
从ChatGPT到AI Agent!AI Agent进化论:从提示词工程师到流程架构师的蜕变之路!
文章通过"学霸的五个成长阶段"的比喻,详细解释了AI Agent从简单API调用到复杂思考-行动-观察循环的进化过程。作者指出,Agent能力的质变不仅源于底层大模型的智力提升,更关键的是围绕模型设计的"认知流程"。文章深入分析了流程带来的三重价值:用结构为思考建立脚手架、用迭代为记忆打造压缩算法、用交互为模型连接现实世界。最后,文章从控制论和信息论角度解释了Agent有效性的科学基础,并指出开发
TL;DR & 阅读指南
这篇文章,源于我一年半的AI开发实践,也源于我离职这近两个月里和许多团队密集交流后的一个强烈感受。我发现,在讨论Agent时,我们常常陷入两种误区:一些人将其神秘化,认为它无所不能;另一些人则将其过度简化,认为它“不过是把ChatGPT多调用几次”。
因为对 agentic 循环过程的体感缺少和原理的理解,形成认知的错位,最终导致我们的沟通成本很高。
因此,我写下这篇长文,希望能为我们这些从业者,建立一个关于Agent的体感和共识基础:AI Agent能力的质变,不仅在于底层大模型日益增长的智力,更关键的,在于我们围绕模型所设计的、那一套行之有效的“认知流程”。
本文近万字,就是体感的建立和对这套“流程”的完整拆解。你可以根据这份指南,快速找到自己感兴趣的部分:
- • 第一部分 (0x01 & 0x02):建立直观理解
- • 这里,我用了一个 “学霸的五个成长阶段” 的比喻,来描述Agent核心能力的演进过程。
- • 同时,我们会分析那个被行业广泛使用的“旅行规划”案例。它就像一道“标准考题”,在对比中,我们可以清晰地看到一个动态流程与一次性生成的本质区别。
- • 第二部分 (0x03 & 0x05):面向开发者的核心
- • 0x03 是本文的技术核心。它会详细拆解“流程”带来的三重价值:如何用“结构”为思考建立脚手架,如何用“迭代”为记忆打造压缩算法,以及如何用“交互”为模型连接现实世界。
- • 0x05 探讨了我们的角色转变——从“提示词工程师”到 “Agent 流程架构师” ,并讨论了Agent的性能工程与未来的架构演进方向。
- • 第三部分 (0x04):探寻理论根基
- • 最后,如果你好奇为什么这套
思考->行动->观察的流程从根本上就是有效的,0x04 会为你揭示其背后的科学基石,它与经典的控制论和信息论有着深刻的联系。
希望这篇文章,能为我们后续的交流与协作,提供一个更坚实的起点。
0x00 如果,高考可以再来一次
这几个月,我和非常多的开发者交流AI Agent。一个普遍的困惑是,很多人都知道Agent那个抽象的 思考 -> 行动 -> 观察 循环,但却无法真正“体感”到它的威力。他们会问:
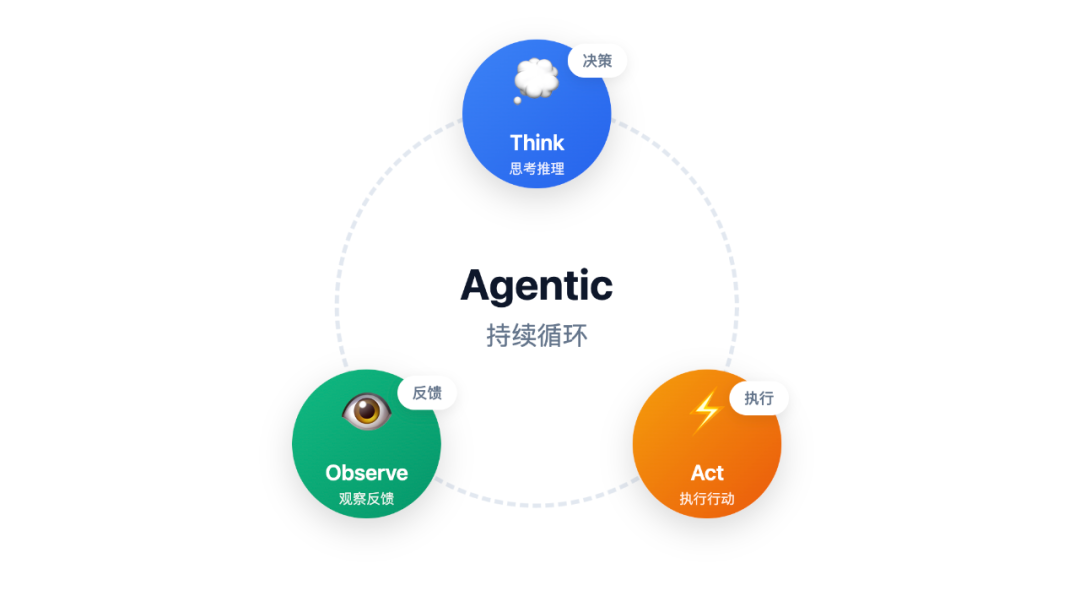
“这不就是我和ChatGPT多聊几轮吗?凭什么自动化之后就能产生质变?”
为了回答这个问题,我们不妨先回到一个大家都经历的场景。
问一个可能有些“扎心”的问题:如果时间倒流,让你在高考结束的第二天,立刻重考一次,你的分数会更高吗?
相信,许多曾为高考结果扼腕叹息的同学会立刻站起来:
- • “我考完才猛然想起,那道复杂的解析几何题,如果换个思路用‘数形结合’的方法,本可以迎刃而解。”
- • “我因为太过紧张,有道选择题,脑子里想的是B,手上却涂成了C,交卷前也没检查出来。”
- • “我当时就是时间分配不合理,最后一道物理大题的完整思路明明都在草稿纸上,却没来得及誊上答卷!”
再来一次,就凭着这些细微末节的调整,提升几十分,并非不可能。
短短一天,你那经过十二年寒窗苦读才构建的知识储备,并没有发生任何质变。这就像今天的大语言模型(LLM),它的核心知识在训练完成的那一刻就被“冻结”了,形成了一个庞大但静态的知识库。
那么,分数提升的奥秘究竟在哪?
答案,正是我们理解AI Agent的核心所在:Agent的强大,并非源于模型智力的再次飞跃,而是源于我们为其赋予的“认知流程”的巨大提升。
这套“流程”,就如同你在考场上学会的“先易后难”的时间分配策略、交卷前雷打不动的“检查”习惯、以及解不出难题时果断“换个思路”的变通能力。
而要理解这套流程是如何在AI身上一步步建立起来的,我们不妨从学霸“小明”的成长史说起。
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接👇👇

0x01 一个比喻讲清Agent核心:学霸的五个成长阶段
小明的成长,就是一部不断优化“解题流程”的进化史。
阶段一:原生天才
小明天赋异禀,脑子转得飞快。做数学题时,他极度自信,全程心算。考试时,他总是第一个把卷子“啪”地一声拍在讲台上,一脸轻松地走出教室。至于分数?别问,问就是“快不快吧!”。他确实把卷子做完了,但卷面之下,究竟有多少是因为跳步导致的计算失误,有多少是审题不清造成的方向性错误,他自己都不知道。
这完美对应了我们最开始使用大语言模型(LLM)的方式:基础API调用。我们把问题丢给它,它一次性地、黑盒般地生成一个答案。这个答案看起来很完整,甚至文采飞扬,但它究竟是如何得出的?其中有没有事实性错误?我们一无所知。这个阶段的AI,就像只追求速度的小明,交付了一个结果,却无法保证这个结果的可靠性。
阶段二:思考者
在几次因粗心丢分后,老师下达了硬性要求:所有题目,必须在草稿纸上写下详细的解题步骤。小明虽不情愿,但照做之后发现,正确率真的大幅提升了。把思考过程“外化”在纸上,让他能轻易发现逻辑链条中的微小瑕疵。
[核心概念:思维链 (Chain of Thought, CoT)]
CoT是第一个、也是最基础的结构化思考流程。它的核心作用在于,强制模型将一个复杂的、需要一步到位的“猜测式”任务,分解成了一系列简单的、线性的“推理式”子任务。它如同一个缰绳,拉住了试图“跳步”的思维野马,强迫它把注意力集中在当前这一步,利用上一步的结论,推导出下一步的结果,从而极大地降低了模型产生幻觉的概率。
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.
阶段三:细心人
小明又进步了。他不仅会打草稿,还学会了一个新技能。当他提前答完所有题目,抬头一看,发现离考试结束还有十分钟,他会启动一个全新的“心智模式”:交卷前检查。此刻,他不再是“答题者”,而是一个苛刻的“检查者”,用批判性的眼光审视自己的答案,主动寻找可能的错误并加以修正。
[核心概念:自我反思 (Self-Reflection)]
Reflexion框架的本质,是为Agent引入了一套‘先行动、再复盘、后修正’的自我迭代流程。它让Agent在完成一次任务后,先不急着输出最终结果,而是生成一段对刚才执行过程的“复盘笔记”。在下一次尝试时,这段“错题本”一样的信息会作为重要参考,被一同放进上下文中,引导Agent避免重蹈覆辙。
关键数据证明:通过这套迭代流程,Reflexion在HumanEval代码生成任务上取得了91%的准确率,超越了当时GPT-4的80%记录,无可辩驳地证明了“流程”优化的巨大杠杆效应。
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning.
阶段四:战略家
随着考试难度的提升,小明意识到,光有解题能力和细心还不够。他开始在拿到试卷的第一分钟,不再埋头做题,而是快速通览全局,在脑中形成一个作战计划:哪些题是送分题要先拿稳,哪些题是硬骨头要放到最后,并为每个部分预估时间。在答题过程中,如果发现某道题耗时超预期,他还会动态调整这个计划。
[核心概念:规划 (Planning)]
这是更高阶的宏观流程设计。在处理一个复杂任务时,具备规划能力的Agent不再是走一步看一步,而是会先将宏大目标分解成一系列逻辑清晰的子任务,形成一个计划清单。这个清单就是它行动的蓝图,确保了它的每一步都是在为最终目标服务,极大地提升了执行效率和确定性。这是大多数高级Agent框架的核心组件。
阶段五:学者
后来,小明进入了大学,开始做真正的研究。他的任务不再是解答有标准答案的考题,而是去探索一个开放性的前沿课题,比如“分析近年国内新能源汽车市场的渗透率变化趋势”。
面对这个课题,他脑中的课本知识(模型的静态权重)显然已经过时。于是,他启动了一套全新的工作模式,这正是Agent最强大的工具使用(Tool Use)能力的完美体现。而其核心,并非工具本身,而是《ReAct》框架所揭示的那套将思考与行动深度绑定的、里程碑式的工作流程:思考 -> 行动 -> 观察。
首先,他思考(Thought):“我的知识库里只有几年前的旧数据,无法直接回答这个问题。我必须获取最新的行业报告和数据。”
这个思考驱动了他采取行动(Act)。他没有凭空猜测,而是选择了一个工具——走向图书馆,打开知网和行业数据库,输入关键词进行检索。这对应Agent调用search_api("中国新能源汽车2023-2025市场渗透率报告")。
紧接着,他 观察(Observe) 到了行动的结果:几篇最新的报告和数据图表出现在屏幕上。这是他之前完全不知道的、来自外部世界的新信息,是客观事实。
最后,他带着观察到的新知,回到 再次思考(Thought) 的环节:“原来最新的数据是XX%,主要增长动力来自二线城市,并且某项技术革新是关键变量。现在,我可以基于这些事实进行分析和论证了。”
这个循环,将AI从一个封闭的“大脑”,变成了一个能与现实世界持续互动的“行动者”。它通过工具打破了自身知识的局限,用真实、即时的信息来校准和迭代自己的思考,从而将成果的质量和可靠性提升到了一个全新的高度。
至此,小明的进化之路走到了终点。他从一个只靠天赋的“原生天才”,最终成长为一位懂得规划、反思、并善用工具解决复杂问题的学者。而他一路习得的这些能力——打草稿(思维链)、复盘检查(自我反思)、谋篇布局(规划)、查阅资料(工具使用)——正是构成一个强大AI Agent的核心组件。
这,就是从Chatbot到Agent的完整进化路径。
[核心概念:工具使用 (Tool Use) 与 ReAct 框架]
ReAct框架的伟大之处,不在于工具本身,而在于它定义了一套将‘思考’和‘行动’深度绑定的交互式工作流程:
思考 -> 行动 -> 观察。这个循环,将AI从一个封闭的“大脑”,变成了一个能与现实世界持续互动的“行动者”。它通过工具打破了自身知识的局限,用真实、即时的信息来校准和迭代自己的思考,从而将成果的质量和可靠性提升到了一个全新的高度。
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models.
0x02 从“优雅的独白”到“可靠的行动”
说完了小明的进化史,我们回到那个被各家 Agent 用烂了的旅行规划例子,用刚刚建立的视角,重新审视一下,Agent 究竟强在哪。
“帮我规划一个北京周末三人游,要求包含故宫和一个适合孩子的科技馆,并给出预估的总预算。”
(是的,我知道,又是这个烂大街的旅行规划例子。我们在此也无法免俗地用它来‘公开处刑’,因为它实在太经典、太能说明问题了。)
Chatbot的答卷:一个“博学但健忘”的秘书
你向ChatGPT提出这个问题。就像最开始的那个小明,不带任何犹豫,它“噼里啪啦”就为你生成了一篇堪称完美的攻略:
**北京周末亲子探索之旅** ✈️您好!很高兴为您规划这次精彩的北京之旅。行程安排如下:**周六:历史与文化熏陶** 🏰* 上午:参观故宫博物院,感受皇家气派。建议提前在官网预订门票,票价为60元/人。* 下午:前往位于西城区的“北京儿童科技探索馆”,那里有丰富的互动展项,非常适合孩子。* 晚上:...**预算估算:** 💰* 门票:(60元/故宫 + 50元/科技馆) x 3人 = 330元* 住宿:...* 餐饮:...* **总计:约1500元**
攻略格式工整、文采飞扬、语气贴心,甚至还带上了emoji。它看起来就像任何一篇你在小红书上能刷到的旅行攻略。
然而,如果我们仔细检查这份“攻略”,就会发现它华而不实,漏洞百出:
-
- 信息过时(幻觉):它引用的故宫门票信息,可能来自其训练数据中的某个陈旧网页。它根本不知道,在旅游旺季的当下,故宫早就换了预约方式。
-
- 信息虚构(幻觉):它提到的“北京儿童科技探索馆”听起来很不错,但如果你真的去搜索,会发现这个地方根本不存在。这是模型基于“北京”、“儿童”、“科技馆”等关键词,在统计概率上“创造”出的一个最像答案的组合。
-
- 缺乏可执行性:那个“1500元”的预算,只是一个模糊的概数,你无法信任它,更无法基于它做出任何决策。
这就是Chatbot的本质:一次 “优雅的文本统计模仿”。因为它执行的是一个静态的、一次性的生成流程,它没有机制去验证、去反思、去与现实交互。
AI Agent的答卷:一个“有点刻板但极其可靠”的行动派
现在,我们把同样的任务交给一个AI Agent。你不会立刻得到一份混杂着emoji的攻略。相反,如果你能打开它的详细执行过程,你会看到一场动态的、目标导向的行动正在上演。
它会像一个真正的项目经理那样,直播它的“内心独白”与“行动”:
Think (Planning): “收到任务。第一步,制定计划:1. 验证故宫门票情况。2. 查找北京真实存在的、适合儿童的科技馆。3. 查询所有地点的确切票价和开放时间。4. 汇总精确预算。5. 生成最终方案。”
(看,这就是第一章提到的 ‘规划’流程 在启动,它为整个任务建立了宏观的执行框架。)
Think: “开始执行计划第一步:验证故宫门票。”
Act:
search_api("故宫博物院官网订票")Observe: “官网提示:本周门票已售罄。需要提前一周预约。”
Think: “计划受阻! 故宫无法前往。这与用户的核心要求冲突,必须动态调整计划(Re-planning)。新计划:1. 明确告知用户故宮门票售罄的事实。2. 继续执行原计划第二步,查找科技馆,并以此为核心规划新行程。”
(而这个关键的调整,正是 ‘反思’流程 被触发的结果,它让Agent从失败中学习。)
这个 Think -> Act -> Observe 的循环会不断持续,直到它完成计划中的所有步骤。最终,它呈现给你的报告可能不那么“文采飞扬”,但却百分之百基于事实、完全可用:
**北京周末亲子旅行规划(修订版)**您好,在为您规划行程时,我通过实时查询发现【故宫博物院本周门票已全部售罄】。因此,我为您重新规划了以科普为主题的备选方案:**核心行程:*** **地点:** 中国科学技术馆 (地址:北京市朝阳区北辰东路5号)* **票价信息:** 主展厅成人票30元/人,学生票20元/人。假设您的孩子符合学生票条件,三人门票总计为 30x2 + 20x1 = 80元。* ...(后续会基于此,继续查询交通、餐饮等,并给出精确预算)
这时候再回看,Chatbot与Agent的天壤之别已无需多言。
前者看起来很美,但你永远不敢用它上考场,因为它只是在复刻答案;后者过程虽然笨拙缓慢,但真的能做出成果,因为它是在执行一个发现答案的流程。
0x03 Agent的核心驱动:以“流程”驾驭模型之力
很多人初次接触Agent,打开它的运行日志时,会产生一种反直觉的困惑:
“怎么感觉它这么‘慢’,这么‘笨拙’?查个东西来来回回好几轮,远不如我直接问ChatGPT一秒出答案来得‘聪明’啊!”
这种“慢”,恰恰是通往Agent强大能力的第一扇门。它揭示了一个深刻的转变:我们正在从追求大语言模型(LLM)那种一次性的、直觉式的 “快思考”,转向设计一种结构化的、可验证的 “慢思考”。
而这套“慢思考”的核心,就是我们为AI设计的流程(Process)。
Agent的核心驱动力,并非源于模型自身的又一次智力爆炸,而是源于我们为它设计的这套工作流程。开发者所做的一切,本质上都是在用“更多的计算步骤”和“更长的思考时间”,去交换一个在真实商业世界里至关重要的东西——结果的“高质量”与“确定性”。
这套流程,究竟为Agent带来了什么?
第一重价值:用“结构”对抗“混沌”——为思考建立脚手架
首先,我们必须承认,LLM原生的思考方式是“发散的”、“扁平的”。它就像一个知识渊博但思维跳跃的天才,在面对一个真正复杂的任务时,它的长链条推理非常脆弱,很容易在中间某个环节“跑偏”,或者干脆“忘记”了最初的目标。
而我们设计的规划(Planning)、思维链(CoT)、甚至更复杂的树状思维(Tree of Thoughts)等流程,其本质,就是在为AI混乱的思考过程,强行建立一套“逻辑脚手架”。
- • 规划(Planning) 流程,如同建筑师手中的总设计蓝图。它在任务开始时,就将一个宏大到无法一次性思考的目标(“建一栋摩天大楼”),分解为一系列清晰、有序、可执行的步骤(“第一步:打地基;第二步:建主体;第三步:封顶……”)。它确保了AI的每一步行动都服务于最终目标,这是在“宏观”层面,用结构对抗混沌。
- • 思维链(CoT),则更像是现场工人的施工手册。它保证了每一步内部的逻辑是严谨的(“钢筋要这么绑,混凝土必须是C50标号”)。它强制AI的推理过程必须环环相扣、步步为营,这是在“微观”层面,用结构对抗混沌。
这套“脚手架”的存在,确保了AI在处理复杂问题时,不会因为思维的发散而半途坍塌。它极大地提升了AI解决复杂问题的能力上限。
第二重价值:用“迭代”对抗“遗忘”——为记忆打造压缩算法
LLM最致命的短板,莫过于它有限的“注意力”,也就是我们常说的上下文窗口(Context Window)。它就像一条记忆只有7秒的鱼,既无法一次性处理海量的信息,也记不住漫长的历史教训。
而我们设计的反思(Reflection)、总结(Summarization)等流程,本质上是在为AI的记忆,量身打造了一套“高效的压缩算法”。
让我们回到那个旅行规划的例子。当Agent通过工具查询后,得知“故宫门票售罄”时,Reflexion流程被触发了。它做了什么?
它并没有把官网返回的所有HTML代码、弹窗提示等冗长的、原始的信息,全都塞进自己本就宝贵的“记忆”里。如果是那样,它的上下文窗口很快就会被垃圾信息撑爆。
相反,这个流程启动了一次 “记忆压缩”。它将这次失败的交互过程,提炼成了一句高信息密度的结论,并将其作为一条“经验”存入记忆:
“经验:故宫门票需提前一周预订,本周不可行。”
这个过程,是一次有损但极其有效的压缩。它丢弃了99%的无关细节,却用极小的上下文空间,保留了对未来决策100%关键的信息。正是这个小小的“经验便签”,让AI在后续的规划中,能够“吃一堑,长一智”,实现真正的学习与迭代。
这套“压缩算法”,让AI拥有了动态演化的“长期记忆”,使其能够在有限的注意力范围内,处理更长的时间线,完成更复杂的任务。
第三重价值:用“交互”对抗“虚无”——为模型连接现实世界
一个流程,无论内部设计得多么精妙,如果它与现实世界完全隔离,那它就是在 “空转”。它所有的输出,都可能只是建立在模型内部“幻觉”之上的、逻辑完美的空中楼阁。
因此,流程必须拥有与世界交互的能力。在这里,我们才需要顺理成章地引入工具(Tool)。
工具不是一个与流程并列的概念。它更像是流程这条“中枢神经”末端的“神经触手”。
- •
ReAct框架之所以伟大,就在于它并非一个工具框架,而是一个将“思考”与“行动(调用工具)”深度绑定的流程。在这个流程的驱动下,AI在思考过程中如果意识到“我的内部知识不足以支撑下一步决策”,它就会主动伸出search_api()这个“触手”,去真实地“触碰”一下互联网,然后把感知到的“温度”(也就是客观事实)传回大脑,再继续下一步的思考。
这个机制,确保了我们“用时间换质量”的策略,最终能够换回 “真实的质量”,而非“高质量的幻觉”。工具,作为流程的延伸,拓宽了AI能够发挥作用的能力边界。
结论:重新定义上下文(Context)
至此,我们再回看“上下文工程”这个时髦的词,就会有全新的理解。
上下文不是需要我们去“填充”的目标,而是我们设计的卓越流程所“产出”的结果。 面对LLM有限的注意力窗口这一核心枷锁,一个好的流程,天然就是一位“上下文架构师”。它通过两大核心机制来对抗遗忘和混乱:
-
- 高效的信息压缩:如
Reflexion流程,它不会把冗长的失败日志直接塞入记忆,而是将其提炼成一句高信息密度的“经验教训”(例如:“经验:故宫门票需提前一周预订”)。这是一种有损但高效的压缩,用极低的Token成本保留了最关键的决策信息。
- 高效的信息压缩:如
-
- 精准的选择性注入:流程在每一个
Think环节之前,会像一位顶级外科手术的器械护士,精准地判断“此时此刻,LLM这个‘主刀医生’最需要哪一条历史经验?最需要哪一个工具的观察结果?”然后,它会将这些信息组合成一个干净、高效的 “数据包”,递给LLM进行处理。
- 精准的选择性注入:流程在每一个
因此,我们工作的重心,不是去“堆砌”一个越来越长的上下文,而是去设计一个能够动态构建、剪裁和管理上下文的智能流程。
我们作为开发者,正在完成一次深刻的角色转变。我们的核心工作,不再是“提示词工程师”,而是 “Agent 流程架构师”。我们的核心价值,体现在我们为AI设计的思考结构、记忆机制和世界交互的范式上。
当你不再纠结于如何写出一个能让AI惊艳四座的提示词(Prompt),而是开始为它设计一套能够自我规划、自我纠错、自我迭代的工作流时,你才真正推开了Agent时代的大门。
0x04 回归本质:Agent为何有效?
我们已经从实践的层面,解释了Agent是什么,以及它是如何工作的。但这留下了一个核心问题:为什么 思考 -> 行动 -> 观察 这个循环,从根本上就是有效的?
要回答这个问题,我们需要暂时跳出AI的范畴。其科学基础,建立在两个经典的理论之上:
- • 控制论 (Cybernetics):它解释了系统如何通过反馈来达成目标,体现了 Agent “逼近”解决方案的过程。
- • 信息论 (Information Theory):它解释了信息与不确定性的关系,体现了 Agent “探索”问题空间的过程。
控制论视角:从开环到闭环的进化
为了理解Agent的有效性,我们首先要区分两种根本不同的系统:开环系统 (Open-loop System) 与 闭环系统 (Closed-loop System)。
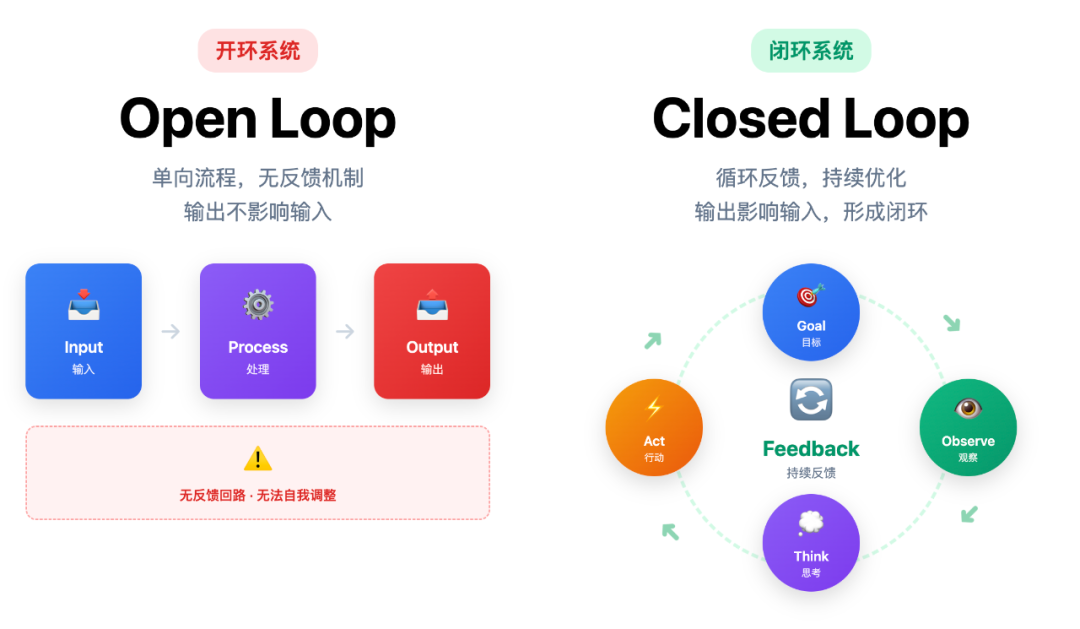
一个典型的开环系统,是那种只带定时器的老式暖气。你设定它“运行一小时”,期望它能让房间变得温暖。但它没有感知“当前室温”的能力。因此,它的行为是盲目的:
- • 如果今天恰好有太阳,一小时后房间会闷热难耐。
- • 如果恰逢寒流来袭,一小时后房间可能依然冰冷。
开环系统的根本缺陷在于缺乏反馈。它只能单向地执行指令,而对执行的结果一无所知,因此无法根据实际情况进行自我调整。这正是标准Chatbot的工作模式——它接收指令并一次性生成结果,却无法验证这个结果是否真正解决了问题。
而一个闭环系统则通过引入反馈机制,解决了这个问题。让我们来看一个经典的闭环系统范例——冰箱。
冰箱的核心任务是“维持冷藏室恒定在5°C”。它不依赖“猜测”或固定的时间表,而是运用了一套可靠的反馈机制,这正是控制论思想的体现:
-
- 目标 (Set Point):用户设定的“5°C”。
-
- 传感器 (Sensor):内部的温度计,它持续观察 (Observe) 当前的实际温度。
-
- 控制器 (Controller):温控芯片,它思考 (Think) 的唯一问题就是“当前温度和目标温度之间是否存在偏差?”
-
- 执行器 (Actuator):压缩机。一旦控制器发现偏差(比如温度上升到6°C),就会命令压缩机行动 (Act)。
-
- 反馈闭环 (Feedback Loop):压缩机工作导致温度下降,传感器将新温度反馈给控制器,控制器发现偏差消失(回到5°C),于是命令执行器停止。
现在,我们可以清晰地看到,Agent的工作流程与这个闭环系统一一对应。它本质上就是一个软件形式的闭环控制系统:
- • 目标 (Set Point):用户的指令
- • 传感器 (Sensor):
Observe环节,获取工具返回的结果 - • 控制器 (Controller):
Think环节,LLM进行推理和规划 - • 执行器 (Actuator):
Act环节,调用工具 - • 反馈闭环 (Feedback Loop):将
Observe的结果,作为输入传给下一轮Think
Observe 环节,正是这个系统的“传感器”。它的存在,是Agent实现从开环到闭环进化的关键。它赋予了Agent感知“行动结果”的能力,从而能够像冰箱一样,在动态变化的环境中,通过不断的“行动-观察-修正”循环,持续地、稳定地逼近并最终达成目标。
信息论视角:在“战争迷雾”中进行熵减
如果说控制论解释了Agent如何“逼近”一个目标,那么信息论则揭示了它在探索未知问题时究竟在“做什么”。
这里,我们需要理解一个核心概念:熵 (Entropy)。信息论将熵定义为对不确定性的度量。一个系统的信息量越大,其不确定性就越小,熵值也就越低。所有解决问题的过程,本质上都可以视为一个通过获取信息来降低不确定性(即“熵减”)的过程。
这个概念听起来可能有些抽象,但我们可以通过一个非常直观的例子来理解它——在《星际争霸》或《王者荣耀》这类游戏中驱散 “战争迷雾”。
游戏开局时,除了基地周围的狭小视野,整个地图都处于未知状态。这在信息论中被称为 “高熵”状态——系统充满了极高的不确定性。你的任务(摧毁敌方基地)是明确的,但通往任务的路径是完全未知的。
你的每一个动作,都是一个信息探索的过程:
- • 你派出一个侦察单位(Act)进入黑暗区域。
- • 这个单位的视野点亮了地图的一部分,让你看到了地形、资源或敌方踪迹(Observe)。
- • 这个“观察”的结果,就是信息。它让你对这片区域的认知,从“完全不确定”变成了“确定”。
这个“用信息消除不确定性”的过程,就是 “熵减”。信息论的奠基人克劳德·香农(Claude Shannon)为“信息熵”给出了数学定义:

这个公式的数学细节无需深究,但其核心思想至关重要:一个系统的可能性越多、越平均,其不确定性(熵)就越高。而获取信息的价值,就在于它可以排除掉一些可能性,从而降低系统的总熵。
Agent的工作,正是在一个抽象的“问题空间”中,进行着一场严谨的熵减行动。它的每一次 Act-Observe 循环,都是一次科学实验,目的就是为了获取能最大程度降低问题不确定性的信息。当不确定性被完全消除,通往答案的唯一路径也就清晰地浮现出来。
综上所述,Agent的有效性并非偶然。控制论为它提供了目标导向的纠错能力,确保它在复杂的执行路径中“不跑偏”;而信息论则定义了它探索未知空间的核心任务——通过行动获取信息,系统性地消除不确定性。
这两个理论共同为Agent框架的可靠性与有效性,提供了坚实的科学基石。
0x05 结论:你的新角色——从“提示词工程师”到“Agent 流程架构师”
至此,我们从一个“高考重考”的遗憾出发,跟随“学霸小明”的脚步,见证了解题流程的步步演进;在“旅行规划”的强烈对比中,我们亲身体会了动态流程与静态生成的本质区别;我们深入解构了流程作为核心驱动力的三重价值——以结构对抗混沌,以迭代对抗遗忘,以交互对抗虚无;最后,我们从控制论和信息论的视角,找到了这套流程有效性的科学基石。
结论,已不言自明——LLM 应用的未来,其竞争力的核心,已不再是模型本身的参数大小或某个提示词的精巧,而是我们围绕模型所设计的那套智能流程的优劣。
这不仅仅是认知上的转变,更是一次深刻的职业角色进化。
定义你的新角色:Agent 流程架构师
“提示词工程师(Prompt Engineer)”这个短暂的、在LLM蛮荒时代应运而生的角色,正迅速成为历史。当行业跨越了“与AI巧妙对话”的浅滩,我们开发者真正的战场早已转移。我们的工作,不再是“对话者”,而是“系统设计者”。
欢迎来到你的新角色:Agent 流程架构师 (Intelligent Process Architect)。
这个角色的核心职责,不再是雕琢语言,而是构建系统。具体来说,包含三大核心:
-
- 设计AI的思考流程 (Cognitive Workflow)
你将定义AI如何进行规划、拆解、推理与反思。你设计的不是一个提示词,而是AI的“心智内核”与“行事准则”。
- 设计AI的思考流程 (Cognitive Workflow)
-
- 赋能AI的行动工具 (Toolbox)
你将为AI锻造与物理世界和数字世界交互的“双手双脚”。你需要敏锐地识别流程中的信息瓶颈,并创造或接入合适的工具,让AI的能力边界得以延伸。
- 赋能AI的行动工具 (Toolbox)
-
- 构建AI的决策上下文 (Context Architecture)
你不再是上下文的“搬运工”,而是“建筑师”。优秀的流程天然就是上下文管理的大师。你将通过精妙的流程设计,确保在每一个决策瞬间,AI的“注意力”不多不少,恰好聚焦在最有价值的信息上。
- 构建AI的决策上下文 (Context Architecture)
踏入Agent时代的门槛:从实现“心跳”到构建“大脑”
我们正在迈向一个激动人心的未来:我们创造的,将不再是“回答问题的机器”,而是“解决问题的伙伴”。
但在此之前,我们必须建立一个至关重要的认知:今天我们所熟知的 Think -Act -Observe 循环,并非 Agent 设计的终点。它更像是 Agent 的 “心跳”——那个维持智能体与世界进行交互的、最基础、最核心的原子节律 (Agentic Loop)。
我们作为架构师的核心工作,不是去替换这个心跳,而是要为这个心跳设计一个强大的 “大脑”与“神经系统”。然而,这套强大的“慢思考”流程在提升结果质量的同时,也带来了新的、不可回避的工程挑战——执行效率。
我们如何化解这种“慢”带来的延迟,让Agent在追求高质量的同时,也能拥有高性能?这正是“Agent 流程架构师”必须面对的第一个现实课题:Agent的性能工程。前沿的工程实践正从以下几个关键层面寻求突破:
- • 架构选型与剪枝 (Architectural Pruning): 并非所有任务都需要复杂的
ReAct循环。业界发现,对于能通过一两步直接解决问题的场景,使用LLM内置的工具调用 (Tool-Calling) 范式会更高效。 这类Agent省去了显式的“思考”文本生成环节,直接输出结构化的函数调用指令,显著降低了token消耗和端到端延迟,是架构师在设计流程时进行的第一层性能优化。 - • 并行化执行 (Parallel Execution): 这是最显著的提速手段。当Agent的规划结果中包含多个没有依赖关系的子任务时(例如,“查询北京的天气”和“搜索热门饭店”),现代Agent框架如LangChain已经支持并行工具调用 (Parallel Tool Calling)。 它利用异步I/O (
asyncio) 的能力,将原本需要串行等待的多个API请求并发出去,从而将总耗时从“所有任务耗时之和”缩短为“最长任务的耗时”,极大地提升了执行效率。 - • 模型特化与路由 (Model Specialization & Routing): “一招鲜,吃遍天”的单一模型策略正在被淘汰。更优的实践是采用混合模型策略。例如,使用一个轻量、高速的模型(如gemini-2.5-flash, claude-haiku-4.5)来承担流程中“规划”、“路由”或简单工具选择等高频、低复杂度的任务,仅在遇到需要深度推理的复杂节点时,才调用重量级、高成本的核心模型(如gpt-5-pro, gemini-2.5-pro)。这种分层策略能以更低的成本和延迟,完成大部分流程步骤。
- • 高效的记忆架构 (Efficient Memory Architecture): Agent的性能瓶颈,往往出现在它与记忆的交互上。LLM有限的上下文窗口决定了我们不可能将所有历史信息塞入提示。因此,设计一个高效的 “记忆检索”机制至关重要。这不仅仅是技术选型(如使用向量数据库),更是策略设计:如何将对话历史、过往的行动轨迹、成功的经验与失败的教训进行 压缩、提炼并结构化存储。一个优秀的记忆架构,就像一位顶级图书管理员,能在Agent需要时,精准、快速地从海量信息中提取出 “此时此刻最需要的那一条知识”,并以最低的Token成本注入上下文。这直接决定了Agent能否快速做出正确决策,避免在冗余信息中迷失方向,从而在根本上提升其运行效率与智能水平。
当我们通过精良的工程实践,为Agent的‘心跳’装上了‘加速器’之后,我们才能真正着手去构建那个更宏观、更智能的 “大脑”——一套能够驾驭这个心跳的认知架构 (Cognitive Architecture)。
满足于实现一个基础循环,就像满足于让一颗心脏跳动,却没给它构建一个能思考、能协作的躯体。真正的价值创造,发生在这些基础节律之上。当前,业界最前沿的探索,正聚焦于以下几个方向:
1. 认知调度中心:智能工作流编排 (Intelligent Workflow Orchestration)
一个成熟的 Agent,应当像一位经验丰富的项目经理,面对不同的任务,能自主地规划并编排最优的执行流程。这正是“动态流程编排”的核心思想,而 Anthropic 最新发布的 “Skills” 功能,是这一思想的最佳行业实践。它允许开发者定义一套丰富的“技能”(即工具集),模型则能自主理解用户的宏观意图,并像一个指挥家一样,智能地选择、组合并依次调用多个“技能”以协作完成复杂目标。这代表着 Agent 的思考环节,已从“下一步做什么”的战术决策,进化为“如何分步达成最终目标”的战略规划。
2. 从“单兵”到“团队”:规约驱动的分层架构 (Spec-Driven)
对于超越单体 Agent 能力的复杂任务,分层与分治是必然选择。其关键在于如何保证团队高效、可靠地协作。答案正在从“即兴的角色扮演”走向更严肃的工程范式——“规约驱动”。在这种架构下,一个“规划Agent”的首要任务是生成一份详尽、明确的技术规约 (Specification),它如同工程蓝图,成为所有下游“执行Agent”工作的唯一契约。这正是以 AI IDE Kiro、GitHub 开源的 SpecKit 等为代表的前沿项目所探索的核心思想,它标志着 Agent 协同正在进化为可追溯、可验证的“现代软件工程”。
3. 从“使用工具”到“创造工具”:即时代码生成 (On-the-fly Code Generation)
传统工具使用是让 Agent 在固定的工具箱里做选择题。未来的方向是,让 Agent 自己创造工具。CodeAct (CodeAct: A Multi-Turn Code Agent with In-Context Learning) 等研究正在引领这一趋势。当面对没有现成工具可用的问题时,这类 Agent 会动态地生成一段 Python 代码(一个微型工具),在隔离环境中执行它,并根据执行结果推进任务。这让 Act 环节从简单的“API调用”,进化为具备无限可能的“代码生成与执行”,从而实现了 Agent 能力边界的动态扩展。
这些,才是“Agent 流程架构师”未来几年最激动人心的工作。我们不再是基础“心跳”的实现者,而是这些高级认知架构的“创造者”。
所以,从今天起,忘掉提示词的奇技淫巧。去为你手头的任务,画出第一张流程图吧。这,就是成为一名Agent 流程架构师的开始。
参考与延伸阅读资源库
Part 1: 核心学术论文
-
- 思维链 (Chain of Thought, CoT)
- • 标题: Chain-of-Thought PromptingElicitsReasoning in Large Language Models
- • 链接:
https://arxiv.org/abs/2201.11903 - • 简介: 首次系统性地证明,通过在提示中加入“思考过程”的范例,可以激发大语言模型解决复杂推理任务的能力,是结构化提示的奠基性工作。
-
- 思维树 (Tree of Thoughts, ToT)
- • 标题: Tree of Thoughts:DeliberateProblem Solving with Large Language Models
- • 链接:
https://arxiv.org/abs/2305.10601 - • 简介: 将线性的思维链扩展为树状的多路径探索。它允许 Agent 在一个思考节点上探索多个不同的推理路径,并使用自我评估来决定最优解,是更强大的结构化思考流程。
-
- Reflexion框架
- • 标题: Reflexion: Language Agents withVerbalReinforcementLearning
- • 链接:
https://arxiv.org/abs/2303.11366 - • 简介: 首次将“自我反思/复盘”这一概念框架化、自动化。它证明了 Agent 可以通过对过往失败进行“语言反思”来迭代优化自身行为,而无需重新训练模型。
-
- ReAct框架
- • 标题: ReAct:SynergizingReasoning and Acting in Language Models
- • 链接:
https://arxiv.org/abs/2210.03629 - • 简介: 提出了里程碑式的
Thought -> Act -> Observe框架,将“思考”(Reasoning)和“行动”(Acting)深度交织,是现代 Agent 框架与外部世界交互的理论基石。
-
- CodeAct 框架
- • 标题: CodeAct: A Multi-Turn Code Agent with In-Context Learning
- • 链接:
https://arxiv.org/abs/2402.01030 - • 简介: 雄辩地证明了 Agent 的
Act环节可以从“调用预定义工具”进化到“即时生成代码并执行”,极大地扩展了 Agent 的能力边界。
Part 2: 行业资料与实践资源
-
- 奠基性的综述:Lilian Weng的《LLM-poweredAutonomousAgents》
- • 链接:
https://lilianweng.github.io/posts/2023-06-23-agent/ - • 简介: OpenAI 应用研究负责人撰写的、行业内引用最广泛的 Agent 综述文章,是建立该领域全局认知地图的第一站。
-
- 核心思想:“LLM操作系统” by Andrej Karpathy
- • 简介: Andrej Karpathy (OpenAI创始成员) 在多个演讲中极具前瞻性地提出,LLM 是新型计算范式的“CPU”,而 Agent 框架则扮演了“操作系统(OS)”的角色。
-
- 主流开发框架:LangGraph & LlamaIndex
- • 链接:
https://www.langchain.com/langgraph和https://www.llamaindex.ai/ - • 简介: 当下构建 Agent 应用的两大事实标准库。LangGraph 侧重于流程(Chain & Agent),LlamaIndex 侧重于数据(RAG),是开发者将理论付诸实践的首选工具。
前沿架构探索
-
- 规约驱动的协同 (Specification-DrivenCollaboration)
- • 简介: 解决多 Agent 协作的核心,在于建立一套机器可读的“契约”或“规约”(Specification)。这一方向的代表性项目包括 AI IDE Kiro (
https://kiro.dev/) 和开源工具包 SpecKit (https://github.com/braid-work/spec-kit)。
-
- 复杂工具的智能编排 (Intelligent ToolOrchestration)
- • 简介: 强大的 Agent 应能为达成一个复杂目标,自主地、多步骤地规划并调用一系列工具。Anthropic 的 “Skills” 功能 (
https://www.anthropic.com/news/skills) 将 Agent 的工具使用能力从“单次调用”提升到了“智能编排”,是这一方向的最佳行业实践。
-
- 社会行为涌现:斯坦福的“西部世界小镇” (Generative Agents)
- • 论文: GenerativeAgents:InteractiveSimulacraof HumanBehavior (
https://arxiv.org/abs/2304.03442) - • 简介: 一项现象级的 AI 实验,展示了当 Agent 拥有了记忆和反思能力后,在一个虚拟社会中能够涌现出多么可信的自发行为,是多 Agent 系统探索的绝佳延伸阅读。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接👇👇
为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
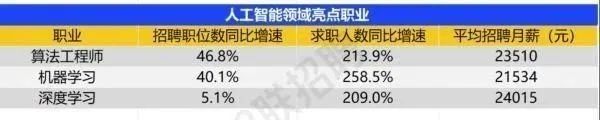
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐
 30
30 0
0- 0



 已为社区贡献318条内容
已为社区贡献318条内容

所有评论(0)