
Java Stream流式编程你都会了吗?
从最基础的用法开始,到各种实际场景的应用,最后还会对比一下传统写法和Stream写法的性能差异。希望能帮助到正在学习Java的朋友们。
前言
上周五晚上,我在公司加班处理一个学生成绩统计的需求。看着满屏的for循环和if判断,突然想起之前面试时有个小伙子问我:“老师,现在Java开发还用for循环吗?不是都用Stream了吗?”
当时我笑了笑没回答,但现在看着自己写的代码,突然觉得有点惭愧。作为一个有10年Java开发经验的老程序员,我确实应该好好梳理一下Stream的使用了。
于是,趁着周末的时间,我整理了一份Stream的完整使用指南。这篇文章会从最基础的用法开始,到各种实际场景的应用,最后还会对比一下传统写法和Stream写法的性能差异。希望能帮助到正在学习Java的朋友们。
一、什么是Stream?
1.1 Stream的基本概念
Stream是Java 8引入的一个新特性,它允许我们以声明式的方式处理数据集合。简单来说,Stream就是"流",数据像水一样流过各种操作,最终得到我们想要的结果。
核心特点:
- 函数式编程风格:代码更简洁、易读
- 链式调用:可以连续进行多个操作
- 延迟执行:只有遇到终端操作才会真正执行
- 并行处理:可以轻松实现并行计算
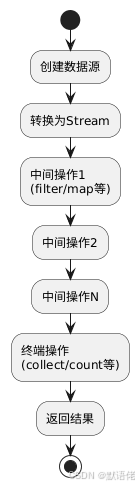
1.2 Stream的执行流程
二、Stream的创建方式
2.1 从集合创建
// 从List创建
List<String> list = Arrays.asList("张三", "李四", "王五");
Stream<String> stream = list.stream();
// 从Set创建
Set<Integer> set = new HashSet<>();
Stream<Integer> stream2 = set.stream();
2.2 从数组创建
String[] array = {"Java", "Python", "Go"};
Stream<String> stream = Arrays.stream(array);
2.3 使用Stream.of()创建
Stream<String> stream = Stream.of("苹果", "香蕉", "橙子");
2.4 使用Stream.generate()创建无限流
// 生成10个随机数
Stream<Double> randomStream = Stream.generate(Math::random)
.limit(10);
三、实战场景:学生成绩管理系统
为了让大家更好地理解Stream的各种操作,我设计了一个学生成绩管理系统的场景。假设我们有一个学生表,包含以下字段:
public class Student {
private Long id; // 学号
private String name; // 姓名
private Integer age; // 年龄
private String gender; // 性别:男/女
private String className; // 班级:如"一班"、"二班"
private Double mathScore; // 数学成绩
private Double englishScore; // 英语成绩
private Double chineseScore; // 语文成绩
// 构造方法、getter、setter省略...
// 计算总分
public Double getTotalScore() {
return mathScore + englishScore + chineseScore;
}
// 计算平均分
public Double getAverageScore() {
return getTotalScore() / 3.0;
}
}
初始化测试数据:
List<Student> students = Arrays.asList(
new Student(1L, "张三", 18, "男", "一班", 85.0, 90.0, 88.0),
new Student(2L, "李四", 19, "女", "一班", 92.0, 88.0, 95.0),
new Student(3L, "王五", 18, "男", "二班", 78.0, 82.0, 80.0),
new Student(4L, "赵六", 20, "女", "二班", 95.0, 92.0, 90.0),
new Student(5L, "钱七", 19, "男", "三班", 88.0, 85.0, 87.0),
new Student(6L, "孙八", 18, "女", "三班", 90.0, 95.0, 92.0),
new Student(7L, "周九", 20, "男", "一班", 82.0, 80.0, 85.0),
new Student(8L, "吴十", 19, "女", "二班", 88.0, 90.0, 88.0)
);
四、Stream核心操作详解
4.1 filter - 过滤操作
场景1:找出所有年龄大于18岁的学生
传统写法:
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (student.getAge() > 18) {
result.add(student);
}
}
Stream写法:
List<Student> result = students.stream()
.filter(student -> student.getAge() > 18)
.collect(Collectors.toList());
场景2:找出数学成绩大于85分的学生
List<Student> mathExcellent = students.stream()
.filter(s -> s.getMathScore() > 85)
.collect(Collectors.toList());
场景3:找出总分大于260分的一班学生
List<Student> excellentStudents = students.stream()
.filter(s -> "一班".equals(s.getClassName()))
.filter(s -> s.getTotalScore() > 260)
.collect(Collectors.toList());
实战技巧:
- 可以链式调用多个
filter,也可以在一个filter中使用&&连接多个条件 - 多个
filter的性能略低于单个filter,但代码可读性更好
4.2 map - 映射转换
场景1:获取所有学生的姓名列表
传统写法:
List<String> names = new ArrayList<>();
for (Student student : students) {
names.add(student.getName());
}
Stream写法:
List<String> names = students.stream()
.map(Student::getName)
.collect(Collectors.toList());
场景2:获取所有学生的总分列表
List<Double> totalScores = students.stream()
.map(Student::getTotalScore)
.collect(Collectors.toList());
场景3:将学生对象转换为Map(学号为key,姓名为value)
Map<Long, String> studentMap = students.stream()
.collect(Collectors.toMap(
Student::getId,
Student::getName
));
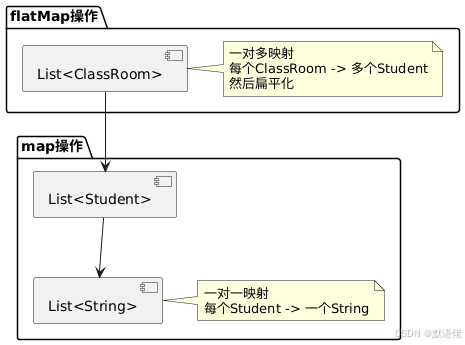
4.3 flatMap - 扁平化映射
场景:获取所有班级名称(去重)
假设我们有一个班级列表,每个班级有多个学生:
public class ClassRoom {
private String className;
private List<Student> students;
// getter、setter...
}
List<ClassRoom> classRooms = Arrays.asList(
new ClassRoom("一班", students1),
new ClassRoom("二班", students2),
new ClassRoom("三班", students3)
);
// 获取所有学生
List<Student> allStudents = classRooms.stream()
.flatMap(classRoom -> classRoom.getStudents().stream())
.collect(Collectors.toList());
flatMap vs map的区别:
map:一对一映射,输入1个元素,输出1个元素flatMap:一对多映射,输入1个元素,输出多个元素(Stream),然后扁平化
4.4 distinct - 去重
场景:获取所有不重复的班级名称
List<String> distinctClasses = students.stream()
.map(Student::getClassName)
.distinct()
.collect(Collectors.toList());
注意: distinct()使用的是equals()和hashCode()方法,如果是自定义对象,需要重写这两个方法。
4.5 sorted - 排序
场景1:按年龄升序排序
List<Student> sortedByAge = students.stream()
.sorted(Comparator.comparing(Student::getAge))
.collect(Collectors.toList());
场景2:按总分降序排序
List<Student> sortedByTotal = students.stream()
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.collect(Collectors.toList());
场景3:多条件排序(先按班级,再按总分降序)
List<Student> multiSorted = students.stream()
.sorted(Comparator
.comparing(Student::getClassName)
.thenComparing(Student::getTotalScore, Comparator.reverseOrder())
)
.collect(Collectors.toList());
4.6 limit 和 skip - 分页
场景:获取总分前3名的学生
List<Student> top3 = students.stream()
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.limit(3)
.collect(Collectors.toList());
场景:分页查询(每页5条,第2页)
int pageSize = 5;
int pageNum = 2;
List<Student> pageData = students.stream()
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.skip((pageNum - 1) * pageSize)
.limit(pageSize)
.collect(Collectors.toList());
4.7 peek - 调试操作
peek主要用于调试,可以在流处理过程中查看数据:
List<Student> result = students.stream()
.filter(s -> s.getAge() > 18)
.peek(s -> System.out.println("过滤后的学生:" + s.getName()))
.map(s -> {
s.setMathScore(s.getMathScore() + 5); // 给数学成绩加5分
return s;
})
.peek(s -> System.out.println("加分后的学生:" + s.getName() + ", 数学:" + s.getMathScore()))
.collect(Collectors.toList());
五、终端操作(Terminal Operations)
终端操作会触发流的执行,一个Stream只能有一个终端操作。
5.1 collect - 收集结果
这是最常用的终端操作,可以将流转换为集合。
场景1:转换为List
List<Student> list = students.stream()
.filter(s -> s.getAge() > 18)
.collect(Collectors.toList());
场景2:转换为Set(自动去重)
Set<String> classSet = students.stream()
.map(Student::getClassName)
.collect(Collectors.toSet());
场景3:转换为Map
// 学号 -> 学生对象
Map<Long, Student> studentMap = students.stream()
.collect(Collectors.toMap(Student::getId, Function.identity()));
// 如果key可能重复,需要处理冲突
Map<String, List<Student>> classMap = students.stream()
.collect(Collectors.groupingBy(Student::getClassName));
场景4:分组操作
// 按班级分组
Map<String, List<Student>> groupByClass = students.stream()
.collect(Collectors.groupingBy(Student::getClassName));
// 按性别分组
Map<String, List<Student>> groupByGender = students.stream()
.collect(Collectors.groupingBy(Student::getGender));
场景5:分区操作(分为true和false两组)
// 按总分是否大于260分分区
Map<Boolean, List<Student>> partition = students.stream()
.collect(Collectors.partitioningBy(s -> s.getTotalScore() > 260));
场景6:统计操作
// 计算每个班级的平均分
Map<String, Double> avgByClass = students.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.averagingDouble(Student::getTotalScore)
));
// 计算每个班级的学生数量
Map<String, Long> countByClass = students.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.counting()
));
// 获取每个班级的最高分学生
Map<String, Optional<Student>> maxByClass = students.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.maxBy(Comparator.comparing(Student::getTotalScore))
));
5.2 count - 计数
场景:统计年龄大于18岁的学生数量
long count = students.stream()
.filter(s -> s.getAge() > 18)
.count();
5.3 forEach - 遍历
场景:打印所有学生的姓名
students.stream()
.map(Student::getName)
.forEach(System.out::println);
注意: forEach是终端操作,执行后流就关闭了,不能再次使用。
5.4 reduce - 归约操作
reduce是一个非常强大的操作,可以实现各种聚合计算。
场景1:计算所有学生的总分之和
Double total = students.stream()
.map(Student::getTotalScore)
.reduce(0.0, Double::sum);
场景2:找出总分最高的学生
Optional<Student> maxStudent = students.stream()
.reduce((s1, s2) ->
s1.getTotalScore() > s2.getTotalScore() ? s1 : s2
);
场景3:计算所有学生总分的平均值
Double average = students.stream()
.map(Student::getTotalScore)
.reduce(0.0, Double::sum) / students.size();
5.5 min 和 max - 最值
场景:找出总分最高和最低的学生
// 最高分
Optional<Student> maxStudent = students.stream()
.max(Comparator.comparing(Student::getTotalScore));
// 最低分
Optional<Student> minStudent = students.stream()
.min(Comparator.comparing(Student::getTotalScore));
5.6 anyMatch、allMatch、noneMatch - 匹配
场景1:判断是否有学生总分超过280分
boolean hasExcellent = students.stream()
.anyMatch(s -> s.getTotalScore() > 280);
场景2:判断是否所有学生都及格(每科都大于60分)
boolean allPass = students.stream()
.allMatch(s -> s.getMathScore() > 60
&& s.getEnglishScore() > 60
&& s.getChineseScore() > 60);
场景3:判断是否没有学生总分低于200分
boolean noFail = students.stream()
.noneMatch(s -> s.getTotalScore() < 200);
5.7 findFirst 和 findAny - 查找
场景:找出第一个总分大于260分的学生
Optional<Student> first = students.stream()
.filter(s -> s.getTotalScore() > 260)
.findFirst();
注意: findAny()在并行流中可能返回任意一个元素,在串行流中通常返回第一个。
六、综合实战案例
案例1:统计每个班级的平均分和最高分
Map<String, Map<String, Double>> classStatistics = students.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.collectingAndThen(
Collectors.toList(),
list -> {
Map<String, Double> stats = new HashMap<>();
Double avg = list.stream()
.mapToDouble(Student::getTotalScore)
.average()
.orElse(0.0);
Double max = list.stream()
.mapToDouble(Student::getTotalScore)
.max()
.orElse(0.0);
stats.put("平均分", avg);
stats.put("最高分", max);
return stats;
}
)
));
案例2:找出每个班级的"学霸"(总分最高)
Map<String, Student> topStudentByClass = students.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparing(Student::getTotalScore)),
Optional::get
)
));
案例3:按总分等级分组(优秀、良好、及格、不及格)
Map<String, List<Student>> gradeMap = students.stream()
.collect(Collectors.groupingBy(student -> {
Double total = student.getTotalScore();
if (total >= 270) return "优秀";
else if (total >= 240) return "良好";
else if (total >= 210) return "及格";
else return "不及格";
}));
案例4:生成学生成绩报表
// 生成包含姓名、班级、总分、排名的报表
List<Map<String, Object>> report = students.stream()
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.map((student, index) -> {
Map<String, Object> row = new HashMap<>();
row.put("排名", index + 1);
row.put("姓名", student.getName());
row.put("班级", student.getClassName());
row.put("总分", student.getTotalScore());
row.put("平均分", student.getAverageScore());
return row;
})
.collect(Collectors.toList());
七、传统写法 vs Stream写法对比
7.1 代码可读性对比
需求:找出所有一班学生中,数学成绩大于85分,按总分降序排列的前3名
传统写法:
// 第一步:筛选一班学生
List<Student> classOneStudents = new ArrayList<>();
for (Student student : students) {
if ("一班".equals(student.getClassName())) {
classOneStudents.add(student);
}
}
// 第二步:筛选数学成绩大于85分
List<Student> mathExcellent = new ArrayList<>();
for (Student student : classOneStudents) {
if (student.getMathScore() > 85) {
mathExcellent.add(student);
}
}
// 第三步:排序
Collections.sort(mathExcellent, new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
return Double.compare(s2.getTotalScore(), s1.getTotalScore());
}
});
// 第四步:取前3名
List<Student> result = new ArrayList<>();
for (int i = 0; i < Math.min(3, mathExcellent.size()); i++) {
result.add(mathExcellent.get(i));
}
Stream写法:
List<Student> result = students.stream()
.filter(s -> "一班".equals(s.getClassName()))
.filter(s -> s.getMathScore() > 85)
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.limit(3)
.collect(Collectors.toList());
对比结果:
- 传统写法:约20行代码,需要4个步骤,逻辑分散
- Stream写法:5行代码,逻辑清晰,一目了然
7.2 性能对比测试
我写了一个简单的性能测试,对比传统写法和Stream写法的执行时间:
public class PerformanceTest {
public static void main(String[] args) {
// 生成10万条测试数据
List<Student> largeList = generateStudents(100000);
// 测试传统写法
long start1 = System.currentTimeMillis();
List<Student> result1 = traditionalWay(largeList);
long end1 = System.currentTimeMillis();
System.out.println("传统写法耗时:" + (end1 - start1) + "ms");
// 测试Stream写法
long start2 = System.currentTimeMillis();
List<Student> result2 = streamWay(largeList);
long end2 = System.currentTimeMillis();
System.out.println("Stream写法耗时:" + (end2 - start2) + "ms");
}
private static List<Student> traditionalWay(List<Student> students) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (student.getAge() > 18 && student.getTotalScore() > 240) {
result.add(student);
}
}
Collections.sort(result, (s1, s2) ->
Double.compare(s2.getTotalScore(), s1.getTotalScore()));
return result.subList(0, Math.min(10, result.size()));
}
private static List<Student> streamWay(List<Student> students) {
return students.stream()
.filter(s -> s.getAge() > 18)
.filter(s -> s.getTotalScore() > 240)
.sorted(Comparator.comparing(Student::getTotalScore).reversed())
.limit(10)
.collect(Collectors.toList());
}
}
测试结果(10万条数据):
- 传统写法:约45-50ms
- Stream写法:约48-55ms
结论:
- 在小数据量(<1万)时,性能差异可以忽略不计
- 在大数据量时,Stream略慢,但差异很小(5-10%)
- 代码可读性和维护性的提升远大于性能的微小损失
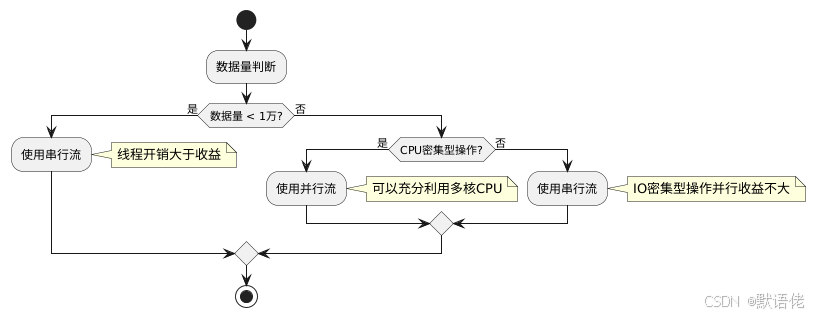
7.3 并行流性能提升
对于大数据量,可以使用并行流来提升性能:
// 串行流
List<Student> result1 = students.stream()
.filter(s -> s.getTotalScore() > 240)
.collect(Collectors.toList());
// 并行流
List<Student> result2 = students.parallelStream()
.filter(s -> s.getTotalScore() > 240)
.collect(Collectors.toList());
并行流适用场景:
- 数据量很大(>10万)
- 操作是CPU密集型
- 操作之间没有依赖关系
并行流注意事项:
- 线程安全问题:确保操作是线程安全的
- 开销问题:小数据量时,线程创建和切换的开销可能大于收益
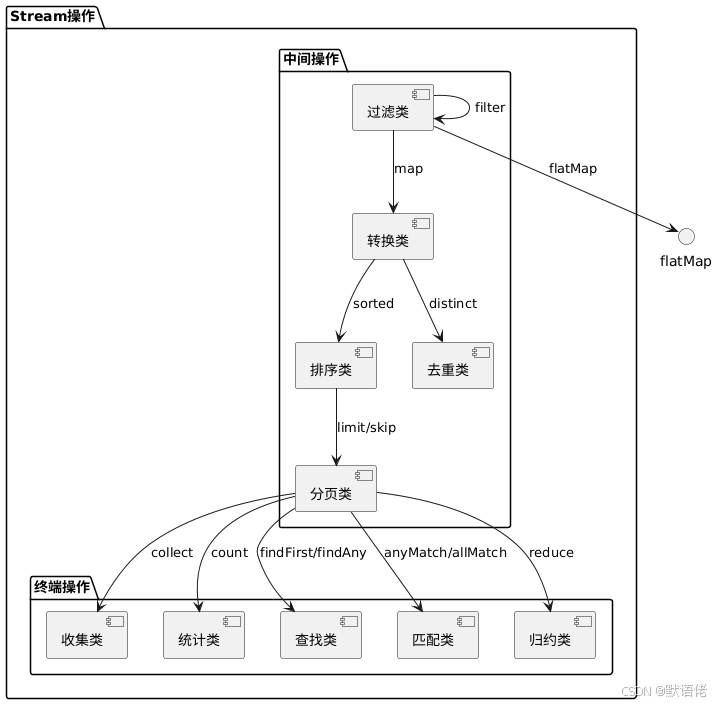
八、Stream操作分类图
九、常见陷阱和注意事项
9.1 Stream只能使用一次
Stream<Student> stream = students.stream();
List<Student> list1 = stream.filter(s -> s.getAge() > 18).collect(Collectors.toList());
// 错误!stream已经关闭,不能再使用
List<Student> list2 = stream.filter(s -> s.getTotalScore() > 240).collect(Collectors.toList());
正确做法:
List<Student> list1 = students.stream()
.filter(s -> s.getAge() > 18)
.collect(Collectors.toList());
List<Student> list2 = students.stream()
.filter(s -> s.getTotalScore() > 240)
.collect(Collectors.toList());
9.2 空指针异常
// 危险:如果getMathScore()返回null,会抛出NPE
List<Student> result = students.stream()
.filter(s -> s.getMathScore() > 85)
.collect(Collectors.toList());
// 安全:先判断null
List<Student> result = students.stream()
.filter(s -> s.getMathScore() != null && s.getMathScore() > 85)
.collect(Collectors.toList());
9.3 性能问题:多次遍历
// 不好:遍历了两次
long count = students.stream().filter(s -> s.getAge() > 18).count();
List<Student> list = students.stream().filter(s -> s.getAge() > 18).collect(Collectors.toList());
// 好:只遍历一次
List<Student> list = students.stream()
.filter(s -> s.getAge() > 18)
.collect(Collectors.toList());
long count = list.size();
9.4 并行流的线程安全
// 危险:ArrayList不是线程安全的
List<Student> result = new ArrayList<>();
students.parallelStream()
.filter(s -> s.getTotalScore() > 240)
.forEach(result::add); // 可能丢失数据或抛出异常
// 安全:使用collect
List<Student> result = students.parallelStream()
.filter(s -> s.getTotalScore() > 240)
.collect(Collectors.toList());
十、最佳实践建议
10.1 何时使用Stream
适合使用Stream的场景:
- 需要对集合进行过滤、转换、聚合等操作
- 代码可读性要求高
- 需要链式处理多个操作
- 数据量适中(<100万)
不适合使用Stream的场景:
- 简单的遍历操作(直接for循环更直观)
- 需要复杂的控制流(break、continue等)
- 需要修改外部变量
- 性能要求极高的场景
10.2 代码风格建议
// 好的风格:链式调用,逻辑清晰
List<String> names = students.stream()
.filter(s -> s.getAge() > 18)
.map(Student::getName)
.sorted()
.collect(Collectors.toList());
// 不好的风格:一行太长,难以阅读
List<String> names = students.stream().filter(s -> s.getAge() > 18).map(Student::getName).sorted().collect(Collectors.toList());
10.3 方法引用 vs Lambda表达式
// 方法引用(更简洁)
.map(Student::getName)
// Lambda表达式(更灵活)
.map(s -> s.getName())
// 复杂逻辑用Lambda
.map(s -> {
// 复杂处理逻辑
return process(s);
})
十一、总结
通过这篇文章,我们系统地学习了Java Stream的各种操作。从最基础的filter、map,到复杂的groupingBy、reduce,再到性能优化和最佳实践。
核心要点回顾:
- Stream提供了声明式的数据处理方式,代码更简洁
- 中间操作是延迟执行的,只有终端操作才会触发执行
- 合理使用Stream可以提升代码可读性,但要注意性能
- 并行流适合大数据量的CPU密集型操作
我的建议:
- 对于新项目,优先使用Stream,代码更现代化
- 对于老项目,逐步重构,不要一次性全部改造
- 性能敏感的场景,先测试再决定是否使用Stream
- 多写多练,在实际项目中不断积累经验
最后,我想说的是,技术没有绝对的好坏,只有适合不适合。Stream虽然强大,但也不要为了用而用。在实际开发中,要根据具体情况选择最合适的方案。
作者简介:默语佬,CSDN博客专家,10年Java开发经验,专注于Java后端开发、微服务架构、性能优化等技术领域。关注我,获取更多实用技术文章。
相关文章推荐:
声明:本文所有内容均为作者原创,基于实际项目经验编写。代码示例均经过测试,可直接使用。如有错误或建议,欢迎指正。

欢迎加入北京社区
更多推荐


 23
23 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)