
【深度分析】你现在加入AI推理一体机的混乱市场还有机会吗?
【摘要】阿里巴巴发布开源多模态模型Qwen3.5系列,覆盖0.8B至397B参数规模,具备原生多模态与智能体能力,在推理、编程等领域表现优异。其中397B模型采用混合架构优化推理效率,支持201种语言。该模型支持本地部署,可通过Ollama运行,并与自动化工具OpenClaw集成,适用于不同硬件环境。Qwen3.5的视觉编程、空间智能等能力为教育、科研等领域提供新可能,其开源特性为开发者带来高效A

阿里巴巴前天发布Qwen3.5 开源王炸,多模态性能屠榜,本地部署 + OpenClaw 实战可以大大提高在座各位的各种例行性日常工作的效率,估计不少机构和个人又来跃跃欲试自己安装或者购置一台主机来运行该Qwen3.5 开源模型。(感兴趣的可以参考本底部关于本次Qwen3.5的一些说明)
我们今天就来聊聊,对于这两年比较火热的本地化(on premise)部署AI推理一体机业务,没有资源的中小公司想分一杯羹在当前这个阶段还有入场的可能吗?尤其是这类低成本主机运行几千亿参数的模型的应用场景,例如本次发布的3970 亿(397B)的模型,或者之前deepseek发布的6710亿(671B)参数的模型 如果实在想进入,当前市场的现状到底是个啥子样子呢?有哪些坑会等着你呢?
低成本本地化 AI 推理一体机的搭建与商业化深度研究
摘要
近两年在中国出现的“经济型本地化(on‑prem)AI 推理主机/一体机”,本质是把“可买到的通用硬件(x86 PC/入门服务器 + 消费级 GPU + 大内存/SSD)”与“开源推理引擎 + 预装驱动/CUDA + Web 入口(如 Open WebUI)+ RAG/知识库”捆绑,提供面向政务与企业内网的“开箱即用”推理与知识库能力。中国信息通信研究院的行业调研也指出,一体机常被用于在内网快速上线智能客服、智能检索等能力,并强调本地部署能满足金融、政务、医疗等对数据隐私的严格要求,同时一体机通常集成 RAG 来提升回答专业性并降低幻觉。
针对“能加载并运行 671B 级 MoE 大模型”的 DIY 目标,本报告给出两条现实可复制路径:第一条(路径 B,推荐)是使用“动态量化/超低比特 GGUF(约 131–212GB 权重)+ llama.cpp/兼容 OpenAI API 的 server + Open WebUI”,重点在于让模型真正可在单机加载与稳定运行,以牺牲部分吞吐换取成本与落地确定性。动态量化方案已有公开实现:例如 Unsloth 报告将 DeepSeek‑R1 671B 动态 1.58-bit 量化到约 131GB,并提供 131–212GB 多档版本与 GPU 分层 offload 的经验表。
第二条(路径 A,实验性)是“FP8 近全精度(约 700GB 权重)+ 至少 1TB DRAM + CPU/KV cache offload + 推理引擎调度”,其技术方向与近期《电子产品世界》转载文章中描述的“小显存跑大模型”一致;该文声称在 24GB GPU + 1024GB DDR + SGLang 框架下可 4 路并发运行 DeepSeek 671B FP8,推理约 28 tokens/s,但这类结果更可能依赖特定调度/工程优化,DIY 复现存在不确定性与较高排障成本。 同时,SGLang 面向 DeepSeek V3/R1 的官方最佳实践明确指出 FP8 全精度的“推荐配置”通常是多卡数据中心 GPU(例如 8×H200/H100/B200 等),这意味着路径 A 在消费级硬件上属于“偏工程 hack 的边界玩法”。
市场层面,“大模型一体机/推理一体机”总体已呈红海化:一方面,工信智库/研究机构与媒体报道显示产业链参与者快速增长、产品形态趋同(预装模型、RAG、可视化运维、开箱即用);另一方面,服务器与集成服务格局中头部厂商(如华为、新华三、浪潮等)在政企渠道与生态上优势明显,且中国加速服务器市场集中度较高。 因此创业/小 SI 若仅“拼硬件堆料 + 预装开源软件”,很容易陷入价格战;更可持续的差异化应来自合规与交付能力(安全域隔离、SSO/LDAP、审计、可观测性)、行业工作流产品化、服务 SLA、以及对供应链波动的管理能力。
供应链方面,2025 年下半年以来内存、SSD 价格波动与交期问题已成为“经济型一体机”最现实的成本与交付风险之一:TrendForce 对 DDR4/DRAM 与 NAND/SSD 的涨价预期与多阶段调涨信息、以及媒体对厂商“内存成本上升”的报道,都指向构建 BOM 的价格不确定性显著增强。 同时,面向中国市场的高端 GPU/加速器还叠加出口管制与合规风险(例如美国 BIS 的先进计算出口规则与对部分芯片/型号的限制事件),进一步放大“拿货与交付可控性”的难度。
技术与产品形态概览
本地化推理一体机的典型“产品栈”可以抽象为四层:硬件(CPU/内存/SSD/GPU/网络/电源散热)→ 系统(Linux/Windows + 驱动 + CUDA)→ 推理与管理(vLLM/SGLang/llama.cpp/Ollama + 模型仓库 + 监控)→ 应用入口(WebUI、账号权限、知识库/RAG、API 网关)。中国信通院的《大模型一体机应用研究报告》对“硬件能力、软件能力、模型能力、应用适配”等要素给出了较标准化的描述,并明确提到一体机常集成资源监控、故障定位、模型仓库、容器化部署,以及 RAG 和智能体(agent)等能力以降低用户门槛。
需求侧推动力主要来自“数据不出域/合规/内网隔离”的硬约束:报告在智能客服等场景中强调,本地一体机可在企业内网快速上线问答与检索能力,避免数据外传并满足金融、政务、医疗等行业对隐私的严格要求,同时通过 RAG 把企业内部文档作为“外挂知识”降低幻觉与提高专业性。 这也是为什么个人用户可直接购买云端 API 服务,而政企客户更偏好 on‑prem 形态的根本原因之一(采购侧往往也更看重可控、可审计、可运维与长期成本可预期)。
“671B 级 MoE 大模型能否在廉价硬件上运行”背后有两个关键事实:第一,MoE 的计算激活参数远小于总参数。以 DeepSeek‑V3 技术报告为例,其为 671B 总参数、每 token 仅激活约 37B 参数。 这解释了为什么推理算力压力可能不像“671B dense 模型”那样不可承受。
第二,权重存储仍由总参数决定。市场文章中直接给出估算:DeepSeek 671B 若按 FP8 需要约 700GB 权重空间,这会把单机 VRAM 需求推到消费级无法承受的量级。 因此“低成本能跑”的核心不在于“算得动”,而在于“装得下 + 传得快 + 稳得住”。
在全球背景下,厂商也在用“更大统一内存/更紧耦合架构”降低本地运行门槛:例如 英伟达 推出的 NVIDIA DGX Spark 强调 128GB 统一内存,可在桌面形态“运行最高约 200B 参数的模型”,其官方新闻稿与产品页均明确了这一定位。 这类趋势与中国市场中“用大内存 + 软件卸载/分层存储来突破显存墙”的思路一致。
DIY 部署指南
两条路径对比与选型结论
路径 A(FP8 + 1TB DRAM + offload)更像“工程挑战题”:可以作为技术演示或研发试验,但落地交付与稳定性风险更高;其最强支持来自《电子产品世界》转载文章中的案例描述与 vLLM 的 CPU/KV offload 机制参数。
路径 B(动态量化 131–212GB)更像“交付题”:核心是用成熟的 GGUF 生态与 Open WebUI 的产品化能力,把“能运行 671B”变成可复制、可维护的私有化方案。
下表给出面向“能加载并运行 671B 级 MoE 模型”的关键差异(成本为估算区间/模板,原因见供应链章节;若某参数未指定,将明确标注为未指定):
| 维度 | 路径 A:FP8(~700GB 权重)+ 1TB DRAM + offload | 路径 B:动态量化(~131–212GB)+ GGUF/llama.cpp |
|---|---|---|
| 目标 | 尽可能接近原始权重精度,并在小显存下“勉强跑起”大模型 | 以量化换取“装得下 + 可稳定运行”,面向实际交付 |
| 权重体量 | FP8 约 700GB(市场文章估算) | 公开动态量化版本约 131/158/183/212GB |
| 推荐内存 | 1TB DDR(文章案例:1024GB) | 256–512GB DDR(建议取决于并发与上下文;见后文验收) |
| GPU 角色 | 主要算子在 GPU,权重/部分 KV 在 CPU 内存分层/卸载 | 以 CPU 内存承载权重为主,GPU offload 少量层/算子加速 |
| 预期性能 | 公开案例声称 4 路并发 28 tok/s(不保证可复现) | 性能强依赖硬件;公开博文给出 H100 级别吞吐与单用户示例,强调消费硬件“可跑但慢” |
| 主要风险 | PCIe 传输瓶颈、NUMA 远程访存、调度不当导致抖动/崩溃;可能需要深度工程优化 | 量化精度风险、长上下文 KV 占用导致并发受限、文档向量化过程可能影响 WebUI 交互 |
| 适用场景 | 研发验证、对精度极敏感且能承担调试风险的客户 | 政企“能用、可交付、可运维”的本地推理与知识库 |
路径 B(推荐):动态量化 671B(131–212GB)+ llama.cpp server + Open WebUI
参考硬件 BOM
以下给出两套“可落地”的 BOM(均支持局域网 Web 访问 + 用户注册 + 选模型推理 + 知识库/RAG),你可按预算与供货情况替换。由于 2025 下半年以来内存/SSD价格波动显著,成本仅给出区间与计价模板,若未指定具体品牌/型号则不强行虚构。
BOM‑B1:入门可交付型(优先保证“能加载 + 稳定”)
-
CPU 家族:单路 8 通道内存平台(推荐 AMD EPYC/Threadripper Pro 或 英特尔 Xeon Scalable 类平台;具体型号未指定)
-
主板/平台:支持 ≥8 通道内存、≥2 个 PCIe x16 插槽、≥2× M.2/U.2 NVMe 的工作站/服务器平台
-
内存:256–512GB
-
类型:ECC RDIMM(服务器)或 ECC UDIMM(部分工作站)
-
NUMA:单路通常 1 NUMA;若双路则按 socket 分 NUMA(见 BIOS/NUMA 小节)
-
-
GPU:1× 24GB 显存(例:RTX 4090/3090 级别;具体型号未指定)
-
说明:Unsloth 给出在 24GB GPU 上 offload 层数的经验表(例如 131GB 档约 7 层),供你做初始参数设置。
-
-
NVMe:至少 2× 4TB(推荐 1 块系统盘 + 1 块模型/向量库盘;容量可按知识库规模上调)
-
PSU:1200–1600W(单卡)
-
机箱形态:4U 工作站机箱或 2U 服务器(取决于散热与机房条件)
BOM‑B2:并发增强型(面向“多用户/长上下文”)
-
CPU 家族:双路平台(更高内存容量与带宽,代价是 NUMA 复杂度上升)
-
内存:512GB–1TB(建议优先 1DPC 方案,即每通道 1 根条以获得更好带宽/时延特性;戴尔科技 的 EPYC NUMA/内存填充建议中也强调先填满通道再做 2DPC。)
-
GPU:2× 24GB(或 1× 48GB;具体型号未指定)
-
NVMe:至少 3 块(系统 / 模型仓库 / 向量库与日志分离)
-
PSU:2× 1600–2000W 冗余(2U/4U 服务器常见)
成本估算模板(RMB 与 USD)
-
记 GPU 单价为 (P_g),内存单价(每 GB)为 (P_m),NVMe 单价(每 TB)为 (P_s),其余平台(CPU+主板+机箱+电源+散热)为 (P_b)。
-
则硬件总成本近似:[ C \approx N_g\cdot P_g + M{GB}\cdot P_m + S{TB}\cdot P_s + P_b ]
-
由于 TrendForce 报告与媒体信息表明 DRAM/NAND 价格在 2025–2026 存在明显上行与波动,建议你在商业报价上采用“周度/双周更新 + 锁价条款 + 替代料清单”机制。
-
汇率与渠道价随时间变化,本报告不强行给出单一“精确到元”的数字,以免在交付时失真;可在你拿到实际渠道报价后代入上式生成 RMB,并按当期汇率换算 USD(汇率未在本报告中指定)。
BIOS/固件设置(关键项)
-
Above 4G Decoding / Large BAR多 GPU/大显存映射时,建议开启 Above 4G Decoding。英伟达 的官方文档在 NIC/PCIe 资源相关场景中明确建议开启该选项,以避免 PCIe 资源不足。
-
NUMA(NPS / Nodes per Socket)策略双路平台一定会引入 NUMA。VMware 与服务器厂商文档对 EPYC 的 NPS 选项(NPS‑1/2/4)给出定义与调优建议,强调需要按工作负载测试选择。 对本场景的可操作建议是:
-
若你以“加载超大权重 + 降低远程访存”为第一目标:优先 NPS‑1,让每 socket 呈现为更少 NUMA 节点,减少跨 NUMA 抖动的排障复杂度(具体取值需实测)。
-
若你以“单机多租户/更细粒度绑核绑卡”为目标:可试 NPS‑2/4,但必须配合进程绑核与 GPU 亲和性设置,否则可能出现吞吐不升反降。
-
Memory Interleaving联想的 UEFI 性能调优文档建议 Memory Interleave 通常保持开启,并提示可按 NUMA 优化工作负载尝试 NPS2/NPS4。
-
固件与微码
-
更新主板 BIOS/固件到厂家建议版本(版本未指定)。
-
GPU VBIOS 一般无需手动刷写,除非存在兼容性 bug(本报告不建议把“刷 VBIOS”作为标准交付流程)。
操作系统、内核与系统调优
推荐 OS:生产交付更建议 Linux(如 Ubuntu Server LTS),因为 vLLM 在官方文档中明确 Windows 不原生支持,通常需 WSL。(若你强制 Windows,建议把商业承诺限制为“桌面试用/POC”,并将生产交付转向 Linux。)
性能调优的“最小可交付原则”:不要一上来就堆大量内核参数;优先保证稳定性,然后在同一套基准测试下逐项修改。
建议的三步法:
-
安装 tuned 并启用吞吐型 profile(可回滚)Ubuntu 文档介绍了 TuneD 用于自动系统调优与 profile 管理。
-
NUMA/内存页策略(可选项,必须基准验证)
-
Red Hat 的知识库在“大规模 NUMA 系统高内存占用”问题中建议禁用 THP、关闭自动 NUMA balancing,以规避内存 compaction 造成的软锁问题。
-
与之相对,AMD ROCm 文档也举例说明某些平台会建议启用 THP 来提升性能。结论:THP/NUMA balancing 在不同推理栈上可能得出相反结果;建议把它纳入“验收测试矩阵”,按你选定的推理框架与模型实际测。
-
Docker/容器共享内存若你用 vLLM/SGLang 多进程/张量并行,vLLM 文档提示容器需要
--ipc=host或足够--shm-size,否则共享内存不足会导致异常。
驱动/CUDA 与容器运行时
Ollama 的最低 NVIDIA 驱动要求:Ollama 官方写明支持计算能力 5.0+ 且驱动版本 531+ 的 NVIDIA GPU。vLLM 的 GPU/软件栈关键点:
-
vLLM 稳定版要求 CUDA GPU 计算能力 ≥7.0,并说明包含预编译 CUDA 二进制(文档中给出包含 CUDA 12.8/并提供按 CUDA 版本选择 wheel 的方式),且官方提供
vllm/vllm-openai镜像用于部署 OpenAI 兼容服务。
建议的交付做法:
-
推理服务尽量容器化(Ollama/vLLM/Open WebUI都可 Docker 化),把主机侧依赖收敛为:内核 + NVIDIA 驱动 + 容器运行时 + nvidia-container-toolkit(未在本报告中给出特定版本号,因版本与发行版强相关)。
模型获取与导入(GGUF/GGML/Ollama)
本节以“动态量化 DeepSeek‑R1 671B(131GB 档)”为例。注意:你手头的具体模型变体(例如 R1、V3、V3.1 或某个特定 revision)在问题描述中未指定;因此以下以公开可得的 DeepSeek‑R1 671B 动态量化方案做模板,交付时请替换为你实际选定的模型仓库与文件名。
方式一:llama.cpp server(推荐用于 671B 超大 GGUF)+ Open WebUI
Open WebUI 官方教程给出了完整的“下载 → llama-server 启动 → Open WebUI 连接”的步骤,并明确 llama.cpp server 提供 OpenAI 兼容 API 端点,Open WebUI 可通过 Connections 进行对接。
-
下载模型(示例:Hugging Face snapshot_download)

示例目录结构与文件分片形式在 Open WebUI 教程中有明确展示。
-
启动 llama.cpp server(Open WebUI 官方示例)
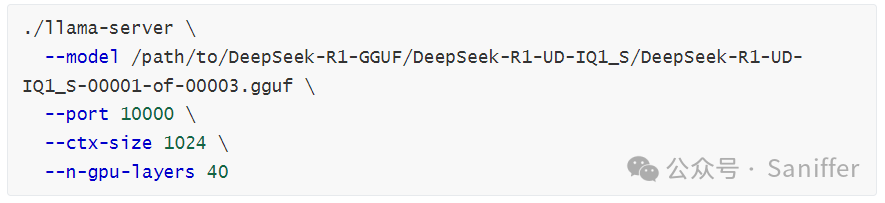
其中 --n-gpu-layers 用于指定 offload 到 GPU 的层数;Open WebUI 文档建议参考 Unsloth 的表来设定。
-
在 Open WebUI 中配置连接
Open WebUI 教程给出:在 Admin Settings → Connections → OpenAI Connections 中新增 URL(例如 http://127.0.0.1:10000/v1),API Key 可填 none。
-
关键调参建议(基于 Unsloth 的公开经验表)
Unsloth 给出“不同量化档在 24GB/80GB/2×80GB GPU 上可 offload 的层数”经验值,并提示结合 --ctx-size 与 KV cache 量化来控制内存。建议你的调参顺序是:
-
优先把
--ctx-size固定在业务所需的最小值(例如 2K/4K/8K 分档验收)。 -
逐步提高
--n-gpu-layers,以“不 OOM 且 tokens/s 最优”为目标。 -
并发(多用户)上升时,优先加 DRAM 与/或减少上下文长度,而不是盲目拉高 offload 层数(原因:KV cache 随上下文线性增长,容易把显存/内存顶爆;具体增长量需按模型配置计算)。
方式二:Ollama(适合中等模型;671B 需谨慎评估)
-
Ollama 官方支持 Docker 部署,并提供启动命令模板(含
--gpus=all与持久化卷)。 -
但对于 671B 超大 GGUF,实际更常见的做法是使用 llama.cpp server 做后端,Open WebUI 做前端(Open WebUI 官方教程也是如此)。
若你仍希望导入 GGUF 到 Ollama,Ollama 文档提供了“从 GGUF 导入”的 Modelfile 方式(以下为示例结构,具体以你本地文件路径为准):


说明:Open WebUI 官方教程强调“在 Ollama 上的真正 671B DeepSeek‑R1”与其他蒸馏版需区分对待,这在做商业宣传与验收时尤其重要。
Open WebUI 安装、账号与安全配置(局域网交付必做)
-
安装(Docker Quick Start)Open WebUI Quick Start 给出 Docker 拉取与启动步骤,并说明“首个注册账号自动成为管理员、后续注册默认 Pending 需管理员审核”,这与政企内网交付的权限管控高度契合。
-
静态 IP 与最小暴露面
-
建议把推理后端端口(如 10000/11434/8000)限制为仅 Open WebUI 所在主机可访问;对用户只暴露 WebUI 入口(通常 3000/8080 之一,具体端口未指定)。
-
若必须允许内网直连 OpenAI‑compatible API,至少使用防火墙限制源网段,并启用 API Key(见下一条)。
-
API Key、RBAC 与监控Open WebUI 的“API Keys & Monitoring”文档提供了启用 API Keys 的路径(Admin Panel → Settings → General → Authentication → Enable API Keys),并支持更细粒度的 endpoint 限制。 同时 RBAC 权限文档强调“全局开关 + 权限检查”共同生效,管理员也不自动豁免。
-
反向代理与 HTTPSOpen WebUI 官方提供 Nginx 场景指南,并特别警告 WebSocket 常见故障来自 CORS 配置,要求正确设置
CORS_ALLOW_ORIGIN。NGINX 的反向代理基础配置也有官方文档可参考,用于理解转发头、WebSocket 与缓冲等机制。 -
企业级 SSO/LDAP(可选,但强烈建议用于政企)Open WebUI 提供联邦认证分类与 LDAP 集成文档,可用于对接企业目录(例如 OpenLDAP)。 同时其环境变量文档也提示在 SSO 场景下可强制禁用密码登录以降低账号接管风险。
RAG/知识库集成(Open WebUI 原生路径)
Open WebUI 的 RAG 功能文档定义了其可从本地/远程文档、网页、多媒体等检索上下文并拼接到提示词中;其 Features 页面进一步列出 embedding 模型配置入口(Admin Panel → Settings → Documents)、可选混合检索(BM25)与 CrossEncoder rerank,并支持 RAG 引用标注。
可交付的最小 RAG 步骤(按 Open WebUI 官方 RAG Tutorial):
-
Workspace → Knowledge → 创建 Knowledge Base(选择 Private 或指定 Group)
-
上传企业文档(建议先从 Markdown/纯文本开始,再扩展到 PDF/Office)
-
在 Documents 设置中选择 embedding 模型(可用 Ollama 或 OpenAI 格式接口)
-
绑定 Knowledge Base 到一个对话/模型配置,进行检索增强问答与引用验证
文档解析的工程建议:若你需要较高质量的 PDF/Word 表格与版式抽取,可考虑 Open WebUI 提供的 Docling 集成(其文档写明可把 PDF、Word、表格、HTML、图片等转成结构化 JSON/Markdown)。 但也要注意:向量化与写入过程可能在某些版本/场景下造成 UI 卡顿(社区 issue 报告“保存 embedding 到向量库时界面冻结”),这会直接影响多用户体验与售后。
验证测试与验收标准(tokens/s、并发、稳定性)
为了把 DIY 主机做成“可交付产品”,验收必须覆盖:性能、并发、正确性、稳定性与安全。
性能指标:tokens/s 与 TTFT(首 token 延迟)
-
llama.cpp:常见的速度/时间统计会区分 prompt eval 与生成 eval,并可通过 bench 工具或 server 输出做分析(社区 issue 示例展示了 tokens/s 分项统计)。 另外,NVIDIA 论坛讨论也指出 llama-bench 与 llama-server 的结果可能因网络/HTTP/模板开销不同而有差异,因此披露性能时要注明测试方式。
-
vLLM:官方 benchmark 文档提供
vllm bench serve用于在线服务吞吐/延迟测试,并支持设定--max-concurrency等参数来模拟并发上限。
并发测试:建议的最小测试矩阵
-
固定 3 档工作负载:短 prompt(256 输入/256 输出)、中等(1K/512)、长上下文(4K/512)。
-
并发从 1 → 2 → 4 → 8 逐步拉升,记录:
-
平均 tokens/s(输出吞吐)
-
TTFT p50/p95
-
OOM/重启次数
-
CPU/内存带宽、GPU 利用率、PCIe 传输(可用 nvidia-smi 与系统监控;监控体系建议见运维章节)
-
-
对 vLLM 可直接使用官方 CLI;对 llama.cpp 则建议同时跑 server(真实交付形态)与 bench(剥离网络开销)两套结果,避免“宣传口径与客户体验不一致”。
正确性/可用性验收
-
功能:Web 注册/登录、模型切换、知识库创建/权限、RAG 引用可追溯。
-
安全:默认关闭公网暴露;启用 API keys 或 SSO;后续账号注册需审批(如适用)。
-
稳定:7×24 小时 soak test(持续请求 + 定时知识库写入),验证无内存泄露/无死锁(Open WebUI 的向量化阻塞问题需要重点关注)。
路径 A(实验性):FP8 671B(~700GB)+ 1TB DRAM + CPU/KV offload(可选 CXL 思路)
可行性边界与结论
该路径的可信支撑来自两类公开信息:
-
市场文章提出“用大容量 DDR/CXL 内存池 + CPU/KV Cache Offload + MoE 特性调度”来突破显存墙,并给出一张 24GB GPU + 1024GB DDR + SGLang 的技术验证结果(4 路并发、28 tok/s)。
-
vLLM 文档提供了明确的 CPU offload 与 KV offloading 参数,并警告 CPU offload 依赖快速 CPU‑GPU 互联,因为推理会在前向过程中按需把部分权重从 CPU 内存搬运到 GPU。
但同时,SGLang 面向 DeepSeek V3/R1 的官方推荐配置把 FP8 全精度推理放在多卡数据中心 GPU 上(例如 8×H200/H100/B200 等),这意味着“消费卡 + 超大 DRAM + offload”更像是非主流、工程依赖强的实现路线。 因此本报告把路径 A 定位为:可尝试的研发路线,但不建议作为默认交付方案。
参考硬件 BOM(偏服务器平台)
-
CPU/平台:双路服务器平台(理由:更易上 1TB 内存;单路也可但平台选择更苛刻)
-
内存:1TB DDR(优先 1DPC 填满通道)
-
GPU:至少 1× 24GB(更现实是 2×/4× 以降低每步搬运量;具体型号未指定)
-
NVMe:用于模型下载、缓存、日志(可选)
-
网络:至少 10GbE(内网多用户时推荐;未指定)
-
电源与散热:按 GPU 数量核算(双路+多卡通常需要冗余电源)
推理引擎与关键参数(以 vLLM 为例)
vLLM 的 Engine Args 文档给出:
-
--cpu-offload-gb:每 GPU 可 offload 到 CPU 的 GiB 空间,直观上相当于“虚拟扩展显存”;并指出需要快速 CPU‑GPU 互联,因为每次 forward pass 会在 CPU/GPU 间搬运。 -
--kv-offloading-size与--kv-offloading-backend:用于把 KV cache offload 到 CPU,并指定 backend(native/lmcache)。 -
--swap-space:每 GPU 的 CPU swap 空间。
可复制的“起步命令模板”(示意):
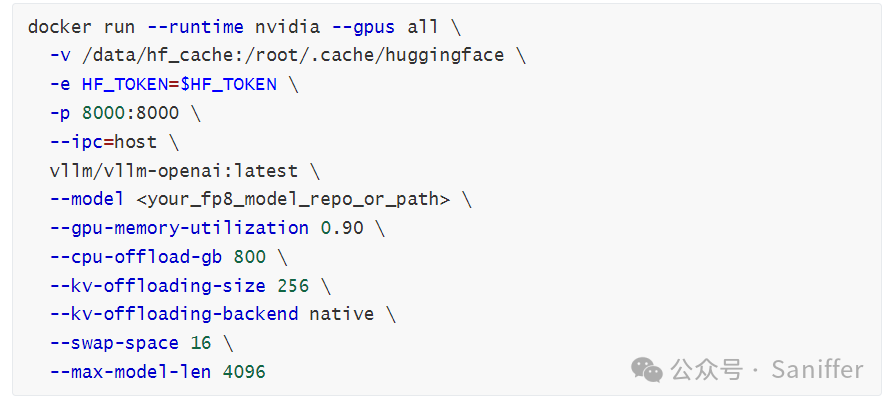
其中 Docker 镜像与 --ipc=host 的必要性在 vLLM 官方 GPU 安装文档中有明确说明。
为什么“能加载”不等于“可交付”
路径 A 的本质是用 CPU 内存(甚至未来 CXL 内存池)替代显存承载权重与 KV cache。文章把这一思路描述为“让 GPU 专注计算、把完整参数/KV cache 放在 DDR/CXL 内存池”,并强调 CXL 未来可做 TB 级内存池化。 但在现实硬件上,CPU‑GPU 数据搬运通常经由 PCIe,带宽/时延远不如 GPU 本地 HBM/显存,因此很容易出现:吞吐大幅下降、延迟抖动、并发上升即崩溃。vLLM 对 CPU offload 的“需要快速互联”提示正是对此类风险的直接点名。
因此,若你把一体机作为商业产品,路径 A 更适合作为“实验室卖点/技术演示”,而非默认交付配置;真正面向政企生产环境,通常应提供路径 B(量化可控)或更高端的多卡/数据中心配置选项(对应 SGLang 官方推荐路线)。
部署架构与交付流程图

市场竞争与销售壁垒
是否已成为红海
从供给侧看,一体机形态高度标准化:信通院报告把“集成主流深度学习框架、全栈工具链、可视化管理、模型预置、RAG”描述为普遍能力,并给出了产业链上游硬件、软件、模型、应用、整机等多类参与者数量(例如硬件供应商、软件供应商、模型供应商都已呈“多家”格局)。 同时,研究机构与媒体对中国加速服务器/智算集成服务的市场份额分析显示头部厂商优势显著:例如 IDC 数据口径下 2024 年中国加速服务器市场,浪潮信息以约 36.1% 居首,其后宁畅、新华三、超聚变、华为昇腾等占据较高份额。 这意味着:
-
纯硬件拼装很难长期抗衡头部厂商的渠道、资金与供应链能力;
-
纯软件预装也容易同质化,因为 Open WebUI、Ollama、vLLM 等均可公开获取,形成“安装脚本即产品”的低门槛竞争。
因此,在“政府/央国企/教育/金融”这些最符合 on‑prem 需求的垂直市场,一体机更接近红海:竞争核心逐步从“能跑模型”转向“谁更合规、更易采购、更敢签 SLA、更能做行业工作流”。
竞争主要集中区域与垂直行业
区域上,竞争与需求通常集中在政企客户密集、ICT 产业链完善的城市群与核心城市,典型包括:
-
北京(央企总部/部委与科研资源集中)
-
上海(金融与总部经济、AI 生态)
-
深圳(硬件供应链与制造/电子信息产业)
-
杭州(互联网与云生态、产业数字化)
行业上,信通院报告明确列出政务、金融、医疗、教育、制造等一体机落地领域,并给出企业在智能客服、智能检索、智能数据分析等场景中的产品覆盖比例(如智能数据分析一体机占比高于 80%)。 这些领域对“数据不出域、权限审计、可控可管”诉求强,且预算与采购流程更偏传统 IT 设备采购(而非开发者自助购买)。
销售 barrier:拿客户 vs 拿货
拿客户(更关键)政企客户的采购门槛往往不是“技术能否跑”,而是“能否进入采购体系 + 能否通过安全与合规审查 + 能否提供长期服务承诺”。政府采购法明确公开招标为主要采购方式,且达到公开招标数额标准的项目必须公开招标(除非按规定批准采用其他方式),这使得“供应商资质、过往业绩、交付与售后条款”对中小厂商极为关键。进入实操层面,很多地区会通过政采平台(如政采云等)进行供应商入驻与资质审核入库;相关入驻指南通常要求营业执照、人员信息与声明材料等流程化提交。
拿货(近两年显著变难)
-
内存/SSD:TrendForce 与媒体对 2025–2026 DRAM 与 NAND 的价格上行、调涨与“短缺推动成本上升”的报道,意味着一体机 BOM 中“内存与 SSD”供价可能需要周度更新。
-
GPU:一方面存在供需波动(Reuters 报道对 2026 年某些芯片供给紧张的预期),另一方面还叠加对华出口管制与型号限制的不确定性(BIS 规则与相关新闻)。结论是:中小厂商更可能在“稳定供货 + 锁价 + 交期”上吃亏,而这直接影响投标报价与履约能力。
供应商类型与采购切入点(Top 10 示例表)
该表以“类型 + 代表性例子 + 典型采购入口”方式呈现,便于你规划渠道,而不是做品牌罗列(示例需要在公开资料中出现过,或与产业链图谱一致)。
| 供应商类型 | 代表性例子(示例,不穷举) | 典型采购入口/打法 |
|---|---|---|
| 整机服务器/加速服务器头部 | 浪潮信息、新华三(市场份额/政企资源强) | 集采目录/框架协议、政企大客户直签、与 ISV 联合投标 |
| 全栈 ICT 与生态整合 | 华为(智算集成服务占优势) | 政务云/行业云生态,软硬件一揽子方案 |
| 公有云/混合云厂商(带私有化方案) | 阿里云、百度智能云(报告提及一体机产业链角色) | “云+本地”混合试点、存量客户迁移、MaaS+一体机组合 |
| 运营商系 SI | 中国移动、中国电信(报告提及软件/模型/应用生态参与) | 政企专线/园区网络+一体机捆绑、运营商政企渠道 |
| 开源推理栈/平台化软件提供方 | 以 vLLM、SGLang 等为核心(项目本身非公司,不做实体示例) | 通过“性能与可运维”作为卖点,做行业二次封装与 SLA |
| “装机型”一体机初创/小厂 | 多为区域 SI/渠道商(公开名单随时间变化,本报告不虚构) | 靠区域关系与快速交付,需强化合规材料与售后承诺 |
| 国产 AI 加速芯片生态 | 寒武纪 等(报告列出国产芯片格局) | 在进口受限场景替代;与行业软件适配绑定 |
| 政采平台与代理机构 | 政采云等平台(平台本身不在本报告做实体标注) | 供应商入库、框架协议、代理机构合作 |
| 行业 ISV(垂直应用软件) | 金融风控/政务知识库/教育教务等厂商(未指定) | 联合打包:一体机=“硬件+模型+行业应用+数据治理” |
| 安全与身份治理能力提供方 | 以 LDAP/SSO/审计链路为重点(Open WebUI 支持 LDAP/SSO 配置) | 作为差异化:满足客户“统一身份、审计、最小权限” |
供应链与合规风险
内存与 SSD 价格波动
我们观察到“2025 下半年以来内存与 SSD 拉升、周度更新报价”与公开市场信息一致:TrendForce 对 DRAM/DDR4 与 NAND/SSD 的供需与价格趋势多次给出上行判断,媒体也报道了 OEM 厂商受到内存短缺影响、产品价格调整的现象(甚至反映到 DGX Spark 等产品价格上调)。
对一体机厂商的直接影响:
-
毛利难锁:你若不做锁价条款,很容易出现“中标价 < 采购价”的倒挂。
-
交付延期:内存条/企业级 NVMe 一旦缺货,整机无法出货。
-
规格变更风险:客户可能要求“指定品牌/型号/国产化清单”,进一步缩小可替代范围。
建议的 sourcing 策略(可操作):
-
以“平台级替代”为单位做备选:例如 DDR4 RDIMM 的容量档位与频率档位做 A/B/C 三档,而不是只认某个料号。
-
把“内存/SSD”从一次性报价改成“基础价 + 随行就市浮动条款”,并把 TrendForce 等指数/公开行情作为双方认可的参考(合同条款层面,不在本报告展开)。
-
建立二手/翻新服务器渠道作为“保底交付池”,但要在 SLA 中明确 MTBF 与保修边界(见运维章节)。
GPU 供给与出口管制的不确定性
对中国市场而言,GPU 不仅是价格波动问题,还包含合规与可获得性风险:美国 BIS 的先进计算出口管制规则与后续公告构成了对相关芯片/性能阈值的制度性约束;同时媒体持续报道面向中国市场的部分产品/型号限制事件。
这导致的商业后果往往是:
-
同一“显存容量/算力档位”的可买型号随政策与渠道变化而变化;
-
交付周期不可控,且客户可能要求出具来源/合规文件;
-
售后备件池难建立(尤其是同型号 GPU 的替换)。
CXL、内存池化与“分层存储”作为中长期对冲
《电子产品世界》转载文章把 CXL 描述为从“临时卸载”向“常态化内存分层管理”演进的重要抓手,强调未来可通过 CXL 交换机把远端大容量内存池纳入 GPU 可访问空间,形成热/温/冷数据分层(甚至把冷数据进一步下沉到 CXL SSD)。
对商业化的启示是:
-
短期(当下可卖):用“量化 + 大内存 + 稳定推理栈”交付确定性。
-
中期(技术差异化):把“内存分层/缓存策略/离线批处理”做成可配置能力,形成你与纯硬件拼装商的分水岭。
交付后运维与支持风险
常见不稳定模式清单
-
驱动与框架版本耦合导致回归vLLM 文档指出其为高性能需要编译大量 CUDA kernel,从而带来与 CUDA/PyTorch 构建配置的二进制不兼容风险,因此建议使用“全新环境/官方 wheel 或官方 Docker 镜像”。 这意味着你在交付时必须控制版本组合,否则升级极易引入回归。
-
热设计与电源瞬态多 GPU 工作负载下,峰值功耗与温度会导致:掉卡、ECC 错误(如启用)、系统重启等(本段为工程经验描述,不引用特定数据源)。建议把“温度墙/功耗墙”纳入验收:满载 2 小时不降频、不掉卡。
-
NUMA/PCIe 拓扑导致的吞吐抖动NUMA 相关最佳实践文档强调不同 NPS 配置会改变内存交错与 PCIe 设备本地性;若进程/线程不做亲和性控制,性能可能出现非线性波动。
-
Offload 带来的延迟与长尾vLLM 对 CPU offload 的描述明确指出:推理会在 forward pass 过程中从 CPU 内存向 GPU 内存“动态搬运”权重,要求快速互联,否则会有明显性能损失。 类似地,llama.cpp 的 server 形态可能存在“首请求延迟较大/冷启动慢”的现象(社区讨论与 issue 中可见),这在多用户使用时会被放大为体验问题。
-
知识库向量化与 UI 可用性Open WebUI 的社区反馈显示,在某些情况下“保存 embedding 到向量库”会造成其他用户界面冻结,属于典型的“上线后才暴露”的多用户问题。
预期售后支持负载与 SLA 建议
基于以上不稳定模式,你可以把售后负载拆成三类:
-
部署期(1–2 周):网络/权限/证书/模型下载失败/驱动不匹配,是工单高峰。
-
磨合期(1–2 月):并发上来后暴露的 KV cache、RAG 质量、向量化卡顿与磁盘占用爆炸。
-
稳定期:更多是“版本升级 + 硬件故障 + 新知识库导入”三类事件。
建议的 SLA 套餐(建议项,供你定价与分层服务):
-
基础版:5×8 支持;响应 4 小时;远程诊断;不含版本升级。
-
标准版:7×12 支持;响应 2 小时;季度升级窗口;关键告警联动。
-
政企版:7×24 支持;响应 30–60 分钟;备件池/先行更换;年度渗透测试/审计配合(若客户需要)。
监控、可观测与加固落地清单
-
Open WebUI:启用 API Keys 并结合 RBAC 做最小权限;监控文档提供了监控与 API keys 设置入口。
-
vLLM:使用官方 benchmark/指标体系,持续记录吞吐、延迟与并发极限,作为升级前后的回归基准。
-
反向代理:按 Open WebUI 的 Nginx HTTPS 指南处理 WebSocket/CORS,避免“上线后间歇性断连”。
-
文档解析:若启用 Docling,把其作为可选组件,并建立“解析失败/格式不兼容”的用户预期管理与回退路径。
Go‑to‑market 建议与风险清单
产品定位与差异化策略
若你的产品定义只是“PC/服务器 + RTX + 预装模型 + WebUI”,在红海中很难长期生存;你需要把差异化锚定在客户愿意为之付费、且进入门槛更高的部分:
-
安全与合规的工程化交付信通院报告强调政务/金融/医疗等行业对数据隐私要求严格,一体机的价值也在于“数据不出域、模型可控”。 你的差异化应包括:SSO/LDAP、API key 策略、审计留痕、离线更新包、最小暴露面网络策略(Open WebUI 在 SSO/LDAP 与环境变量层面给出了可落地的技术路径)。
-
行业工作流产品化把“模型对话”做成“业务流程”:例如政务知识库问答、会议纪要与公文写作、合同比对与批注、客服质检等。信通院报告列举了智能客服、智能检索、智能写作等场景普及率,并说明 RAG 作为主流配置。 你应把“知识库建设方法论(切分、embedding、rerank、引用)+ 模板 prompt + 评测集”打包成行业方案,而不是把所有责任丢给客户自己“上传文档”。
-
可运维与 SLA(把交付做成服务)把“性能基准、升级策略、故障演练”写进合同与交付文档:vLLM 的版本兼容性复杂、Open WebUI 的版本行为差异、以及 GPU/内存供应链的不确定性,都会在长期运维中变成客户风险。
定价模型建议(可操作框架)
建议采用“双层定价”:
-
硬件(一次性):BOM 成本 + 集成与测试费 + 备件池摊销。
-
软件与服务(订阅):基础版/标准版/政企版 SLA;按“并发用户数/知识库容量/升级频率/驻场”分档。这类模型能对冲内存/SSD 波动导致的硬件毛利下滑,并把你的核心能力(运维与合规交付)货币化。
政府/政企项目的简化销售打法
结合政府采购法“公开招标为主”的制度现实,你的销售动作可拆为五步(方法论建议,非法律意见):
-
入库:完成政采平台供应商入驻与资质材料准备(政采云入驻指南体现了典型流程)。
-
试点:用“路径 B 的可交付方案”打出 1–2 个可复制 demo(强调离线、内网、引用可追溯)。
-
标书要点:把“可用性验收指标(tokens/s、TTFT、并发)、安全策略(SSO/API keys/审计)、升级机制”写成可量化条款(vLLM benchmark 与 Open WebUI 监控/权限机制可作为技术依据)。
-
联合体:与行业 ISV/系统集成商做联合投标,避免你单独承担全部集成与合规压力(信通院产业链图谱本质也说明“整机/软件/应用”需要协同)。
-
售后承诺:对“供应链替代/锁价条款/备件池”给出清晰机制,以缓解客户对交期与持续运维的担忧。
风险与缓解清单(短版)
-
供应链涨价导致亏损 → 周度报价机制 + 锁价条款 + 替代料清单。
-
GPU 合规与交付不确定 → 预先定义“可交付 GPU 列表 + 等价替代规则 + 备件池策略”,避免投标时承诺单一型号。
-
“671B 可跑但很慢”引发客户落差 → 把路径 B 定位为“可用性/内网合规”,把“高并发/高吞吐”绑定到更高端 SKU(或多机集群),并用基准测试数据写进验收。
-
版本升级引发回归 → 采用官方 Docker 镜像与固定版本;升级前后跑同一 benchmark 套件;保留回滚。
-
知识库导入导致 UI 卡顿/体验差 → 设定导入窗口与队列;把 Docling 等解析链路作为“可选而非默认”;对大文件提供离线预处理。
成本-性能权衡示意图(用于产品线规划)
说明:下图为“示意性规划工具”,用来帮助你做 SKU 分层与报价策略;具体 tokens/s 与成本需用你的硬件与验收脚本实测后替换。
Qwen3.5 正式发布!开源多模态模型屠榜,全尺寸覆盖,本地部署+Telegram 全攻略!
2026年3月3日
就在刚刚,Qwen 正式发布了全新的开源模型系列 —— Qwen3.5 多模态模型。这一次更新,可以说在开源模型领域掀起了不小的震动。不仅性能几乎“屠榜”,而且全面迈向了原生多模态智能体时代,真正把开源模型带入了一个新的阶段。

Qwen3.5 多模态系列覆盖了从 0.8B 到 397B 的多个尺寸版本,适配不同硬件环境和应用场景。其中 0.8B 和 2B 两款模型体积极小,但推理速度极快,非常适合移动设备、物联网设备以及低延迟实时交互场景。在边缘端部署时,这类小模型可以实现更快响应和更低功耗,对于需要即时反馈的应用来说意义重大。
4B 版本则是“平民级”中的性能担当。它在资源消耗和性能之间取得了极佳平衡,非常适合作为轻量级 Agent 的核心大脑。对于本地部署用户或显存有限的开发者来说,这是一个兼顾智能水平与成本的理想选择。
9B 模型的表现则更进一步。它的综合能力可以媲美许多超大参数开源模型,在推理能力与多模态理解方面表现优异,同时对显存的要求却远低于百亿级以上模型,是服务器端部署中性价比极高的通用模型方案。
而最引人关注的,是开源的 Qwen3.5 397B-17B 模型。该模型总参数达到 3970 亿,但每次前向传播仅激活 170 亿参数,采用创新的混合架构,将线性注意力机制与稀疏混合专家(MoE)结构结合,在保持强大能力的同时显著优化了推理效率与成本。这种“高智能密度”的设计理念,让它在推理、编程、智能体能力、多模态理解等基准测试中全面领先。
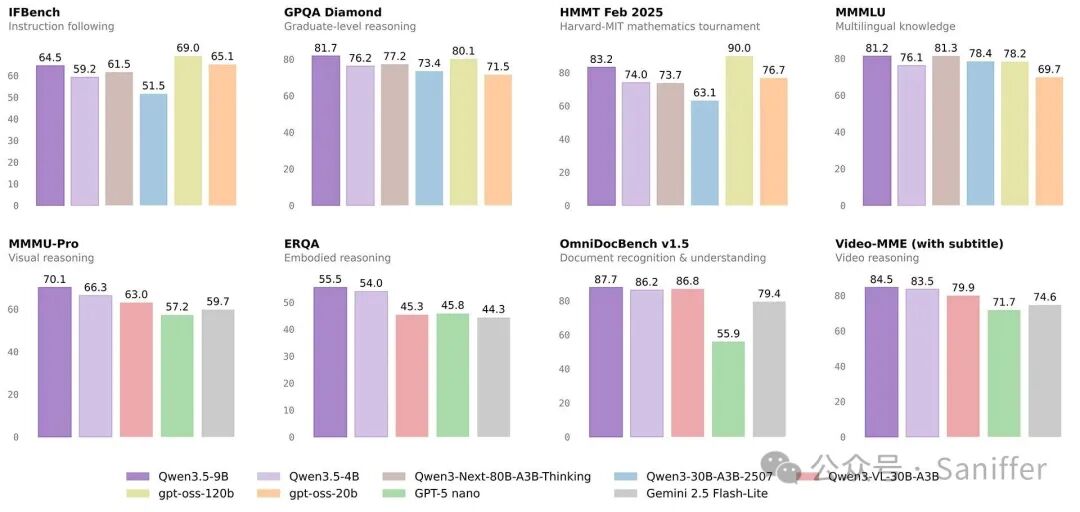
Qwen3.5 还大幅扩展了多语言与方言支持,从 119 种提升至 201 种语言与变体,为全球开发者与企业用户提供更广泛的可用性和更完善的支持。模型发布后迅速引爆 AI 社区,连 Elon Musk 也在社交媒体上点赞评论,称其“智能密度令人印象深刻”。
真正让 Qwen3.5 脱颖而出的,是它的原生多模态与 Agent 能力。它不仅可以理解文本与图像,还能够边思考、边搜索、边调用工具,实现真正意义上的智能体协作。在代码与智能体方向,Qwen3.5 可以协助进行网页开发、游戏开发,尤其是在前端构建与界面适配方面表现出色。开发者只需输入自然语言指令,它便能生成可运行代码,并支持实时迭代。
基于 Qwen3.5 底座模型打造的 Qwen Code,更进一步提升了 Web-coding 体验。它能够将自然语言直接转化为代码,实现实时开发与创意生成任务,包括网页构建、项目原型设计,甚至视频生成等创新型任务,为日常编程与探索性开发带来流畅高效的体验。
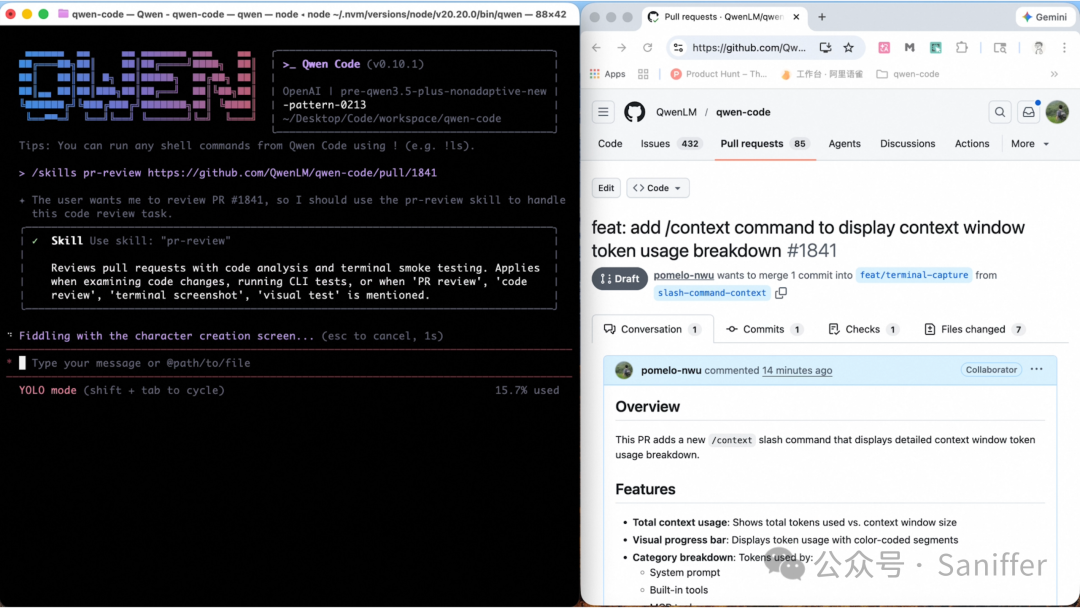
在视觉智能体方向,Qwen3.5 可以自主操作手机或电脑完成任务。移动端已适配主流应用,支持自然语言驱动操作;电脑端则可处理跨应用数据整理与多步骤流程自动化,有效减少重复人工操作,显著提升效率。
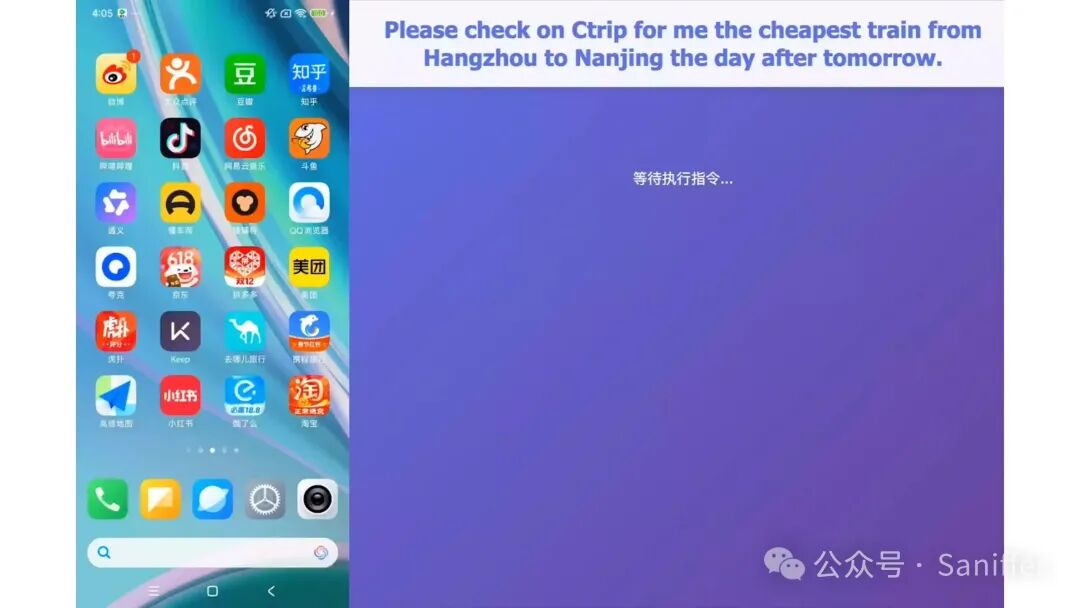
视觉编程能力同样令人惊艳。Qwen3.5 可以将草图转化为结构清晰的前端代码,将简单游戏视频还原为逻辑框架,甚至将长视频内容提炼为结构化网页或可视化图表,大幅降低从创意到实现的门槛。
在空间智能理解方面,Qwen3.5 通过对图像像素与位置信息的建模,在物体计数、相对位置判断与空间关系描述任务中更加精准。它能够有效缓解因遮挡或视觉变化带来的误判,在自动驾驶场景理解与机器人导航等具身智能领域展现出良好潜力。
相比上一代视觉语言模型,Qwen3.5 在学科解题与复杂视觉推理任务上更加稳健。它能够结合图像内容与上下文进行多步逻辑推理,为教育与科研领域的多模态 Agent 应用提供更加可靠的基础能力。


如果你想在本地部署 Qwen3.5,可以通过 Ollama 来运行模型。Ollama 支持完全本地化部署与离线运行,保障数据安全,同时也能与自动化工具 OpenClaw 快速集成。不同尺寸模型对显存要求不同,例如部分版本约需 6GB 左右显存即可运行,而更大尺寸模型则需要更高显存配置。根据自身硬件条件选择合适版本即可。
通过 Ollama 下载模型后,可在终端运行对应命令进行加载。如果希望更友好地使用,也可以通过外部 UI 插件直接调用本地模型。在集成 OpenClaw 后,Qwen3.5 可以实现网页搜索、信息收集、结构化报告生成,以及自动化编程任务。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)