
Java程序员AI大模型学习秘籍:LLM完整学习路线指南,助你少走99%弯路!
人工智能正以颠覆性力量重塑科技行业,而大型语言模型(LLM)作为AI浪潮的核心引擎,已从“前沿概念”变为“必备技能”。对于深耕JVM生态的Java程序员而言,这并非“要不要学”的选择,而是“如何将Java的工程优势与AI结合”的机遇——毕竟我们熟悉的Spring生态、高并发处理、企业级中间件经验,正是构建稳定、可靠AI应用的关键基石。本文将为你打造一份“Java友好型”AI大模型学习路线,从基础认
人工智能正以颠覆性力量重塑科技行业,而大型语言模型(LLM)作为AI浪潮的核心引擎,已从“前沿概念”变为“必备技能”。对于深耕JVM生态的Java程序员而言,这并非“要不要学”的选择,而是“如何将Java的工程优势与AI结合”的机遇——毕竟我们熟悉的Spring生态、高并发处理、企业级中间件经验,正是构建稳定、可靠AI应用的关键基石。本文将为你打造一份“Java友好型”AI大模型学习路线,从基础认知到私有化部署,帮你一步步实现从“Java开发者”到“AI+Java全栈工程师”的转型。
1、为什么Java程序员必须学大模型?
过去,我们的工作聚焦于业务逻辑开发、微服务架构设计、JVM性能调优,但如今大模型已渗透到Java技术栈的核心场景,不学就会面临“技能断层”:
- 交互范式升级: 从传统的GUI(图形界面)、API(接口调用),转向CUI(对话式界面)——比如用AI对话替代复杂的管理后台,让业务人员直接通过自然语言查询数据、生成报表,而Java需要负责对话背后的逻辑支撑。
- 开发效率革命: AI辅助工具不再是“锦上添花”,而是“生产力刚需”——GitHub Copilot、CodeGeeX等工具能生成符合阿里巴巴Java开发手册的代码,甚至帮你排查NPE(空指针异常)、分析GC日志,但前提是你会用“精准提示词”引导工具。
- 企业业务转型: 无论是金融领域的“智能风控”(用大模型分析交易日志)、电商领域的“智能客服”(对接Java工单系统),还是传统行业的“文档数字化”(用AI解析PDF报表),本质都是“Java系统+大模型能力”的融合——不懂大模型,就会错过企业级项目的核心开发机会。
2、Java开发者AI大模型学习路线全景图
为了让Java程序员少走弯路,这份路线图从“Java技术栈适配性”出发,分为四个递进阶段,每个阶段都融入Java场景化实践,避免“学了用不上”的问题。

下面我们逐一拆解每个阶段的核心知识点与Java专属实践方案。
阶段一:建立AI认知,掌握Java场景化提示工程(L1)
目标: 跳出“大模型=炼丹”的误区,明确大模型的能力边界,同时学会用“Java专属提示词”让AI高效解决Java问题——这是最低成本、最高回报的入门步骤。
1.1 大模型核心概念(Java视角解读)
不用纠结复杂的数学公式,重点理解与Java开发相关的核心概念:
- 什么是大模型?: 可以理解为“一个训练了海量文本的‘超级代码库+知识库’”,Java调用它就像调用一个“远程的智能工具类”,但需要用“提示词”定义输入输出格式。
- Transformer架构: 核心是“自注意力机制”——类比Java中的“缓存”,能快速定位文本中关键信息(比如你问“Spring Boot如何集成Redis”,它能优先关注“Spring Boot”“Redis”“集成”这几个关键词)。
- Token机制: 文本会被拆成Token处理(比如“Spring”是1个Token,“@Autowired”是2个Token),这和Java中“字符串拆分”类似,但要注意:大模型有Token上限(如GPT-4是8k/32k Token),就像Java方法的参数长度限制,超过会报错。
1.2 Java场景化提示工程(核心技能)
提示工程不是“写作文”,而是“给AI写‘Java需求文档’”,重点掌握3个技巧:
- 基础指令:明确“Java技术栈+场景+输出格式”: 不要写“生成一个接口”,而要写“生成一个符合RESTful规范的Spring Boot接口,包含用户查询功能(参数:userId,返回:UserDTO),并添加@Valid参数校验和全局异常处理”。
- 上下文学习:给AI“Java示例”: 比如你想让AI优化一段Java代码,先给它“反例”(比如有NPE风险的代码),再给它“期望效果”(比如用Optional优化后的代码),AI会更贴合你的需求。
- 思维链:引导AI“像Java程序员一样思考”: 比如问“JVM内存溢出如何排查”,可以加一句“请按照‘查看日志→分析堆转储文件→定位大对象→优化代码’的步骤,用Java工具(jmap、jhat)说明排查过程”。
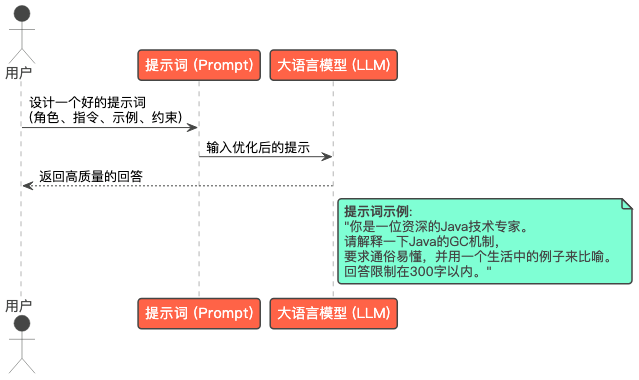
实践项目一:Java问题专属AI助手练习
- 选择一款代码友好型大模型(如DeepSeek-Coder、CodeLlama),避免用通用对话模型(如ChatGPT 3.5,代码场景效果较差)。
- 设计3类Java问题,对比不同提示词的效果:
- 基础问题:“用Java 8 Stream API实现List按年龄分组”(无提示 vs 加“要求代码简洁,包含空值判断”)。
- 故障排查:“为什么我的MyBatis查询返回null?”(无提示 vs 加“请列出3种常见原因,并给出Java代码层面的排查方法”)。
- 架构设计:“设计一个Java微服务的日志系统”(无提示 vs 加“要求集成Logback+ELK,支持按服务名、日志级别筛选,给出核心配置代码”)。
- 整理“有效提示词模板”,后续开发可直接复用。
阶段二:API驱动开发,打造Java+AI融合应用(L2)
目标: 把大模型的能力“接入”Java应用——就像集成Redis、MySQL一样,通过API调用让Java系统拥有AI功能,重点解决“企业级场景的落地问题”(如知识老旧、幻觉)。
2.1 核心技术(Java开发者必学)
- 大模型API调用:Java HTTP客户端实践: 不用死记API参数,重点掌握“封装与容错”:
- 用Spring Cloud OpenFeign封装API(比如封装OpenAI的ChatCompletion接口),简化调用代码;
- 用OkHttp的拦截器处理API密钥(避免硬编码,从Nacos配置中心获取)、请求重试(遇到503错误时重试);
- 用Java的DTO类定义请求/响应格式(比如ChatRequest、ChatResponse),避免JSON解析异常。
- Embedding技术:Java文本向量化: 理解Embedding是“将文本转换成Java中的double数组(向量)”,就像把“用户问题”和“文档内容”都变成“数字密码”,通过计算向量相似度(如余弦相似度)找到最相关的内容——这是实现“语义搜索”的基础。
- RAG技术:解决大模型“知识过期”问题: 企业场景中,大模型的“幻觉”(编造答案)和“知识老旧”(不知道2024年后的新技术)是致命问题,RAG就是“给大模型装一个‘Java知识库’”:

- 把Java文档(如Spring Boot 3.2新特性、MyBatis-Plus手册)拆成小块;
- 用Embedding API将文本块转成向量,存入向量数据库(如Milvus、FAISS,Java有对应的SDK);
- 用户提问时,先从向量库中找到最相关的文档块,再把文档块和问题一起发给大模型,让它基于文档回答。
- Function Calling:让大模型调用Java工具: 大模型本身不能操作数据库、调用第三方API,但可以通过Function Calling“告诉Java该调用哪个方法”——比如用户问“查询用户ID=100的订单”,大模型会生成“调用getOrderByUserId(100)”的指令,Java代码接收指令后执行DAO层方法,再把结果返回给大模型。
2.2 实践项目二:Java技术文档智能问答系统(企业级demo)
- 文档处理: 收集Java技术文档(如《Spring Cloud Alibaba实战手册》PDF、Markdown格式的Nacos官方文档),用Apache PDFBox(处理PDF)、CommonMark(处理Markdown)提取文本,按“每500字一个块”拆分,避免Token超限。
- 向量库集成: 用Java代码调用Milvus SDK,创建向量集合,将文本块的Embedding向量(调用OpenAI Embedding API或国内的通义千问Embedding API)存入Milvus。
- 后端接口开发: 基于Spring Boot开发两个接口:
/api/ai/query: 接收用户问题(如“Nacos如何配置服务熔断”),先查询Milvus获取相关文档块,再调用大模型API生成回答;/api/doc/upload: 支持上传新的Java文档,自动完成文本提取、向量生成、入库,实现“知识库更新”。
- 容错与优化: 用Resilience4j实现API调用的熔断(大模型API超时后返回默认提示),用Redis缓存高频问题的Embedding结果(减少重复调用成本)。
阶段三:框架赋能,构建Java驱动的AI Agent(L3)
目标: 当简单的API调用无法满足复杂业务(如“自动完成Java项目初始化”“智能排查微服务故障”)时,需要用LLM框架构建AI Agent——让大模型像“Java工程师”一样,自主规划任务、调用工具、解决问题。
3.1 主流LLM框架(Java友好型)
- LangChain4j: 专为Java开发者设计的框架,封装了“链(Chain)”“内存(Memory)”“Agent”等核心组件——比如用Chain串联“Embedding查询→大模型回答”的流程,用Memory保存用户对话历史(避免用户重复提问),用Agent实现“自主调用工具”。
- Semantic Kernel: 微软推出的框架,核心是“技能(Skill)”——把Java方法封装成“技能”(如“创建Spring Boot项目”“生成MyBatis Mapper”),Agent会根据目标自动选择技能组合。
3.2 AI Agent核心逻辑(Java落地)
Agent的本质是“大模型+Java工具集+任务规划器”,核心遵循ReAct模式(Reason→Act→Observe):
- 思考(Reason): 用户说“帮我初始化一个Spring Boot 3.2项目,集成MySQL和Redis”,Agent会思考“需要先创建项目结构→配置application.yml→生成实体类和DAO层→写测试用例”;
- 行动(Act): 调用Java工具(如用Spring Initializr API创建项目、用FreeMarker模板生成application.yml);
- 观察(Observe): 检查工具执行结果(如项目是否创建成功、配置文件是否正确),如果有问题(如MySQL依赖版本错误),则调整步骤重新执行。

3.3 实践项目三:Java项目初始化AI Agent
- 定义Java工具(Skill):
createSpringBootProject(String groupId, String artifactId, List<String> dependencies): 调用Spring Initializr API创建项目,返回项目压缩包URL;generateApplicationYml(String dbUrl, String redisHost): 用FreeMarker模板生成application.yml配置文件;generateUserEntity(String tableName): 根据MySQL表名(如user)生成Java实体类(包含@TableName、@TableId注解)。
- Agent构建(用LangChain4j):
- 配置Agent的“记忆”(保存用户输入的项目信息,如groupId、依赖列表);
- 设定“工具选择规则”(当需要创建项目时调用
createSpringBootProject,需要配置文件时调用generateApplicationYml); - 加入“结果校验逻辑”(调用Java方法检查生成的application.yml是否包含
spring.datasource配置)。
- 测试与优化: 输入目标“创建一个groupId为com.example、artifactId为ai-demo的Spring Boot项目,集成MySQL 8.0、Redis、Spring Security”,观察Agent是否能自主调用工具,生成完整的项目结构和配置文件。
阶段四:模型调优与私有化,成为Java+AI专家(L4)
目标: 解决企业“数据安全”和“领域适配”问题——比如金融、医疗行业不能把敏感数据发给第三方API,需要将大模型部署在自己的服务器上;同时,通过调优让模型更懂Java(如只训练“Java代码生成”相关数据)。
4.1 模型调优(Java开发者需了解的核心方法)
不用深入Python炼丹,但要知道“如何让模型更贴合Java场景”:
- 全量调优: 更新模型所有参数,效果最好但成本极高(需要GPU集群),适合大厂,Java开发者一般用不到;
- PEFT(参数高效微调): 只训练模型的“小部分参数”(如LoRA技术),成本低、效果好——比如用Java项目的开源代码(如Spring、MyBatis的源码)作为训练数据,微调开源模型(如CodeLlama),让它生成的Java代码更符合工业标准。
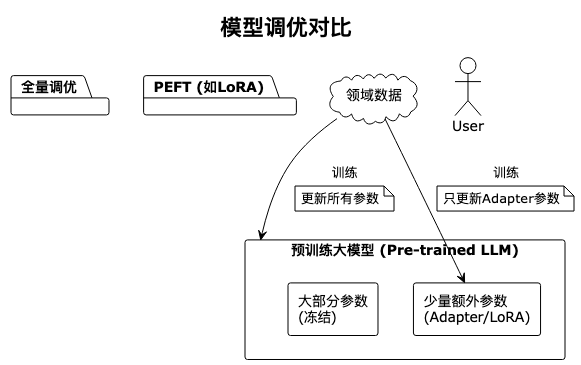
4.2 大模型私有化部署(Java集成方案)
Java开发者不用自己训练模型,重点掌握“如何将开源模型部署成API,供Java应用调用”:
- 模型选型: 根据硬件选择模型——本地开发用“小模型”(如CodeLlama-7B,需16GB内存),服务器部署用“中模型”(如Qwen-14B-Chat,需32GB内存);
- 部署工具: 用Ollama(简单易用,支持一键部署CodeLlama、Qwen)或TGI(Text Generation Inference,高性能,支持Docker部署),部署后会暴露HTTP API(和OpenAI API格式兼容);
- Java集成: 修改之前的Spring Boot应用,把大模型API地址从“https://api.openai.com”改成“http://localhost:8080/v1”(Ollama的默认地址),无需修改其他代码——实现“无缝切换第三方API和私有模型”。
4.3 实践项目四:本地Java代码生成助手(私有化部署)
- 部署模型: 在本地电脑(或云服务器)上用Ollama部署CodeLlama-7B-Instruct模型,执行命令
ollama run codellama:7b-instruct,启动后检查API是否可用(访问http://localhost:11434/v1/models)。 - Java客户端开发: 用Spring Boot开发一个“代码生成工具”,提供接口
/api/code/generate,支持参数:task: 代码生成任务(如“生成Java 8的线程池工具类”“写一个Spring Boot的全局异常处理器”);style: 编码风格(如“阿里巴巴Java开发手册规范”“简洁风格,无注释”)。
- 性能测试: 用JMH(Java Microbenchmark Harness)测试本地模型和OpenAI API的响应时间(比如生成100行Java代码的耗时),对比私有化部署的优势(延迟低、无网络依赖)。
3、总结:Java程序员的AI时代竞争力
这份学习路线没有让你“放弃Java去学Python炼丹”,而是让你“用Java的优势驾驭AI”——从提示工程的“精准指令”,到API开发的“企业级集成”,再到Agent的“自主任务规划”,最后到私有化部署的“安全可控”,每一步都围绕Java技术栈展开。
记住,AI大模型不是“替代Java程序员”,而是“让Java程序员能做更有价值的事”——你不用再写重复的CRUD代码,而是可以专注于“AI应用的架构设计”“Java系统与大模型的融合方案”“企业级AI应用的性能优化”。
从现在开始,先完成“阶段一的提示工程练习”,再逐步推进到项目开发——当你能用Java写出一个稳定运行的AI Agent时,你就已经成为了AI时代的“稀缺人才”。
4、 AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 28
28 0
0- 0



 已为社区贡献289条内容
已为社区贡献289条内容

所有评论(0)