收藏级干货!谷歌开源Embedding Gemma:3亿参数实现6亿性能,RAG实战代码+向量搜索全解析
EmbeddingGemma是Google发布的开源小规模多语言文本嵌入模型,旨在常见设备(如手机、笔记本、台式机)上高效运行,同时在 MTEB / MMTEB 等评测任务中保持与同类模型竞争的性能。其核心价值在于:支持离线运行、保护隐私、内存占用小、兼容多种推理框架,并提供灵活的输出维度。
1. 简介
EmbeddingGemma是Google发布的开源小规模多语言文本嵌入模型,旨在常见设备(如手机、笔记本、台式机)上高效运行,同时在 MTEB / MMTEB 等评测任务中保持与同类模型竞争的性能。其核心价值在于:支持离线运行、保护隐私、内存占用小、兼容多种推理框架,并提供灵活的输出维度。
2. 关键特性
模型规模与上下文长度:参数量约为 308M,支持最长 2K tokens 的上下文窗口,默认输出向量维度为 768。
多语言支持:训练语料涵盖 100 多种语言。
MRL(嵌套表示学习):支持将 768 维的嵌入向量截断为 512/256/128 等更短维度,兼顾效率与效果。
工程优化:支持量化感知训练(QAT)与设备端优化,量化后模型大小可控制在 200MB 以内。
3. 架构与训练要点
基于 Gemma 3 的编码器风格骨干网络:EmbeddingGemma 使用 Gemma 3 作为主干网络,并将注意力机制改为双向,相比传统的解码器结构在大规模检索/嵌入任务中表现更优。
池化与映射结构:模型先输出 token 级别的向量,再通过均值池化聚合成文本向量,最后经由两层全连接层映射到 768 维的嵌入空间。
训练数据与清洗:模型基于大规模多语言语料训练,训练过程中实施了严格的质量过滤与安全过滤。
4. MRL与Prompt 模板
MRL原理和效果
EmbeddingGemma 在训练阶段引入了 MRL机制,使得推理时可选择不同的嵌入维度(768/512/256/128),而性能下降控制在可接受范围内。其原理类似“套娃”结构,高维嵌入向量的前一部分包含“核心信息”,后一部分为“补充信息”。因此既可使用完整 768 维向量,也可仅使用前 512/256/128 维,而不导致效果显著下降。
在资源受限环境中,可通过牺牲少量精度换取更低的存储与计算开销。而在分层检索系统中,可先用低维嵌入进行粗筛,再使用高维嵌入对候选结果进行精排。
支持针对特定任务的Prompt
EmbeddingGemma 在训练时使用了一系列 prompt_name(例如 query、document、STS 等)。在实际推理或测试中,建议沿用这些prompt以获得最佳效果。
若使用sentence-transformers库,其内置的 encode_query/encode_document方法会自动添加相应 prompt。若直接使用 Transformers 或其他底层框架,需在输入文本前手动拼接对应的prompt。
支持的 Prompt 模板(根据不同任务使用可提升效果):
query:"task: search result | query: "
document:"title: none | text: "
BitextMining:"task: search result | query: "
Clustering:"task: clustering | query: "
Classification:"task: classification | query: "
InstructionRetrieval:"task: code retrieval | query: "
MultilabelClassification:"task: classification | query: "
PairClassification:"task: sentence similarity | query: "
Reranking:"task: search result | query: "
Retrieval-query:"task: search result | query: "
Retrieval-document:"title: none | text: "
STS:"task: sentence similarity | query: "
Summarization:"task: summarization | query: "
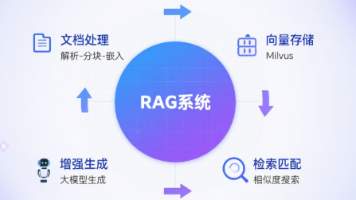
5. 实战:一个简单的RAG系统示例
1 环境依赖
pip install sentence-transformers==2.2.2 transformers huggingface-hub
pip install faiss-cpu # 若使用 GPU 可安装 faiss-gpu
2加载生成语言模型
#加载Gemma3生成模型
from transformers import pipeline
pipeline =pipeline(
task="text-generation",
model="google/gemma-3-4b-it",
device_map="auto",
dtype="auto"
)
3 加载嵌入模型
import torch
from sentence_transformers importSentenceTransformer
#设置设备
device ="cuda"if torch.cuda.is_available()else"cpu"
model_id ="google/embeddinggemma-300M"
model =SentenceTransformer(model_id).to(device=device)
print(f"运行设备: {model.device}")
print(model)
print("模型总参数量:",sum([p.numel()for _, p in model.named_parameters()]))
4 使用 Prompt 模板
在 RAG 系统中,为查询和文档使用不同的 prompt 模板可提升效果:
- • 查询编码:使用
prompt_name="Retrieval-query"
query_embedding = model.encode(
"How do I use prompts with this model?",
prompt_name="Retrieval-query"
)
- • 文档编码:使用
prompt_name="Retrieval-document"。
为进一步优化,可加入标题信息:
- • 带标题:
doc_embedding = model.encode(
"文档正文内容...",
prompt_name="Retrieval-document",
prompt="title: 在 RAG 中使用 Prompt | text: "
)
- • 无标题:
doc_embedding = model.encode(
"文档正文内容...",
prompt_name="Retrieval-document",
prompt="title: none | text: "
)
5 构建示例知识库
#公司知识库示例
corp_knowledge_base =[
{
"category":"人力资源与请假政策",
"documents":[
{
"title":"非计划缺勤流程",
"content":"如因生病或紧急情况无法工作,请于东京时间上午9:30前通过邮件通知直接上级和人力资源部门,邮件主题请注明“病假 - [你的姓名]”。若连续缺勤超过两天,返岗时需提供医生证明(診断書)。"
},
{
"title":"年假政策",
"content":"全职员工首年可享受10天带薪年假。年假自入职满六个月后生效,并随服务年限增加。例如,服务满三年的员工每年可享受14天年假。详细 accrual 表请参阅附件《年假累积表》。"
},
]
},
{
"category":"IT 与安全",
"documents":[
{
"title":"账户密码管理",
"content":"如忘记密码或账户被锁定,请使用自助重置门户:https://reset.ourcompany。系统将提示您回答预设的安全问题。出于安全考虑,IT帮助台无法通过电话或邮件重置密码。若未设置安全问题,请携带员工ID卡至涩谷办公室12楼IT支持台处理。"
},
{
"title":"软件采购流程",
"content":"所有新软件申请须通过‘IT服务台’门户中的‘软件申请’类别提交,需包含业务理由。所有软件许可须经部门负责人批准后方可采购。请注意,标准办公软件已预批准,无需走此流程。"
},
]
},
{
"category":"财务与报销",
"documents":[
{
"title":"费用报销政策",
"content":"为确保及时处理,当月所有费用报销须在次月第5个工作日前提交审批。例如,7月产生的所有费用须在8月第5个工作日前提交。逾期提交的费用可能延至下一付款周期处理。"
},
{
"title":"差旅费用指南",
"content":"差旅费用原则上按最合理、最经济路线的实际成本报销。使用新干线或飞机前请提前提交差旅费用申请。仅当公共交通不可用或运输重型设备时允许乘坐出租车。必须保留收据。"
},
]
},
{
"category":"办公与设施",
"documents":[
{
"title":"会议室预订指南",
"content":"涩谷办公室所有会议室可通过日历应用预订。创建新会议邀请,添加参会人后,使用‘会议室查找’功能选择可用房间。请确保选择正确的楼层。10人以上会议请预订14楼的‘樱’或‘富士’房间。"
},
{
"title":"邮件与快递政策",
"content":"公司邮件服务仅用于业务相关信函。出于安全与责任考虑,请员工避免将私人包裹或邮件寄至涩谷办公室地址。前台无法代收或保管私人快递。"
},
]
},
]
6 设置辅助函数并检索
question ="如何重置密码?"#可替换为其他问题
similarity_threshold =0.4#相似度阈值,低于此值认为不匹配语义搜索核心逻辑:
#---语义搜索相关辅助函数---
def _calculate_best_match(similarities):
print("相似度分数:", similarities)
if similarities is None or similarities.nelement()==0:
returnNone,0.0
#找出最高分及其索引
best_index = similarities.argmax().item()
best_score = similarities[0, best_index].item()
return best_index, best_score
def find_best_category(model, query, candidates):
"""
从候选类别中找出与查询最相关的类别。
参数:
model:SentenceTransformer模型
query:用户查询字符串
candidates:类别名称列表
返回:
最佳类别索引和相似度分数
"""
if not candidates:
return None,0.0
#对查询和候选类别进行编码(使用分类任务prompt)
query_embedding = model.encode(query, prompt_name="Classification")
candidate_embeddings = model.encode(candidates, prompt_name="Classification")
print("候选类别:", candidates)
return _calculate_best_match(model.similarity(query_embedding, candidate_embeddings))
def find_best_doc(model, query, candidates):
"""
从候选文档中找出与查询最相关的文档。
参数:
model:SentenceTransformer模型
query:用户查询字符串
candidates:文档列表,每个文档应包含'title'和'content'
返回:
最佳文档索引和相似度分数
"""
if not candidates:
return None,0.0
#对查询进行编码(使用检索任务prompt)
query_embedding = model.encode(query, prompt_name="Retrieval-query")
#构建文档文本并编码
doc_texts =[
f"title: {doc.get('title', 'none')} | text: {doc.get('content', '')}"
for doc in candidates
]
candidate_embeddings = model.encode(doc_texts)
print("候选文档:",[doc['title']for doc in candidates])
#计算余弦相似度
return _calculate_best_match(model.similarity(query_embedding, candidate_embeddings))
#---主搜索逻辑---
best_document =None#初始化最佳文档
#1.寻找最相关类别
print("步骤1: 寻找最相关类别...")
categories =[item["category"]for item in corp_knowledge_base]
best_category_index, category_score =find_best_category(model, question, categories)
#检查类别匹配分数是否超过阈值
if category_score < similarity_threshold:
print(f" `-> 🤷 未找到相关类别。最高分仅为 {category_score:.2f}。")
else:
best_category = corp_knowledge_base[best_category_index]
print(f" `-> ✅ 找到类别: '{best_category['category']}' (分数: {category_score:.2f})")
#2.仅当找到合适类别后,在该类别中寻找最相关文档
print("\n步骤2: 在该类别中寻找最相关文档...")
best_document_index, document_score =find_best_doc(
model, question, best_category["documents"]
)
#检查文档匹配分数是否超过阈值
if document_score < similarity_threshold:
print(f" `-> 🤷 未找到相关文档。最高分仅为 {document_score:.2f}。")
else:
best_document = best_category["documents"][best_document_index]
print(f" `-> ✅ 找到文档: '{best_document['title']}' (分数: {document_score:.2f})")
7 基于检索结果生成答案
qa_prompt_template ="""请仅根据以下CONTEXT回答问题。如果CONTEXT中未包含答案,请回答“我不知道”。
---
CONTEXT:
{context}
---
QUESTION:
{question}
"""
if best_document and "content" in best_document:
# 如果找到有效文档,生成答案
context = best_document["content"]
prompt = qa_prompt_template.format(context=context, question=question)
messages =[
{
"role":"user",
"content":[{"type":"text","text": prompt}],
},
]
print ("问题🙋♂️: "+ question)
# 调用生成模型获取答案
answer = pipeline(messages, max_new_tokens=256, disable_compile=True)[0]["generated_text"][1]["content"]
print("使用文档: "+ best_document["title"])
print("回答🤖: "+ answer)
else:
# 未找到相关文档时的回复
print("问题🙋♂️: "+ question)
print("回答🤖: 抱歉,未找到相关文档来回答该问题。")
6. 一些工程经验
统一使用 Prompt:模型训练时使用了特定 prompt 名称和内容,因此生产环境中应保持使用这些prompt以保证效果一致性。
维度选择权衡:MRL 支持降维,在对吞吐量或存储敏感的场景中,可优先尝试512或256维,而非直接降至 128 维。
量化与精度平衡:该模型主打轻量级使用,量化可显著减少内存占用,但应根据精度需求和应用场景谨慎选择量化策略(如QAT 或 PTQ)。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)