保姆级RAG教程:仅用几十行代码!UltraRAG 2.0+Milvus+MCP整合实战,超详细入门到精通指南!
做RAG系统,要解决的核心问题是什么?总结有二:**成本过高**,如何在多轮推理、动态检索、自适应知识组织等高级特性下,避免工程实现的巨大开销?
做RAG系统,要解决的核心问题是什么?
总结有二:
成本过高,如何在多轮推理、动态检索、自适应知识组织等高级特性下,避免工程实现的巨大开销?
工程落地太复杂,各种大模型框架、向量数据库门槛不低,时间花费在了各种细节的调参、选索引之上。
要解决这个问题,清华大学THUNLP实验室联合东北大学NEUIR、OpenBMB与AI9Stars推出UltraRAG 2.0,可以作为一个很好的参考。
通过组件化封装、声明式编排以及轻量调度,UltraRAG 2.0可以用YAML配置文件替代传统编码,工程师只要几十行声明式语句就能搞定串行、循环、条件分支等复杂逻辑,以低代码实现多阶段推理系统。
01
RAG Pipeline架构
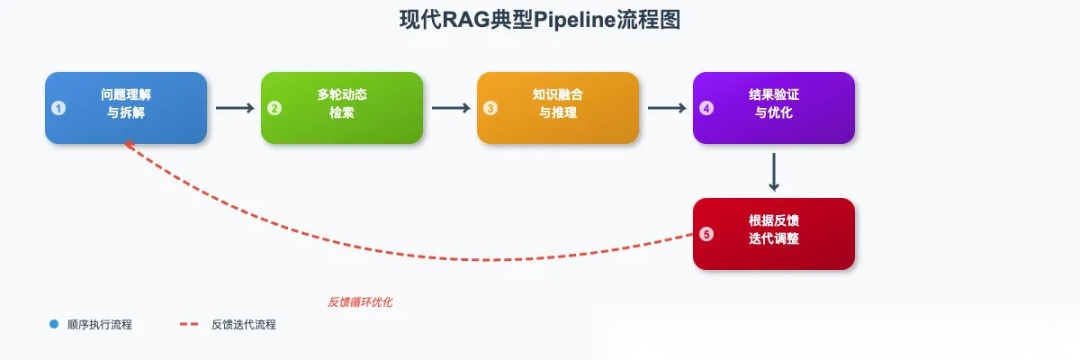
现如今,RAG技术正从早期检索+生成的简单拼接,升级为工程实现复杂、技术门槛高、能够搞定多轮推理、动态检索的复杂AI应用领域。典型代表如DeepResearch、Search-o1等。
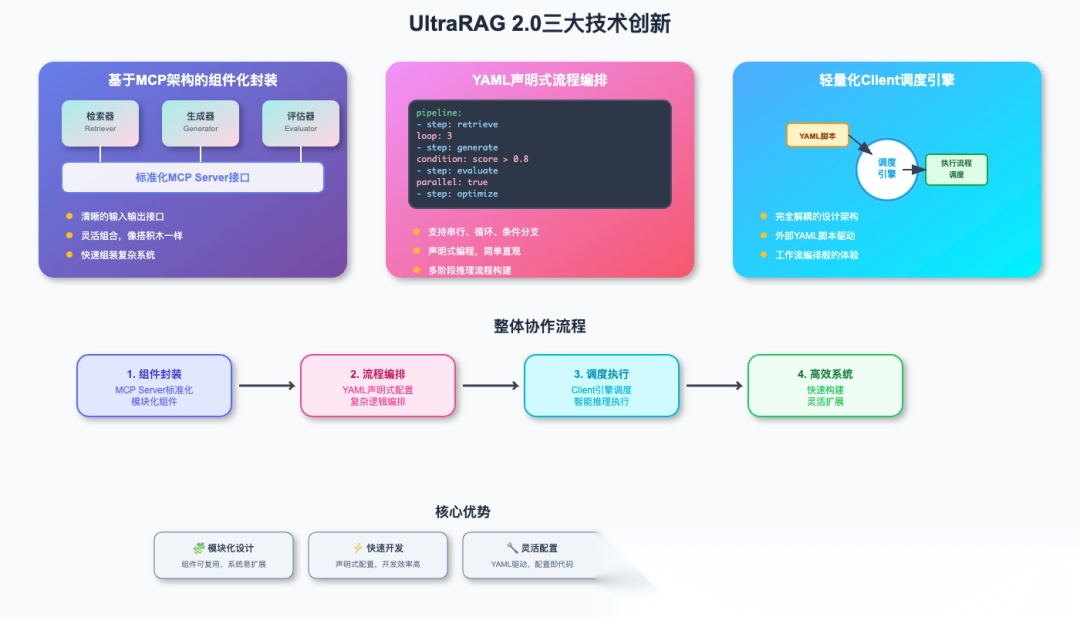
在此基础上,UltraRAG 2.0有三大技术创新:
首先是组件化封装,基于MCP架构将复杂的RAG组件标准化为独立服务,实现了真正的模块化设计,开发者只需关注业务逻辑,无需处理底层通信细节。
其次是声明式编排,面对复杂的多阶段推理流程,传统方法很难定位具体哪个环节出现问题。UltraRAG 2.0的YAML配置让整个执行流程一目了然,每个步骤的输入输出都有清晰的追踪记录,调试效率提升数倍。
最后是轻量调度,内置的Client引擎确保了系统的高效运行和完全解耦,传统RAG系统往往是单体架构,添加新功能需要修改核心代码。UltraRAG 2.0采用微服务化的MCP架构,新组件可以独立开发和部署,系统扩展可以像安装插件一样简单。
02
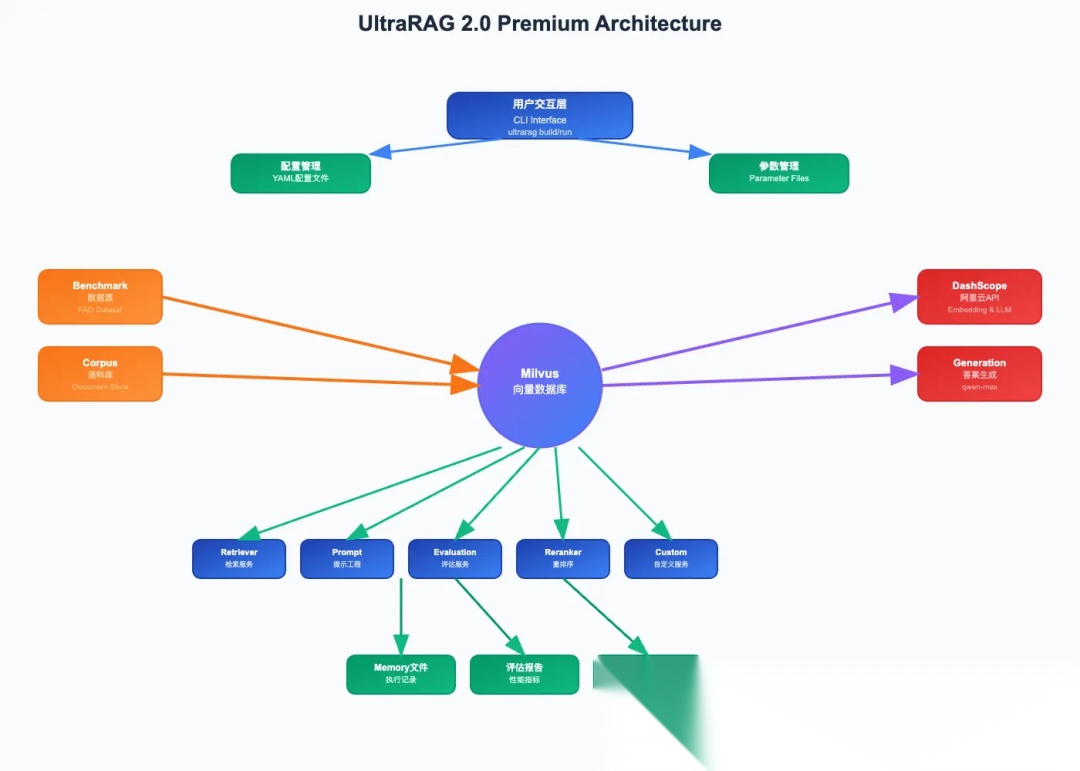
为RAG Pipeline集成Milvus
在UltraRAG 2.0的技术栈中,向量数据库的选择至关重要,我们可以通过集成方式使项目支持Milvus。集成后用户可以通过简单的 ultrarag build 和 ultrarag run 命令来构建索引和执行查询,系统会自动加载配置并协调各个服务模块完成任务。
演示目标:
1.集成Milvus到UltraRAG2.0项目中
2.自定义基于Milvus的Pipeline
3.测试跑通项目
4.项目运行结果评估分数可忽略(不是本地演示目的)
数据准备
说明:使用Milvus仓库的FAQ作为数据集,格式是jsonl。
{"id":"faq_0","contents":"If you failed to pull the Milvus Docker image from Docker Hub, try adding other registry mirrors. Users from the Chinese mainland can add the URL https://registry.docker-cn.com to the registry-mirrors array in /etc.docker/daemon.json."}{"id":"faq_1","contents":"Docker is an efficient way to deploy Milvus, but not the only way. You can also deploy Milvus from source code. This requires Ubuntu (18.04 or higher) or CentOS (7 or higher). See Building Milvus from Source Code for more information."}{"id":"faq_2","contents":"Recall is affected mainly by index type and search parameters. For FLAT index, Milvus takes an exhaustive scan within a collection, with a 100% return. For IVF indexes, the nprobe parameter determines the scope of a search within the collection. Increasing nprobe increases the proportion of vectors searched and recall, but diminishes query performance."}{"id":"faq_3","contents":"Milvus does not support modification to configuration files during runtime. You must restart Milvus Docker for configuration file changes to take effect."}{"id":"faq_4","contents":"If Milvus is started using Docker Compose, run docker ps to observe how many Docker containers are running and check if Milvus services started correctly. For Milvus standalone, you should be able to observe at least three running Docker containers, one being the Milvus service and the other two being etcd management and storage service."}{"id":"faq_5","contents":"The time difference is usually due to the fact that the host machine does not use Coordinated Universal Time (UTC). The log files inside the Docker image use UTC by default. If your host machine does not use UTC, this issue may occur."}{"id":"faq_6","contents":"Milvus requires your CPU to support a SIMD instruction set: SSE4.2, AVX, AVX2, or AVX512. CPU must support at least one of these to ensure that Milvus operates normally."}{"id":"faq_7","contents":"Milvus requires your CPU to support a SIMD instruction set: SSE4.2, AVX, AVX2, or AVX512. CPU must support at least one of these to ensure that Milvus operates normally. An illegal instruction error returned during startup suggests that your CPU does not support any of the above four instruction sets."}{"id":"faq_8","contents":"Yes. You can install Milvus on Windows either by compiling from source code or from a binary package. See Run Milvus on Windows to learn how to install Milvus on Windows."}{"id":"faq_9","contents":"It is not recommended to install PyMilvus on Windows. But if you have to install PyMilvus on Windows but got an error, try installing it in a Conda environment. See Install Milvus SDK for more information about how to install PyMilvus in the Conda environment."}
1.第一步:部署Milvus向量数据库
1.1.下载部署文件
wget https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml -O docker-compose.yml
1.2.启动Milvus服务
docker-compose up -d
docker-compose ps -a

2.第二步:Clone项目
git clone https://github.com/OpenBMB/UltraRAG.git
3.第三步:Pipleline实现
3.1 集成Milvus向量数据库
说明:原有支持类型中集成Milvus
vim ultraRAG/UltraRAG/servers/retriever/src/retriever.py
import osfrom urllib.parse import urlparse, urlunparsefrom typing importAny, Dict, List, Optionalimport aiohttpimport asyncioimport jsonlinesimport numpy as npimport pandas as pdfrom tqdm import tqdmfrom flask import Flask, jsonify, requestfrom openai import AsyncOpenAI, OpenAIErrorfrom fastmcp.exceptions import NotFoundError, ToolError, ValidationErrorfrom ultrarag.server import UltraRAG_MCP_Serverapp = UltraRAG_MCP_Server("retriever")retriever_app = Flask(__name__)classRetriever:def__init__(self, mcp_inst: UltraRAG_MCP_Server): mcp_inst.tool( self.retriever_init, output="retriever_path,corpus_path,index_path,faiss_use_gpu,infinity_kwargs,cuda_devices->None", ) mcp_inst.tool( self.retriever_init_openai, output="corpus_path,openai_model,api_base,api_key->None", ) mcp_inst.tool( self.retriever_init_Milvus, output="corpus_path,Milvus_host,Milvus_port,collection_name,embedding_dim->None", ) mcp_inst.tool( self.retriever_embed, output="embedding_path,overwrite,use_alibaba_cloud,alibaba_api_key,alibaba_model,alibaba_endpoint->None", ) mcp_inst.tool( self.retriever_embed_openai, output="embedding_path,overwrite->None", ) mcp_inst.tool( self.retriever_index, output="embedding_path,index_path,overwrite,index_chunk_size->None", ) mcp_inst.tool( self.retriever_index_lancedb, output="embedding_path,lancedb_path,table_name,overwrite->None", )# Note: retriever_index_Milvus has been removed# Use setup_Milvus_collection.py for collection creation and indexing mcp_inst.tool( self.retriever_search, output="q_ls,top_k,query_instruction,use_openai->ret_psg", ) mcp_inst.tool( self.retriever_search_lancedb, output="q_ls,top_k,query_instruction,use_openai,lancedb_path,table_name,filter_expr->ret_psg", ) mcp_inst.tool( self.retriever_search_Milvus, output="q_ls,top_k,query_instruction,use_openai->ret_psg", ) mcp_inst.tool( self.retriever_deploy_service, output="retriever_url->None", ) mcp_inst.tool( self.retriever_deploy_search, output="retriever_url,q_ls,top_k,query_instruction->ret_psg", ) mcp_inst.tool( self.retriever_exa_search, output="q_ls,top_k->ret_psg", ) mcp_inst.tool( self.retriever_tavily_search, output="q_ls,top_k->ret_psg", )defretriever_init( self, retriever_path: str, corpus_path: str, index_path: Optional[str] = None, faiss_use_gpu: bool = False, infinity_kwargs: Optional[Dict[str, Any]] = None, cuda_devices: Optional[str] = None, ):try:import faissexcept ImportError: err_msg = "faiss is not installed. Please install it with `conda install -c pytorch faiss-cpu` or `conda install -c pytorch faiss-gpu`." app.logger.error(err_msg)raise ImportError(err_msg)try:from infinity_emb.log_handler import LOG_LEVELSfrom infinity_emb import AsyncEngineArray, EngineArgsexcept ImportError: err_msg = "infinity_emb is not installed. Please install it with `pip install infinity-emb`." app.logger.error(err_msg)raise ImportError(err_msg) self.faiss_use_gpu = faiss_use_gpu app.logger.setLevel(LOG_LEVELS["warning"])if cuda_devices isnotNone:assertisinstance(cuda_devices, str), "cuda_devices should be a string" os.environ["CUDA_VISIBLE_DEVICES"] = cuda_devices infinity_kwargs = infinity_kwargs or {} self.model = AsyncEngineArray.from_args( [EngineArgs(model_name_or_path=retriever_path, **infinity_kwargs)] )[0] self.contents = []with jsonlines.open(corpus_path, mode="r") as reader: self.contents = [item["contents"] for item in reader] self.faiss_index = Noneif index_path isnotNoneand os.path.exists(index_path): cpu_index = faiss.read_index(index_path)if self.faiss_use_gpu: co = faiss.GpuMultipleClonerOptions() co.shard = True co.useFloat16 = Truetry: self.faiss_index = faiss.index_cpu_to_all_gpus(cpu_index, co) app.logger.info(f"Loaded index to GPU(s).")except RuntimeError as e: app.logger.error(f"GPU index load failed: {e}. Falling back to CPU." ) self.faiss_use_gpu = False self.faiss_index = cpu_indexelse: self.faiss_index = cpu_index app.logger.info("Loaded index on CPU.") app.logger.info(f"Retriever index path has already been built")else: app.logger.warning(f"Cannot find path: {index_path}") self.faiss_index = None app.logger.info(f"Retriever initialized")defretriever_init_openai( self, corpus_path: str, openai_model: str, api_base: str, api_key: str, ):ifnot openai_model:raise ValueError("openai_model must be provided.")ifnot api_base ornotisinstance(api_base, str):raise ValueError("api_base must be a non-empty string.")ifnot api_key ornotisinstance(api_key, str):raise ValueError("api_key must be a non-empty string.") self.contents = []with jsonlines.open(corpus_path, mode="r") as reader: self.contents = [item["contents"] for item in reader]try: self.openai_model = openai_model self.client = AsyncOpenAI(base_url=api_base, api_key=api_key) app.logger.info(f"OpenAI client initialized with model '{openai_model}' and base '{api_base}'" )except OpenAIError as e: app.logger.error(f"Failed to initialize OpenAI client: {e}")defretriever_init_Milvus( self, corpus_path: str, Milvus_host: str = "192.168.8.130", Milvus_port: int = 19530, collection_name: str = "ultrarag_collection_v3", embedding_dim: int = 1024, ):"""Initialize Milvus vector database connection. Args: corpus_path (str): Path to the corpus JSONL file (for reference only) Milvus_host (str): Milvus server host Milvus_port (int): Milvus server port collection_name (str): Name of the existing collection to use embedding_dim (int): Dimension of embeddings (for reference only) Note: This method assumes the collection already exists and is properly configured. Use setup_Milvus_collection.py to create and configure collections. """try:from pyMilvus import connections, Collection, utilityexcept ImportError: err_msg = "pyMilvus is not installed. Please install it with `pip install pyMilvus`." app.logger.error(err_msg)raise ImportError(err_msg)# Initialize Alibaba Cloud client for embeddingstry:from openai import AsyncOpenAIexcept ImportError: err_msg = "openai is not installed. Please install it with `pip install openai`." app.logger.error(err_msg)raise ImportError(err_msg)# Set up Alibaba Cloud client for embeddings self.alibaba_client = AsyncOpenAI( base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key="sk-xxxxxx" ) self.alibaba_model = "text-embedding-v3"# Load corpus data (for reference, not used in search) self.contents = []with jsonlines.open(corpus_path, mode="r") as reader: self.contents = [item["contents"] for item in reader]# Connect to Milvustry: connections.connect( alias="default", host=Milvus_host, port=Milvus_port ) app.logger.info(f"Connected to Milvus at {Milvus_host}:{Milvus_port}")except Exception as e: app.logger.error(f"Failed to connect to Milvus: {e}")raise ConnectionError(f"Failed to connect to Milvus: {e}")# Store Milvus configuration self.Milvus_host = Milvus_host self.Milvus_port = Milvus_port self.collection_name = collection_name self.embedding_dim = embedding_dim# Connect to existing collection (must exist and be loaded)ifnot utility.has_collection(collection_name):raise ValueError(f"Collection '{collection_name}' does not exist. Please create it first using setup_Milvus_collection.py") self.Milvus_collection = Collection(collection_name)# Verify collection is loaded load_state = utility.load_state(collection_name)if load_state != "Loaded": app.logger.warning(f"Collection '{collection_name}' is not loaded (state: {load_state}). Attempting to load...")try: self.Milvus_collection.load() utility.wait_for_loading_complete(collection_name=collection_name, timeout=60) app.logger.info(f"Successfully loaded collection '{collection_name}'")except Exception as e:raise RuntimeError(f"Failed to load collection '{collection_name}': {e}")# Verify collection has data and indexes entity_count = self.Milvus_collection.num_entitiesif entity_count == 0: app.logger.warning(f"Collection '{collection_name}' is empty")else: app.logger.info(f"Connected to collection '{collection_name}' with {entity_count} entities") app.logger.info("Milvus retriever initialized successfully")asyncdefretriever_embed( self, embedding_path: Optional[str] = None, overwrite: bool = False, use_alibaba_cloud: bool = False, alibaba_api_key: Optional[str] = None, alibaba_model: str = "text-embedding-v3", alibaba_endpoint: Optional[str] = None, ):if embedding_path isnotNone:ifnot embedding_path.endswith(".npy"): err_msg = f"Embedding save path must end with .npy, now the path is {embedding_path}" app.logger.error(err_msg)raise ValidationError(err_msg) output_dir = os.path.dirname(embedding_path)else: current_file = os.path.abspath(__file__) project_root = os.path.dirname(os.path.dirname(current_file)) output_dir = os.path.join(project_root, "output", "embedding") embedding_path = os.path.join(output_dir, "embedding.npy")ifnot overwrite and os.path.exists(embedding_path): app.logger.info("embedding already exists, skipping")return os.makedirs(output_dir, exist_ok=True)if use_alibaba_cloud:# Use Alibaba Cloud API for embeddingsifnot alibaba_api_key ornot alibaba_endpoint:raise ValueError("Alibaba Cloud API key and endpoint must be provided") client = AsyncOpenAI(base_url=alibaba_endpoint, api_key=alibaba_api_key)asyncdefalibaba_embed(texts): embeddings = [] batch_size = 100# Process in batches to avoid rate limitsfor i inrange(0, len(texts), batch_size): batch = texts[i:i+batch_size]try: response = await client.embeddings.create(input=batch, model=alibaba_model ) batch_embeddings = [item.embedding for item in response.data] embeddings.extend(batch_embeddings) app.logger.info(f"Processed batch {i//batch_size + 1}/{(len(texts)-1)//batch_size + 1}")except Exception as e: app.logger.error(f"Error in Alibaba Cloud embedding batch {i//batch_size + 1}: {e}")raisereturn embeddings embeddings = await alibaba_embed(self.contents) app.logger.info("Alibaba Cloud embedding completed")else:# Use local model for embeddingsasyncwith self.model: embeddings, usage = await self.model.embed(sentences=self.contents) embeddings = np.array(embeddings, dtype=np.float16) np.save(embedding_path, embeddings) app.logger.info("embedding success")asyncdefretriever_embed_openai( self, embedding_path: Optional[str] = None, overwrite: bool = False, ):if embedding_path isnotNone:ifnot embedding_path.endswith(".npy"): err_msg = f"Embedding save path must end with .npy, now the path is {embedding_path}" app.logger.error(err_msg)raise ValidationError(err_msg) output_dir = os.path.dirname(embedding_path)else: current_file = os.path.abspath(__file__) project_root = os.path.dirname(os.path.dirname(current_file)) output_dir = os.path.join(project_root, "output", "embedding") embedding_path = os.path.join(output_dir, "embedding.npy")ifnot overwrite and os.path.exists(embedding_path): app.logger.info("embedding already exists, skipping") os.makedirs(output_dir, exist_ok=True)asyncdefopenai_embed(texts): embeddings = []for text in texts: response = await self.client.embeddings.create(input=text, model=self.openai_model ) embeddings.append(response.data[0].embedding)return embeddings embeddings = await openai_embed(self.contents) embeddings = np.array(embeddings, dtype=np.float16) np.save(embedding_path, embeddings) app.logger.info("embedding success")defretriever_index( self, embedding_path: str, index_path: Optional[str] = None, overwrite: bool = False, index_chunk_size: int = 50000, ):""" Build a Faiss index from an embedding matrix. Args: embedding_path (str): .npy file of shape (N, dim), dtype float32. index_path (str, optional): where to save .index file. overwrite (bool): overwrite existing index. index_chunk_size (int): batch size for add_with_ids. """try:import faissexcept ImportError: err_msg = "faiss is not installed. Please install it with `conda install -c pytorch faiss-cpu` or `conda install -c pytorch faiss-gpu`." app.logger.error(err_msg)raise ImportError(err_msg)ifnot os.path.exists(embedding_path): app.logger.error(f"Embedding file not found: {embedding_path}") NotFoundError(f"Embedding file not found: {embedding_path}")if index_path isnotNone:ifnot index_path.endswith(".index"): app.logger.error(f"Parameter index_path must end with .index now is {index_path}" ) ValidationError(f"Parameter index_path must end with .index now is {index_path}" ) output_dir = os.path.dirname(index_path)else: current_file = os.path.abspath(__file__) project_root = os.path.dirname(os.path.dirname(current_file)) output_dir = os.path.join(project_root, "output", "index") index_path = os.path.join(output_dir, "index.index")ifnot overwrite and os.path.exists(index_path): app.logger.info("Index already exists, skipping") os.makedirs(output_dir, exist_ok=True) embedding = np.load(embedding_path) dim = embedding.shape[1] vec_ids = np.arange(embedding.shape[0]).astype(np.int64)# with cpu cpu_flat = faiss.IndexFlatIP(dim) cpu_index = faiss.IndexIDMap2(cpu_flat)# chunk to write total = embedding.shape[0]for start inrange(0, total, index_chunk_size): end = min(start + index_chunk_size, total) cpu_index.add_with_ids(embedding[start:end], vec_ids[start:end])# with gpuif self.faiss_use_gpu: co = faiss.GpuMultipleClonerOptions() co.shard = True co.useFloat16 = Truetry: gpu_index = faiss.index_cpu_to_all_gpus(cpu_index, co) index = gpu_index app.logger.info("Using GPU for indexing with sharding")except RuntimeError as e: app.logger.warning(f"GPU indexing failed ({e}); fall back to CPU") self.faiss_use_gpu = False index = cpu_indexelse: index = cpu_index# save faiss.write_index(cpu_index, index_path)if self.faiss_index isNone: self.faiss_index = index app.logger.info("Indexing success")defretriever_index_lancedb( self, embedding_path: str, lancedb_path: str, table_name: str, overwrite: bool = False, ):""" Build a Faiss index from an embedding matrix. Args: embedding_path (str): .npy file of shape (N, dim), dtype float32. lancedb_path (str): directory path to store LanceDB tables. table_name (str): the name of the LanceDB table. overwrite (bool): overwrite existing index. """try:import lancedbexcept ImportError: err_msg = "lancedb is not installed. Please install it with `pip install lancedb`." app.logger.error(err_msg)raise ImportError(err_msg)ifnot os.path.exists(embedding_path): app.logger.error(f"Embedding file not found: {embedding_path}") NotFoundError(f"Embedding file not found: {embedding_path}")if lancedb_path isNone: current_file = os.path.abspath(__file__) project_root = os.path.dirname(os.path.dirname(current_file)) lancedb_path = os.path.join(project_root, "output", "lancedb") os.makedirs(lancedb_path, exist_ok=True) db = lancedb.connect(lancedb_path)if table_name in db.table_names() andnot overwrite: info_msg = f"LanceDB table '{table_name}' already exists, skipping" app.logger.info(info_msg)return {"status": info_msg}elif table_name in db.table_names() and overwrite:import shutil shutil.rmtree(os.path.join(lancedb_path, table_name)) app.logger.info(f"Overwriting LanceDB table '{table_name}'") embedding = np.load(embedding_path) ids = [str(i) for i inrange(len(embedding))] data = [{"id": i, "vector": v} for i, v inzip(ids, embedding)] df = pd.DataFrame(data) db.create_table(table_name, data=df) app.logger.info("LanceDB indexing success")# Note: retriever_index_Milvus method has been removed# Collection creation and indexing is now handled by setup_Milvus_collection.py# This simplifies the retriever logic and separates concernsasyncdefretriever_search( self, query_list: List[str], top_k: int = 5, query_instruction: str = "", use_openai: bool = False, ) -> Dict[str, List[List[str]]]:ifisinstance(query_list, str): query_list = [query_list] queries = [f"{query_instruction}{query}"for query in query_list]if use_openai:asyncdefopenai_embed(texts): embeddings = []for text in texts: response = await self.client.embeddings.create(input=text, model=self.openai_model ) embeddings.append(response.data[0].embedding)return embeddings query_embedding = await openai_embed(queries)else:asyncwith self.model: query_embedding, usage = await self.model.embed(sentences=queries) query_embedding = np.array(query_embedding, dtype=np.float16) app.logger.info("query embedding finish") scores, ids = self.faiss_index.search(query_embedding, top_k) rets = []for i, query inenumerate(query_list): cur_ret = []for _, idinenumerate(ids[i]): cur_ret.append(self.contents[id]) rets.append(cur_ret) app.logger.debug(f"ret_psg: {rets}")return {"ret_psg": rets}asyncdefretriever_search_Milvus( self, query_list: List[str], top_k: int = 5, query_instruction: str = "", use_openai: bool = False, ) -> Dict[str, List[List[str]]]:""" Search in Milvus vector database. Args: query_list (List[str]): List of query strings top_k (int): Number of top results to return query_instruction (str): Instruction to prepend to queries use_openai (bool): Whether to use OpenAI for embedding Returns: Dict[str, List[List[str]]]: Search results """try:from pyMilvus import connections, Collectionexcept ImportError: err_msg = "pyMilvus is not installed. Please install it with `pip install pyMilvus`." app.logger.error(err_msg)raise ImportError(err_msg)ifisinstance(query_list, str): query_list = [query_list] queries = [f"{query_instruction}{query}"for query in query_list]# Generate query embeddingsif use_openai:asyncdefopenai_embed(texts): embeddings = []for text in texts: response = await self.client.embeddings.create(input=text, model=self.openai_model ) embeddings.append(response.data[0].embedding)return embeddings query_embedding = await openai_embed(queries)else:# Use Alibaba Cloud API for embeddingsasyncdefalibaba_embed(texts): embeddings = []for text in texts: response = await self.alibaba_client.embeddings.create(input=text, model=self.alibaba_model ) embeddings.append(response.data[0].embedding)return embeddings query_embedding = await alibaba_embed(queries) query_embedding = np.array(query_embedding, dtype=np.float32) app.logger.info("Query embedding finished")# Ensure collection is loaded before searchtry:ifnot self.Milvus_collection.has_index(): app.logger.warning("Collection has no index, search may be slow")# Always load collection before search to ensure it's available app.logger.debug("Loading collection for search...") self.Milvus_collection.load() app.logger.debug("Collection loaded successfully")except Exception as load_error: app.logger.error(f"Failed to load collection: {load_error}")return {"ret_psg": [[]] * len(query_list)}# Search in Milvus search_params = {"metric_type": "IP","params": {"nprobe": 10} } rets = []for i, query_vec inenumerate(query_embedding):try:# Perform search with proper error handling results = self.Milvus_collection.search( data=[query_vec.tolist()], anns_field="embedding", param=search_params, limit=top_k, output_fields=["text"], expr=None# Explicitly set no filter expression )# Extract results with null checks cur_ret = []for hit in results[0]: text_content = hit.entity.get("text")if text_content isnotNone: cur_ret.append(text_content)else: app.logger.warning(f"Found null text content in search result") rets.append(cur_ret)except Exception as e: app.logger.error(f"Milvus search failed for query {i}: {e}")# Return empty result for failed query rets.append([]) app.logger.debug(f"ret_psg: {rets}")return {"ret_psg": rets}asyncdefretriever_search_lancedb( self, query_list: List[str], top_k: Optional[int] | None = None, query_instruction: str = "", use_openai: bool = False, lancedb_path: str = "", table_name: str = "", filter_expr: Optional[str] = None, ) -> Dict[str, List[List[str]]]:try:import lancedbexcept ImportError: err_msg = "lancedb is not installed. Please install it with `pip install lancedb`." app.logger.error(err_msg)raise ImportError(err_msg)ifisinstance(query_list, str): query_list = [query_list] queries = [f"{query_instruction}{query}"for query in query_list]if use_openai:asyncdefopenai_embed(texts): embeddings = []for text in texts: response = await self.client.embeddings.create(input=text, model=self.openai_model ) embeddings.append(response.data[0].embedding)return embeddings query_embedding = await openai_embed(queries)else:asyncwith self.model: query_embedding, usage = await self.model.embed(sentences=queries) query_embedding = np.array(query_embedding, dtype=np.float16) app.logger.info("query embedding finish") rets = []ifnot lancedb_path: NotFoundError(f"`lancedb_path` must be provided.") db = lancedb.connect(lancedb_path) self.lancedb_table = db.open_table(table_name)for i, query_vec inenumerate(query_embedding): q = self.lancedb_table.search(query_vec).limit(top_k)if filter_expr: q = q.where(filter_expr) df = q.to_df() cur_ret = []for id_str in df["id"]: id_int = int(id_str) cur_ret.append(self.contents[id_int]) rets.append(cur_ret) app.logger.debug(f"ret_psg: {rets}")return {"ret_psg": rets}asyncdefretriever_deploy_service( self, retriever_url: str, ):# Ensure URL is valid, adding "http://" prefix if necessary retriever_url = retriever_url.strip()ifnot retriever_url.startswith("http://") andnot retriever_url.startswith("https://" ): retriever_url = f"http://{retriever_url}" url_obj = urlparse(retriever_url) retriever_host = url_obj.hostname retriever_port = ( url_obj.port if url_obj.port else8080 ) # Default port if none provided @retriever_app.route("/search", methods=["POST"])asyncdefdeploy_retrieval_model(): data = request.get_json() query_list = data["query_list"] top_k = data["top_k"]asyncwith self.model: query_embedding, _ = await self.model.embed(sentences=query_list) query_embedding = np.array(query_embedding, dtype=np.float16) _, ids = self.faiss_index.search(query_embedding, top_k) rets = []for i, _ inenumerate(query_list): cur_ret = []for _, idinenumerate(ids[i]): cur_ret.append(self.contents[id]) rets.append(cur_ret)return jsonify({"ret_psg": rets}) retriever_app.run(host=retriever_host, port=retriever_port) app.logger.info(f"employ embedding server at {retriever_url}")asyncdefretriever_deploy_search( self, retriever_url: str, query_list: List[str], top_k: Optional[int] | None = None, query_instruction: str = "", ):# Validate the URL format url = retriever_url.strip()ifnot url.startswith("http://") andnot url.startswith("https://"): url = f"http://{url}" url_obj = urlparse(url) api_url = urlunparse(url_obj._replace(path="/search")) app.logger.info(f"Calling url: {api_url}")ifisinstance(query_list, str): query_list = [query_list] query_list = [f"{query_instruction}{query}"for query in query_list] payload = {"query_list": query_list}if top_k isnotNone: payload["top_k"] = top_kasyncwith aiohttp.ClientSession() as session:asyncwith session.post( api_url, json=payload, ) as response:if response.status == 200: response_data = await response.json() app.logger.debug(f"status_code: {response.status}, response data: {response_data}" )return response_dataelse: err_msg = (f"Failed to call {retriever_url} with code {response.status}" ) app.logger.error(err_msg)raise ToolError(err_msg)asyncdefretriever_exa_search( self, query_list: List[str], top_k: Optional[int] | None = None, ) -> dict[str, List[List[str]]]:try:from exa_py import AsyncExafrom exa_py.api import Resultexcept ImportError: err_msg = ("exa_py is not installed. Please install it with `pip install exa_py`." ) app.logger.error(err_msg)raise ImportError(err_msg) exa_api_key = os.environ.get("EXA_API_KEY", "") exa = AsyncExa(api_key=exa_api_key if exa_api_key else"EMPTY") sem = asyncio.Semaphore(16)asyncdefcall_with_retry( idx: int, q: str, retries: int = 3, delay: float = 1.0 ):asyncwith sem:for attempt inrange(retries):try: resp = await exa.search_and_contents( q, num_results=top_k, text=True, ) results: List[Result] = getattr(resp, "results", []) or [] psg_ls: List[str] = [(r.text or"") for r in results]return idx, psg_lsexcept Exception as e: status = getattr(getattr(e, "response", None), "status_code", None )if status == 401or"401"instr(e):raise RuntimeError("Unauthorized (401): Access denied by Exa API. ""Invalid or missing EXA_API_KEY." ) from e app.logger.warning(f"[Retry {attempt+1}] EXA failed (idx={idx}): {e}" )await asyncio.sleep(delay)return idx, [] tasks = [ asyncio.create_task(call_with_retry(i, q)) for i, q inenumerate(query_list) ] ret: List[List[str]] = [None] * len(query_list) iterator = tqdm( asyncio.as_completed(tasks), total=len(tasks), desc="EXA Searching: " )for fut in iterator: idx, psg_ls = await fut ret[idx] = psg_lsreturn {"ret_psg": ret}asyncdefretriever_tavily_search( self, query_list: List[str], top_k: Optional[int] | None = None, ) -> dict[str, List[List[str]]]:try:from tavily import ( AsyncTavilyClient, BadRequestError, UsageLimitExceededError, InvalidAPIKeyError, MissingAPIKeyError, )except ImportError: err_msg = "tavily is not installed. Please install it with `pip install tavily-python`." app.logger.error(err_msg)raise ImportError(err_msg) tavily_api_key = os.environ.get("TAVILY_API_KEY", "")ifnot tavily_api_key:raise MissingAPIKeyError("TAVILY_API_KEY environment variable is not set. Please set it to use Tavily." ) tavily = AsyncTavilyClient(api_key=tavily_api_key) sem = asyncio.Semaphore(16)asyncdefcall_with_retry( idx: int, q: str, retries: int = 3, delay: float = 1.0 ):asyncwith sem:for attempt inrange(retries):try: resp = await tavily.search( query=q, max_results=top_k, ) results: List[Dict[str, Any]] = resp["results"] psg_ls: List[str] = [(r["content"] or"") for r in results]return idx, psg_lsexcept UsageLimitExceededError as e: app.logger.error(f"Usage limit exceeded: {e}")raise ToolError(f"Usage limit exceeded: {e}") from eexcept InvalidAPIKeyError as e: app.logger.error(f"Invalid API key: {e}")raise ToolError(f"Invalid API key: {e}") from eexcept (BadRequestError, Exception) as e: app.logger.warning(f"[Retry {attempt+1}] Tavily failed (idx={idx}): {e}" )await asyncio.sleep(delay)return idx, [] tasks = [ asyncio.create_task(call_with_retry(i, q)) for i, q inenumerate(query_list) ] ret: List[List[str]] = [None] * len(query_list) iterator = tqdm( asyncio.as_completed(tasks), total=len(tasks), desc="Tavily Searching: " )for fut in iterator: idx, psg_ls = await fut ret[idx] = psg_lsreturn {"ret_psg": ret}if __name__ == "__main__": Retriever(app) app.run(transport="stdio")
3.2 定义parameter配置文件
说明: 配置参数设置文件
vim parameter.yaml
# servers/retriever/parameter.yamlretriever_path: openbmb/MiniCPM-Embedding-Lightcorpus_path: UltraRAG/data/Milvus_faq_corpus.jsonlembedding_path: embedding/embedding.npyindex_path: index/index.index# infinify_emb configinfinity_kwargs: bettertransformer: false pooling_method: auto device: cuda batch_size: 1024cuda_devices: "0,1"query_instruction: "Query: "faiss_use_gpu: Truetop_k: 5overwrite: falseretriever_url: http://localhost:8080index_chunk_size: 50000# OpenAI API configuration (if used)use_openai: falseopenai_model: "embedding"api_base: ""api_key: ""# Alibaba Cloud API configuration (alternative to local embedding)use_alibaba_cloud: truealibaba_api_key: "sk-xxxxxxx" # Your Alibaba Cloud API keyalibaba_model: "embedding" # Alibaba Cloud embedding modelalibaba_endpoint: "https://dashscope.aliyuncs.com/compatible-mode/v1" # Alibaba Cloud endpoint# LanceDB configuration (if used)lancedb_path: "lancedb/"table_name: "vector_index"filter_expr: null# Milvus configuration (if used)use_Milvus: trueMilvus_host: "192.168.8.130"Milvus_port: 19530collection_name: "ultrarag_collection_v3"embedding_dim: 1024
3.3 定义server配置文件
说明:集成阿里云API功能
vim rag_Milvus_faq_server.yaml
benchmark: parameter: /root/ultraRAG/UltraRAG/servers/benchmark/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/benchmark/src/benchmark.py tools: get_data: input: benchmark: $benchmark output:- q_ls- gt_lscustom: parameter: /root/ultraRAG/UltraRAG/servers/custom/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/custom/src/custom.py tools: output_extract_from_boxed: input: ans_ls: ans_ls output:- pred_lsevaluation: parameter: /root/ultraRAG/UltraRAG/servers/evaluation/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/evaluation/src/evaluation.py tools: evaluate: input: gt_ls: gt_ls metrics: $metrics pred_ls: pred_ls save_path: $save_path output:- eval_resgeneration: parameter: /root/ultraRAG/UltraRAG/servers/generation/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/generation/src/generation.py tools: generate: input: base_url: $base_url model_name: $model_name prompt_ls: prompt_ls sampling_params: $sampling_params api_key: $api_key output:- ans_lsprompt: parameter: /root/ultraRAG/UltraRAG/servers/prompt/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/prompt/src/prompt.py prompts: qa_rag_boxed: input: q_ls: q_ls ret_psg: ret_psg template: $template output:- prompt_lsretriever: parameter: /root/ultraRAG/UltraRAG/servers/retriever/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/retriever/src/retriever.py tools: retriever_init_Milvus: input: collection_name: $collection_name corpus_path: $corpus_path embedding_dim: $embedding_dimMilvus_host: $Milvus_hostMilvus_port: $Milvus_port retriever_search_Milvus: input: query_instruction: $query_instruction query_list: q_ls top_k: $top_k use_openai: $use_openai output:- ret_psg
3.4.定义索引构建(Build Index)
说明:将文档语料库转换为向量并存储到 Milvus 数据库中 需要配置的关键参数
vim Milvus_index_parameter.yaml
retriever: alibaba_api_key: sk-xxxxxxx alibaba_endpoint: https://dashscope.aliyuncs.com/compatible-mode/v1 alibaba_model: text-embedding-v3 collection_name: ultrarag_collection_v3 corpus_path: data/corpus_example.jsonl embedding_dim: 1024 embedding_path: embedding/embedding.npy Milvus_host: 192.168.8.130 Milvus_port: 19530 overwrite: false use_alibaba_cloud: true
vim mivus_index.yaml
# Milvus Index Building Configuration# Build vector index using Milvus database# Note: This configuration is now deprecated. Use setup_Milvus_collection.py instead.# MCP Serverservers: retriever: servers/retriever# Parameter Configurationparameter_config: examples/parameter/Milvus_index_parameter.yaml# MCP Client Pipeline# Updated pipeline for new architecturepipeline: - retriever.retriever_init_Milvus # Connect to existing Milvus collection - retriever.retriever_embed # Generate embeddings (if needed)# Note: Index building is now handled by setup_Milvus_collection.py# The collection ultrarag_collection_v3 should already exist with proper indexing
3.5.定义RAG 查询(Run RAG)
说明:执行完整的 RAG 流程,包括检索、生成答案、评估等 需要配置的关键参数
vim rag_Milvus_faq_server
benchmark: parameter: /root/ultraRAG/UltraRAG/servers/benchmark/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/benchmark/src/benchmark.py tools: get_data: input: benchmark: $benchmark output:- q_ls- gt_lscustom: parameter: /root/ultraRAG/UltraRAG/servers/custom/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/custom/src/custom.py tools: output_extract_from_boxed: input: ans_ls: ans_ls output:- pred_lsevaluation: parameter: /root/ultraRAG/UltraRAG/servers/evaluation/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/evaluation/src/evaluation.py tools: evaluate: input: gt_ls: gt_ls metrics: $metrics pred_ls: pred_ls save_path: $save_path output:- eval_resgeneration: parameter: /root/ultraRAG/UltraRAG/servers/generation/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/generation/src/generation.py tools: generate: input: base_url: $base_url model_name: $model_name prompt_ls: prompt_ls sampling_params: $sampling_params api_key: $api_key output:- ans_lsprompt: parameter: /root/ultraRAG/UltraRAG/servers/prompt/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/prompt/src/prompt.py prompts: qa_rag_boxed: input: q_ls: q_ls ret_psg: ret_psg template: $template output:- prompt_lsretriever: parameter: /root/ultraRAG/UltraRAG/servers/retriever/parameter.yaml path: /root/ultraRAG/UltraRAG/servers/retriever/src/retriever.py tools: retriever_init_Milvus: input: collection_name: $collection_name corpus_path: $corpus_path embedding_dim: $embedding_dimMilvus_host: $Milvus_hostMilvus_port: $Milvus_port retriever_search_Milvus: input: query_instruction: $query_instruction query_list: q_ls top_k: $top_k use_openai: $use_openai output:- ret_psg
vim rag_Milvus_faq.yaml
# Milvus RAG FAQ Demo# Complete RAG pipeline using Milvus vector database with FAQ dataset# MCP Server Configurationservers: benchmark: UltraRAG/servers/benchmark retriever: UltraRAG/servers/retriever prompt: UltraRAG/servers/prompt generation: UltraRAG/servers/generation evaluation: UltraRAG/servers/evaluation custom: UltraRAG/servers/custom# Parameter Configurationparameter_config: examples/parameter/rag_Milvus_faq_parameter.yaml# MCP Client Pipeline# Sequential execution: data -> init -> search -> prompt -> generate -> extract -> evaluatepipeline:- benchmark.get_data- retriever.retriever_init_Milvus- retriever.retriever_search_Milvus- prompt.qa_rag_boxed- generation.generate- custom.output_extract_from_boxed- evaluation.evaluate
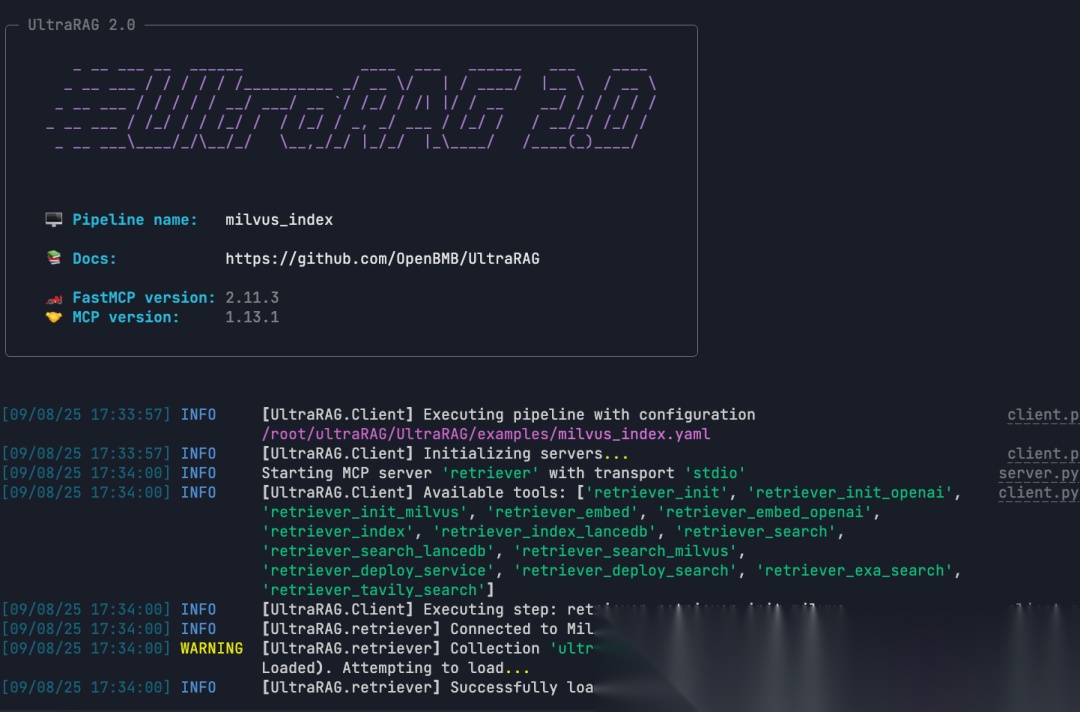
3.6 执行build索引
说明:运行成功后,就会得到对应的语料向量和索引文件,后续 RAG Pipeline 就可以直接使用它们来完成检索。
ultrarag build examples/Milvus_index.yaml
ultrarag run examples/Milvus_index.yaml
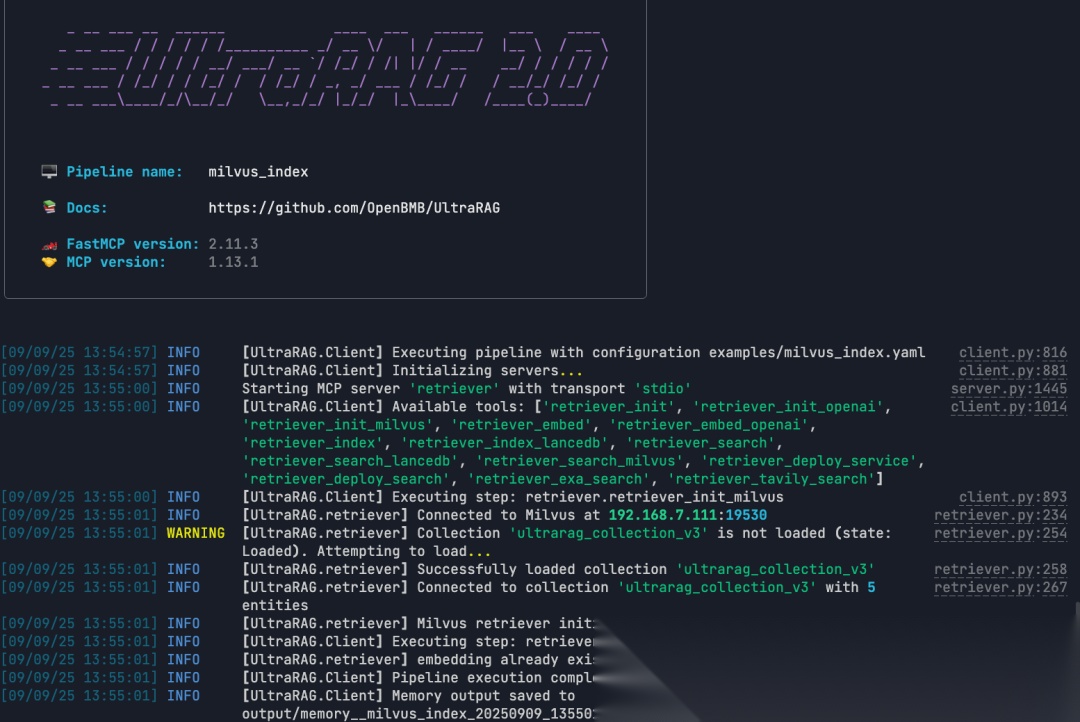
3.7 执行RAG查询
说明:搭建并运行一个完整的 RAG Pipeline
ultrarag build examples/rag_Milvus.yaml
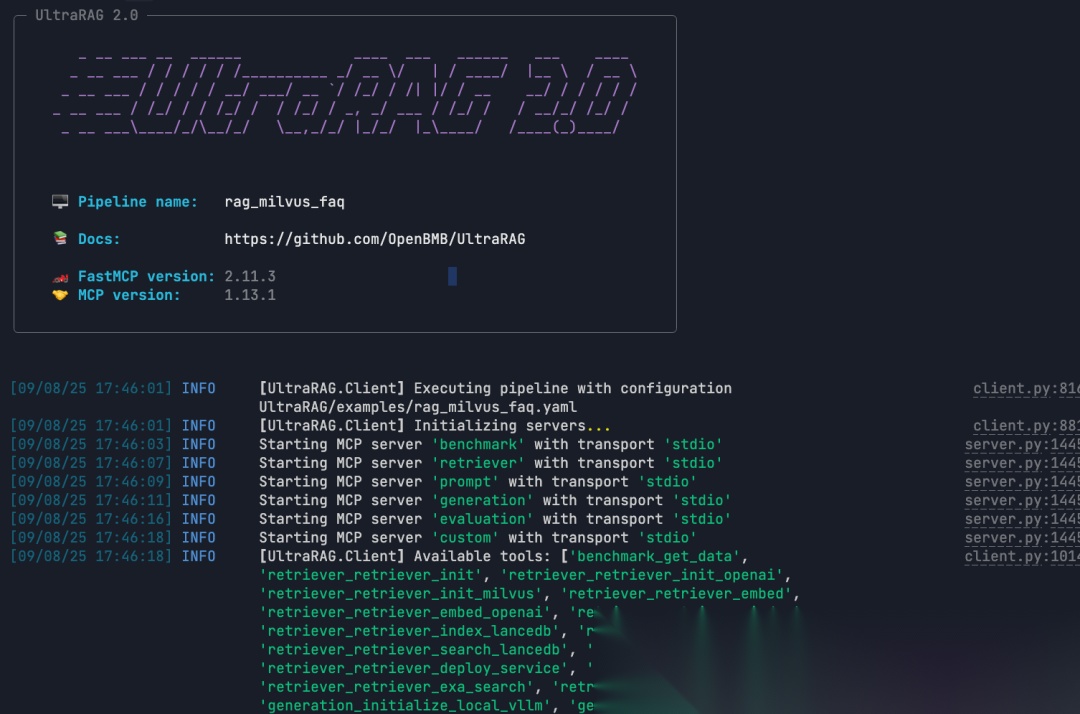
ultrarag run examples/rag_Milvus.yaml

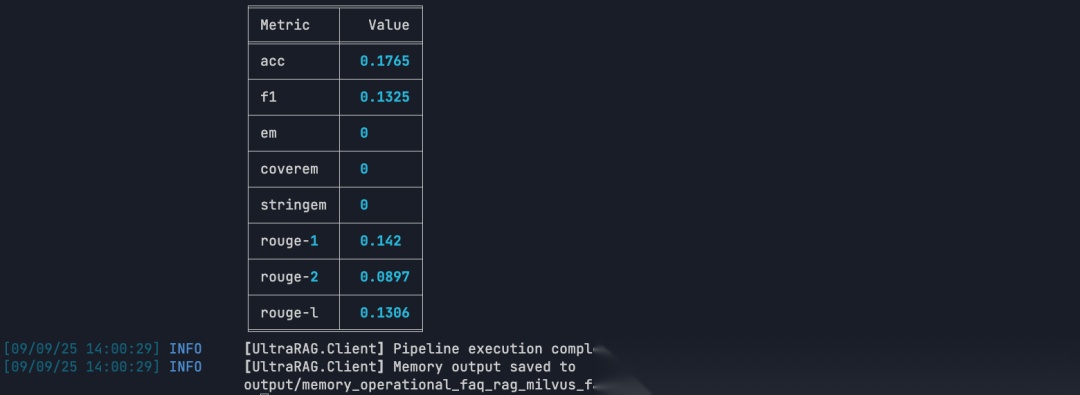
03
写在最后
传统的RAG,Pipeline需要至少几百甚至上千行代码,UltraRAG 2.0 只要几十行代码就能搞定类似的功能,甚至其中一半都是编排的 Yaml 伪代码,极大降低了很多企业级RAG落地的门槛。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)