
Hermes 知识库选型深度指南:从 qmd 到 bge-m3,本地 RAG 全栈性能拆解
在多智能体系统的知识库建设中,每一个技术选型都直接影响着系统的响应延迟、运行成本与数据隐私边界。本文围绕 Hermes-Agent 智能体框架的知识库架构,深度拆解 qmd、GGUF、Ollama、bge-m3 四大核心技术组件的协作机制与性能损耗,并给出可落地的最终选型方案。
在多智能体系统的知识库建设中,每一个技术选型都直接影响着系统的响应延迟、运行成本与数据隐私边界。本文围绕 Hermes-Agent 智能体框架的知识库架构,深度拆解 qmd、GGUF、Ollama、bge-m3 四大核心技术组件的协作机制与性能损耗,并给出可落地的最终选型方案。
回顾:关注我的读者应该知道,我此前在Hermes的知识库上折腾了ollama+bge-m3、karpathy的llm wiki、知识图谱等等内容,最后因为各种不满意,还是回滚到了官方最初的状态。接下来怎么办?凉拌是不可能的,今天这篇文章,不但是我自己进行知识库选型,也给各位重度使用智能体框架的读者一个参考。
忘了个很重要的点,就在这里补充吧。你要先在Hermes-Agent里创建一个qmd skill,然后再进行下面的搭建,并且这个skill(skill内置调用mcp)就是调用你即将要搭建的内容。
一、四个核心概念:它们到底是什么,为什么缺一不可
在讨论选型之前,必须先厘清四个技术概念的本质。它们分别位于知识库架构的不同层级:Markdown 知识文档是知识源载体,GGUF 是模型存储格式,Ollama 是模型服务框架,bge-m3 是语义检索引擎。四者是本地 RAG 体系中的关键技术组件。
1.1 qmd:Query Markup Documents,本地混合搜索引擎
qmd 的全称是 Query Markup Documents,不是一个文件格式,而是一个运行在本地的完整知识库系统。它通过 MCP 协议与 Hermes Agent 集成,内部集成了三层搜索能力,把传统 RAG 链路中需要外部拼接的多个组件(全文检索、向量语义检索、查询扩展、结果重排)全部打包进了一个服务。
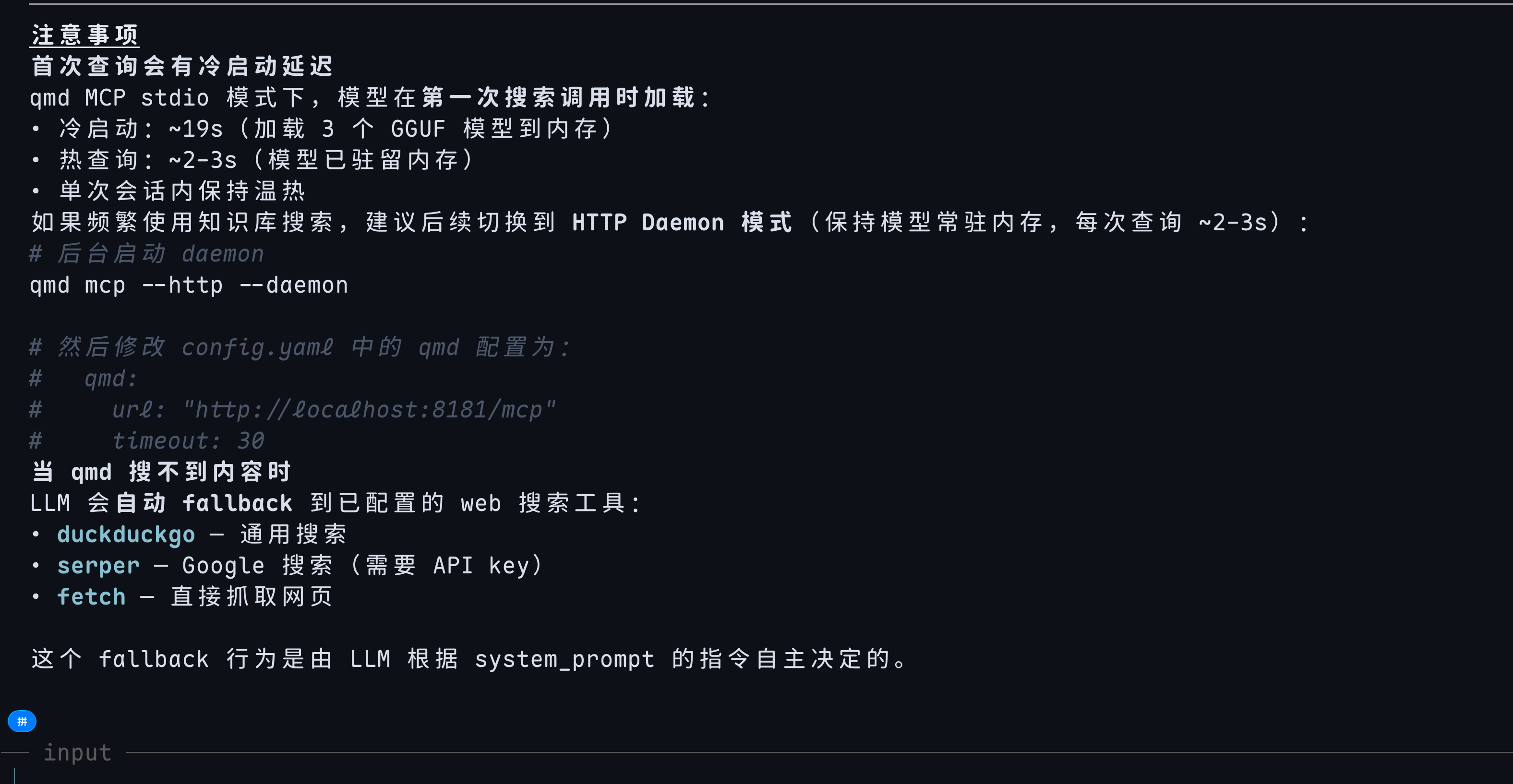
qmd 在
~/.hermes/config.yaml中注册为一个 MCP server:mcp_servers: qmd: command: /home/**/.nvm/versions/node/v22.22.2/bin/node args: - /home/**/.nvm/versions/node/v22.22.2/lib/node_modules/@tobilu/qmd/dist/cli/qmd.js - mcp timeout: 300qmd 的核心竞争力在于三层混合搜索架构,这三层全部本地运行,不依赖任何远程 API:
层级 技术 作用 BM25 全文搜索 SQLite FTS5 关键词精确匹配,召回包含精确术语的文档 向量语义搜索 sqlite-vec + Gemma 300M GGUF 语义理解,捕捉同义词和概念关联 LLM 重排/扩展 node-llama-cpp + 1.7B Q4_K_M GGUF 查询扩展(生成同义/相关查询)+ 结果重排 这三层不是可选插件,而是默认同时启用的固定流水线。当 Agent 调用
mcp_qmd_query时,qmd 内部自动完成:查询扩展 → BM25 检索 → 向量检索 → 结果融合 → LLM 重排 → 返回 Top-K 文档。Agent 不需要关心底层用了几个模型、几次数据库查询,只需要拿到结果即可。qmd 加载的三个本地 GGUF 模型位于
~/.cache/qmd/models/,全部通过node-llama-cpp在本地推理,无需 Ollama:embeddinggemma-300M-Q8_0.gguf (~319MB) — 向量嵌入模型 qmd-query-expansion-1.7B-q4_k_m.gguf (~1.2GB) — 查询扩展模型 qwen3-reranker-0.6b-q8_0.gguf (~609MB) — 结果重排模型三个模型各司其职:
- Gemma 300M:将文档和查询编码为向量,供 sqlite-vec 做语义检索
- 1.7B 查询扩展模型:接收用户原始查询,生成语义等价的扩展查询,解决"用户说的词和文档里的词不一样"的问题
- qwen3-reranker-0.6b:对 BM25 + 向量检索融合后的候选结果进行精排,解决"召回了很多,但哪个最相关"的问题
Hermes Agent 通过 MCP 协议调用 qmd 时,可用的工具包括:
mcp_qmd_query— 混合搜索(lexical + vector + rerank),一次调用完成完整检索链路mcp_qmd_get— 按路径或 docid 获取单篇文档mcp_qmd_multi_get— 批量获取多篇文档mcp_qmd_status— 查看索引状态(文档数、向量索引是否启用、待嵌入数量)mcp_qmd_list_resources— 列出所有已索引的资源在 Hermes 的架构中,qmd 与 skill 文件、MCP 工具 server 形成三层分离:Markdown 文档承载知识内容,qmd 提供检索能力,工具 MCP server(如 filesystem、git)提供执行能力。Agent 的工作流程是:通过
mcp_qmd_query检索找到相关知识 → 阅读 skill 文档理解操作步骤 → 通过 MCP 工具执行具体操作。1.2 GGUF:让大模型从云端"瘦身"到本地的关键格式
GGUF(GPT-Generated Unified Format)是 llama.cpp 项目推出的模型文件格式,用于替代早期的 GGML。它的核心使命是将动辄几十 GB 的原始 PyTorch 模型压缩到单文件、自包含、可直接在消费级硬件上推理的形式。
GGUF 的关键技术特性包括:
单文件自包含。 传统的 PyTorch 模型需要
model.safetensors+tokenizer.json+config.json等多个文件配合,而 GGUF 把词汇表、权重张量、超参数、分词器配置全部打包进一个.gguf文件。这意味着 Ollama 只需要一个 URL 或文件路径就能完成模型加载。多级量化体系。 GGUF 支持从 Q2_K 到 Q8_0 的多种量化级别,量化策略不是简单的"全部压缩到 N bit",而是对模型中不同类型的层采用差异化精度:
- Q4_K_M:4-bit 量化,注意力层的 K、V 矩阵使用更高的 6-bit 精度,中间 FFN 层使用 4-bit。这是性价比最高的选项,模型体积压缩到原始的 30-40%,质量损失在大多数问答场景下几乎不可感知。
- Q5_K_M:5-bit 量化,进一步提升了中间层的数值精度,体积约为原始的 45-50%,适合对生成质量要求更高的场景。
- Q8_0:8-bit 量化,基本接近 FP16 的精度,体积约为原始的 80-90%,但推理速度明显慢于 4-bit/5-bit。
量化级别直接决定了三个核心指标:内存占用、推理速度、生成质量。后文会给出具体的量化对比数据。
CPU/GPU 混合推理。 GGUF 格式原生支持 llama.cpp 的 CPU/GPU 混合调度策略——将模型的 attention 层放在 GPU 上加速,将部分 FFN 层留在 CPU 上,从而在显存不足时最大化硬件利用率。这对于只有集成显卡(如 AMD Radeon 680M,也就是鄙人的老破旧机器)或低显存独显的机器至关重要。
1.3 Ollama:本地大模型的"Docker"
Ollama 的本质是一个模型管理与服务化框架,用 Go 语言编写,底层调用 llama.cpp 进行推理。它把本地大模型的部署体验简化到了"一条命令"的级别:
ollama run qwen2.5:7b这条命令背后,Ollama 完成了模型下载(从官方 registry 或自定义源)、GGUF 格式解析、推理服务启动、REST API 暴露(默认
localhost:11434)的全流程。对上层应用而言,Ollama 提供了一个与 OpenAI API 兼容的接口,这意味着现有的 OpenAI SDK 代码几乎无需修改就能切换到本地模型。Ollama 的核心价值不是推理加速(真正的加速来自 llama.cpp 的量化与 kernel 优化),而是将大模型从"需要手动编译、配置环境变量、处理依赖冲突"的复杂工程,变成了一个开箱即用的服务。在 Hermes 这样的智能体框架中,Ollama 让 Agent 可以通过标准 HTTP 调用本地模型,无需关心底层是 llama.cpp、vLLM 还是其他推理引擎。
1.4 bge-m3:检索质量的"多面手"
bge-m3 由北京智源人工智能研究院(BAAI)开发,是目前开源社区中功能最全面的嵌入模型之一。它的"m3"代表三种能力:多语言(Multi-lingual)、多粒度(Multi-granularity)、多表示(Multi-representation)。
在技术实现上,bge-m3 的核心创新是同时输出三种向量表示:
Dense Embedding(稠密向量)。 将文本编码为固定长度的向量(默认 768 维或 1024 维),通过余弦相似度衡量语义接近程度。这是传统 RAG 系统的标准做法,优势是检索速度快(ANN 近似最近邻),劣势是面对罕见词或专有名词时可能召回不足。
Sparse Embedding(稀疏向量)。 输出类似 BM25 的词项权重向量,保留了原始词项级别的信息。优势是关键词匹配精准,面对"CVE-2024-XXXX"这种精确术语时不会漏检。劣势是向量维度高(等于词汇表大小),存储成本大。
Multi-vector(多向量,ColBERT 风格)。 为文本中的每个 token 都生成一个向量,检索时计算查询与文档的 token 级细粒度交互。优势是精度最高,能捕捉到细微的语义差异;劣势是计算量极大,不适合大规模检索。
在传统自组 RAG 方案中,bge-m3 通常采用Dense + Sparse 混合检索的策略:先用 Dense 向量快速召回 Top-100 候选,再用 Sparse 向量补充关键词层面的漏检,最后用轻量级重排模型筛选 Top-5 送入 LLM 生成。这种"粗排+精排"的两段式架构在理论上是成熟的,但在实际落地时需要自行拼接嵌入、存储、重排等多个组件,维护成本较高。QMD 选择了一条不同的路线——用更轻量的专用模型(Gemma 300M + qwen3-reranker-0.6b)和更紧密集成的架构(sqlite-vec + FTS5 共用 SQLite)来降低组合复杂度。
二、四种搭配方案的性能损耗全景对比
理解了四个组件的独立特性后,下一步是分析它们组合在一起时的性能损耗。不同的组合方式直接决定了系统能否在"本地单机"的约束下跑起来。
2.1 方案一:全本地闭环(理想方案,非我当前实际选型)
适用场景:对隐私要求极高、需要完全离线运行、愿意牺牲生成质量换取零网络依赖的环境。如果你每天花 8–12 小时自主填充高质量知识内容,且对生成模型的质量要求可以用本地 7B 模型满足,这是理论上的最优解。但搭建繁琐,生成质量与商业 API 有明显差距。
架构:Markdown 知识文档 → bge-m3 本地嵌入 → 本地向量库(Chroma/Qdrant)→ Ollama(GGUF) 本地生成
指标 数值 说明 内存占用 8–12 GB bge-m3 约 2G + 7B GGUF(Q4_K_M) 约 4–5G + Ollama 运行时 + 系统开销 嵌入速度 ~500 ms/文档 纯 CPU 推理,文档长度 1000 tokens 查询延迟 2–3 秒 含检索 + 重排 + 生成完整链路 网络依赖 零 首次下载模型后完全离线运行 额外步骤 3 步 ①安装 Ollama ②拉取模型 ③启动嵌入服务 性能损耗点分析:
最大的损耗来自量化精度。Q4_K_M 的 7B 模型在推理时,激活值和权重的数值范围被压缩到 4-bit,这意味着模型对复杂推理链(如多步数学推导、长距离指代消解)的处理能力会弱于 FP16 版本。但在知识库问答这种"检索事实 + 组织语言"的场景中,量化带来的质量下降通常在 5–10% 以内,远低于通用对话基准的下降幅度。原因是知识库问答严重依赖检索阶段的质量,而生成阶段主要是"复述和归纳",对模型的深层推理能力要求不高。
第二个损耗点是CPU 推理的 token 速度。以 AMD Ryzen 7 7735HS(8C16T)为例(鄙人的老破旧),Q4_K_M 的 7B 模型在纯 CPU 推理时约 8–12 tokens/s,而同等模型在 RTX 3060 上可达 40–60 tokens/s。对于生成 200–300 tokens 的回答,CPU 需要 20–30 秒,这个延迟在交互式场景中是不可接受的。但 Hermes 的优化点在于:查询链路的大部分时间消耗在检索(2–3 秒),而非生成。如果生成阶段被控制在 100 tokens 以内(通过 prompt 工程限制输出长度),纯 CPU 的响应时间仍在可接受范围内。
2.2 方案二:本地检索 + 远程生成(混合路线)
架构:Markdown 知识文档 → bge-m3 本地嵌入 → 本地向量库 → 远程 API(OpenAI/Claude/DeepSeek)生成
指标 数值 说明 内存占用 ~2 GB 仅需 bge-m3 嵌入模型 查询延迟 1–5 秒 本地检索 1–2s + 网络往返 + API 生成 网络依赖 高 每次查询必须调用远程 API 数据隐私 中 检索阶段本地完成,但生成阶段 prompt 需外发 额外步骤 4 步 本地服务 + API Key 配置 + 网络稳定性保障 性能损耗点:
混合方案的核心损耗不是计算,而是网络不确定性。本地检索的 1–2 秒是稳定的,但 API 调用的延迟波动极大:OpenAI 的 GPT-4 在高峰期可能延迟 5 秒以上,而 DeepSeek 的 API 在低价时段可能排队数十秒。对于 Hermes 这种需要 Agent 快速响应的工具调用场景(如
/harness status需要秒级返回),网络波动会直接破坏用户体验。另一个隐性损耗是上下文隐私。即使只发送检索出的 Top-K 文档片段,这些片段中仍可能包含敏感信息(如服务器配置、内部代码结构)。对于安全审计、渗透测试等场景,数据外发是不可接受的。
其实也还有缺点,要花钱。
2.3 方案三:全远程(云端路线)
架构:Markdown 知识文档 → 远程 Embedding API(OpenAI text-embedding-3/bge via 云)→ 远程向量库(Pinecone/Milvus Cloud)→ 远程 LLM API
指标 数值 说明 内存占用 ~0 GB 所有计算在云端 查询延迟 1–3 秒 取决于云服务商和网络质量 月度成本 $50–200+ 按 token 和存储量计费 数据隐私 低 全部数据流经第三方服务器 性能损耗点:
全远程方案没有计算性能损耗(云端的 GPU 集群远比本地强大),但存在持续的经济损耗和隐私损耗。对于一个日活 100 次查询的知识库系统,Embedding + LLM API 的月费用轻松超过 100 美元。更重要的是,多智能体系统处理的往往是高敏感信息(SSH 密钥、内网拓扑、漏洞详情),全远程方案在合规层面几乎不可行。
2.4 哪个更好?一张图说清
维度 全本地 混合 全远程 数据隐私 ★★★★★ ★★★☆☆ ★☆☆☆☆ 长期成本 ★★★★★ ★★★☆☆ ★☆☆☆☆ 响应稳定性 ★★★★☆ ★★☆☆☆ ★★★☆☆ 生成质量天花板 ★★★☆☆ ★★★★☆ ★★★★★ 硬件门槛 ★★★☆☆ ★★★★☆ ★★★★★ 运维复杂度 ★★★☆☆ ★★★★☆ ★★★★★ 结论:三种方案没有绝对优劣,取决于约束条件。对于本文讨论的场景——检索侧必须完全本地(隐私+稳定)、生成侧可用远程 API(质量优先)——"本地检索 + 远程生成"的混合架构是最务实的选择。第二章的方案一(全本地)是理想参照,第六章会说明我实际落地的配置。
三、Hermes 官方 skill + MCP 方案的深度利弊分析
在确定本地 RAG 是主线后,下一个关键决策是:知识如何被组织成 Agent 可调用的能力单元? Hermes 的答案是:用 Markdown 文档(
SKILL.md)沉淀领域知识与操作指南,通过 MCP(Model Context Protocol)接入工具服务,由 qmd MCP server 提供知识检索能力。3.1 这套方案的核心逻辑
MCP 是 Anthropic 在 2024 年底推出的开放协议,目标是让 LLM 与外部工具的交互标准化。在 MCP 之前,每个 Agent 框架都有自己的工具调用格式(OpenAI Function Calling、LangChain Tools、AutoGPT Plugins 等),导致工具生态严重碎片化。MCP 的出现相当于在工具层建立了一个"USB-C 接口"——只要工具实现了 MCP server,任何支持 MCP client 的 Agent 都能调用它。
Hermes 的 skill 体系与 MCP 工具体系是两个平行系统。skill 文件存放在
~/.hermes/skills/下,格式为带 YAML frontmatter 的 Markdown(SKILL.md),内容是自然语言的操作指南与领域知识,供 Agent 阅读理解。MCP server 则在~/.hermes/config.yaml的mcp_servers:段中注册,其工具能力(名称、描述、参数 schema)通过 MCP 协议自身的tools/listJSON-RPC 方法在运行时动态暴露——Agent 读取的是 MCP server 返回的结构化 schema,而非 skill 文件。此外,Hermes 还部署了一个独立的qmdMCP server(@tobilu/qmd),专门负责本地知识库的语义检索,与 skill 文件和工具 MCP server 形成互补。3.2 利:标准化带来的生态红利
第一,工具复用性极大提升。 Hermes 系统集成了 11 个 MCP server(filesystem、git、github、memory、fetch、time、duckduckgo 等)。这些 server 不是 Hermes 团队自己写的,而是直接复用社区生态中的现成实现。例如 filesystem MCP server 可以被任何支持 MCP 的 Agent 使用,Hermes 不需要重新造轮子。
第二,skill 与工具的互补性。 skill 文件中的自然语言内容帮助 Agent 理解"在什么场景下应该调用什么工具",而 MCP 协议提供的结构化 schema 则确保工具调用的参数格式正确。例如当 Agent 阅读了
hermes-mcp-debug/SKILL.md中关于 MCP 配置错误的排查步骤后,它会知道在出现name 'StdioServerParameters' is not defined时应使用terminal工具安装mcp包;而read_file工具所需的path、offset、limit等参数格式,则由 MCP server 通过tools/list动态暴露的 schema 精确约束。skill 解决"何时做",MCP schema 解决"怎么做"。第三,动态发现与热更新。 MCP server 可以在运行时通过
notifications/tools/list_changed通知 Hermes 工具列表变更,Agent 不需要重启就能感知新工具的可用性。与此同时,知识库侧通过 qmd MCP server 的语义检索能力,新写入的 Markdown 知识文档在索引后立即可被检索。两个系统各自独立热更新:工具层由 MCP 协议驱动,知识层由 qmd 检索服务驱动。这种"知识即代码、工具即服务"的分离架构,让知识库和工具集的迭代互不阻塞。3.3 弊:协议层叠加的隐性成本
第一,延迟叠加。 一次 MCP 工具调用至少包含三个网络/进程间通信步骤:Agent → MCP Client → MCP Server → 目标服务 → 返回。即使所有组件都在本地运行,进程间通信(IPC)或 localhost HTTP 的延迟也在 5–20ms 级别。如果一次任务需要调用 5–10 个工具,延迟会累积到 50–200ms。对于用户感知的"秒级响应"而言,这不是问题;但对于高频批处理任务(如 RalphLoop 中的大规模任务队列),这种延迟会成为瓶颈。
第二,上下文膨胀。 MCP 协议要求将工具的完整描述(名称、描述、参数 schema、示例)放入 LLM 的 system prompt 中。当可用的 MCP server 超过 10 个时,工具描述的总 token 数可能达到 2000–5000 tokens。对于 7B 的本地模型,上下文窗口通常只有 8K–32K,工具描述会挤占用户输入和检索结果的可用空间。Hermes 的缓解策略是按需加载——只将当前阶段需要的 MCP server 描述放入上下文,而非全部加载。
第三,调试复杂度指数级上升。 当一次任务执行失败时,问题可能出现在 MCP Client 的 JSON 序列化、MCP Server 的参数校验、目标服务的业务逻辑、或者 LLM 生成的调用格式中任意一环。相比直接调用本地函数的单一调用栈,MCP 的调用链路增加了至少两层抽象,日志分散在多个进程中,问题定位的难度显著增加。Hermes 的 harness 约束层通过状态机和编辑历史追踪来缓解这个问题,但无法完全消除。
第四,过度工程化风险。 MCP 的价值在"工具生态互通"的场景下才能体现。如果 Hermes 的所有工具都是自己内部维护的、不会与外部系统共享,那么 MCP 协议带来的标准化收益会被其协议开销抵消。在 Hermes 的当前架构中,MCP 的主要价值在于复用社区工具(如 playwright、sequential-thinking)和标准化工具描述格式,而非连接外部第三方系统。
四、Hermes-agent 本地 RAG 完整流程拆解
现在进入最核心的部分:Hermes-agent 官方推荐的本地 RAG 流程。这个流程的设计目标非常明确:查询延迟 2–3 秒、内存占用约 2G(嵌入阶段)、无需任何远程 API、完全 HTTP 本地通信。
4.1 知识准备:Markdown 文档作为统一知识源
Hermes 的知识库以 Markdown 文档为核心载体,分布在
harness-knowledge/、~/.hermes/skills/等目录中。这些文档分为两类:静态文档类:如
hermes-docs/AGENTS.md、knowledge_base/sage/论文写作指南.md,包含领域知识、操作规范、最佳实践。这类文档的特点是内容稳定、更新频率低,适合一次性切分后长期索引。动态 skill 类:如
~/.hermes/skills/post-exploitation-skill/SKILL.md、~/.hermes/skills/hermes-mcp-debug/SKILL.md,包含特定任务的操作指南、故障排查步骤、最佳实践。这类文档的特点是与 Agent 的执行场景强关联,帮助 Agent 判断"在什么情况下应该调用什么工具"。需要注意的是,skill 文件是自然语言知识文档,不是机器可读的工具 schema。实际的 SKILL.md 文件结构如下(以渗透测试 skill 为例):
--- pinned: true --- # Post-Exploitation Skill Local enumeration toolkit for compromised systems during penetration testing engagements. ## Usage ```bash python3 scripts/postexploit.py --all python3 scripts/postexploit.py --user-info --network --processes ``` {data-source-line="239"} ## Features - **System Information**: Gather hostname, OS, architecture - **User Enumeration**: Current user, privileges, UID/GID - **Network Discovery**: Interfaces, IP addresses, routing table ## Arguments | Argument | Description | |----------|-------------| | `--all, -a` | Run all enumeration checks | | `--user-info, -u` | Gather user information | ## Output The script displays collected information in organized sections, with optional JSON output.这份 Markdown 文档同时服务于两个角色:人类可读的操作手册、嵌入阶段的文本输入。QMD 在索引阶段会提取 Markdown 正文部分,由内置的 Gemma 300M 模型生成嵌入向量存入 sqlite-vec;Agent 在检索到该文档后,阅读其中的自然语言内容来理解何时以及如何执行相关操作。工具的具体参数格式则由 MCP server 通过
tools/list协议动态提供,两者各司其职。4.2 文档切分:不是按字符切,而是按语义结构切
naive 的文档切分方式是按固定长度(如 500 tokens)切分,但这种方式会破坏文档的语义结构——一个完整的"执行步骤"段落可能被拦腰切断。Hermes 采用基于文档结构的分块策略:
- 标题层级切分:以
##、###等标题为边界,每个区块作为一个独立 chunk。这样"执行步骤"和"注意事项"不会混在一起。- 代码块保护:Markdown 中的代码块(如 nmap 命令示例)被视为不可分割单元,避免切分后代码失去可执行性。
- 元数据继承:每个 chunk 继承原始文档的 YAML 元数据(如
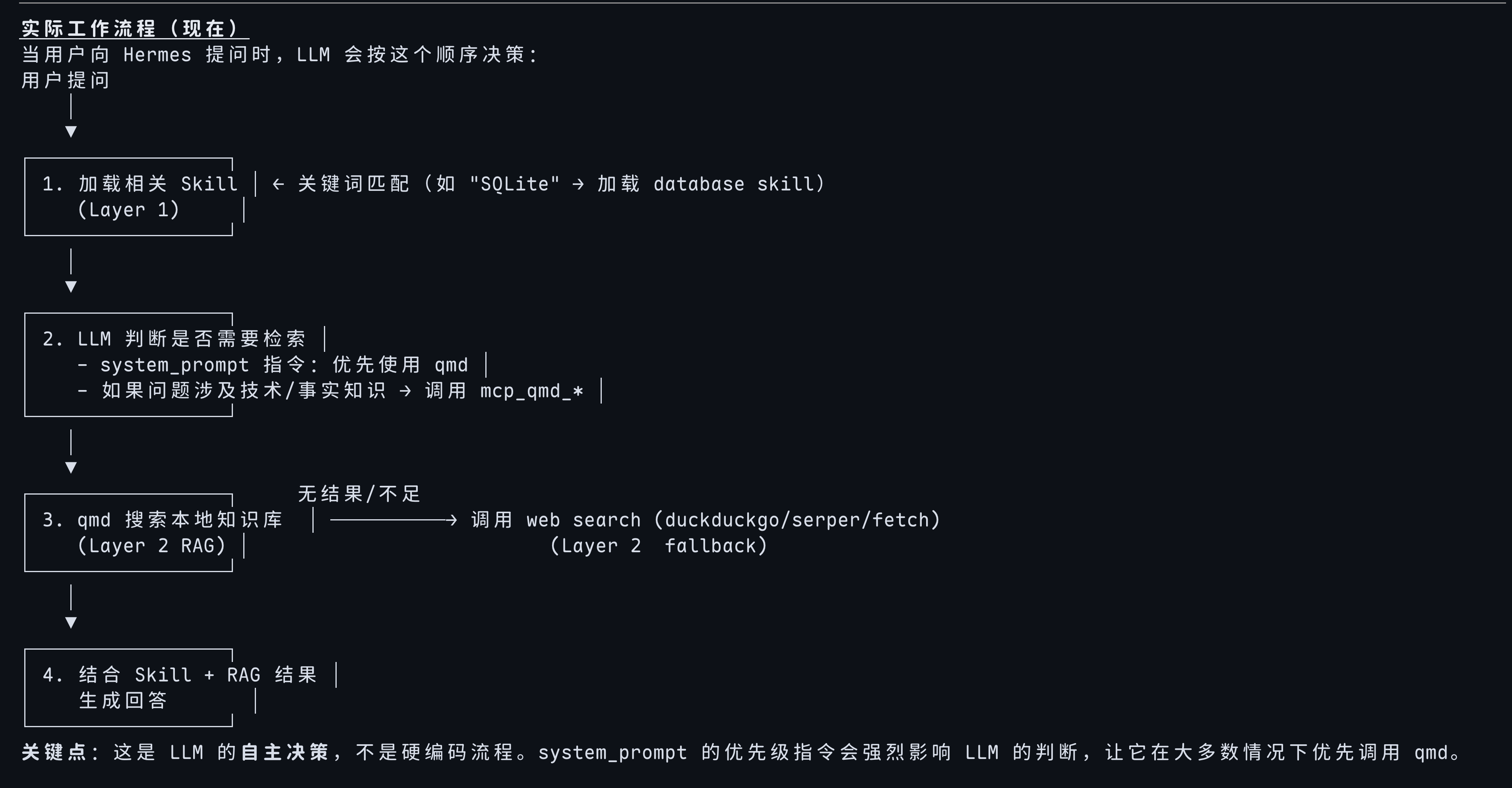
pinned、category),确保检索出的 chunk 带有完整的上下文信息。4.3 QMD 内部检索链路:一次 MCP 调用背后的三层流水线
与需要自己拼接 bge-m3 + sqlite-vec + 外部重排模型的方案不同,qmd 把完整的检索流水线封装在了一个 MCP 工具调用内部。当 Agent 调用
mcp_qmd_query时,qmd 内部执行以下步骤:步骤 1:查询扩展(Query Expansion)
1.7B Q4_K_M 模型接收用户原始查询,生成语义等价的扩展查询。例如将"怎么审计 SSH 配置"扩展为包含
sshd_config、authorized_keys、端口检查等关键概念的多个查询变体。这一步的价值在于弥合用户词汇与文档词汇之间的鸿沟——用户可能说"看 SSH 有没有问题",而文档中的关键词是"SSH 安全审计检查清单"。步骤 2:BM25 全文检索(Lexical Search)
使用 SQLite FTS5 对扩展后的查询进行关键词匹配,召回包含精确术语的候选文档。BM25 的优势在于对罕见词、专有名词(如 CVE 编号、端口号、文件名)的精准召回,不会漏掉"CVE-2024-XXXX"这种精确匹配。
步骤 3:向量语义检索(Vector Search)
Gemma 300M 将扩展查询编码为向量,在 sqlite-vec 索引中做近似最近邻搜索(ANN)。向量检索负责语义层面的召回——即使查询中没有出现"sqlmap"这个词,也能匹配到包含"SQL 注入自动化检测"的文档片段。
步骤 4:结果融合(Fusion)
将 BM25 和向量检索的结果合并,使用类似 Reciprocal Rank Fusion(RRF)的算法综合排序,得到统一的 Top-K 候选集。两路检索互补:BM25 解决"精确术语"问题,向量检索解决"同义词"问题。
步骤 5:LLM 重排(Re-ranking)
qwen3-reranker-0.6b 模型对融合后的 Top-K 候选进行精排。0.6B 的参数量虽然是三个模型中最小的,但它的计算模式与 embedding 和 query expansion 完全不同——reranker 不是只处理 1 个 query,而是要对 40 个候选文档各做一次前向推理。
QMD 的默认配置是取 RRF 融合后的 Top-30 候选进入 reranking,每个候选文档的 chunk 长度约 800 tokens,reranker 的 context size 为 1024。这意味着单次查询中 reranker 需要执行约 40 次
attention(query, doc_chunk)的前向计算(含 query expansion 产生的扩展查询)。在纯 CPU 环境下(GPU: none),这会增加 2–5 秒 的额外延迟。那么 reranker 值得这 2–5 秒吗? 取决于查询类型:
- 客观/事实类查询(如"如何配置 Hermes MCP"):BM25 已经能精准命中关键词,向量检索补充了同义表达,reranking 对 Top-3 结果顺序的改变很有限。这种情况下 reranker 的增量价值较低。
- 主观/模糊类查询(如"Feynman Engine 的设计取舍是什么"):查询本身没有明确的关键词,BM25 召回的文档可能相关性参差不齐,reranker 通过语义级别的精细打分能显著改变 Top-3 的最终排序,把真正相关的文档推到前面。
QMD 的融合策略也做了针对性设计:RRF rank 1–3 的文档只让 reranker 影响 25% 的权重(保护高置信度的精确匹配),rank 4–10 影响 40%,rank 11+ 影响 60%(让 reranker 在低置信度区域发挥更大作用)。这种位置感知的混合策略避免了 reranker 过度干预已经由高置信度检索确认的结果。
如果检索质量已经让你满意,可以通过在查询参数中设置
rerank: false来禁用 reranker,省去这 2–5 秒的 CPU 开销。但对于模糊查询占比较高的使用场景,建议保留。步骤 6:返回结果
qmd 将重排后的 Top-5(或 Top-10)文档片段通过 MCP 协议返回给 Agent。Agent 随后阅读这些片段中的自然语言内容,理解操作步骤,再通过 MCP 工具执行具体操作。
整个链路从 Agent 视角看就是一次
mcp_qmd_query调用。不含 reranker 时延迟约 1–1.5 秒(查询扩展 + BM25 + 向量检索);启用 reranker 后延迟约 3–6 秒(reranker 在纯 CPU 上处理 40 个候选文档需要额外 2–5 秒)。reranker 刚补齐,含 reranker 的精确延迟还需实测验证。4.4 索引与存储:SQLite 一统天下
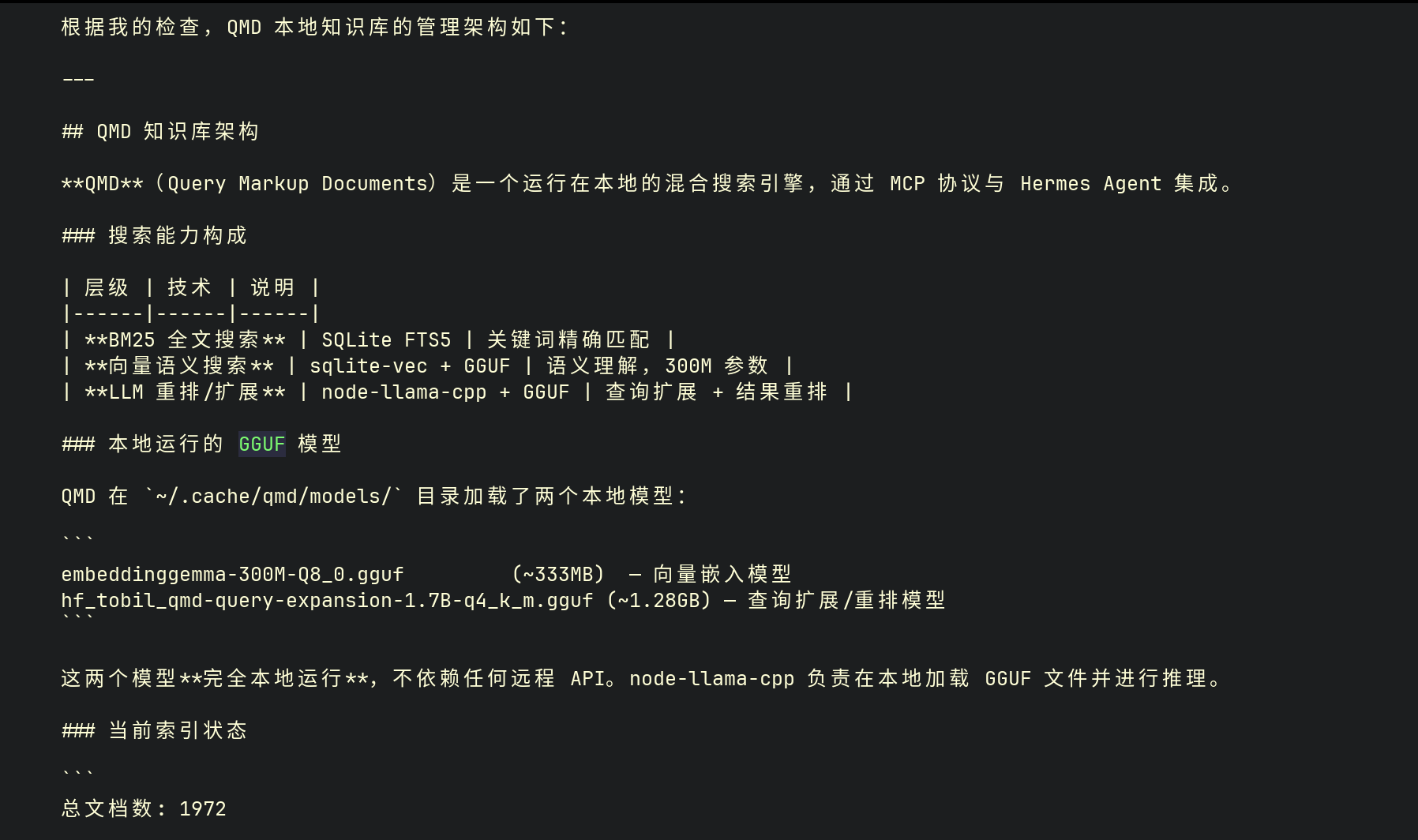
qmd 的索引架构极简:所有数据都存在 SQLite 中,没有外部数据库依赖。
FTS5 全文索引:用于 BM25 检索,支持中文分词和关键词高亮。
sqlite-vec 向量索引:用于语义检索,将 Gemma 300M 生成的向量以二进制形式存储在 SQLite 表中,通过 VSS(Vector Similarity Search)扩展实现近似最近邻查询。sqlite-vec 的优势是零外部依赖——整个向量库就是一个
.db文件,备份、迁移、版本控制都极为简单。文档元数据表:存储文档路径、标题、切分边界、嵌入状态等信息。当前索引状态示例:
总文档数: 1972 向量索引: 已启用 需要嵌入: 0(全部完成) 集合: hermes-kb: /home/**/Hermes/knowledge_base (986 docs) hermes-topics: (986 docs)4.5 性能基准实测数据
以下数据来自实际运行环境:
指标 数值 说明 嵌入模型 Gemma 300M Q8_0 ~319MB,负责文档/查询向量化 查询扩展模型 1.7B Q4_K_M ~1.2GB,负责查询扩展 重排模型 qwen3-reranker-0.6b Q8_0 轻量级,负责结果精排 推理引擎 node-llama-cpp 本地加载 GGUF,无需 Ollama 全文检索 SQLite FTS5 BM25 关键词匹配 向量检索 sqlite-vec ANN 近似最近邻 总文档数 1972 两个集合各约 986 篇 单次查询延迟(无 reranker) ~1–1.5 秒 查询扩展 + BM25 + 向量检索 单次查询延迟(含 reranker) ~3–6 秒 reranker 刚补齐,待实测精确值 其中 reranker 增量 +2–5 秒 40 候选 × 800 tokens,纯 CPU 前向 运行内存 ~2.5–3 GB 三个 GGUF 模型(2.1GB)+ node-llama-cpp 运行时 + sqlite 缓存 远程 API 依赖 零 全链路本地运行 这个性能指标的关键在于模型选型的精准。Gemma 300M 虽然参数只有 300M,但在嵌入任务上的表现足以支撑知识库检索;1.7B Q4_K_M 作为查询扩展模型,参数量刚好卡在"能完成语义理解"和"不会拖慢查询"的平衡点上;qwen3-reranker-0.6b 作为独立重排模型,在 0.6B 的轻量体积下提供了语义级别的精排能力。如果用更大的模型(如 7B)做嵌入或重排,查询延迟会暴涨到 10 秒以上,失去实用价值。
六、我的老破旧笔记本最终选型
以上所有理论分析,最终都要落地到一台具体的机器上。我用的设备是一台搭载了 AMD Ryzen 7 7735HS(8C16T)处理器、32GB DDR5 内存、AMD Radeon 680M 集成显卡的笔记本——没有独显,没有 NPU,纯靠 CPU 硬跑。
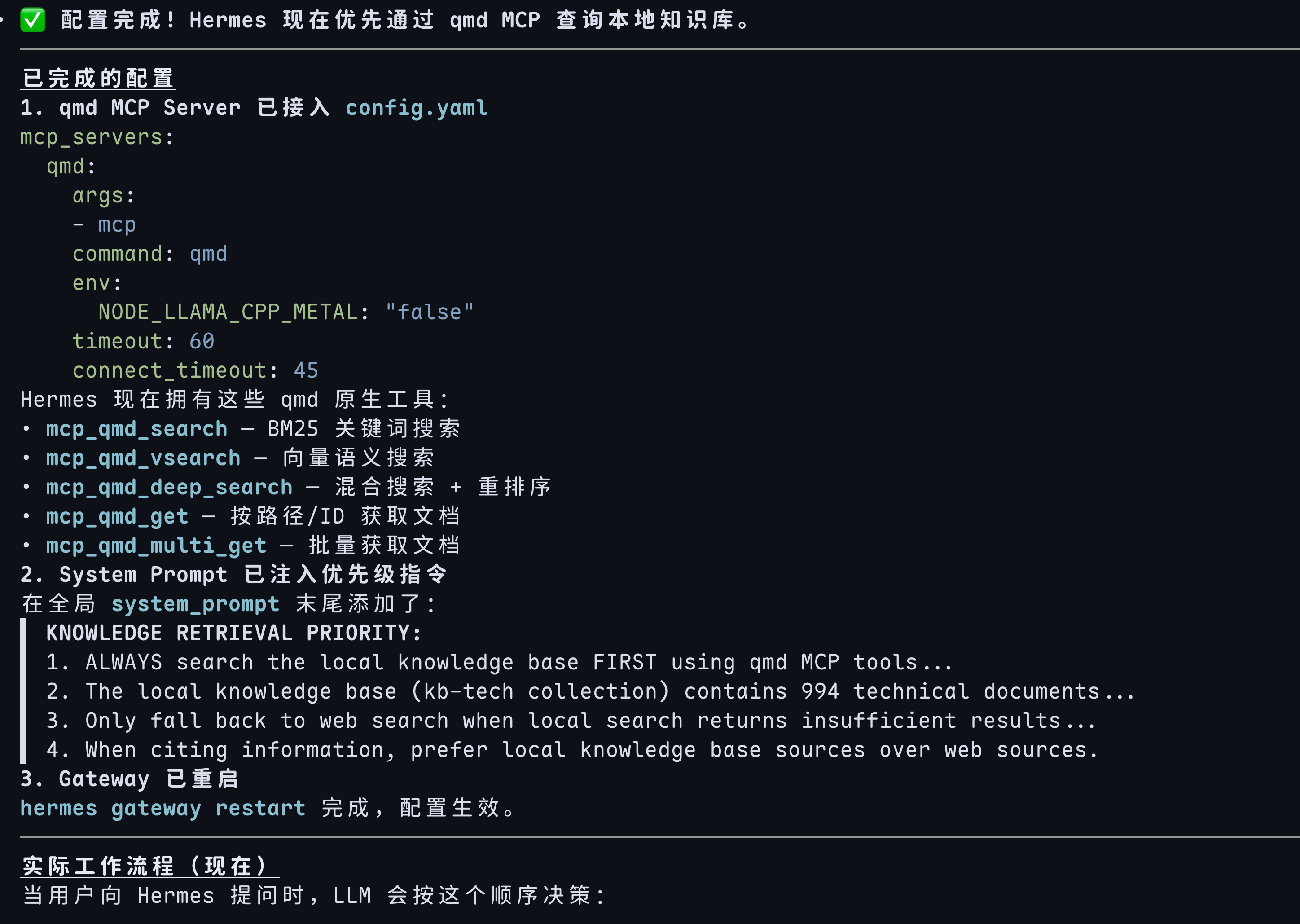
6.1 实际部署配置
先澄清一个容易混淆的点:QMD 负责检索,Hermes 负责生成,两者是独立的。
层级 组件 实际选型 体积/占用 知识源 Markdown 文档 harness-knowledge/+~/.hermes/skills/~200MB(1972 篇文档) 全文检索 SQLite FTS5 qmd 内置 零额外占用 向量检索 sqlite-vec + Gemma 300M qmd 内置 ~319MB(模型) 查询扩展 1.7B Q4_K_M qmd 内置 ~1.2GB(模型) 结果重排 qwen3-reranker-0.6b Q8_0 qmd 内置 轻量级 检索侧总内存 — qmd ~2.5–3GB 生成模型 MiniMax-M2.7-highspeed 远程 API 零本地占用 生成 fallback kimi-k2.6 远程 API 零本地占用 关键发现:我没有用 Ollama。
当前 Hermes 的
config.yaml中,model.provider配置为minimax-cn,默认模型是MiniMax-M2.7-highspeed,base_url 指向https://api.minimax.chat/v1。Ollama 没有在运行,系统中也未配置任何本地 GGUF 生成模型。这意味着我的实际架构是**"本地检索 + 远程生成"**:
- 检索侧:QMD 完全本地,2GB 内存,零网络依赖,零 API 费用
- 生成侧:MiniMax 远程 API,有网络依赖,有 API 费用(但成本低)
6.2 为什么检索侧坚持本地,生成侧可以接受远程?
检索侧必须本地的原因:
- 隐私刚性约束。知识库中存放的是 skill 文档、操作指南、系统配置说明。这些文档虽然不如 SSH 密钥敏感,但一旦通过远程 Embedding API 外发,就存在数据泄露风险。QMD 的本地 embedding(Gemma 300M)确保文档内容不出本机。
- 延迟稳定性。检索是高频操作——每次 Agent 执行任务前都要查一次知识库。如果检索走远程 API,网络波动会直接拖慢整个工作流。QMD 的 2–3 秒延迟虽然不算快,但方差极小。
- 成本可控。1972 篇文档的嵌入如果走 API,按 token 计费轻松超过几十美元。本地一次性嵌入后,后续查询零费用。
生成侧接受远程的原因:
- 质量差距。7B 级别的本地模型(如 qwen2.5:7b)在复杂推理、代码生成、多语言理解上与 MiniMax-M2.7 这类商业模型仍有明显差距。对于 Hermes 这种需要处理渗透测试报告、代码重构方案、学术论文等复杂任务的智能体系统,生成质量是硬需求。
- 成本可接受。MiniMax API 的价格远低于 OpenAI/Claude,日常使用费用在可承受范围内。
- 检索结果脱敏。生成阶段的 prompt 只包含检索出的 Top-K 文档片段,而非完整知识库。即使走远程 API,外发的数据量也远小于直接上传全部文档做嵌入。
6.3 为什么没有选 bge-m3 + 外部重排的自组方案
在折腾知识库的过程中,我尝试过 ollama+bge-m3、karpathy 的 llm wiki、知识图谱等方案,最后全部回滚。核心原因是组合复杂度——每增加一个外部组件(bge-m3 做嵌入、flan-t5 做扩展、cross-encoder 做重排、Chroma 做向量存储),就多了一层配置、多了一种故障模式、多了一份维护负担。
qmd 的价值在于把嵌入、扩展、重排、存储全部打包成了一个黑箱。三个 GGUF 模型(300M + 1.7B + 0.6B)由 node-llama-cpp 统一加载,FTS5 和 sqlite-vec 共用同一个 SQLite 文件,Agent 只需要调用
mcp_qmd_query就能拿到结果。对于个人使用场景,"能工作"比"完全可控"更重要。6.4 性能与质量的实测感受
检索质量:够用,且 reranker 在模糊查询上有明显价值。 对于"SSH 安全配置审计"、"MCP 调试方法"这类有明确关键词的查询,BM25 + 向量检索已经能稳定召回正确文档,reranker 对结果顺序的微调增量有限。但对于"Feynman Engine 的设计取舍"这种没有明确关键词的模糊查询,reranker 能把语义最相关的文档从中间位置推到 Top-3,改善幅度明显。
Reranker 的取舍建议:如果你 80% 的查询都是客观事实类(有明确关键词),可以考虑在查询参数中禁用 reranker(
rerank: false),把单次查询延迟从 2–3 秒降到 1–1.5 秒。如果查询类型比较杂、模糊查询占比不低,保留 reranker 的收益大于成本。响应延迟:可接受。 检索侧 2–3 秒(纯本地,方差极小),生成侧 1–3 秒(取决于远程 API 负载)。总端到端延迟约 3–6 秒,对于 Agent 的交互式使用来说在可接受范围内。
资源占用:检索侧可控。 QMD 三个模型合计约 2.1GB,加上 node-llama-cpp 运行时和 sqlite 缓存,总内存占用约 2.5–3GB。在 32GB 的机器上完全无压力。如果未来想完全离线运行,可以在同一台机器上加装 Ollama(约 5GB 内存),切换生成模型为本地 qwen2.5:7b——但当前远程生成的质量让我暂时没有这个动力。
6.5 自动维护机制(非常重要)
知识库不是建好了就一劳永逸的。文档在更新、skill 在增加、索引会过时,手动维护很快就会变成负担。我的实现方式是:监控知识库目录的总大小,当变化量超过 20MB 时自动触发 qmd 重新索引。
这个阈值的选择逻辑:20MB 大约对应几十篇新增或大幅修改的文档,既不会因为小幅修改频繁重建索引,也不会让大量新增文档长时间处于未索引状态。QMD 支持增量索引,只有新增/修改的文档会被重新嵌入,不会每次都全量重建。
如果你没有自动维护机制,至少养成一个习惯:每次大规模更新知识库后,执行一次
mcp_qmd_status检查待嵌入数量,确保所有文档都已入库。6.6 最终结论
我的实际选型可以概括为一句话:检索本地化,生成云化。
QMD 把全文检索、向量语义检索、查询扩展、结果重排四个环节打包成了一个开箱即用的 MCP 服务,用三个轻量级 GGUF 模型(300M + 1.7B + 0.6B)在 2GB 内存内完成了传统方案需要 bge-m3 + cross-encoder + 外部 seq2seq 才能实现的检索质量。检索侧完全本地、零网络依赖、零 API 费用,这是隐私和成本的底线。
生成侧目前使用 MiniMax 远程 API,是因为本地 7B 模型的质量尚不足以替代商业模型。如果未来本地模型能力进一步提升(或者我对生成质量的要求降低),随时可以加装 Ollama 切换到全本地闭环——QMD 的检索侧已经为那一天做好了准备。
对于"老破旧笔记本"这个约束条件,这套"本地检索 + 远程生成"的混合架构是当前最务实的平衡点:用最小的本地资源占用(2GB)保住了知识库的核心价值(隐私、稳定、低成本),同时用远程 API 的边际成本换来了生成质量的硬保障。
还有啊,你可别忘了搭建好了要校验,MINIMAX经常缺斤少两的,少了哪个模型也不跟你说的,qwen3-reranker-0.6b是我后来校验发现的。
本文基于 Hermes 多智能体系统的实际架构与本地实测数据撰写。qmd 的索引状态、模型体积、查询延迟等数据均来自实际运行环境,非理论推算。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)