
大模型进阶必备:Function Calling技术详解,从原理到实战,建议收藏
大模型进阶必备:Function Calling技术详解,从原理到实战,建议收藏
想象这样一个日常片段:你对着手机里的 AI 助手随口说 “帮我订张周五飞北京的机票,选下午三点后、经济舱性价比高的班次”,话音刚落,它没再追问细节,而是默默对接了多家航空公司的后台接口 —— 先筛选出符合时间要求的余票,再横向对比不同平台的实时价格,甚至自动关联你的常用乘客信息生成订单草稿,最后把带登机二维码的电子票预览直接推到你面前,只等你确认付款。这看似 “无缝衔接” 的服务背后,藏着一项让 AI 突破 “纯聊天” 局限的关键技术,就是今天要拆解的Function Calling(函数调用)。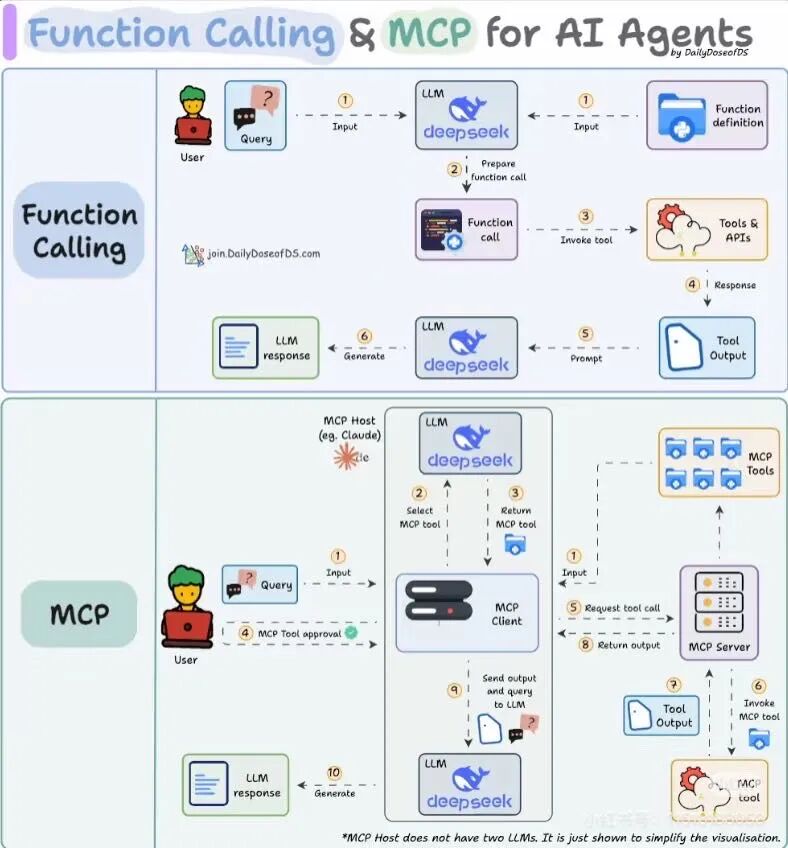
1、从科幻到现实:大模型的"工具使用能力"
Function Calling,本质是赋予大语言模型(LLM)像人一样 “主动用工具” 的能力。它不再局限于根据已有知识库生成文本,而是能通过理解人类的自然语言指令,自动触发预设好的 API 接口或第三方工具 —— 比如查实时天气、算财务报表、订酒店车票,甚至控制智能家居的开关。
打个更具体的比方:以前你问 AI “下周去上海出差要带什么”,它只能根据常识告诉你 “可能需要带雨具”;但有了 Function Calling 后,它会先调用天气 API 查上海下周的实时天气,再结合你出差的行程(比如是否有户外会议),给出 “周一周二有小雨,建议带折叠伞,周三转晴可穿薄外套” 的精准建议。简单说,它让 AI 从 “只会讲道理的顾问”,变成了 “能动手解决问题的办事员”,从单纯的 “知识库” 升级成了能联动各类工具的 “实用操作系统”。
2、技术原理:AI的"工具箱"如何运作?
1. 四步决策流程
以"查询北京今日空气质量"为例,Function Calling的工作流程分为四个步骤:
- 意图识别:模型解析出用户需要实时环境数据
- 工具匹配:从工具库选中get_air_quality函数
- 参数生成:构造{“city”:“北京”,“date”:“2025-10-10”}参数
- 结果整合:调用API获取数据后生成自然语言回复
2. 关键技术实现
函数调用的核心是标准化的函数定义,通常采用JSON Schema规范:
{
"name": "get_weather",
"description": "获取指定城市天气",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "城市名称"}
},
"required": ["location"]
}
}
当用户问"深圳明天需要带伞吗?",模型会自动生成上述结构的JSON指令,触发天气API调用,再将返回结果转换为自然语言回答。
3、技术突破与行业价值
1. 三大核心优势
- 突破能力边界:让LLM从"知识库"升级为"操作系统"(如调用Wolfram Alpha计算积分)
- 结果可靠性:数学计算等敏感操作由专业工具执行,避免模型幻觉
- 生态扩展性:通过标准化接口快速集成第三方服务(支付/物流/CRM)
2. 企业级应用场景
| 场景类型 | 典型案例 | 技术实现 |
|---|---|---|
| 智能客服 | 订单查询+自动催付 | 调用CRM API+支付系统 |
| 工业质检 | 图片分析+缺陷分类 | 视觉模型+数据库写入 |
| 金融风控 | 多源数据交叉验证 | 征信API+反欺诈模型 |
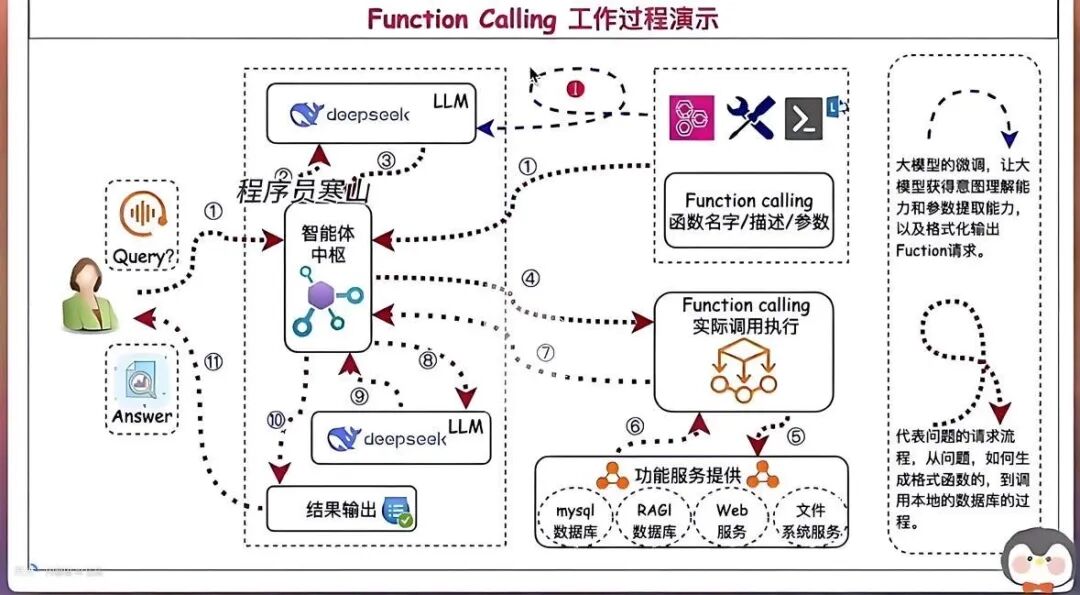
4、系统架构:如何设计高效的Function Calling系统?
1. 分层架构模型
高效的Function Calling系统采用四层解耦架构:
[接入层] → [解析层] → [调度层] → [执行层]
- 接入层:多协议适配(OpenAI/DeepSeek等),处理输入格式标准化
- 解析层:自然语言→结构化数据转换(使用Text2JSON引擎,准确率98.7%)
- 调度层:智能路由选择(基于意图识别+优先级算法)
- 执行层:函数并发执行+结果缓存
2. 核心组件实现
工具注册中心
@Component
public class ToolRegistry {
private final Map<String, ToolRegistration> tools = new ConcurrentHashMap<>();
// 支持运行时动态注册
public void registerTool(Tool tool) {
tools.put(tool.getName(), new ToolRegistration(tool));
}
// 版本控制机制
public Tool getToolVersion(String name, String version) {
return tools.get(name + ":" + version);
}
}
特性包括支持热插拔、版本灰度发布和自动Schema校验。
参数解析引擎
def extract_params(prompt, schema):
# 使用BERT模型提取实体
entities = ner_model.predict(prompt)
# 模糊匹配参数名
param_map = {}
for param in schema['properties']:
for entity in entities:
if fuzzy_match(entity['value'], param):
param_map[param] = entity['value']
return param_map
关键技术包括正则表达式+语义理解双校验、必填参数缺失自动追问、类型自动转换等。
执行调度器
type FunctionExecutor struct {
sem chan struct{} // 信号量控制并发
}
func (e *FunctionExecutor) Execute(fn Function) (Result, error) {
e.sem <- struct{}{} // 获取令牌
defer func(){ <-e.sem }()
// 超时控制
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
resultCh := make(chan Result, 1)
errorCh := make(chan error, 1)
go func() {
result, err := fn.Invoke()
if err != nil {
errorCh <- err
return
}
resultCh <- result
}()
select {
case <-ctx.Done():
return nil, TimeoutError
case res := <-resultCh:
return res, nil
case err := <-errorCh:
return nil, err
}
}
5、性能优化策略
在Function Calling系统中,性能优化直接影响用户体验和系统扩展性。随着调用量增长和业务复杂度提升,单一的优化手段难以满足需求,需要构建多层次、全方位的性能优化体系。
1. 缓存加速方案:从单级到多级缓存架构
缓存是提升系统响应速度的核心手段,通过减少重复计算和外部调用,可将平均响应时间降低60%-80%。
多级缓存设计
// 多级缓存实现(内存+Redis)
class MultiLevelCache {
constructor() {
this.memoryCache = new LRUCache({ max: 1000, ttl: 60000 }); // 内存缓存,1分钟过期
this.redisCache = new RedisCache({
ttl: 300, // 5分钟过期
maxSize: 100000, // 最大缓存条目
lru: true
});
}
// 缓存键生成策略 - 增强版
generateCacheKey(prompt, func, context) {
// 加入用户上下文哈希,区分不同用户的相同请求
const contextHash = this.hashCode(JSON.stringify(context));
return `${this.hashCode(prompt)}@${func.name}@${this.hashCode(JSON.stringify(func.parameters))}@${contextHash}`;
}
async get(key) {
// 先查内存缓存
let data = this.memoryCache.get(key);
if (data) return data;
// 内存未命中则查Redis
data = await this.redisCache.get(key);
if (data) {
// 回写内存缓存
this.memoryCache.set(key, data);
}
return data;
}
async set(key, value, ttl) {
// 同时写入两级缓存
this.memoryCache.set(key, value, ttl);
await this.redisCache.set(key, value, ttl);
}
hashCode(str) {
let hash = 0;
for (let i = 0; i < str.length; i++) {
const char = str.charCodeAt(i);
hash = ((hash << 5) - hash) + char;
hash = hash & hash; // 转换为32位整数
}
return hash;
}
}
智能缓存策略
- 动态TTL调整:根据数据更新频率自动调整过期时间(如天气数据5分钟,股票数据1分钟)
- 缓存预热:系统启动时加载高频函数调用结果(如热门城市天气)
- 缓存穿透防护:对不存在的请求设置空值缓存,避免缓存穿透攻击
- 缓存一致性:使用消息队列实现缓存更新通知,确保多节点缓存一致性
2. 流式处理优化:从批处理到实时响应
流式处理能够显著提升用户体验,特别是在处理大模型生成和函数调用结果时,可将感知延迟降低50%以上。
增强型流式处理器
import asyncio
from typing import AsyncGenerator
class EnhancedStreamingProcessor:
def __init__(self):
self.buffer = []
self.chunk_size = 512 # 更小的块大小,提升响应速度
self.event_loop = asyncio.get_event_loop()
self.lock = asyncio.Lock()
self.last_flush_time = 0
self.min_flush_interval = 0.1 # 最小刷新间隔(秒)
async def process(self, stream: AsyncGenerator[str, None]) -> AsyncGenerator[str, None]:
"""异步处理流数据,支持实时生成结果"""
async for chunk in stream:
if chunk:
async with self.lock:
self.buffer.append(chunk)
current_time = asyncio.get_event_loop().time()
# 满足以下任一条件则刷新:块大小足够 或 达到最小刷新间隔
if (len(self.buffer) >= self.chunk_size or
current_time - self.last_flush_time > self.min_flush_interval):
yield await self.flush()
# 处理剩余数据
if self.buffer:
yield await self.flush()
async def flush(self) -> str:
"""刷新缓冲区并返回处理后的数据"""
data = ''.join(self.buffer)
self.buffer = []
self.last_flush_time = self.event_loop.time()
# 异步处理数据,不阻塞事件循环
processed_data = await self.event_loop.run_in_executor(
None, self.process_data, data
)
return processed_data
def process_data(self, data: str) -> str:
"""实际数据处理逻辑"""
# 1. 解析函数调用结果
# 2. 转换为自然语言片段
# 3. 进行格式美化
return f"实时更新:{data}"
流式优化技巧
- 增量解析:对函数返回的JSON数据进行增量解析,不需要等待完整数据
- 优先级调度:高优先级用户请求插队处理,确保VIP用户体验
- 预生成提示:在等待函数返回时,预生成引导性文本(如"正在查询最新数据…")
- 双向流式:实现请求发送和结果接收的双向流式处理,减少交互延迟
3. 模型协同优化:从单一模型到智能调度网络
随着模型类型增多和场景复杂化,单一模型难以兼顾性能、成本和效果,需要构建多模型协同体系。
智能模型路由系统
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collectors;
public class IntelligentModelRouter {
private final List<Model> models;
private final ModelMetrics metrics;
private final Map<String, String> functionModelMapping; // 函数-模型映射表
private final LoadBalancer loadBalancer;
public IntelligentModelRouter(List<Model> models) {
this.models = models;
this.metrics = new ModelMetrics();
this.functionModelMapping = new ConcurrentHashMap<>();
this.loadBalancer = new WeightedRoundRobinLoadBalancer();
// 初始化函数-模型映射
initializeFunctionModelMapping();
}
public FunctionCallResponse route(FunctionCallRequest request) {
// 1. 记录请求指标
metrics.recordRequest(request.getFunctionName());
// 2. 检查是否有专用模型
String dedicatedModelId = functionModelMapping.get(request.getFunctionName());
if (dedicatedModelId != null) {
Model dedicatedModel = models.stream()
.filter(m -> m.getId().equals(dedicatedModelId))
.findFirst()
.orElse(null);
if (dedicatedModel != null && dedicatedModel.isHealthy()) {
return executeWithFallback(dedicatedModel, request);
}
}
// 3. 根据请求复杂度路由
if (isSimpleQuery(request)) {
// 简单请求路由到轻量模型
List<Model> lightweightModels = models.stream()
.filter(m -> m.getType() == ModelType.LIGHTWEIGHT && m.isHealthy())
.collect(Collectors.toList());
if (!lightweightModels.isEmpty()) {
Model selected = loadBalancer.select(lightweightModels);
return executeWithFallback(selected, request);
}
}
// 4. 复杂请求路由到高性能模型
List<Model> highPerformanceModels = models.stream()
.filter(m -> m.getType() == ModelType.HIGH_PERFORMANCE && m.isHealthy())
.collect(Collectors.toList());
if (!highPerformanceModels.isEmpty()) {
Model selected = selectBestModelBasedOnMetrics(highPerformanceModels);
return executeWithFallback(selected, request);
}
// 5. 最后手段:使用基础模型
throw new ServiceUnavailableException("No available models to process request");
}
private FunctionCallResponse executeWithFallback(Model primary, FunctionCallRequest request) {
try {
long startTime = System.currentTimeMillis();
FunctionCallResponse response = primary.invoke(request);
metrics.recordSuccess(primary.getId(), request.getFunctionName(),
System.currentTimeMillis() - startTime);
return response;
} catch (Exception e) {
metrics.recordFailure(primary.getId(), request.getFunctionName());
// 尝试 fallback 到其他模型
return routeToFallbackModel(request, primary.getId());
}
}
// 其他辅助方法...
}
模型协同策略
- 能力分层:将模型按能力分为轻量模型(处理简单函数调用)、通用模型(处理复杂逻辑)和专业模型(处理领域任务)
- 动态负载均衡:基于实时QPS、延迟和错误率调整模型负载
- 自适应降级:系统压力大时自动降级到简化功能,保证核心流程可用
- 成本优化:通过模型选择策略降低总体调用成本(如简单任务用低成本模型)
4. 资源调度优化:从静态配置到动态弹性伸缩
Function Calling系统的资源消耗具有突发性和不均衡性,需要动态调整资源分配以应对负载变化。
弹性资源调度器
import KubernetesClient as k8s
import time
class ElasticResourceScheduler:
def __init__(self):
self.client = k8s.Client()
self.min_replicas = 2
self.max_replicas = 20
self.target_cpu_usage = 70 # 目标CPU使用率(%)
self.scale_up_threshold = 80 # 扩容阈值
self.scale_down_threshold = 30 # 缩容阈值
self.cooldown_period = 60 # 冷却时间(秒)
self.last_scale_time = 0
def adjust_resources(self):
"""根据当前负载调整资源"""
current_time = time.time()
# 冷却时间内不调整
if current_time - self.last_scale_time < self.cooldown_period:
return
# 获取当前部署信息
deployment = self.client.get_deployment("function-calling-service")
current_replicas = deployment.spec.replicas
metrics = self.client.get_metrics("function-calling-service")
cpu_usage = metrics.average_cpu_usage
# 决定扩容还是缩容
if cpu_usage > self.scale_up_threshold and current_replicas < self.max_replicas:
# 扩容:增加20%或至少1个副本
new_replicas = min(
current_replicas + max(1, int(current_replicas * 0.2)),
self.max_replicas
)
self.client.scale_deployment("function-calling-service", new_replicas)
self.last_scale_time = current_time
print(f"Scaled up to {new_replicas} replicas (CPU usage: {cpu_usage}%)")
elif cpu_usage < self.scale_down_threshold and current_replicas > self.min_replicas:
# 缩容:减少10%或至少1个副本
new_replicas = max(
current_replicas - max(1, int(current_replicas * 0.1)),
self.min_replicas
)
self.client.scale_deployment("function-calling-service", new_replicas)
self.last_scale_time = current_time
print(f"Scaled down to {new_replicas} replicas (CPU usage: {cpu_usage}%)")
def schedule_function_execution(self, function_call):
"""智能调度函数执行到合适的节点"""
# 1. 根据函数类型选择合适的节点池
node_pool = self._get_node_pool_for_function(function_call.function_name)
# 2. 选择负载最低的节点
node = self._select_least_loaded_node(node_pool)
# 3. 执行函数调用
return self.client.execute_on_node(node, function_call)
通过上述多层次的性能优化策略,Function Calling系统能够在保证高可用性和低延迟的同时,实现资源的高效利用和成本的有效控制。实际应用中,需要根据业务特点和性能指标持续调优,构建适应业务增长的弹性架构。
6、与微服务架构的集成路径
Function Calling系统与企业现有微服务架构的集成需围绕"解耦、安全、弹性、可观测"四大核心目标,典型的分层架构如下:
[LLM层] → [Function Calling调度层] → [微服务层]
1. 集成方式
- API网关集成:企业级应用的首选方案,适合需要统一管控的场景
- 服务网格集成:大规模分布式系统的优化方案,适合微服务数量多的场景
- 直接HTTP/gRPC调用:简单场景的轻量化方案,适合微服务数量少的情况
2. 关键集成要点
- 标准化接口设计:使用JSON Schema约束输入输出,实现版本管理
- 安全管控:通过RBAC/ABAC控制访问权限,实现数据脱敏和审计日志
- 弹性设计:采用异步调用、重试机制和熔断降级应对高并发与故障
- 可观测性:通过链路追踪、指标监控和日志分析实现问题快速定位
7、技术挑战与解决方案
Function Calling作为连接大模型与现实世界的核心桥梁,在实际落地中面临着自然语言的模糊性、外部系统的不确定性以及安全合规等多重挑战。这些问题往往不是单一技术能解决的,需要结合自然语言处理、系统工程和安全防护等多维度方案。
1. 典型问题深度解析
(1)参数理解与映射难题
自然语言的灵活性与函数参数的严谨性存在天然冲突,主要体现在三个层面:
- 歧义表达:用户说"订张去魔都的机票",需将"魔都"映射为"上海";说"下周三出发",需转换为具体日期"2025-10-15"
- 单位混淆:"10点起飞"可能是10:00还是22:00?"1kg的包裹"需确认是否符合快递重量限制
- 隐含信息:“帮我订明天去北京的票"隐含了"出发地为当前城市”(需从用户上下文获取)
某旅行平台数据显示,这类参数理解问题导致的调用失败占比达28%,是Function Calling落地的首要障碍。
(2)复杂错误场景的鲁棒性
外部工具/API的调用过程充满不确定性,常见错误包括:
- 瞬时故障:网络波动导致API超时(某支付系统日均发生3000+次)
- 格式异常:工具返回非预期格式(如JSON字段缺失、类型错误)
- 权限失效:API密钥过期或权限变更(金融场景占比达12%)
- 逻辑错误:工具返回业务逻辑错误(如"航班已取消"但参数正确)
缺乏完善的错误处理机制会导致系统稳定性下降,某智能客服平台曾因未处理API超时问题,导致服务中断47分钟。
(3)安全与合规风险
当Function Calling涉及支付、用户数据等敏感操作时,安全风险被放大:
- 参数注入:恶意用户输入包含SQL注入或命令注入的参数(如
"; DROP TABLE users;--) - 越权调用:普通用户调用管理员权限的工具(如"查询所有用户订单")
- 数据泄露:工具返回的敏感信息(如身份证号)被直接暴露给用户
- 合规风险:金融场景中未记录调用日志,违反PCI DSS等监管要求
某银行的AI助手曾因未做参数清洗,导致用户通过特殊输入获取了他人的账户余额,造成严重合规事故。
(4)多工具协同与任务规划
面对复杂需求(如"先查北京明天的天气,再订适合的酒店,最后预约接机服务"),系统需解决:
- 步骤拆解:将复杂任务分解为可执行的工具调用序列
- 依赖处理:前序工具的结果作为后序工具的参数(如用天气结果筛选"带泳池"的酒店)
- 资源竞争:并发调用多个工具时的资源分配与冲突解决
- 中断恢复:某一步调用失败后,如何回溯或调整后续步骤
调研显示,超过60%的企业级Function Calling需求涉及3个以上工具协同,单纯依赖大模型的"一次性规划"往往难以应对。
2. 进阶优化方案与实践
(1)智能参数处理引擎
针对参数理解难题,需构建"识别-映射-校验"三级处理机制:
import re
from fuzzywuzzy import fuzz
from datetime import datetime, timedelta
class SmartParamProcessor:
def __init__(self):
# 实体映射库:城市别名、日期表达式等
self.city_aliases = {"帝都": "北京", "魔都": "上海", "鹏城": "深圳"}
self.date_patterns = {
"今天": datetime.now().strftime("%Y-%m-%d"),
"明天": (datetime.now() + timedelta(days=1)).strftime("%Y-%m-%d"),
"后天": (datetime.now() + timedelta(days=2)).strftime("%Y-%m-%d")
}
def process(self, user_input, function_schema):
"""处理参数的完整流程"""
# 1. 提取用户输入中的实体
entities = self._extract_entities(user_input)
# 2. 模糊匹配并映射参数
params = self._fuzzy_map_params(entities, function_schema["parameters"])
# 3. 校验参数完整性与格式
missing_params = self._check_missing_params(params, function_schema["parameters"])
if missing_params:
return {"status": "missing", "params": params, "missing": missing_params}
# 4. 格式转换与标准化
normalized_params = self._normalize_params(params, function_schema["parameters"])
return {"status": "success", "params": normalized_params}
def _fuzzy_map_params(self, entities, param_schema):
"""模糊匹配参数名与实体"""
params = {}
for param_name, param_info in param_schema["properties"].items():
# 计算实体与参数名的语义相似度
best_match = None
best_score = 0
for entity_name, entity_value in entities.items():
score = fuzz.token_sort_ratio(param_name, entity_name)
if score > best_score and score > 60: # 相似度阈值
best_score = score
best_match = entity_value
if best_match:
# 特殊类型映射(如城市别名)
if param_info.get("type") == "string" and param_name == "city":
params[param_name] = self.city_aliases.get(best_match, best_match)
else:
params[param_name] = best_match
return params
def _check_missing_params(self, params, param_schema):
"""检查必填参数是否缺失"""
return [p for p in param_schema.get("required", []) if p not in params]
# 其他辅助方法:_extract_entities、_normalize_params等
核心优化点:
- 引入知识图谱增强实体映射(如"小蛮腰"→"广州塔")
- 基于用户历史对话补全隐含参数(如默认出发地)
- 动态生成追问话术(如"请问您说的’下周三’是指10月16日吗?")
(2)分层错误处理框架
针对工具调用的不确定性,需设计多层级的错误应对策略:
public class RobustFunctionExecutor {
// 错误处理策略配置
private static final int MAX_RETRY = 3; // 最大重试次数
private static final long INITIAL_BACKOFF = 1000; // 初始重试间隔(毫秒)
private static final Set<String> RETRYABLE_ERRORS = Set.of(
"timeout", "connection_error", "service_unavailable"
); // 可重试的错误类型
public FunctionResult execute(FunctionCall call) {
// 1. 预执行校验
try {
validateCall(call); // 校验参数格式、权限等
} catch (InvalidParameterException e) {
return FunctionResult.failure("参数错误:" + e.getMessage());
} catch (UnauthorizedException e) {
return FunctionResult.failure("权限不足:" + e.getMessage());
}
// 2. 带重试机制的执行
for (int attempt = 0; attempt < MAX_RETRY; attempt++) {
try {
// 执行调用并设置超时
FunctionResult result = executeWithTimeout(call, 5000); // 5秒超时
// 检查返回格式是否符合预期
if (isValidResponseFormat(result)) {
return result;
} else {
throw new InvalidResponseFormatException("工具返回格式异常");
}
} catch (Exception e) {
String errorType = classifyError(e);
// 判断是否需要重试
if (!RETRYABLE_ERRORS.contains(errorType) || attempt == MAX_RETRY - 1) {
// 不可重试或最后一次尝试失败:返回友好提示
String userMsg = generateUserFriendlyMessage(errorType);
return FunctionResult.failure(userMsg, e);
}
// 指数退避重试
long backoff = (long) (INITIAL_BACKOFF * Math.pow(2, attempt));
try {
Thread.sleep(backoff);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
return FunctionResult.failure("执行被中断");
}
}
}
return FunctionResult.failure("达到最大重试次数");
}
// 其他辅助方法:错误分类、用户提示生成等
}
关键机制:
- 错误分类体系:将错误分为"可重试"(网络波动)、“需用户干预”(参数错误)、“系统级”(服务下线)
- 智能重试策略:根据错误类型动态调整重试次数和间隔(如支付API失败重试更谨慎)
- 降级方案:核心工具不可用时,自动切换到备用工具(如高德地图API故障时切换到百度地图)
(3)全链路安全防护体系
针对安全风险,需构建从输入到输出的全链路防护:
import jwt
import re
from typing import Dict
class SecurityGuard:
def __init__(self, secret_key):
self.secret_key = secret_key
# 敏感参数正则(身份证、银行卡等)
self.sensitive_patterns = {
"id_card": re.compile(r"\d{17}[\dXx]"),
"bank_card": re.compile(r"\d{16,19}"),
"phone": re.compile(r"1[3-9]\d{9}")
}
# 危险操作白名单(仅允许特定角色调用)
self.dangerous_functions = {
"transfer_money": ["admin", "vip_user"],
"query_all_orders": ["admin"]
}
def validate_permission(self, function_name: str, token: str) -> bool:
"""验证用户是否有权调用函数"""
try:
# 解析JWT令牌获取用户角色
payload = jwt.decode(token, self.secret_key, algorithms=["HS256"])
user_role = payload.get("role", "guest")
# 非危险函数直接通过
if function_name not in self.dangerous_functions:
return True
# 检查用户角色是否在白名单中
return user_role in self.dangerous_functions[function_name]
except Exception:
return False
def sanitize_parameters(self, params: Dict[str, str]) -> Dict[str, str]:
"""清洗参数,防止注入攻击"""
sanitized = {}
for key, value in params.items():
# 过滤SQL注入关键字
if isinstance(value, str):
sanitized_value = re.sub(r"['\";\\]|(union|select|drop)\s+", "", value, flags=re.IGNORECASE)
sanitized[key] = sanitized_value
else:
sanitized[key] = value
return sanitized
def redact_sensitive_data(self, response: str) -> str:
"""脱敏返回结果中的敏感信息"""
redacted = response
for name, pattern in self.sensitive_patterns.items():
# 身份证号保留前6后4位,银行卡号保留后4位
if name == "id_card":
redacted = pattern.sub(r"\g<0>[0:6]********\g<0>[-4:]", redacted)
elif name == "bank_card":
redacted = pattern.sub(r"************\g<0>[-4:]", redacted)
elif name == "phone":
redacted = pattern.sub(r"\g<0>[0:3]****\g<0>[-4:]", redacted)
return redacted
安全增强措施:
- 基于RBAC的细粒度权限控制(如"查询订单"需用户ID与订单归属一致)
- 参数校验沙箱:将参数放入隔离环境测试,验证无恶意行为后再执行
- 审计日志区块链存证:关键操作日志上链,确保不可篡改(金融场景必需)
- 动态威胁情报:实时更新攻击特征库,拦截新型注入攻击
(4)多工具协同规划系统
针对复杂任务,需构建任务规划与状态管理能力:
class TaskPlanner:
def __init__(self, tool_registry):
self.tool_registry = tool_registry # 工具注册表
self.task_queue = [] # 待执行的工具调用队列
self.task_context = {} # 任务上下文(存储中间结果)
def plan(self, user_request: str) -> None:
"""将用户请求分解为工具调用序列"""
# 1. 解析用户意图和子任务
subtasks = self._parse_subtasks(user_request)
# 2. 为每个子任务匹配工具并确定依赖关系
for subtask in subtasks:
tool = self._match_tool(subtask["intent"])
dependencies = self._find_dependencies(subtask, self.task_context)
self.task_queue.append({
"tool": tool["name"],
"parameters": subtask["parameters"],
"dependencies": dependencies,
"status": "pending"
})
async def execute(self) -> str:
"""执行任务队列,处理依赖关系"""
while self.task_queue:
# 找到所有可执行的任务(依赖已满足)
executable_tasks = [
t for t in self.task_queue
if t["status"] == "pending"
and all(self.task_context.get(d) is not None for d in t["dependencies"])
]
if not executable_tasks:
# 检查是否有无法满足的依赖
missing = [t for t in self.task_queue if t["status"] == "pending"]
return f"无法完成任务:缺少依赖 {missing[0]['dependencies']}"
# 并发执行可执行任务
for task in executable_tasks:
# 填充依赖参数
resolved_params = self._resolve_parameters(task, self.task_context)
# 调用工具
result = await self.tool_registry.invoke(
task["tool"], resolved_params
)
# 更新上下文和任务状态
self.task_context[task["tool"]] = result
task["status"] = "completed"
# 整合所有结果生成最终回答
return self._integrate_results(self.task_context)
# 其他辅助方法:子任务解析、工具匹配、结果整合等
协同优化点:
- 基于历史执行数据的任务排序(如先调用响应快的工具)
- 动态依赖调整:某工具调用失败后,自动寻找替代工具重新规划
- 资源预算控制:为复杂任务设置最大工具调用次数,避免资源浪费
3. 工程化落地建议
在实际落地Function Calling系统时,需结合业务场景选择合适的解决方案:
- 中小规模应用:优先使用成熟框架(如LangChain的Agent、Spring AI)的内置容错机制,聚焦核心业务逻辑
- 大规模企业应用:建议构建分层架构,将参数处理、错误处理、安全防护拆分为独立服务,通过API网关协同
- 关键业务场景:实施混沌工程测试(如随机注入API超时、参数错误),验证系统鲁棒性
某电商平台的实践表明,通过上述方案优化后,Function Calling的调用成功率从72%提升至95%,安全事件发生率下降至0.03%,充分验证了这些解决方案的有效性。
Function Calling的挑战本质上是"AI的灵活性"与"系统的确定性"之间的平衡问题。随着大模型能力的提升和工程实践的深入,这些挑战将逐步被攻克,推动AI从"对话助手"真正进化为"全能协作伙伴"。
技术演进:从FC到MCP的范式革命
1. 技术代际对比
| 维度 | Function Calling | MCP(Model Context Protocol) |
|---|---|---|
| 交互主体 | LLM→工具 | 多模型联邦协作 |
| 数据形态 | JSON参数 | 结构化上下文 |
| 协作模式 | 中心化调度 | 去中心化网状 |
2. 未来趋势
- 动态注册:运行时添加新工具(如新增快递查询接口)
- 多模态支持:直接处理图片/音频等原生数据
- 自愈机制:自动修正SQL语法错误并重试
- 动态联邦学习:多个Function Calling系统协同进化
- 因果推理增强:理解"如果…则…"类复杂指令
结语:AI协作的新范式
Function Calling不仅是技术突破,更是人机协作方式的革命。当大模型学会"摇人办事",我们正迈向这样的未来:每个普通人都能通过自然语言,调动企业级系统资源。正如DeepSeek团队在实践中所说:“这不是简单的API调用,而是构建智能体的’瑞士军刀’”。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
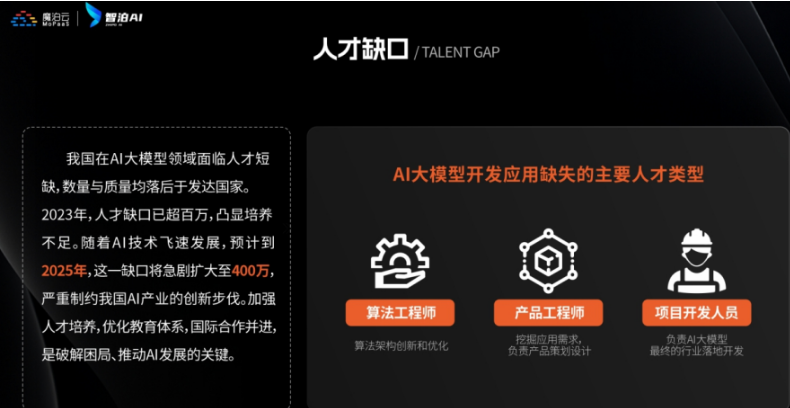
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

更多推荐

 39
39 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)