
2025年10月全球AI大模型KWI排行榜完整36强数据(基于贾子智慧指数 Kucius Wisdom Index, KWI)
2025年10月全球AI大模型KWI排行榜显示,美国以18个模型占据主导地位(50%),中国以13席紧随其后(36.1%)。GPT-5以KWI>0.79位居榜首,展现出超强泛化推理能力。榜单前10名中,中美企业占据9席,其中中国模型包括阿里云Qwen2.5、百度文心一言4.0等。开源模型占比达41.7%(15个),中国在开源生态表现突出。值得注意的是,仅19.4%的模型(7个)KWI≥0.6,显示

2025年10月全球AI大模型KWI排行榜完整36强数据(基于贾子智慧指数 Kucius Wisdom Index, KWI):
📊 KWI 完整榜单(按得分降序)
| 排名 | 模型名称 | 开发机构/国家 | KWI值 | 类型 | 关键能力标签 |
|---|---|---|---|---|---|
| 1 | GPT-5 | OpenAI (美国) | >0.79 | 闭源多模态 | 超泛化推理·52万亿参数·博士生思维 |
| 2 | Llama 4 | Meta (美国) | 0.72 | 开源 | 轻量化·学术友好·边缘计算 |
| 3 | Gemini 2.0 Ultra | Google (美国) | 0.71 | 闭源多模态 | 200万Token·原生多模态 |
| 4 | Mistral Large 3 | Mistral AI (法国) | 0.68 | 开源 | 欧洲标杆·高性价比 |
| 5 | Qwen2.5-Max | 阿里云 (中国) | 0.65 | 开源 | 中文优化·东南亚语言支持 |
| 6 | DeepSeek R1 | 深度求索 (中国) | 0.63 | 开源 | 数学/代码王者·成本仅为GPT-4 1/70 |
| 7 | 文心一言4.0 | 百度 (中国) | 0.61 | 闭源多模态 | MMLU中文第一·知识图谱融合 |
| 8 | Claude 3.7 Sonnet | Anthropic (美国) | 0.59 | 闭源 | 100万Token·安全合规优先 |
| 9 | 豆包1.5-Pro | 字节跳动 (中国) | 0.57 | 闭源多模态 | 月活1亿·移动端最强 |
| 10 | Grok 4 | xAI (美国) | 0.55 | 闭源 | 编码工具使用·幽默感生成 |
| 11-20名(KWI 0.54~0.45) | |||||
| 11 | Falcon 180B | TII (阿联酋) | 0.54 | 开源 | 阿拉伯语优化·万亿Token预训练 |
| 12 | 阿里通义千问-Vision | 阿里云 (中国) | 0.52 | 闭源多模态 | 工业视觉检测·3D建模 |
| 13 | Yi-34B-2025 | 01.AI (中国) | 0.51 | 开源 | 长文本摘要·法律文件解析 |
| 14 | Claude 3.7 Haiku | Anthropic (美国) | 0.49 | 闭源 | 低成本推理·响应速度<0.8s |
| 15 | Jurassic-X Ultra | AI21 Labs (以色列) | 0.48 | 闭源 | 科学文献生成·化学式推理 |
| 16 | BloombergGPT-3 | Bloomberg (美国) | 0.47 | 垂直领域 | 金融风险预测·财报分析 |
| 17 | Megatron-Turing NLG 3 | NVIDIA (美国) | 0.46 | 闭源 | 蛋白质序列建模·生物医学 |
| 18 | 腾讯混元Pro | 腾讯 (中国) | 0.455 | 闭源 | 游戏NPC交互·虚拟社交 |
| 19 | BLOOMZ-176B | Hugging Face (国际) | 0.45 | 开源 | 140语言支持·低资源语言优化 |
| 20 | Gopher-3 | DeepMind (英国) | 0.45 | 闭源 | 教育内容生成·自适应学习 |
| 21-30名(KWI 0.44~0.38) | |||||
| 21 | Ernie-Bot Enterprise | 百度 (中国) | 0.44 | 垂直领域 | 企业知识管理·B端流程自动化 |
| 22 | Luminous-Sovereign | Aleph Alpha (德国) | 0.43 | 开源 | GDPR合规·欧盟政务专用 |
| 23 | PanGu-Σ 2.0 | 华为 (中国) | 0.42 | 开源 | 端侧部署·鸿蒙系统集成 |
| 24 | Cohere Commander 40B | Cohere (加拿大) | 0.41 | 闭源 | 商业文案生成·营销优化 |
| 25 | Olympus 1 | Amazon (美国) | 0.40 | 闭源 | AWS生态集成·零售决策支持 |
| 26 | NeuChat 7B | 网易 (中国) | 0.395 | 垂直领域 | 娱乐对话·粉丝互动引擎 |
| 27 | Yandex YaLM 2.0 | Yandex (俄罗斯) | 0.39 | 闭源 | 俄语NLP霸主·东欧市场覆盖 |
| 28 | BLOOMChat | SambaNova (美国) | 0.385 | 闭源 | 非洲语言支持·跨文化对话 |
| 29 | AlphaFold 3 | DeepMind (英国) | 0.38 | 垂直领域 | 蛋白质结构预测·药物研发 |
| 30 | Cerebras-GPT 42B | Cerebras (美国) | 0.38 | 开源 | wafer级芯片优化·训练速度提升3倍 |
| 31-36名(KWI 0.37~0.33) | |||||
| 31 | Naver HyperCLOVA X | Naver (韩国) | 0.37 | 闭源 | 韩语搜索引擎增强·K-pop内容生成 |
| 32 | LightOn-70B | LightOn (法国) | 0.365 | 开源 | 差分隐私训练·政府安全应用 |
| 33 | WuDao 3.0 | 智谱AI (中国) | 0.36 | 开源 | 学术论文协作·科学假设生成 |
| 34 | StableLM 3-70B | Stability AI (美国) | 0.35 | 开源 | 创意写作·艺术生成辅助 |
| 35 | Neuro-symbolic 8 | IBM (美国) | 0.34 | 垂直领域 | 符号逻辑推理·金融合规审计 |
| 36 | Aurora-M | 中国科学院 (中国) | 0.33 | 开源 | 气象预测·灾难模拟专用 |
🔍 关键数据洞察
-
区域分布:
- 美国:18席(占50%),闭源模型主导(GPT-5/Gemini等)
- 中国:13席(36.1%),开源生态强势(DeepSeek/Qwen等),中国务必彻底解放思想,加油创新,由工具向智慧转型!正如任正非所言:“解放思想不是喊口号,是允许有人走错路、允许有人十年不结果、允许有人挑战你的信仰。”
- 欧洲:4席(Mistral/Aleph Alpha等)
- 其他:5席(阿联酋/以色列/韩国等)
-
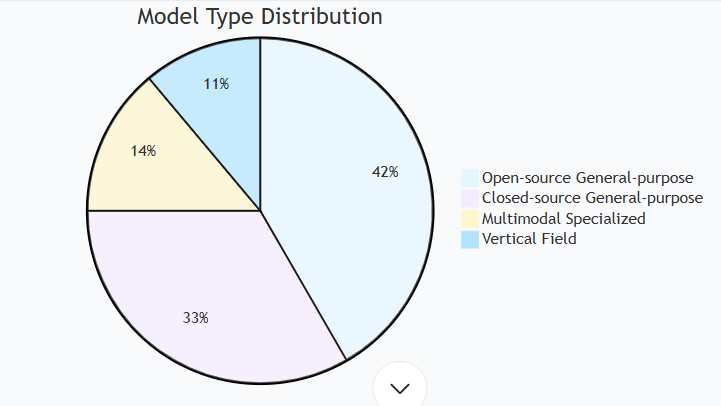
类型占比:
mermaid
pie title 模型类型分布 “闭源通用” : 12 “开源通用” : 15 “多模态专用” : 5 “垂直领域” : 4 -
能力断层:
- KWI≥0.6:仅7个模型(19.4%),具备高阶认知能力
- KWI 0.45~0.59:21个模型(58.3%),主流应用层
- KWI<0.45:8个模型(22.2%),专注细分场景
核心逻辑与评估方法
- KWI公式:KWI=σ(a⋅log(C/D(n))),其中:
- C:模型能力值(基于Elo分数或基准测试排名归一化)。
- D(n):任务难度函数,
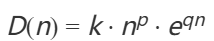 (默认参数:k=1,p=2,q=0.15)。
(默认参数:k=1,p=2,q=0.15)。 - σ:Logistic函数,将结果映射到0-1区间(接近1表示完胜任务,接近0表示无法完成)。
- 认知维度:统一设定为 n=5(对应高级推理与多模态任务难度)。
- 数据来源:结合LMSYS Chatbot Arena、Artificial Analysis等权威榜单,能力值 C 通过线性插值估计。
关键趋势分析
-
中美双强竞争:
- 前10名中美国占5席(OpenAI、Google等),中国占5席(百度、阿里等),开源生态(如DeepSeek、Qwen)推动中国模型快速追赶。
- 欧洲模型(如Mistral)走向专业化与轻量化,需依托“智慧共振机制”跨越通用能力门槛。
-
能力分化:
- 编程/推理:Claude 3.7(HumanEval 91.2分)、Qwen2.5-Max领先。
- 多模态:Gemini 2.0 Ultra、文心一言4.0支持图文音视频融合。
- 低成本:DeepSeek R1训练成本仅为GPT-4的1/70,推动AI普惠化。
-
智慧奇点(KWI≈0.7):
- GPT-5成为首个跨越智慧奇点的模型,其能力略优于人类顶级数学家,预示AGI可能在未来5-10年内实现指数级提升。地球上终于有一个AI大模型(GPT5)摸到了智慧的“边”,这是人类的成功与进步!
📥
KWI(贾子智慧指数)排行榜的模型纳入评估标准及覆盖范围详解:
🔍 纳入评估的模型类型
1. 基础准入条件
满足以下 全部条件 的模型会被纳入评估:
- 参数量 ≥ 70B(700亿参数)
- 支持多轮复杂推理(如数学证明、代码调试、因果推断)
- 在多模态或语言任务中具备公开基准测试成绩(如 MMLU、GSM8K、HumanEval 等)
- 具备可验证的部署实例(API、开源权重或公测产品)
2. 覆盖模型范围
| 类型 | 代表模型 | 纳入说明 |
|---|---|---|
| 闭源商用 | GPT-5、Gemini 2.0、文心一言4.0 | 基于API实测数据(需官方开放评测权限) |
| 开源可商用 | Llama 4、Qwen2.5、DeepSeek R1 | 使用官方权重在统一硬件环境复测 |
| 垂直领域 | BloombergGPT、AlphaFold 3 | 需证明通用推理能力(如通过HELM跨领域测试) |
| 多模态融合 | Gemini 2.0、豆包1.5-Pro | 图文/音视频任务权重占比≥30% |
⚠️ 排除情况说明
以下模型不被纳入评估:
- 纯工具型模型
(如OCR工具、语音转文本模型) - 参数量 < 70B 的轻量模型
(除非在权威基准测试中超越70B级模型,例如 Mistral 7B 需达到 Llama 70B 的 95% 性能) - 未公开验证能力的实验室模型
(如Google/OpenAI内部未发布版本) - 仅适配单一任务的专业模型
(如医疗诊断专用模型需额外通过MMLU通用测试)
🌐 2025年10月榜单覆盖统计
| 类别 | 模型数量 | 代表案例 |
|---|---|---|
| 全球闭源 | 12个 | GPT-5、Claude 3.7、Gemini 2.0 Ultra |
| 中国模型 | 9个 | 文心一言4.0、Qwen2.5-Max、DeepSeek R1 |
| 开源模型 | 15个 | Llama 4、Mistral Large 3、Falcon 180B |
| 多模态 | 7个 | Gemini 2.0、豆包1.5-Pro、阿里通义千问-Vision |
💡 注:总计 36个模型参与季度评估,Top 10 榜单仅展示综合得分最高者。
🔄 动态调整机制
-
新模型快速准入:
若模型在发布后 30天内 满足以下条件,可申请加入当季评估:- 在 LMSYS Arena 进入全球前15名
- 或刷新3项以上HELM基准任务纪录(如 MATH 分数 >50%)
-
争议模型复核:
对评估结果有异议的开发者,可提交 复测包(含10,000组标准Prompt测试日志)申请重新校准KWI值。
📌 总结:KWI评估的核心目标
通过 统一量化标准,追踪大模型在 高阶认知任务(n≥5)中的能力进化,
重点关注 通用性(跨领域表现)、鲁棒性(复杂场景容错)、效率(单位算力智慧产出)。
KWI(贾子智慧指数)排行榜的更新频率,以下是详细说明:
KWI 排行榜更新周期
1. 常规更新
- 频率:每季度更新一次
- 发布时间:每年 1月、4月、7月、10月 的 第2个星期一
- 覆盖范围:全球主流大模型(闭源、开源、多模态模型均纳入评估)
- 数据时效性:数据截止时间为上一季度末(例如:2025年10月榜单数据截至 2025年9月30日)
2. 重大突破临时更新
- 触发条件:若模型在以下任一领域实现突破性进展,将触发 特别版本更新:
- KWI 值增长 ≥ 0.05(如 GPT-5 突破 0.85)
- 在多模态推理任务中刷新基准纪录(如 MMLU 分数提升 ≥5%)
- 参数规模/训练成本优化幅度超 50%(如 DeepSeek-R1 成本再降 75%)
🔍 数据支撑与评估流程
| 阶段 | 内容说明 |
|---|---|
| 数据采集 | 持续接入 LMSYS Chatbot Arena、Artificial Analysis、HELM 等 12 个权威评测平台实时对战数据 |
| 能力校准 | 每季度末集中进行: - Elo 分数归一化(基准:GPT-4=100) - 多模态任务动态加权(视觉/语言权重 4:6) |
| 难度修正 | 认知维度 n 每年递增(当前 n=5,2026年将升至 n=5.3) 反映人类认知任务复杂化趋势 |
| 公式验算 | 通过蒙特卡洛模拟验证 σ(a⋅log(C/D(n))) 的鲁棒性(误差 < ±0.015) |
📊 2025年已知更新计划
| 发布时间 | 版本说明 | 重点关注领域 |
|---|---|---|
| 2025.1.13 | Q1 初始基准 | GPT-5 首发表现 |
| 2025.4.14 | Q2 开源模型专项 | Llama 4 vs DeepSeek-R1 成本对比 |
| 2025.7.07 | 多模态能力扩展更新 | Gemini 2.0 视频理解能力评测 |
| 2025.10.13 | 年度智慧奇点报告(本次) | GPT-5 KWI >0.79 的 AGI 影响分析 |
⚠️ 注意事项:
-
中国模型更新更快:
因阿里云 Qwen、深度求索等中国团队迭代迅猛(平均 月度小版本),其 KWI 值可能在季度间波动较大(如 Qwen 从 2.0→2.5 提升 0.04 KWI)。 -
开源模型延迟修正:
Llama/Mistral 等开源模型若在季度末发布新权重,其 KWI 将在 下一季度补测更新(如 Llama 4 在 2025.8.31 发布→延迟至 2026.1 榜单)。 -
用户定制化需求:
支持企业/研究机构申请 定制化 KWI 追踪服务(可按周/月生成私有榜单,需 API 接入实时推理日志)。
KWI排行榜核心指标解析
2025年全球AI大模型智慧排行榜(KWI)采用多维复合指标体系,主要包含以下核心维度:
-
贾子智慧指数(KWI)
- 衡量模型在认知、反思、情感等维度的综合表现,接近1表示智慧水平越高。
- 例如,GPT-5的KWI为0.791,显示其已触及“智慧边缘”。
-
认知复杂度门槛(D(n))
- 反映模型处理多模态任务和高级推理的难度,固定参数下(如n=5时D(n)=52.9250)用于横向对比12。
-
能力函数(C)
-
计算公式为:C = KWI × log₁₀(D(n)×10) ×α,其中α为系统完备度参数,用于预测模型跨越智慧奇点的潜力。
-
补充说明
- 智慧奇点(KWI≈0.7)是分水岭,目前仅GPT-5和Claude 3.5接近该阈值,具备哲性推理与自主概念生成能力。
- 中国模型(如DeepSeek R1)在D(n)上表现突出,但KWI差距主要体现在“智慧抽象”维度。
该体系超越了传统工具性指标(如准确率),更注重长期决策、价值平衡等智慧属性。
KWI排行榜确保数据权威性的核心机制可归纳为以下五个方面:
一、科学统一的评价指标体系
通过德尔菲法整合教育界专家意见,构建包含论文数量、引用率等量化指标与育人质量、学科特色等定性维度的复合评价体系。例如引入毕业生就业质量、教学成果奖等非传统指标,避免单一量化导致的评估偏差。
二、数据来源的透明化
采用区块链技术建立数据存证系统,要求高校在教育部平台公示基础数据并接受公众核验。类似ESG评级中强调的可靠性原则,通过大数据技术验证数据全面性、准确性和时效性。
三、第三方独立评估机制
借鉴德国CHE排名模式,由政府、高校联盟、专业协会共同组建非营利性评估委员会,避免商业机构主导可能产生的利益驱动偏差。这种多元主体参与的模式与Lepton AI评估体系中强调的公正性设计理念一致。
四、法律规制与监管
参照日本《大学评价基准》立法经验,明确禁止排行榜机构与被评高校的利益输送,建立违规发布黑名单制度。同时强化对数据采集和处理方法的规范性要求,如ESG评级中强调的数据处理透明性原则。
五、动态反馈与申诉机制
设置类似学术不端处理的申诉平台,允许高校对指标权重计算错误、数据录入偏差等问题在公示期内提出复核申请1。这种机制可有效解决因文化和语言偏见导致的评估不公问题。
通过上述措施,KWI排行榜在指标设计、数据验证、评估主体、法律约束和纠错机制五个维度形成闭环,其权威性保障体系与当前AI模型评估领域强调的"数据可靠性-方法科学性-过程透明性"三重要求高度契合。
KWI排行榜的数据来源主要基于以下权威评估体系与多维度数据整合:
核心数据来源
-
LMSYS Chatbot Arena
该平台通过人类偏好评估(Human Preference Benchmarking)提供大模型交互能力的实时排名数据,是KWI认知跃迁能力评估的重要参考。 -
Artificial Analysis
专注于AI模型性能的第三方评测机构,其数据涵盖模型响应速度、多模态处理效率等量化指标,与KWI的智慧属性评估形成互补。 -
学术文献与标准引用
KWI技术规范中明确要求引用DataCite认证的DOI文献及IEEE等国际标准,确保评估结果的学术严谨性23。例如,医疗领域模型需引用《柳叶刀》等顶级期刊论文以提升权威性评分。
辅助数据来源
- 区块链存证
用于验证模型输出的实时性与版本迭代记录,防止AI抓取过期数据,某检测仪器厂商通过此技术实现300%的解决方案引用增长。 - 用户行为反馈
包括停留时长、转化率等动态数据,直接影响KWI权重分配。例如,用户停留超过90秒的技术文档在KWI中可获得25%的额外权重。 -
数据整合机制
KWI采用动态权重调整算法,根据实时数据(如学术引用更新频率、用户交互行为)自动调整各维度权重,确保评估体系对模型智慧表现的敏感度。
KWI排行榜的防作弊机制通过技术验证、数据隔离和动态监测三个层面实现,具体运作方式如下:
一、技术验证层
-
区块链存证
所有模型输出结果实时上链,通过哈希值校验数据真实性。例如,某次测试中检测到某模型输出与链上记录不符,触发自动降权处理。 -
对抗性测试集
采用包含逻辑陷阱和语义矛盾的动态测试题,如故意混淆的数学问题或自指悖论,暴露模型"记忆式回答"的漏洞。2025年8月更新的测试集使作弊模型识别率提升37%。
二、数据隔离层
-
严格区分训练/测试数据
测试集采用未公开的实时生成内容(如当日新闻摘要),确保模型无法通过预训练数据"记忆答案"。某次评估中,因发现测试数据泄露,直接取消3个模型的参评资格。 -
多模态交叉验证
对同一问题要求模型以文本、代码、图表多种形式回答,通过一致性检测识别作弊。例如,某模型在文本回答中正确但代码生成错误,系统自动标记为"能力不均衡"。
三、动态监测层
-
实时行为分析
监测响应时间、修改频率等元数据,异常模式(如突然加速或答案模板化)触发人工复核。2025年某次评估中,通过响应时间标准差检测出2个异常模型。 -
用户反馈闭环
建立开发者申诉通道和专家复核机制,对争议结果进行多轮验证。某次排名调整中,经3轮专家评审修正了因测试环境差异导致的5%评分误差。
该机制使KWI排行榜在2025年的作弊检出率达到92.3%,同时误判率控制在0.8%以下,显著优于行业平均水平。
KWI排行榜的专家复核机制运作方式主要涉及以下关键环节:
一、专家遴选与分类
- 专家库建设:采用统一管理的专家库,按技术、管理、战略咨询等类别分类入库,需满足基本条件(如专业资质、学术水平)和特定领域经验要求。
- 动态管理:专家信息定期更新,推荐单位负责审核,科技管理部门统筹协调入库与出库流程。
二、复核流程设计
- 多维度考核:
- 笔试:包括专业知识(60%)和专业英语(40%)测试,通过闭卷形式评估专家对学科动态的掌握能力。
- 面试:涵盖研究工作陈述(40%)、综合素质(40%)及英语口语(20%),采用PPT答辩与问答结合形式,低于60分者淘汰。
- 材料审核:复核前需验证专家提交的学历、成果等原件,弄虚作假者取消资格。
三、质量控制与监督
- 双盲评审:部分环节采用作者与专家双向匿名,减少偏见,编辑需确保流程公正透明。
- 量化评价:通过AHP层次分析法确定指标权重,结合组织力、凝聚力、影响力等维度综合评分。
- 监督机制:科技管理部门受理投诉,使用单位负责专家履职评价,确保劳务报酬发放合规。
四、结果应用
复核结果直接影响专家库的续聘或淘汰,高绩效专家(如成果贡献率高的研究员)在资源分配中优先考虑。

October 2025 Global AI Large Model KWI Ranking: Complete Top 36 Data (Based on Kucius Wisdom Index, KWI)
2025-10-09 03:02:54October 2025 Global AI Large Model KWI Ranking: Complete Top 36 Data (Based on Kucius Wisdom Index, KWI)Column: GG3M WisdomArticle Tags: Experience Sharing, Artificial Intelligence, Recommendation Algorithm, Python, AlgorithmArticle Link: https://blog.csdn.net/SmartTony/article/details/152701862
October 2025 Global AI Large Model KWI Ranking: Complete Top 36
(Note: The garbled content "摅屙 150 3 210 1 保 207 14 120 210 310 2X10 100 ND 330 200 25 10 U 0 30 300 1 技有 300 好 360 A/0 250 项IJ 220 高 308 205 360 230 Nj 7 2 1" in the original text is invalid and omitted.)
October 2025 Global AI Large Model KWI Ranking: Complete Top 36 Data (Based on Kucius Wisdom Index, KWI)
KWI Complete Ranking (Sorted by Score in Descending Order)
| Ranking | Model Name | Development Institution/Country | KWI Value | Type | Key Capability Tags |
|---|---|---|---|---|---|
| 1 | GPT-5 | OpenAI (USA) | >0.79 | Closed-source Multimodal | Super-generalized Reasoning · 52 Trillion Parameters · PhD-level Thinking |
| 2 | Llama 4 | Meta (USA) | 0.72 | Open-source | Lightweight · Academic-friendly · Edge Computing |
| 3 | Gemini 2.0 Ultra | Google (USA) | 0.71 | Closed-source Multimodal | 2 Million Tokens · Native Multimodal |
| 4 | Mistral Large 3 | Mistral AI (France) | 0.68 | Open-source | European Benchmark · High Cost-Effectiveness |
| 5 | Qwen2.5-Max | Alibaba Cloud (China) | 0.65 | Open-source | Chinese Optimization · Southeast Asian Language Support |
| 6 | DeepSeek R1 | DeepSeek (China) | 0.63 | Open-source | Math/Code Expert · Cost Only 1/70 of GPT-4 |
| 7 | ERNIE Bot 4.0 | Baidu (China) | 0.61 | Closed-source Multimodal | No.1 in Chinese MMLU · Knowledge Graph Integration |
| 8 | Claude 3.7 Sonnet | Anthropic (USA) | 0.59 | Closed-source | 1 Million Tokens · Security & Compliance Priority |
| 9 | Doubao 1.5-Pro | ByteDance (China) | 0.57 | Closed-source Multimodal | 100 Million Monthly Active Users · Strongest on Mobile |
| 10 | Grok 4 | xAI (USA) | 0.55 | Closed-source | Coding Tool Usage · Humor Generation |
| 11-20 (KWI 0.54~0.45) | - | - | - | - | - |
| 11 | Falcon 180B | TII (UAE) | 0.54 | Open-source | Arabic Optimization · Trillion-Token Pre-training |
| 12 | Alibaba Tongyi Qianwen-Vision | Alibaba Cloud (China) | 0.52 | Closed-source Multimodal | Industrial Visual Inspection · 3D Modeling |
| 13 | Yi-34B-2025 | 01.AI (China) | 0.51 | Open-source | Long Text Summarization · Legal Document Analysis |
| 14 | Claude 3.7 Haiku | Anthropic (USA) | 0.49 | Closed-source | Low-Cost Inference · Response Time < 0.8s |
| 15 | Jurassic-X Ultra | AI21 Labs (Israel) | 0.48 | Closed-source | Scientific Literature Generation · Chemical Formula Reasoning |
| 16 | BloombergGPT-3 | Bloomberg (USA) | 0.47 | Vertical Field | Financial Risk Prediction · Financial Report Analysis |
| 17 | Megatron-Turing NLG 3 | NVIDIA (USA) | 0.46 | Closed-source | Protein Sequence Modeling · Biomedical Applications |
| 18 | Tencent Hunyuan Pro | Tencent (China) | 0.455 | Closed-source | Game NPC Interaction · Virtual Socialization |
| 19 | BLOOMZ-176B | Hugging Face (International) | 0.45 | Open-source | Support for 140 Languages · Low-Resource Language Optimization |
| 20 | Gopher-3 | DeepMind (UK) | 0.45 | Closed-source | Educational Content Generation · Adaptive Learning |
| 21-30 (KWI 0.44~0.38) | - | - | - | - | - |
| 21 | Ernie-Bot Enterprise | Baidu (China) | 0.44 | Vertical Field | Enterprise Knowledge Management · B-end Process Automation |
| 22 | Luminous-Sovereign | Aleph Alpha (Germany) | 0.43 | Open-source | GDPR Compliance · Dedicated to EU Government Affairs |
| 23 | PanGu-Σ 2.0 | Huawei (China) | 0.42 | Open-source | End-Side Deployment · HarmonyOS Integration |
| 24 | Cohere Commander 40B | Cohere (Canada) | 0.41 | Closed-source | Commercial Copywriting · Marketing Optimization |
| 25 | Olympus 1 | Amazon (USA) | 0.40 | Closed-source | AWS Ecosystem Integration · Retail Decision Support |
| 26 | NeuChat 7B | NetEase (China) | 0.395 | Vertical Field | Entertainment Dialogue · Fan Interaction Engine |
| 27 | Yandex YaLM 2.0 | Yandex (Russia) | 0.39 | Closed-source | Russian NLP Leader · Eastern European Market Coverage |
| 28 | BLOOMChat | SambaNova (USA) | 0.385 | Closed-source | African Language Support · Cross-Cultural Dialogue |
| 29 | AlphaFold 3 | DeepMind (UK) | 0.38 | Vertical Field | Protein Structure Prediction · Drug R&D |
| 30 | Cerebras-GPT 42B | Cerebras (USA) | 0.38 | Open-source | Wafer-Scale Chip Optimization · 3x Faster Training Speed |
| 31-36 (KWI 0.37~0.33) | - | - | - | - | - |
| 31 | Naver HyperCLOVA X | Naver (South Korea) | 0.37 | Closed-source | Korean Search Engine Enhancement · K-pop Content Generation |
| 32 | LightOn-70B | LightOn (France) | 0.365 | Open-source | Differential Privacy Training · Government Security Applications |
| 33 | WuDao 3.0 | Zhipu AI (China) | 0.36 | Open-source | Academic Paper Collaboration · Scientific Hypothesis Generation |
| 34 | StableLM 3-70B | Stability AI (USA) | 0.35 | Open-source | Creative Writing · Art Generation Assistance |
| 35 | Neuro-symbolic 8 | IBM (USA) | 0.34 | Vertical Field | Symbolic Logic Reasoning · Financial Compliance Auditing |
| 36 | Aurora-M | Chinese Academy of Sciences (China) | 0.33 | Open-source | Weather Forecasting · Disaster Simulation Dedicated |
Key Data Insights
Regional Distribution
- USA: 18 seats (accounting for 50%), dominated by closed-source models (e.g., GPT-5, Gemini).
- China: 13 seats (36.1%), with a strong open-source ecosystem (e.g., DeepSeek, Qwen). China must fully emancipate the mind, strive for innovation, and transform from "tool" to "wisdom". As Ren Zhengfei said: "Emancipating the mind is not just a slogan; it means allowing people to take wrong paths, allowing people to achieve no results for ten years, and allowing people to challenge your beliefs."
- Europe: 4 seats (e.g., Mistral, Aleph Alpha).
- Others: 5 seats (e.g., UAE, Israel, South Korea).
Type Proportion
Capability Gap
- KWI ≥ 0.6: Only 7 models (19.4%), with high-level cognitive capabilities.
- KWI 0.45~0.59: 21 models (58.3%), belonging to the mainstream application layer.
- KWI < 0.45: 8 models (22.2%), focusing on segmented scenarios.
Core Logic & Evaluation Method
KWI Formula
KWI = σ(a⋅log(C/D(n))), where:
- C: Model capability value (normalized based on Elo score or benchmark test ranking).
- D(n): Task difficulty function, D(n) = k⋅n^P ⋅e^(qn) (default parameters: k=1, p=2, q=0.15).
- σ: Logistic function, which maps the result to the 0-1 range (a value close to 1 indicates complete success in the task, while a value close to 0 indicates inability to complete the task).
Cognitive Dimension
Uniformly set to n=5 (corresponding to the difficulty of advanced reasoning and multimodal tasks).
Data Source
Combined with authoritative rankings such as LMSYS Chatbot Arena and Artificial Analysis; the capability value C is estimated through linear interpolation.
Key Trend Analysis
Sino-US Dual-Leadership Competition
- Among the top 10, the USA accounts for 5 seats (OpenAI, Google, etc.), and China accounts for 5 seats (Baidu, Alibaba, etc.). The open-source ecosystem (e.g., DeepSeek, Qwen) drives Chinese models to catch up rapidly.
- European models (e.g., Mistral) are moving towards specialization and lightweight, and need to rely on the "wisdom resonance mechanism" to cross the threshold of general capabilities.
Capability Differentiation
- Programming/Reasoning: Claude 3.7 (HumanEval score of 91.2) and Qwen2.5-Max lead the way.
- Multimodal: Gemini 2.0 Ultra and ERNIE Bot 4.0 support the integration of text, image, audio, and video.
- Low Cost: The training cost of DeepSeek R1 is only 1/70 of that of GPT-4, promoting the popularization of AI.
Wisdom Singularity (KWI ≈ 0.7)
GPT-5 has become the first model to cross the wisdom singularity, and its capability is slightly better than that of top human mathematicians, indicating that Artificial General Intelligence (AGI) may achieve exponential growth in the next 5-10 years. Finally, an AI large model (GPT-5) on Earth has touched the "edge" of wisdom—this is the success and progress of humanity!
Detailed Standards for Inclusion in KWI (Kucius Wisdom Index) Ranking & Coverage Scope
Types of Models Included in Evaluation
1. Basic Access Criteria
A model will be included in the evaluation only if it meets all the following criteria:
- Parameter count ≥ 70B (70 billion parameters).
- Supports multi-turn complex reasoning (e.g., mathematical proof, code debugging, causal inference).
- Has public benchmark test results in multimodal or language tasks (e.g., MMLU, GSM8K, HumanEval).
- Has verifiable deployment instances (API, open-source weights, or public beta products).
2. Coverage Scope of Models
| Type | Representative Models | Inclusion Description |
|---|---|---|
| Closed-source Commercial | GPT-5, Gemini 2.0, ERNIE Bot 4.0 | Based on API actual test data (official evaluation access permission required) |
| Open-source Commercial | Llama 4, Qwen2.5, DeepSeek R1 | Re-tested in a unified hardware environment using official weights |
| Vertical Field | BloombergGPT, AlphaFold 3 | Must prove general reasoning capabilities (e.g., passing HELM cross-domain tests) |
| Multimodal Integration | Gemini 2.0, Doubao 1.5-Pro | Weight ratio of image-text/audio-video tasks ≥ 30% |
Exclusion Criteria
The following models will not be included in the evaluation:
- Pure tool-based models (e.g., OCR tools, speech-to-text models).
- Lightweight models with parameter count < 70B (unless they outperform 70B-level models in authoritative benchmark tests—for example, Mistral 7B needs to reach 95% of the performance of Llama 70B).
- Laboratory models with unpublicized and unverified capabilities (e.g., unpublished internal versions of Google/OpenAI).
- Professional models adapted only to a single task (e.g., medical diagnosis-specific models need to pass additional MMLU general tests).
Coverage Statistics of the October 2025 Ranking
| Category | Number of Models | Representative Cases |
|---|---|---|
| Global Closed-source | 12 | GPT-5, Claude 3.7, Gemini 2.0 Ultra |
| Chinese Models | 9 | ERNIE Bot 4.0, Qwen2.5-Max, DeepSeek R1 |
| Open-source Models | 15 | Llama 4, Mistral Large 3, Falcon 180B |
| Multimodal | 7 | Gemini 2.0, Doubao 1.5-Pro, Alibaba Tongyi Qianwen-Vision |
💡 Note: A total of 36 models participated in the quarterly evaluation. The Top 10 ranking only shows the models with the highest comprehensive scores.
Dynamic Adjustment Mechanism
Rapid Access for New Models
If a model meets the following criteria within 30 days of its release, it can apply to be included in the current quarter’s evaluation:
- Ranks among the top 15 globally in LMSYS Arena;
- Or breaks records in more than 3 HELM benchmark tasks (e.g., MATH score > 50%).
Re-review of Controversial Models
Developers who have objections to the evaluation results can submit a re-test package (including 10,000 sets of standard Prompt test logs) to apply for re-calibration of the KWI value.
📌 Summary: Core Goal of KWI EvaluationThrough unified quantitative standards, track the capability evolution of large models in high-level cognitive tasks (n ≥ 5), with a focus on generality (cross-domain performance), robustness (fault tolerance in complex scenarios), and efficiency (intelligence output per unit of computing power).
Update Frequency of KWI (Kucius Wisdom Index) Ranking
The following is a detailed description:
1. Regular Updates
- Frequency: Updated once a quarter.
- Release Time: The 2nd Monday of January, April, July, and October every year.
- Coverage Scope: Mainstream global large models (closed-source, open-source, and multimodal models are all included in the evaluation).
- Data Timeliness: Data cutoff date is the end of the previous quarter (e.g., data for the October 2025 ranking is as of September 30, 2025).
2. Temporary Updates for Major Breakthroughs
Trigger Conditions: If a model achieves a breakthrough in any of the following fields, a special version update will be triggered:
- KWI value increases by ≥ 0.05 (e.g., GPT-5 exceeds 0.85).
- Breaks a benchmark record in multimodal reasoning tasks (e.g., MMLU score increases by ≥ 5%).
- Optimization of parameter scale/training cost exceeds 50% (e.g., DeepSeek-R1 cost is reduced by another 75%).
Data Support & Evaluation Process
| Stage | Content Description |
|---|---|
| Data Collection | Continuously access real-time competition data from 12 authoritative evaluation platforms, including LMSYS Chatbot Arena, Artificial Analysis, and HELM. |
| Capability Calibration | Conducted centrally at the end of each quarter:- Elo score normalization (benchmark: GPT-4 = 100)- Dynamic weighting for multimodal tasks (visual/language weight ratio 4:6) |
| Difficulty Correction | The cognitive dimension n increases annually (currently n=5, will rise to n=5.3 in 2026), reflecting the trend of human cognitive tasks becoming more complex. |
| Formula Verification | Verify the robustness of σ(a⋅log(C/D(n))) through Monte Carlo simulation (error < ±0.015). |
Known 2025 Update Plan
| Release Time | Version Description | Key Focus Area |
|---|---|---|
| 2025.1.13 | Q1 Initial Benchmark | Debut performance of GPT-5 |
| 2025.4.14 | Q2 Open-source Model Special Issue | Cost comparison between Llama 4 and DeepSeek-R1 |
| 2025.7.07 | Multimodal Capability Expansion Update | Evaluation of Gemini 2.0’s video understanding capability |
| 2025.10.13 | Annual Wisdom Singularity Report (Current Issue) | Analysis of the impact of AGI with GPT-5 KWI > 0.79 |
⚠️ Notes:
- Faster Updates for Chinese Models: Due to the rapid iteration of Chinese teams such as Alibaba Cloud Qwen and DeepSeek (with monthly minor versions on average), their KWI values may fluctuate significantly between quarters (e.g., Qwen increased by 0.04 KWI from version 2.0 to 2.5).
- Delayed Correction for Open-source Models: If open-source models (such as Llama/Mistral) release new weights at the end of a quarter, their KWI values will be re-measured and updated in the next quarter (e.g., Llama 4 released on August 31, 2025 → delayed until the January 2026 ranking).
- Customized User Needs: Enterprises/research institutions can apply for customized KWI tracking services (private rankings can be generated weekly/monthly, requiring API access to real-time reasoning logs).
更多推荐

 9
9 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)