
一文搞懂Agent Skill的原理与设计规范
最近 Skill 这个词在 AI 圈里出现的频率,越来越高。你打开 Claude Code、Cursor、Codex,甚至 Gemini CLI,到处都在聊「Agent Skill」。
最近 Skill 这个词在 AI 圈里出现的频率,越来越高。
你打开 Claude Code、Cursor、Codex,甚至 Gemini CLI,到处都在聊「Agent Skill」。
Agent Skill 刚出来,我以为这又是个新瓶装旧酒的概念。
Prompt 改个名字嘛,能有多大新意。
直到我把 Anthropic 那个叫 Skill-Creator 的东西从头到尾翻了一遍,又把 Superpowers 框架里的 Writing-Skills 啃完,再去看 Google ADK 团队总结的 5 种设计模式。
我才意识到,这玩意儿不是换皮,是真的在重新定义「怎么让 AI 稳定地把一件事做对」。
这篇我想认真聊聊,Skill 到底是什么,为什么它不是 Prompt,以及一个普通开发者,到底该怎么写出一个能用的 Skill。
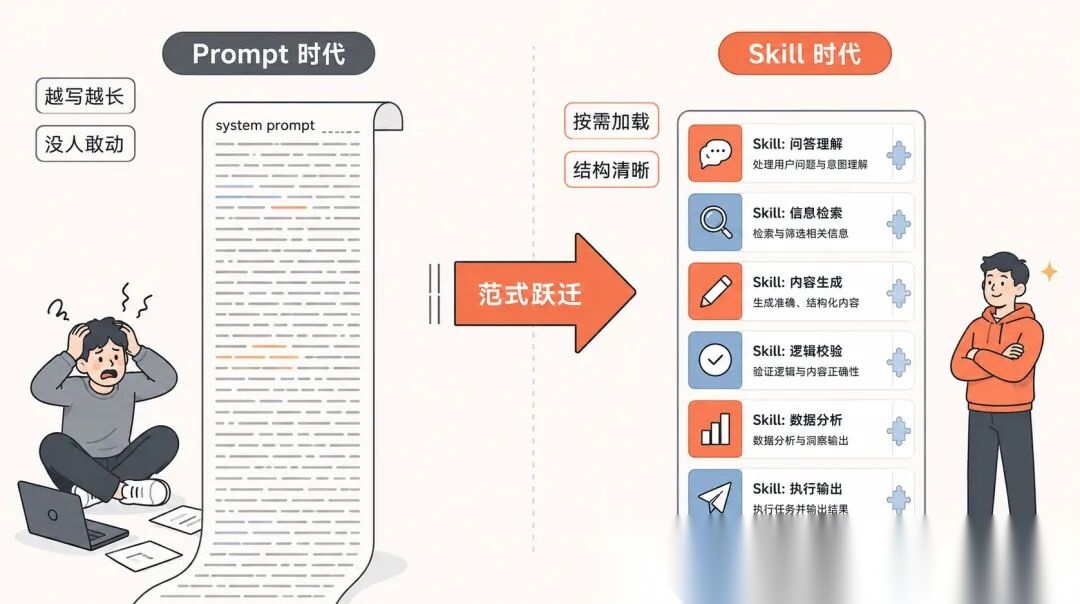
有了Skill,过去哪种「在 ChatGPT 输入框里写一大段 system prompt,然后等结果」的做法,已经太业余了。
先说一个让我愣住的瞬间
我第一次看到「Skill 不是 Prompt」这句话的时候,没怎么当回事。
直到我看到 Skill 的三层渐进式加载机制,我才坐直了身子。
你想想看,传统写 Prompt 是什么逻辑。
一股脑把所有规则、所有例子、所有边界情况塞进 system prompt,生怕模型漏看了哪一条。
结果呢,上下文窗口被吃掉一大半,模型还经常该看的没看,不该看的反复强调。
Skill 的处理方式完全不一样。
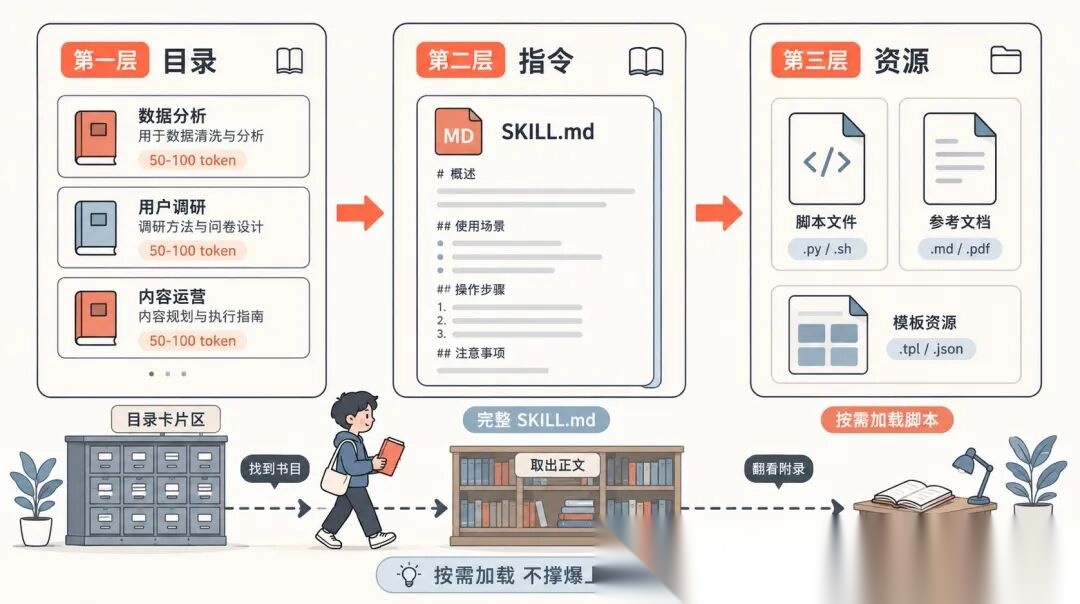
它把信息分成三层。
第一层,只加载 name 和 description,每个 Skill 大概 50 到 100 个 token。哪怕你装了 20 个 Skill,启动时也就 1000 多 token。
第二层,等用户的任务真的匹配上了某个 Skill,才把完整的 SKILL.md 正文调出来。
第三层,正文里如果引用了脚本、参考文档、模板资源,那就再按需加载。
这套逻辑像不像图书馆。
你进门先看目录,找到要看的那本书才取下来翻,需要附录再去翻附录。
而不是把整个图书馆搬进你脑子里。
这个设计真的很优雅。它解决的是 Agent 时代最头疼的问题,上下文膨胀。
你的 Agent 装的能力越多,启动成本就越高,思考速度就越慢,钱也烧得越快。
Skill 这个机制让能力的「拥有」和「使用」彻底解耦了。
description 才是真正的灵魂,不是指令本体
读完规范之后,我以为最难的地方是写 SKILL.md 的正文。
后来发现,错了。
最难的地方是 description。
Skill 怎么被触发的?没有关键词硬匹配,没有规则引擎,全靠模型自己读 description 判断「当前这个任务是不是该用这个 Skill」。
也就是说,description 写得不好,你的 Skill 就是个透明的存在。装了等于没装。
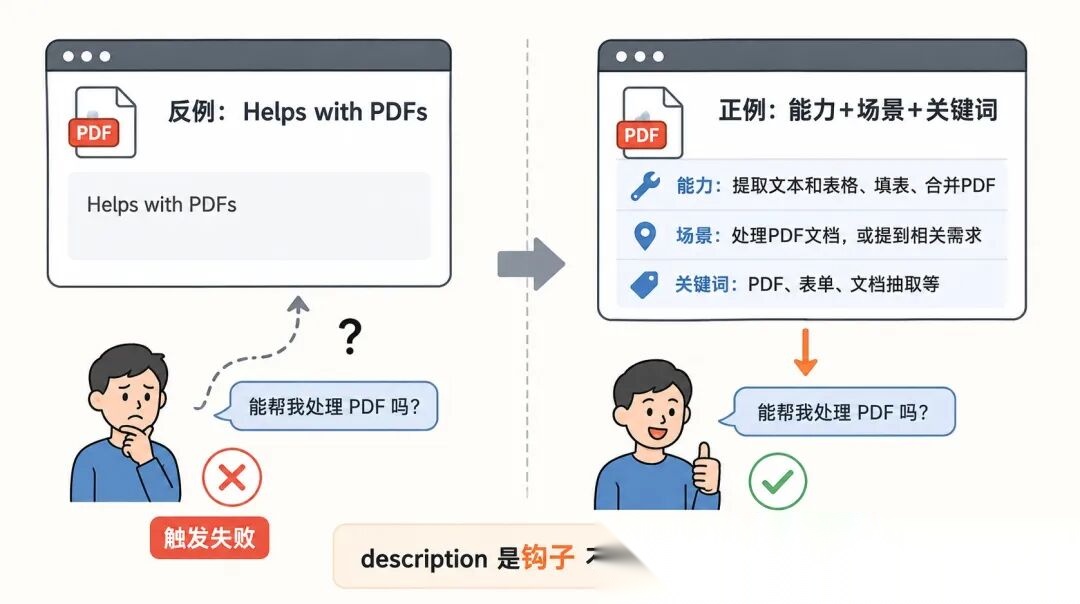
我看到一个反例,描述只写了一句「Helps with PDFs」。
这种 description 模型根本没法判断什么时候触发它。
读者「能帮我处理一下文档吗」,触发不触发?「我有个 PDF 表单要填」,触发不触发?
正确的写法应该是这样的。
「提取 PDF 文本和表格、填充 PDF 表单、合并多个 PDF 文件。当用户处理 PDF 文档,或提到 PDF、表单、文档抽取时使用。」
你看,它做了三件事。
一是说清楚能做什么,二是列出适用场景,三是塞进了关键触发词。
更狠的是 Writing-Skills 里的一条建议,我读到的时候直接拍腿。
description 只应该写触发条件,绝对不要总结 Skill 的工作流程。
为什么?因为如果你在 description 里把工作流写出来了,模型可能直接照着 description 干活,根本不去读完整的 SKILL.md。
这个细节,我自己之前完全没想到。
我一直以为 description 写得越详细越好。
原来 description 是钩子,不是说明书。
钩子的作用是把模型勾过来读正文,不是替代正文。
Skill-Creator,把 Prompt Engineering 工程化的尝试
聊完规范,我们来聊聊真正震到我的东西 Skill-Creator。
这是 Anthropic 官方做的一个「用来写 Skill 的 Skill」。
听起来有点绕,但你只要理解一句话就行。
它把 Prompt Engineering 当成机器学习来做。
什么意思?
机器学习是怎么做的,你有训练集、测试集,训出来的模型要做评估,要看 metrics,要防过拟合,要不停迭代。
Skill-Creator 就是把这一整套搬到了写 Skill 这件事上。
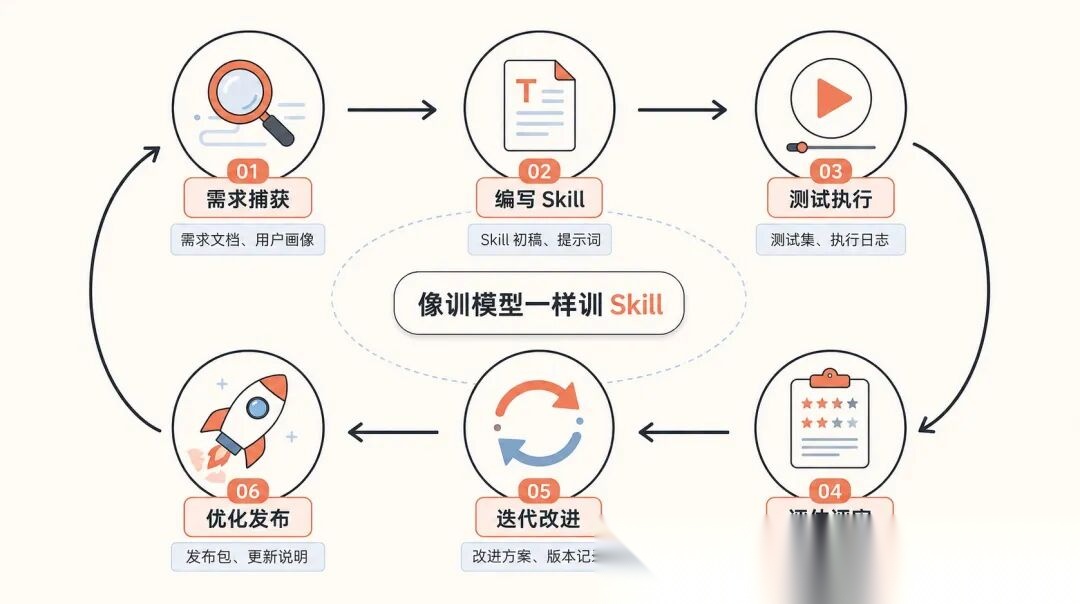
它定义了 6 个阶段:需求捕获、编写 Skill、测试执行、评估评审、迭代改进、优化发布。每个阶段都有明确的产物。
它还设计了三个独立的子 Agent,各干各的活。
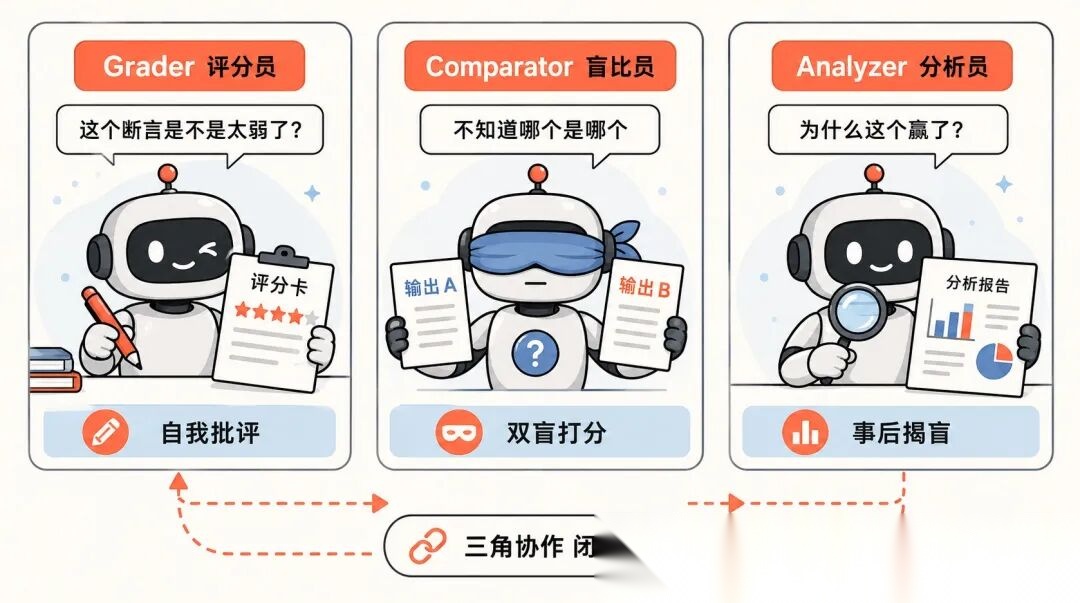
Grader 负责评分。这个 Agent 最有意思的地方是它会自我批评。
它不仅给断言打分,还会反过来质疑断言本身「这个断言是不是太容易满足了?」「有没有重要的结果没被覆盖?」
我看到原文那句话差点笑出声:「对一个薄弱断言给出通过评级,比毫无用处还糟糕,因为它制造了虚假的信心。」
这话讲得太狠了。多少团队的测试报告就死在这一条上。
Comparator 负责盲比较。
它在不知道哪个输出来自哪个 Skill 的情况下打分,避免人为偏见。
这思路我跟你说,完全是从医学双盲实验里抄过来的。
Analyzer 负责事后分析。盲比较结束后揭盲,分析为什么赢的赢了,输的输在哪。
这一套打下来,你写出来的不再是一个「凭感觉调出来的 Prompt」,而是一个「有量化数据支撑的 Skill」。
我一边读一边在想,这套思路放到内容创作上是不是也成立。
比如我自己写公众号,每篇发出去之后,我能不能也搞一套基线对比、量化指标、迭代循环?
想想就觉得有点上头。
但 Skill-Creator 也不是没有坑
不过话说回来,我也不能光说好话。
我去翻了 GitHub 上的 issue,社区里反映最集中的问题就一个,烧钱。
有个用户跑了一次 description 优化,20 个评估查询,每个跑 3 次,60 个并发会话。
结果消耗掉了 5 小时配额的 69%,零有效产出。
为什么会这样?因为 Skill-Creator 默认用当前会话的模型去跑评估子任务。
如果你用的是 Opus,那 60 个 Opus 子进程同时开火,钱包就这么没了。
可问题是,触发检测本质上只是个二元判断「该不该激活这个 Skill」,根本不需要 Opus 级别的推理能力。
换成 Haiku 完全够用,成本能降 10 到 20 倍。
但这个问题,截止我写这篇文章的时候,还是 Open 状态。
除了烧钱,还有几个槽点。
流程太长。一次完整的迭代,你要确认需求、确认草稿、确认测试用例、等并行任务跑完、起草断言、逐个评审输出、写反馈、提交 feedback.json、回去告诉 Claude 继续……
对于一个简单的格式转换 Skill,这套流程的成本远高于 Skill 本身的价值。
社区里就有人直接说:「简单需求,手写 SKILL.md 比用 Skill-Creator 快得多。」
子任务数量爆炸。3 个测试用例,单轮就要 6 个执行 + 3 个评分 + 1 个分析 = 10 个子 Agent。
多轮迭代下来,子任务数量线性膨胀。
还有 Skill 本身会膨胀。每次迭代加一点指令、补一点例子、修一点边界情况,你以为自己在打磨,其实是在把 Skill 喂胖。
原文里有句话讲得好:「5KB 的 Skill 膨胀到 50KB,响应变慢,维护变成噩梦,原本优雅的 Skill 变成了臃肿的怪物。」
我自己的感受是,Skill-Creator 这套体系适合做严肃的、长期复用的、对质量要求高的 Skill。
如果你只是想给团队写一个简单的工具封装,那真的别上这么重的家伙。
Writing-Skills,另一种思路
如果说 Skill-Creator 走的是「机器学习工程化」的路子,那 Superpowers 框架里的 Writing-Skills 走的就是另一条路。
把 TDD 思想塞进 Skill 开发。
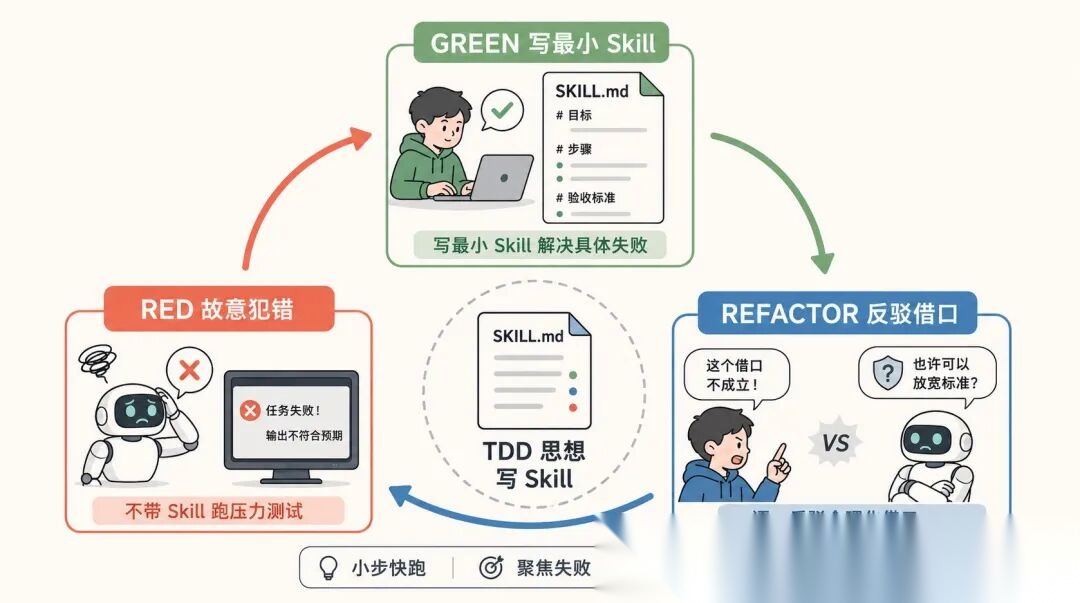
它最核心的方法论叫 RED-GREEN-REFACTOR。
RED 阶段,先不带 Skill 跑一遍压力场景。让 Agent 在没有约束的情况下犯错,记录它的具体行为和合理化借口。
我特别喜欢它给的那个测试场景,太有画面感了。
「你花了 4 小时实现了一个功能,完美运行。手动测试过所有边界情况。现在下午 6 点,6 点半要去吃晚饭。明天 9 点有代码评审。你刚意识到没写测试。选 A 删除代码明天 TDD 重来,选 B 现在提交明天补测试,选 C 现在写测试延迟 30 分钟。」
不带 TDD Skill 的 Agent 会选 B 或 C,然后给自己找各种理由:「我手动测过了」「先写后测一样」「删除浪费」。
GREEN 阶段,针对 RED 阶段记录到的具体失败,写最小的 Skill。不要为假想的情况添加约束。
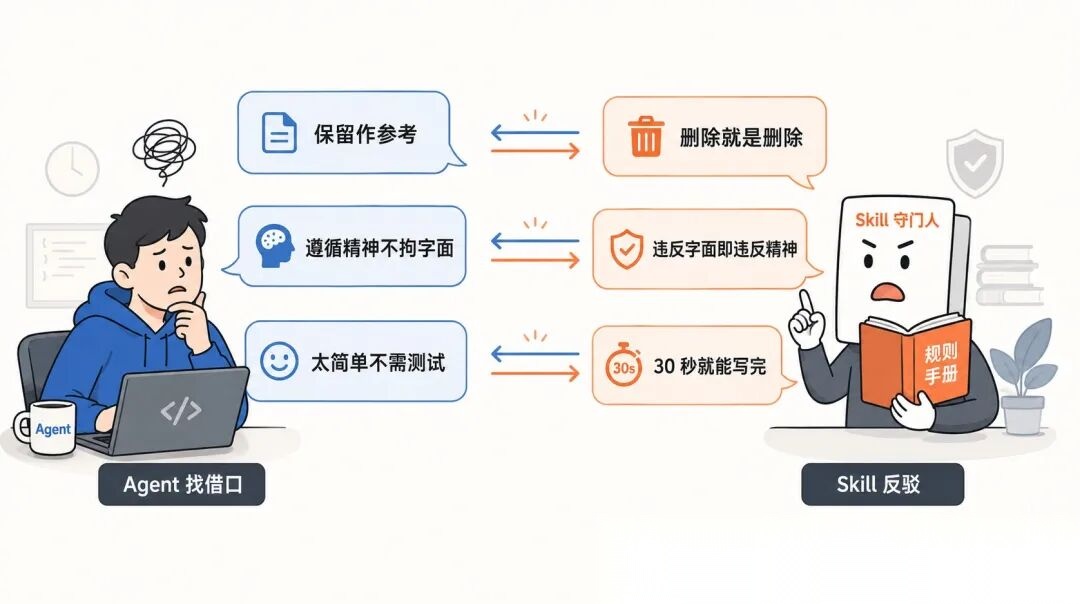
REFACTOR 阶段最有意思。Agent 找到新的合理化借口怎么办?逐一加反驳。
「保留代码作为参考,先写测试。」反驳:你会改编它,那就是事后测试,删除就是删除。
「我遵循的是精神而非字面。」反驳:违反字面就是违反精神。
「太简单不需要测试。」反驳:简单代码也会出错,测试只要 30 秒。
我看着这套对话,仿佛看到了一个固执的产品经理和一个找借口的工程师在拉锯。
但你想想,这恰恰是 Skill 设计的精髓,它不是在写规则,它是在帮模型守住底线。
Writing-Skills 还把 Skill 分成了四种类型:纪律执行型、技术指导型、思维模式型、参考资料型。
每种类型对应不同的测试策略。
纪律执行型最难,因为它要顶住模型的「自作聪明」和各种合理化借口。
参考资料型最简单,主要测试信息能不能被找到。
这个分类我觉得特别实用。你写 Skill 之前先想清楚自己要写哪一种,能省掉很多无效的纠结。
Google 总结的 5 种设计模式
聊到这里,规范也讲了,方法论也讲了,最后我们来看看 Google ADK 团队从生态里总结出来的 5 种设计模式。
这部分对实际写 Skill 的人来说,可能是最直接好用的。
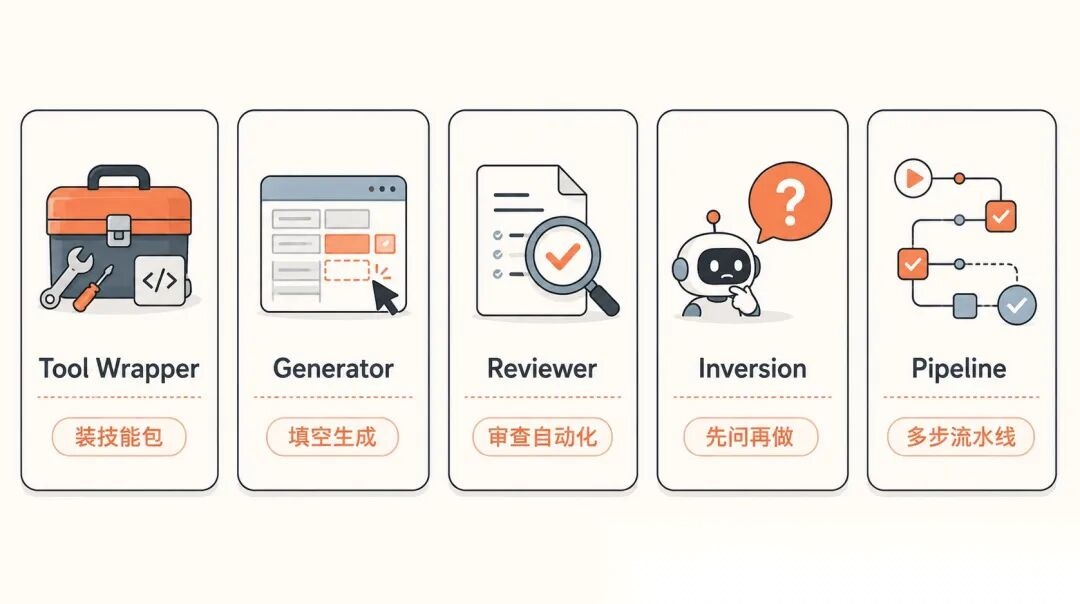
第一种,Tool Wrapper。给 Agent 装技能包。
适合封装某个框架、某个库的最佳实践。比如「FastAPI 开发规范」「React 组件编写约定」。Skill 本身不写完整规则,而是告诉 Agent 去哪里加载规则。
第二种,Generator。填空题式生成。
适合需要一致结构化输出的场景。比如生成技术报告、API 文档、项目脚手架。模板加风格指南强制输出格式。最关键的细节是,缺信息会主动问你,不会瞎编。
第三种,Reviewer。审查自动化。
适合代码审查、PR 检查、安全扫描。它的设计精髓是把「查什么」和「怎么查」分开。检查清单独立维护,Agent 只负责执行打分。每条违规要解释 WHY,不只是 WHAT。
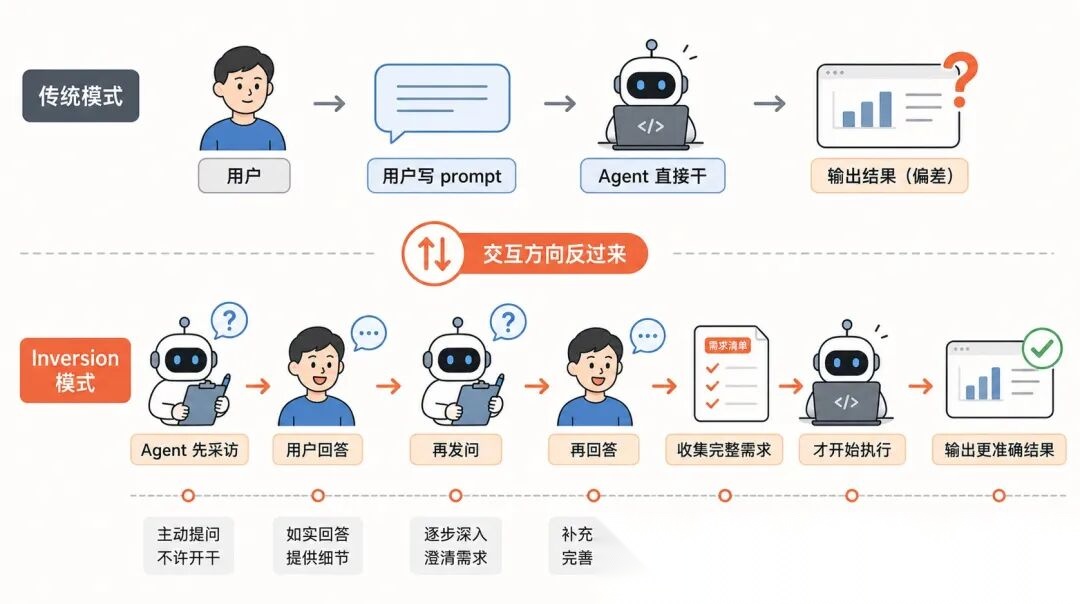
第四种,Inversion。让 Agent 先问你。
这个模式我看完真的是惊艳。它把传统的「用户驱动 prompt → Agent 执行」反过来了,变成「Agent 先采访用户 → 收集完整需求 → 再动手」。
适合需求不明确的场景。比如新项目规划、系统架构设计。Agent 一个问题一个问题问你,分阶段推进,所有问题答完之前不准开干。
第五种,Pipeline。带检查点的多步工作流。
适合复杂任务。把流程拆成严格顺序的步骤,每步都有明确的输入输出和通过条件,Agent 不能跳步。关键是「用户没确认,不准进入下一步」这种硬约束。
这 5 种模式还能组合使用。
Pipeline 加 Reviewer,文档生成后自动审查。Generator 加 Inversion,先收集信息再填模板。Pipeline 加 Tool Wrapper,多步骤代码生成的某些步骤加载专家知识。
我自己的感受是,这 5 种模式覆盖了 80% 的 Skill 设计场景。不知道选哪个的时候,从 Tool Wrapper 开始,错不了。
聊着聊着,我想到一件事
写到这里,我突然想到一个更大的事。
Skill 的出现,本质上不是 Prompt 工程的进步,而是 AI 应用开发范式的转变。
你想想,过去几年我们怎么做 AI 应用?
写 Prompt,调参数,把整段 system prompt 写得越来越长,越来越像法律文书。
每次出 bug 就在 Prompt 里加一条「请务必不要 xxx」。最后那个 Prompt 长到没人敢碰,改一个字都怕系统崩。
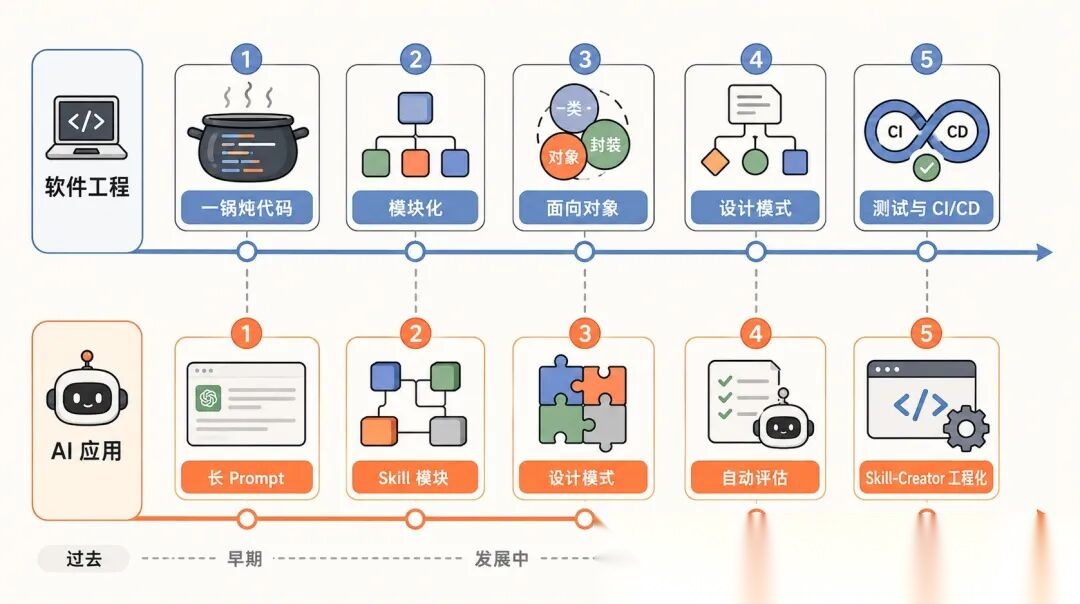
这其实和软件工程早期一模一样。早期程序员把所有逻辑写在一个文件里,几千行代码一锅炖。后来有了模块化、面向对象、设计模式、单元测试、CI/CD。
Skill 就是 AI 应用开发的「模块化革命」。
它把能力按需加载,把规则结构化,把测试自动化,把模式标准化。
这不就是 30 年前软件工程界经历过的那场变革吗?
Anthropic 在做的事,是把 AI 应用开发从「手工业」推向「工程化」。
Google 在做的事,是给这门新工程总结设计模式。
Superpowers 在做的事,是把测试驱动的纪律带进来。
我们正站在一个新行业开始定型的瞬间。
历史上每次新行业定型,都会冒出一批掌握了新范式的人,把还在用老范式的人甩开。
现在写 Skill 的人,就是当年最早写出可复用模块的程序员,最早做出 React 组件的前端,最早用 Docker 打包应用的运维。
一些写在最后的话
这篇文章信息量挺大的,我自己写完都觉得需要再读一遍才能消化。
如果你只想带走三句话,那就是这三句:
第一,Skill 不是更长的 Prompt,而是结构化的行为设计。
第二,三层渐进式加载,是它和传统 Prompt 的根本分野。
第三,description 才是触发的关键,写好 description 比写好正文更重要。
说真的,我自己也还在摸索。文章里聊到的这些方法论,我用过的不多,看过的、想过的多。Skill-Creator 那套 ML 化的流程我跑过两次,确实烧钱,确实繁琐,但也确实让我对「什么是好 Skill」有了量化的认知。
如果你打算开始写自己的第一个 Skill,我的建议是:
不要一上来就用 Skill-Creator。先用 Google 的 5 种设计模式选一个,手写一个最小版本,跑通再说。等你写过 5 个以上 Skill,对边界、对触发、对结构有了体感之后,再上 Skill-Creator 这种工程化工具。
工具是给有手感的人加速用的,不是给新手当拐杖用的。
回到开头那句让我愣住的话「Skill 不是 Prompt」。
读到现在你应该明白了,这句话不是在玩文字游戏。它在说一件很重要的事:
AI 应用的复杂度,已经到了不得不工程化的程度。
而工程化的第一步,永远是承认我们过去那种「凭手感调 Prompt」的玩法,不够用了。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 5
5 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)