零基础入门:MCP架构实现Agentic RAG系统【代码完整可收藏】
同时课程详细介绍了。
本文详细介绍了基于MCP架构的Agentic RAG系统实现,采用Client/Server模式,服务端用LlamaIndex提供RAG管道工具,客户端用LangGraph构建智能Agent。系统实现了文档索引创建、多文档查询、总结性问题等功能,并通过缓存机制优化性能。MCP架构带来了模块化设计、技术灵活性和互操作性等优势,为大模型应用开发提供了新思路。
五一期间,小编尝试用MCP架构从零实现一个完整的Agentic RAG系统,以演示MCP与RAG、Agent的一些有趣融合,在此与大家一起分享。内容涵盖:
- 思考:MCP与Agentic RAG的融合
- MCP标准下的Agentic RAG架构
- MCP服务端:实现RAG-Server(LLamaIndex)
- MCP客户端:实现Agent(LangGraph)
- 端到端效果演示
01
思考:MCP与Agentic RAG的融合
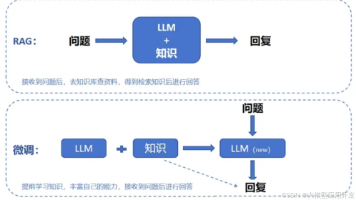
RAG是一种借助外部知识来给LLM提供上下文的AI应用范式。从这个角度来说,RAG与MCP有着相似的意义:给大模型补充上下文,以增强其能力。只是MCP以提供外部工具为主,而RAG则是以注入参考知识为主。这就像一个考试的学生,MCP给你提供计算器,而RAG则是给你一本书。
当然,两者的重点并不一样,MCP强调的是提供工具的方式(集成标准);而RAG则是需要你实现的完整应用。所以两者并不冲突,完全可以用MCP的方法来集成一个RAG应用。
特别是在Agentic RAG系统(如下图)中,由于通常涉及到多个RAG查询管道与Agent的融合,这就与MCP的思想非常契合:
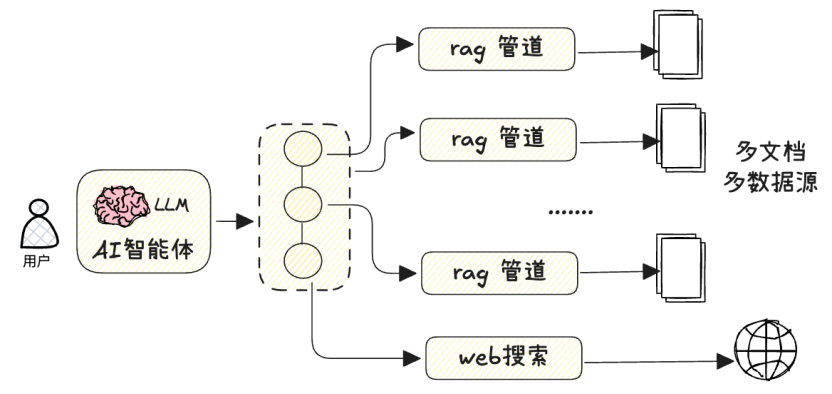
假设一个典型的Agentic RAG应用:

一个针对大量不同文档的问答Agent,这些问答有事实性问题也有摘要性问题,更有跨越多个文档的融合问题,甚至需要搜索引擎来补充信息。
现在我们来用MCP的标准设计并完整的实现这个场景。
02
MCP标准下的Agentic RAG架构
在MCP架构下,无论是SSE还是stdio模式,都是Client/Server模式。你必须在开始之前清晰的设计好MCP Server与Client应用的分工及交互。比如:
- 服务端提供的工具,包括功能边界、输入输出
- 服务功能粒度不能太大(丧失模块化)也不能太小(复杂化)
- 缓存与持久化设计:毕竟RAG是数据密集型应用
- 客户端Agent设计:模型、工作流、与服务端的交互等
- 如果是多用户环境:要考虑只是文档与索引的隔离
【总体思想】
我们基于如下的总体架构来实现:
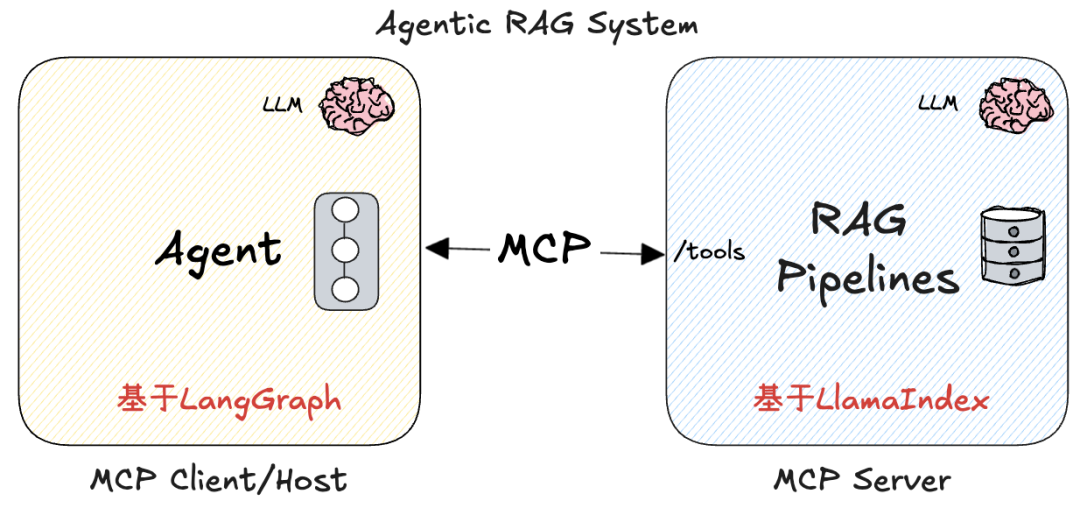
- 在MCP Server上提供RAG管道构建与查询的工具;在客户端创建使用这些工具的AI Agent,提供查询任务规划与执行能力
- MCP Server借助LlamaIndex实现RAG管道;在客户端借助LangGraph实现Agent:让每个‘人’干更擅长的事。
03
MCP Server:RAG管道的核心
MCP Server是RAG功能实现的位置。我们对MCP Server拆解设计如下:
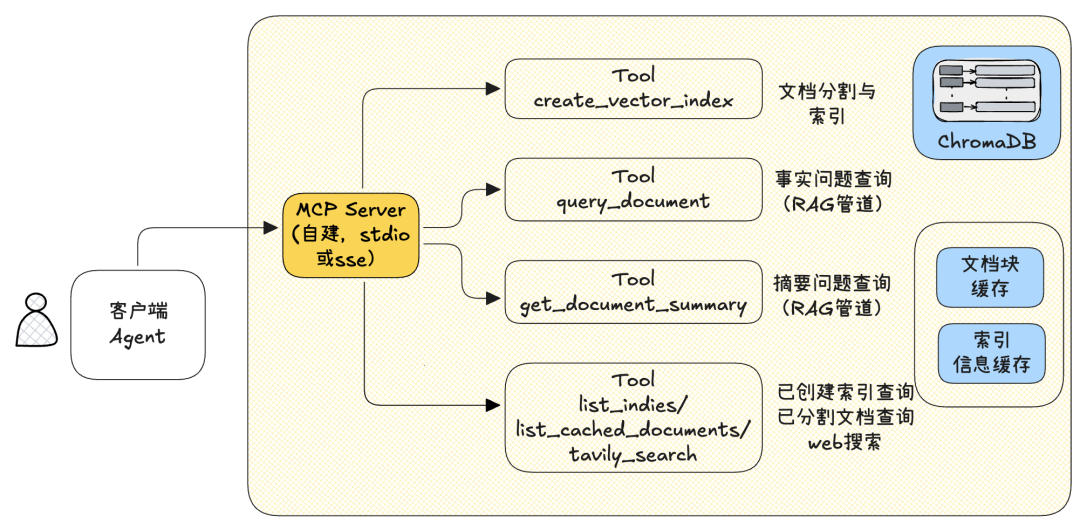
【工具(Tools)】
- create_vector_index:输入文档、索引名与参数,完成解析与索引创建。
- query_document:查询事实问题的RAG管道,输入索引名与查询问题。
- get_document_summary:查询总结性问题的RAG管道,输入文件和查询问题。
- list_indies等:辅助工具,包括一个自己实现的Web搜索工具。
需要说明,在这里的设计中,不同的RAG管道查询的工具是一样的,但参数(索引名,依赖于Agent推理)不同。一个是推理工具,一个推理参数,效果一致。
【缓存机制】
服务端要对文档解析(含分割)与索引创建的信息进行缓存(持久化存储),以防止可能的重复解析与索引创建,提高性能。
-
文档节点缓存:缓存文档解析分拆后的结果,确保文档解析过一次后,只要内容与参数(如chunk_size)不变,就不会被重新解析。
文档缓存的唯一名称是文档内容hash值+解析参数的联合。比如:
“questions.csv_f4056ac836fc06bb5f96ed233d9e2b63_500_50”
-
索引信息缓存:缓存已经创建过的索引信息,防止重复嵌入及向量库访问,避免不必要的模型调用成本。
索引缓存的唯一名称是每个文档关联的唯一索引名称。比如:
“questions_for_customerservice”
以下情况下会导致索引被重建:
- 客户端强制要求重建
- 索引信息缓存不存在
- 文档节点缓存不存在
这样的缓存管理方式,可以增加处理的灵活性与健壮性。如:
- 更改文档内容或解析参数,即时文档名与索引名不变:仍然会触发索引重建。
- 文档内容与参数不变,但修改索引名:会创建新索引,但不会重新解析文档。
【工具实现:create_vector_index】
这是服务端两个重要工具之一,核心代码如下,请参考注释理解:
.....
@app.tool()
asyncdefcreate_vector_index(
ctx: Context,
file_path: str,
index_name: str,
chunk_size: int = 500,
chunk_overlap: int = 50,
force_recreate: bool = False
) -> str:
"""创建或加载文档向量索引(使用缓存的节点)
Args:
ctx: 上下文对象
file_path: 文档文件路径
index_name: 索引名称
chunk_size: 文本块大小
chunk_overlap: 文本块重叠大小
force_recreate: 是否强制重新创建索引
Returns:
操作结果描述
"""
#用来判断索引是否存在
storage_path = f"{storage_dir}/{index_name}"
try:
# 获取Chroma客户端
chroma = ctx.request_context.lifespan_context.chroma
# 获取节点缓存路径(文档内容hash_chunksize_chunovlerlap)
cache_path = get_cache_path(file_path, chunk_size, chunk_overlap)
# 确定是否需要重建索引:强制 or 索引不存在 or 文档有变
need_recreate = (
force_recreate or
not os.path.exists(storage_path) or
not os.path.exists(cache_path)
)
if os.path.exists(storage_path) andnot need_recreate:
returnf"索引 {index_name} 已存在且参数未变化,无需创建"
# 如果需要重新创建,首先尝试删除现有的索引向量库
try:
chroma.delete_collection(name=index_name)
except Exception as e:
logger.warning(f"删除集合时出错 (可能是首次创建): {e}")
# 创建新的向量库
collection = chroma.get_or_create_collection(name=index_name)
vector_store = ChromaVectorStore(chroma_collection=collection)
# 加载与拆分文档
nodes = await load_and_split_document(ctx, file_path, chunk_size, chunk_overlap)
logger.info(f"加载了 {len(nodes)} 个节点")
# 创建向量索引
storage_context = StorageContext.from_defaults(vector_store=vector_store)
vector_index = VectorStoreIndex(nodes, storage_context=storage_context, embed_model=embedded_model)
# 缓存索引信息,这样下次不会重建
vector_index.storage_context.persist(persist_dir=storage_path)
returnf"成功创建索引: {index_name}, 包含 {len(nodes)} 个节点"
except Exception as e:
......
【工具实现:query_document】
这是客户端调用的主要工具。其输入是索引名与查询问题。借助索引缓存,可以快速加载并执行RAG查询。这里不再展示完整处理过程:
@app.tool()
async def query_document(
ctx: Context,
index_name: str,
query: str,
similarity_top_k: int = 5
) -> str:
"""从文档中查询事实性信息,用于回答具体的细节问题
Args:
ctx: 上下文对象
index_name: 索引名称
query: 查询文本
similarity_top_k: 返回的相似节点数量
Returns:
查询结果
"""
......
按类似方法,再创建一个用于回答总结性问题的工具(利用LlamaIndex的SummaryIndex类型索引),此处不在赘述。
04
MCP客户端:实现Agent(基于LangGraph)
客户端的工作流程如下:
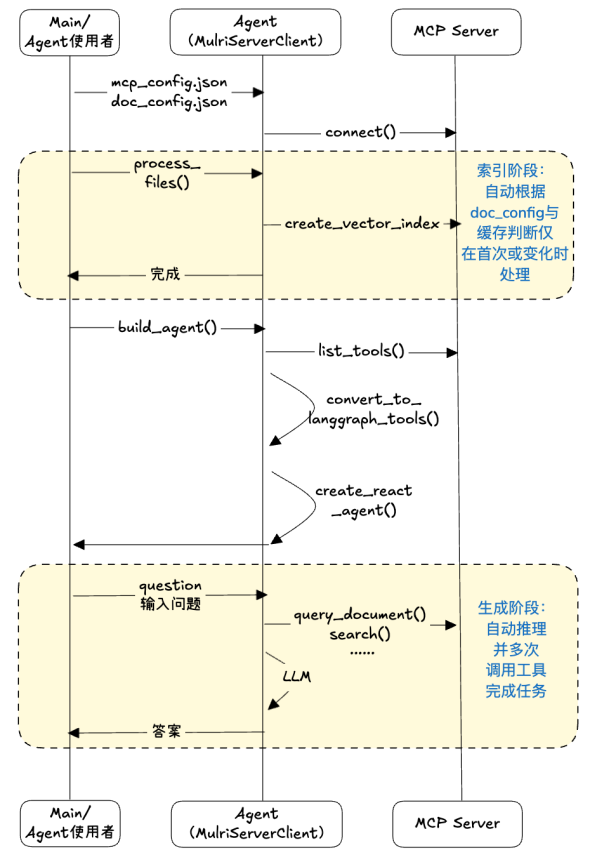
客户端的几个设计重点简单说明如下:
【配置文件】
客户端有两个重要的配置信息,分别用于MCP Server与知识文档的配置。
mcp_config.json:
配置MCP Servers的信息,支持多Server连接、工具加载与过滤(这是一个在langgraph-mcp-adapers基础上扩展的版本)。比如:
{
"servers": {
"rag_server": {
"transport": "sse",
"url": "http://localhost:5050/sse",
"allowed_tools": ["load_and_split_document", "create_vector_index", "get_document_summary", "query_document"]
},
...其他server...
}
doc_config.json:
配置需要索引和查询的全部文档信息。这些信息还会在查询时被注入Agent提示词,用来推理工具的使用参数:
{
"data/c-rag.pdf": {
"description": "c-rag技术论文,可以回答c-rag有关问题",
"index_name": "c-rag",
"chunk_size": 500,
"chunk_overlap": 50
},
"data/questions.csv": {
"description": "税务问题数据集,包含常见税务咨询问题和答案",
"index_name": "tax-questions",
"chunk_size": 500,
"chunk_overlap": 50
},
....其他需要索引和查询的文档.....
}
【主程序】
客户端主程序流程非常简单,基于一个封装的MCP客户端与AgenticRAG类型:
......
client = MultiServerMCPClient.from_config('mcp_config.json')
asyncwith client as mcp_client:
logger.info(f"已连接到MCP服务器: {', '.join(mcp_client.get_connected_servers())}")
# 创建智能体
rag = AgenticRAGLangGraph(client=mcp_client, doc_config=doc_config)
# 创建向量索引,自动排重
await rag.process_files()
# 构建智能体
await rag.build_agent()
# 交互式对话
await rag.chat_repl()
【创建智能体(build_agent)】
注意到这里的关键步骤是build_agent,会借助LangGraph预置的create_react_agent快速创建Agent。如果你需要精细化的控制,也可以自定义Graph:
......
async def build_agent(self) -> None:
# 获取服务端提供的工具列表
mcp_tools = await self.client.get_tools_for_langgraph()
...略:配置文件生成doc_info....
# 使用LangGraph创建ReAct智能体
self.agent = create_react_agent(
model=llm,
tools=mcp_tools,
prompt=SYSTEM_PROMPT.format(
doc_info_str=doc_info_str,
current_time=datetime.now().strftime('%Y-%m-%d %H:%M:%S')),
)
logger.info("===== 智能体构建完成 =====")
篇幅原因,一些细节部分不在这做详细展示。如果有疑问,欢迎后台交流。
05
端到端效果演示
现在让我们来测试下这个的“MCP化”的Agentic RAG应用的运行效果。按照如下步骤来进行:
- 启动MCP RAG-Server。这里用更复杂的SSE模式(暂时未支持文档上传,所以只能本机启动):
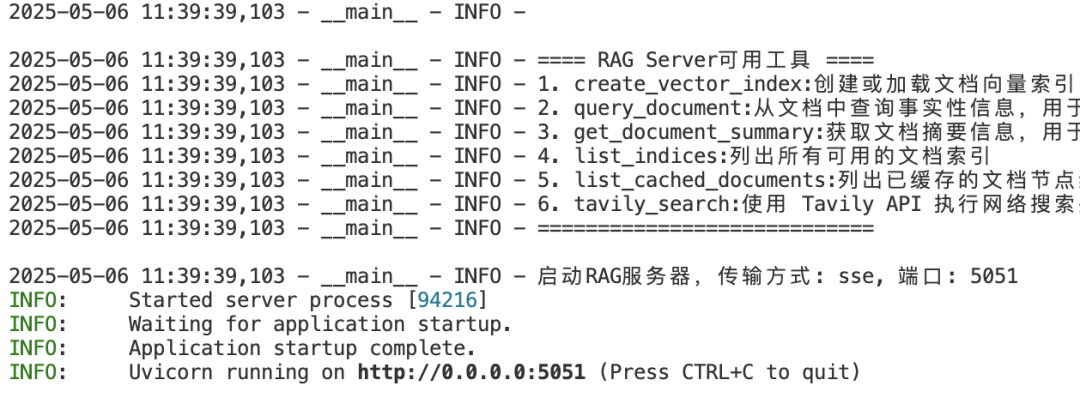
启动时会自动提取并展示服务端的工具清单。
- 准备客户端知识文档与配置文件。将需要索引和查询的文档放在应用的data/目录,配置好mcp_config与doc_config。不做任何其他处理。直接启动客户端应用:
python rag_agent_langgraph.py
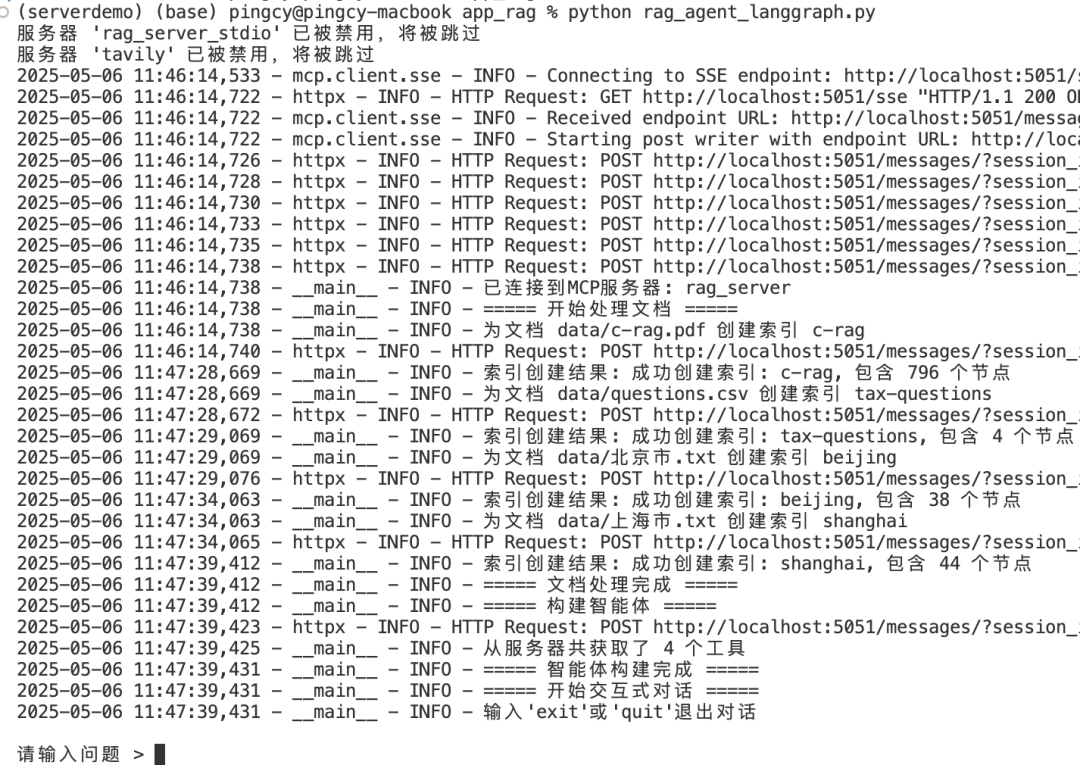
* 观察首次运行的跟踪信息(如下图),这里的过程是:
- 连接RAG-Server与初始化
- 调用服务端工具创建向量索引。由于是首次访问,服务端没有索引缓存,所以会逐个对文件解析与创建向量索引
- 最后会加载Server端工具,创建LangGraph的Agent
* 现在退出程序,再次启动客户端,观察输出(如下图),可以看到由于索引已经创建,所以会显示“无需创建”。

- 交互式测试
进入交互式测试环节(图中的服务端信息是通过MCP接口推送到客户端的远程日志,方便观察服务端的工作状态):
- 关联两个文档信息的查询
由于提供的文档有北京和上海的城市信息介绍,所以看到这个问题调用了北京和上海的RAG管道查询,还自作主张的调用了搜索引擎做补充,然后输出答案:
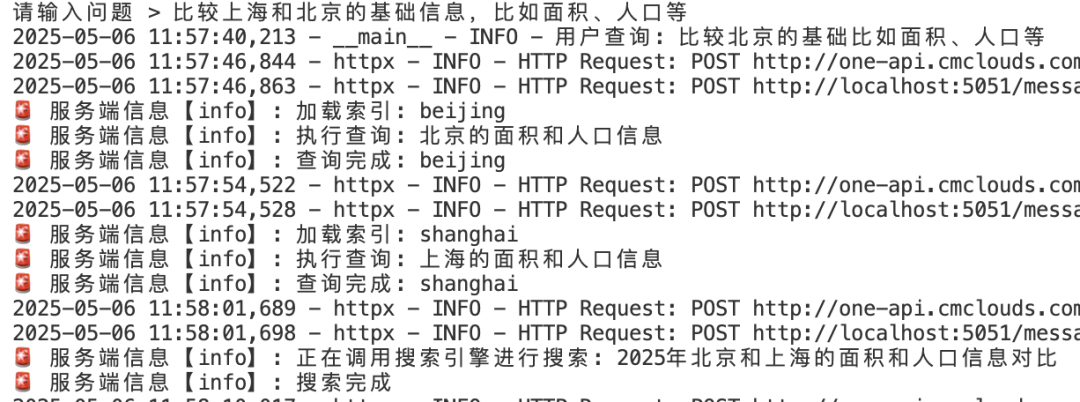

- 查询知识库答案,并要求和网络搜索结果核对。
日志显示,Agent先用本地向量索引查询,然后通过搜索引擎对比,非常准确。


- 总结性问题测试。
日志显示,这里未加载向量索引,而是由工具加载这个文档的节点,并生成文档摘要后返回(SummaryIndex的效率不太高,有待优化)

- 最后一个很有意思的测试。
由于我们把创建索引的过程“工具”化了,所以甚至可以用自然语言来管理索引。比如这里我要求把csv文档的索引重建,智能体准确的推理出工具及参数,并重建了csv文档索引(实际应用要考虑安全性):


以上展示了一个基于MCP架构的Agentic RAG系统的实现。总结这种架构下的一些明显的变化:
-
MCP要求对整个系统做模块化与松耦合的重新设计,这会带来一系列工程上的好处。比如分工与效率提升、可维护性、独立扩展、部署更灵活等。
-
MCP不依赖于某个技术堆栈。因此技术选择上更灵活,比如服务端用LlamaIndex框架,而客户端则用LangGraph;甚至可以用不同的语言。
-
MCP实现了基于标准的模块间互操作。这有助于资源共享,减少重复开发,比如其他人可以基于你的RAG Server构建Agent,而无需了解RAG的具体实现。
当然,本文应用还只是基本能力的演示,实际还有大量优化空间。比如服务端的并行处理(大规模文档)、索引进度报告、多模态解析等,后续我们将不断完善并分享。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)