
解决办法并不复杂:给 Claude Code 的 PostToolUse 加一个 hook,把 Skill 调用记录下来。
核心逻辑可以很轻:
payload = json.loads(sys.stdin.read())
if payload.get("tool_name") != "Skill":
return 0
skill = payload.get("tool_input", {}).get("skill", "<unknown>")
log_file.write(f"{timestamp}\t{session_id}\t{skill}\n")
注意,hook 出错时必须 return 0,不要让一个日志脚本拖垮整个会话。可观测系统可以失败,但不能污染主流程。
有了日志以后,你能立刻看到:
- 哪些 Skill 被高频调用,值得继续优化;
- 哪些 Skill 从未使用,应该删除或重写描述;
- 是否存在 invoked but not installed;
- 新 Skill 上线后,团队是否真的在用;
- 本周和上周的使用趋势是否变化。
这就是 AI 工程里的仪表盘。没有仪表盘,就像开车只靠听发动机声,刺激是刺激,出事也快。
07 最小投入,最大回报:从 60 分到 95 分
如果你的团队现在已经有一些 CLAUDE.md 和项目文档,我建议不要一上来搞复杂的多 Agent 编排。先做三件小事。
第一,装 Skill 套件。
让 AI 在需求澄清、计划拆解、TDD、完成验证这些节点自动进入正确模式。它不一定立刻完美,但会显著减少“直接开写”的冲动。
第二,建立验证铁律。
所有“完成”“通过”“成功”声明,都必须经过 IDENTIFY、RUN、READ、VERIFY、THEN。没有验证证据,就不能说完成。
第三,做可观测层。
一个 hook、一个日志、一个统计脚本,就能知道 AI 到底在用什么。别让团队用 AI 用到最后,只剩一种感觉:“好像挺忙的。”
我的 ROI 排序大概是:
| 投资 | ROI | 说明 |
|---|---|---|
CLAUDE.md 硬规则 |
极高 | 一条规则可能省一年返工 |
| superpowers / Skill 套件 | 极高 | 让 AI 进入工程流程 |
| BRD → FSD → SPEC → PLAN 文档接力 | 极高 | 每个阶段守好边界 |
| Gate Function | 极高 | 防止幻觉污染进入完成声明 |
| Hook 可观测 | 高 | 知道流程真实状态 |
| Memory 反馈层 | 中 | 长期有价值,但启动慢 |
| 复杂多 Agent 编排 | 谨慎 | 90% 场景先别急着上 |
顺序不要反过来。
结尾:AI 不会替不写规约的团队变好
工程化 AI 编程的重点,不是追求更花哨的模型调用,也不是把所有事情都交给 Agent。
它真正要解决的是:如何让 AI 输出从“看起来合理”,变成“可以被团队信任”。
可信不是一句口号。
可信意味着:需求先澄清,边界先写清,工具受约束,输出可验证,失败可观测,经验能沉淀。
最后送一句话:
AI 不会让不写规约的团队变好。它只会让规约写得好的团队,变得快得离谱。
这就是我理解的工程化 AI 编程。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 4
4 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)