
【LLM项目教程】4小时$100打造你的ChatGPT:Karpathy开源nanochat全栈!
Andrej Karpathy推出开源项目nanochat,提供精简代码库帮助用户从零开始全栈实现LLM。运行单一脚本即可完成标记化、预训练、微调等全流程,成本仅100美元,4小时训练出类似ChatGPT的模型,12小时可超越GPT-2性能。项目包含详细教程和评估系统,通过简单UI提供Web服务,适合学习大模型构建全流程。
师从李飞飞、OpenAI 创始人员、特斯拉人工智能和自动驾驶部门总监,被时代杂志评为 AI 领域 100 位最具影响力人物之一……
兼具这些头衔于一身的大神 Andrej Karpathy 又出大招了,推出了全新开源项目 nanochat 。
nanochat 基于一个精简、易于修改且依赖性低的代码库,用于从零开始、全栈实现自己的 LLM 。
只需要运行一个脚本就能实现整个流程,包括标记化、预训练、微调、评估、推理以及通过简单的 UI 进行 Web 服务。
等待 4 小时后,你就可以得到一款属于自己的 ChatGPT ,整个过程成本低至 100 美元。如果把训练时长增加到 12 个小时,它的性能可超越 GPT-2。

评论区除了一片溢美之词,
也引发了热烈的讨论。
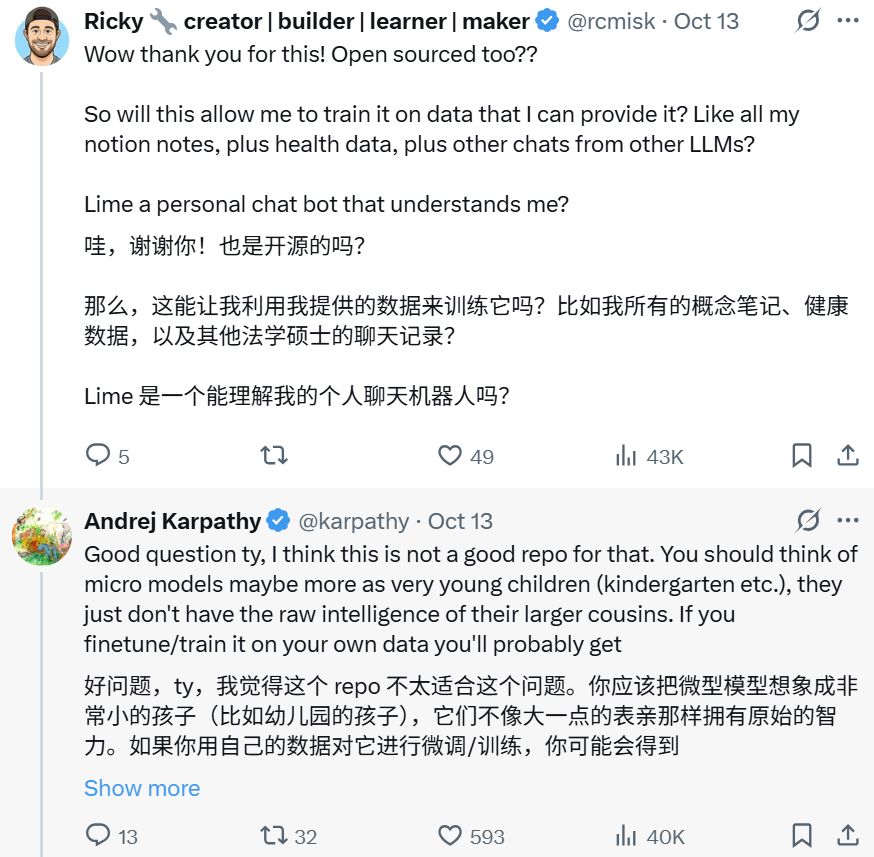
短短两天内就在 GitHub 上斩获 14.9k 星标。
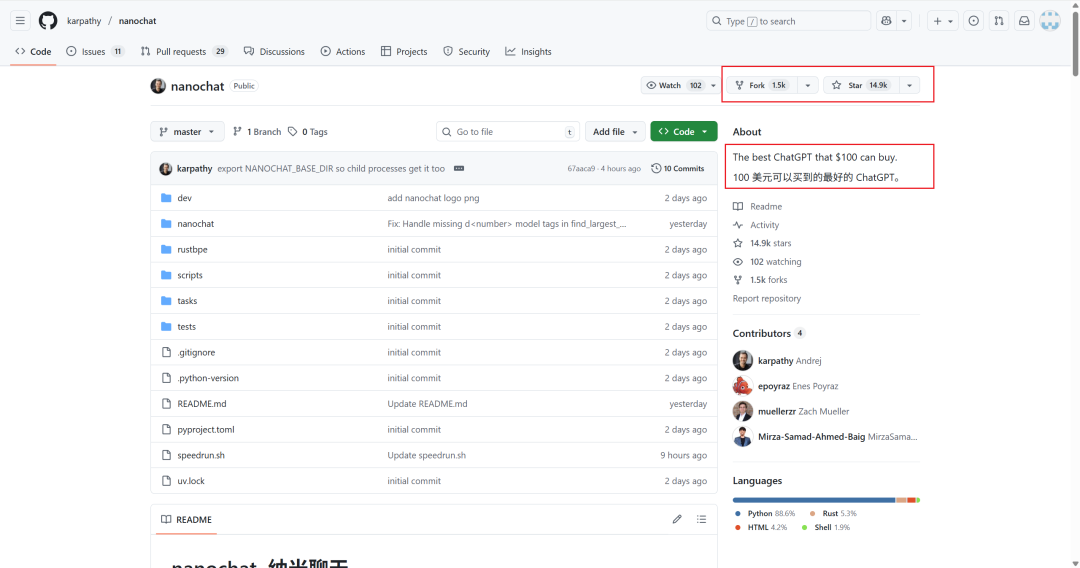
GitHub 指路:
https://github.com/karpathy/nanochat
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

一、项目介绍
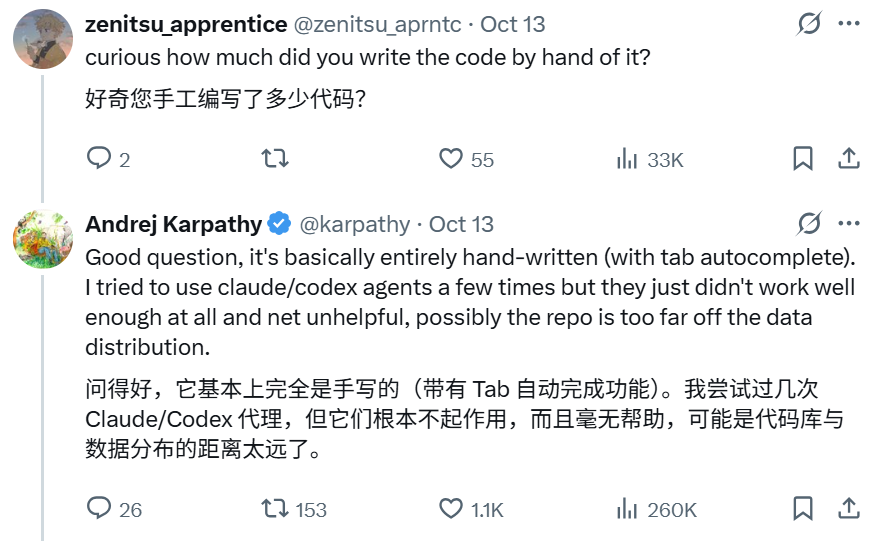
项目共有约 8k 行代码。
有人好奇其中多少是 Andrej Karpathy 自己写的。答案如下:
项目结构主要包括:
- 训练前处理
- 预训练:在 FineWeb 数据集上预训练 Transformer LLM,并通过多项指标评估 CORE 得分。
- 中期训练:使用 SmolTalk 数据集。
- 监督微调:在世界知识多项选择题(ARC-Easy / ARC-Challenge、MMLU)、数学题(GSM8K)、编程题(HumanEval)任务上评估模型。
- 强化学习:在 GSM8K 上通过 GRPO 算法进一步优化模型性能。该阶段可选。
- 推理引擎:在带有 KV 缓存的引擎中高效推理模型,用户可通过命令行或 ChatGPT 风格网页界面与模型交互。
- 生成一份 Markdown 格式报告,总结模型性能表现。
对于这个只用了 100 刀、4 小时的模型的表现,Andrej Karpathy 温馨提示:
这个轻量级、快速生成的 AI 模型计算能力只有 4e19 ,所以有点像和幼儿园小朋友对话 😃。
同时他也指出:
如果将训练时长增加至 12 小时,模型的表现可以超过 GPT-2 CORE 基准。如果预算能到 1000 刀(训练约 41.6 小时),模型将具备更高连贯性,能解决简单的数学与编程问题,并回答多项选择题。
二、Andrej Karpathy的故事
在详细讲解代码之前,我们先来了解一下作者 Andrej Karpathy 的故事。

他于 1986 年出生于斯洛伐克,15 岁时随家人移居多伦多。
大学本科期间开始在 YouTube 上发布发布魔方教程而声名鹊起。这些教程曾被 Feliks Zemdegs 等世界顶尖速解魔方选手使用。
https://www.youtube.com/@badmephisto
2009 年,他在多伦多大学获得计算机科学和物理学学士学位,2011 年在英属哥伦比亚大学获得硕士学位,在导师 Michiel van de Panne 的指导下,研究人体的物理模拟。
2015 年在李飞飞的指导下获得斯坦福大学博士学位,主要研究自然语言处理和计算机视觉的交叉领域,以及适合该任务的深度学习模型。
有些小伙伴可能看过他上的网课。他在博士期间担任了斯坦福大学 CS231n(卷积神经网络与视觉识别)课程的主要讲师之一。
这门课从斯坦福一路火到 B 站,成了 CV 领域的经典课程。我本科的时候也看过。
博士毕业后,Karpathy 进入 OpenAI ,是其创始人员之一。

2017 年 6 月,他成为特斯拉的人工智能总监,直接向老马汇报工作。
2023 年,重新加入 OpenAI 。
目前已经出来创业:Eureka Labs ,做 AI + 教育方向。

我们现在耳熟能详的 vibe coding 这个词,也是今年 2 月他提出来的。
三、项目流程详解
接下来,我们一起更加深入了解这个项目的流程。
首先是一些依赖的搭建和工具的编译。比如安装 uv ,创建虚拟环境,安装 Rust/Cargo ,编译分词器等。
# install uv (if not already installed)command -v uv &> /dev/null || curl -LsSf https://astral.sh/uv/install.sh | sh# create a .venv local virtual environment (if it doesn't exist)[ -d ".venv" ] || uv venv# install the repo dependenciesuv sync# activate venv so that `python` uses the project's venv instead of system pythonsource .venv/bin/activate
``````plaintext
# Install Rust / Cargocurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -ysource "$HOME/.cargo/env"# Build the rustbpe Tokenizeruv run maturin develop --release --manifest-path rustbpe/Cargo.toml
训练 tokenizer
预训练数据就是大量网页的文本,使用 FineWeb-EDU 数据集。

不需要通过huggingface 的 datasets.load_dataset(), Andrej Karpathy 将整个数据集重新打包成简单的、完全混洗过的分片,以便轻松访问。
https://huggingface.co/datasets/karpathy/fineweb-edu-100b-shuffle
下载所有数据需要的内存约在 24GB 左右,默认保存在 ~/.cache/nanochat 中。
python -m nanochat.dataset -n 240
接着训练分词器,它可以在字符串和来自代码本的符号序列之间来回转换。
训练集为 20 亿个字符,只需约 1 分钟即可完成。训练算法与 OpenAI 使用的算法相同(正则表达式拆分,字节级 BPE)。
python -m scripts.tok_train --max_chars=2000000000python -m scripts.tok_eval
还可以对分词器进行评估。
和 GPT-4 相比:
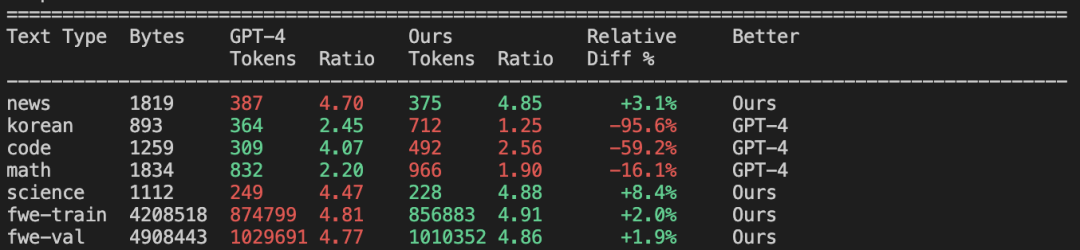
整体效果一般,毕竟 GPT-4 的词汇量要大得多(100277)。但在代码和数学方面二者同样出色
预训练
训练 LLM 通过预测序列中的下一个 token 来压缩网络文本,同时也让它从中获取大量关于世界的知识。
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=20
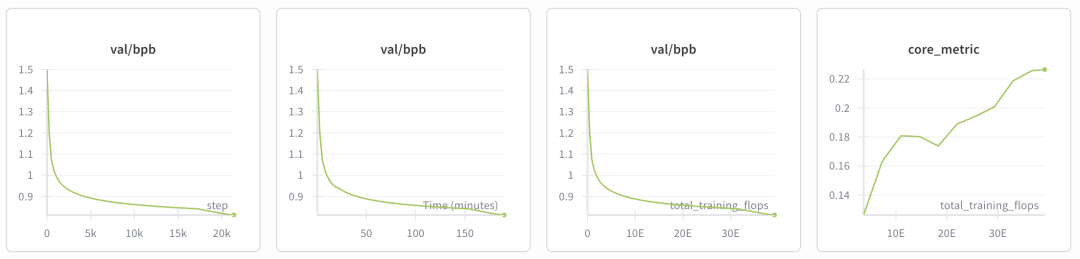
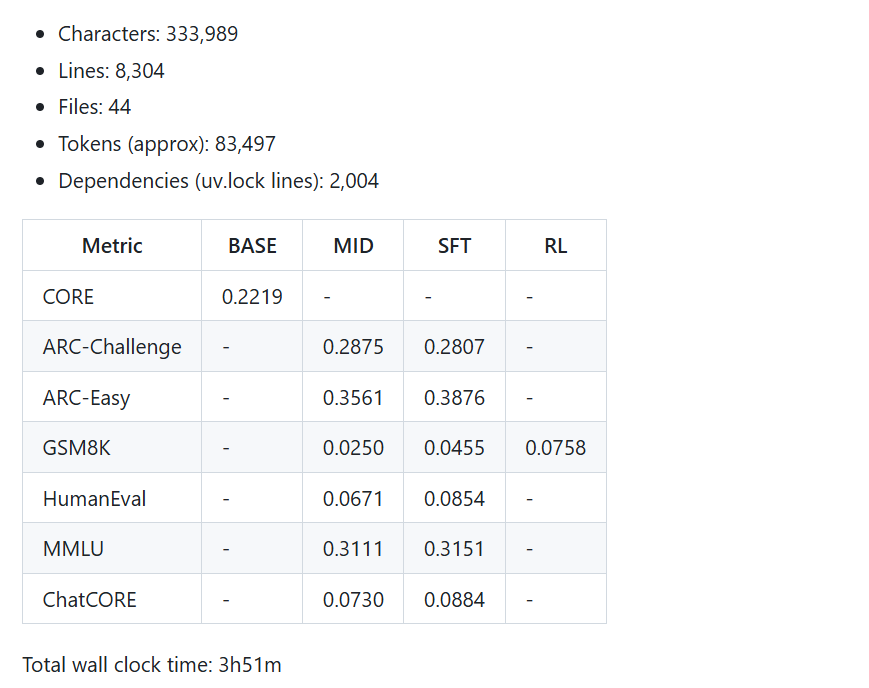
大约等 3 个小时,就可以在 wandb 图中看到:训练/验证的每字节比特数 (bpb) 达到了约 0.81,核心指标也上升到了 0.22。
Midtraining
中期训练将进一步在 smol-SmolTalk 上对模型进行微调。
所有算法都与预训练相同,但数据集现在变成了对话,并且模型会自行适应新的特殊标记,这些标记现在构成了多轮对话对象。
每个对话看起来都像这样,大致遵循 OpenAI Harmony 聊天格式 :
<|bos|><|user_start|>What is the color of the sky?<|user_end|><|assistant_start|>Red. Wait, possibly blue. I'm not sure.<|assistant_end|><|user_start|>lol<|user_end|><|assistant_start|>...etcetc
接着运行:
torchrun --standalone --nproc_per_node=8 -m scripts.mid_traintorchrun --standalone --nproc_per_node=8 -m scripts.chat_eval -- -i mid
这个阶段训练评估得到的结果如下:
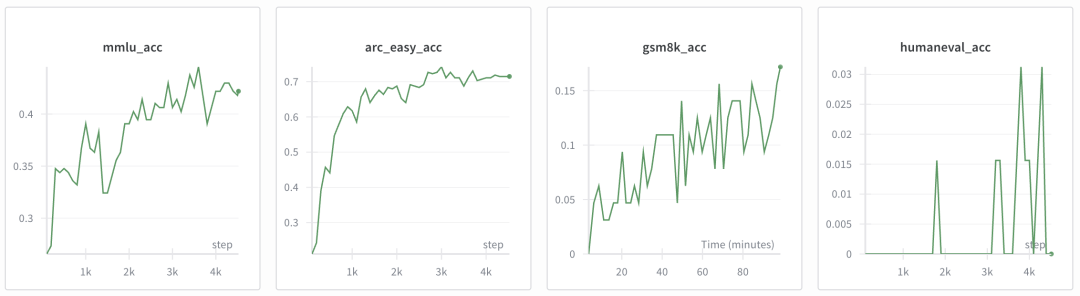
- ARC-Easy: 0.3561
- ARC-Challenge: 0.2875
- MMLU: 0.3111
- GSM8K: 0.0250
- HumanEval: 0.0671
- ChatCORE metric: 0.0730
监督微调
监督微调通常是挑选最优质的数据对对话数据进行又一轮微调。
运行 SFT 并重新评估:
torchrun --standalone --nproc_per_node=8 -m scripts.chat_sfttorchrun --standalone --nproc_per_node=8 -m scripts.chat_eval -- -i sft
得到的指标略有上升:
- ARC-Easy: 0.3876
- ARC-Challenge: 0.2807
- MMLU: 0.3151
- GSM8K: 0.0455
- HumanEval: 0.0854
- ChatCORE metric: 0.0884
接下来就可以和模型对话了。
python -m scripts.chat_clipython -m scripts.chat_web
生成报告
最后,它以 markdown 的形式自动生成一份报告并进行总结。
一起来看看这份价值 100 刀的“成绩单:
四、快速上手
正如前面提到的,只需要运行一个脚本即可实现,整个过程操作如下:
从你最喜欢的供应商(例如,Andrej Karpathy 使用的是 Lambda )启动一个新的 8XH100 GPU ,然后启动训练脚本:
bash speedrun.sh
由于脚本运行了 4 个小时,可以启动一个新的对话,将输出记录到 speedrun.log :
screen -L -Logfile speedrun.log -S speedrun bash speedrun.sh
等待 4 小时,完成后,确保本地 uv 虚拟环境已经激活(运行 source .venv/bin/activate )。
通过类似 ChatGPT 的 Web UI 与 LLM 对话。
python -m scripts.chat_web
然后访问显示的 URL。
确保访问方式正确,例如在 Lambda 上使用所在节点的公网 IP,后接端口,例如 http://209.20.xxx.xxx:8000/ 等。
简单测试:
python -m pytest tests/test_rustbpe.py -v -s
Karpathy 指出 nanochat 目前还远未完成。
未来的目标是提升微型模型的先进水平,使其能够在不到 1000 美元的预算内实现端到端的运行。
最后,虽然这不是什么颠覆性的技术突破,但是拿来学习一波也是受益匪浅。
五、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 9
9 0
0- 0



 已为社区贡献227条内容
已为社区贡献227条内容

所有评论(0)