
【AI大模型前沿】HunyuanWorld-Voyager:腾讯开源的超长漫游世界模型,开启3D场景生成新纪元
HunyuanWorld-Voyager是腾讯基于其混元生态系统发布的最新成果,它能够从单张图片生成用户定义相机路径的3D点云序列,并支持沿着自定义相机轨迹进行世界探索的3D一致场景视频生成。这一模型不仅继承了混元世界模型1.0的图生世界能力,还进一步解决了“用户走出原视角之后”的补全问题。它在3D场景生成、视频重建、图像到3D生成、视频深度估计等多种3D理解和生成任务中都有着出色的表现。
系列篇章💥
目录
前言
在人工智能与3D技术飞速发展的今天,如何高效生成高质量的3D场景成为了众多研究人员和开发者关注的焦点。腾讯推出的HunyuanWorld-Voyager(以下简称Voyager)正是为解决这一问题而生。它作为业界首个支持原生3D重建的超长漫游世界模型,凭借其强大的功能和创新的技术,为3D场景生成领域带来了新的突破。
一、项目概述
HunyuanWorld-Voyager是腾讯基于其混元生态系统发布的最新成果,它能够从单张图片生成用户定义相机路径的3D点云序列,并支持沿着自定义相机轨迹进行世界探索的3D一致场景视频生成。这一模型不仅继承了混元世界模型1.0的图生世界能力,还进一步解决了“用户走出原视角之后”的补全问题。它在3D场景生成、视频重建、图像到3D生成、视频深度估计等多种3D理解和生成任务中都有着出色的表现。
二、核心功能
(一)从单张图片生成3D点云序列
Voyager能够根据用户定义的相机路径,从单张图片生成3D一致的点云序列,支持长距离的世界探索。这一功能使得用户可以仅通过一张图片,就能构建出一个可交互的3D世界,并且能够沿着自定义的路径进行探索。
(二)生成3D一致的场景视频
该模型可以沿着用户自定义的相机轨迹生成3D一致的场景视频,为用户提供沉浸式的3D场景漫游体验。生成的视频不仅在视觉上具有高度的逼真性,而且在空间结构上也保持了一致性。
(三)支持实时3D重建
生成的RGB和深度视频可直接用于高效的3D重建,无需额外的重建工具,实现从视频到3D模型的快速转换。这大大提高了3D重建的效率和精度。
(四)多种应用场景支持
Voyager适用于视频重建、图像到3D生成、视频深度估计等多种3D理解和生成任务,具有广泛的应用前景。无论是虚拟现实、增强现实、游戏开发,还是3D建模和动画制作,都能从中受益。
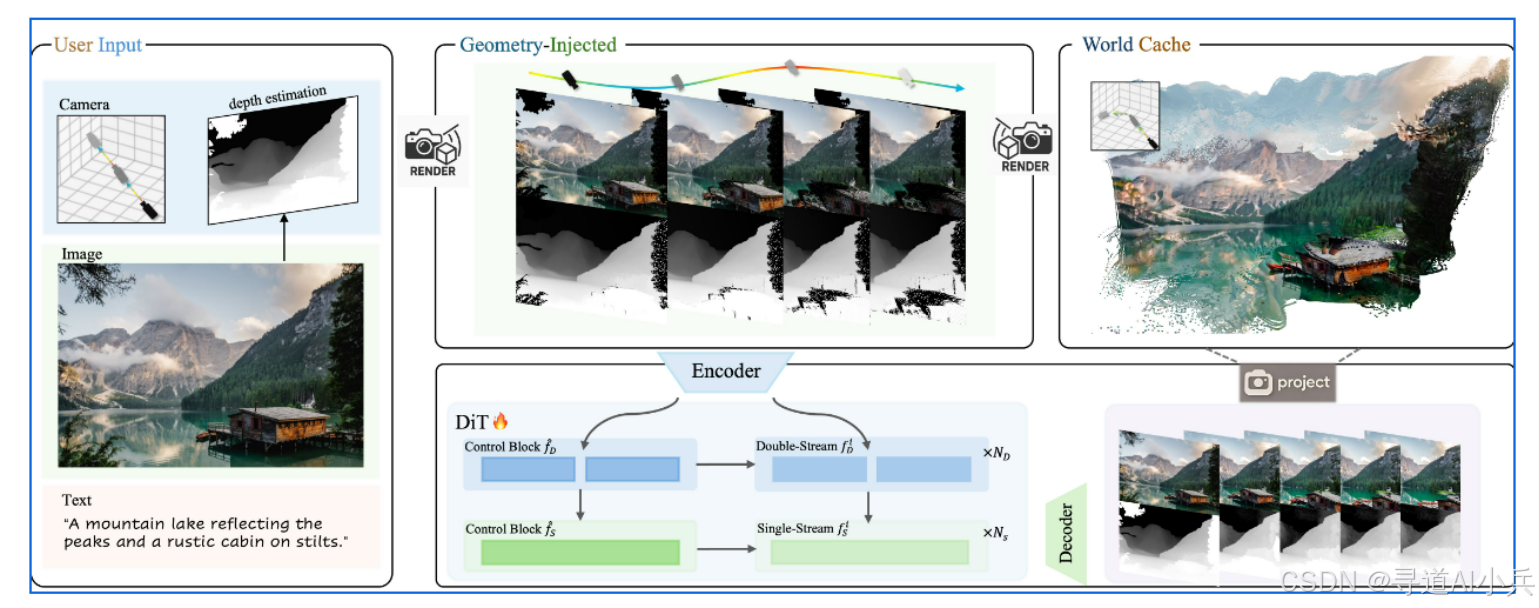
三、技术揭秘
(一)世界一致视频扩散
Voyager采用统一的架构,联合生成对齐的RGB和深度视频序列,通过条件于现有的世界观察来确保全局一致性。它首次在视频生成中引入RGB+Depth的双模态联合建模,形成“点云视频”,先在空间维度上拼接RGB和D(Depth),再在特征维度上结合两模态信息,用VAE框架学习RGB-D的生成规律。
(二)长距离世界探索
Voyager通过提出一种具备空间一致性的可拓展世界缓存机制,突破了长距离世界探索的限制。先生成一个初始场景点云缓存,再将缓存投影至用户设定的相机视角,利用扩散模型生成新视角画面,并不断更新缓存,最终形成一个支持任意相机轨迹的闭环系统。
(三)可扩展的数据引擎
为训练Voyager模型,腾讯构建了一套可扩展的数据构建引擎,可自动对任意输入视频估计相机姿态与时序信息,摆脱人工标注依赖,批量生成可用于RGB-D建模的训练样本。基于该引擎,Voyager融合真实视频与虚幻引擎合成数据,构建了包含超过10万段视频片段的大规模训练集。
四、性能表现
在斯坦福大学发布的WorldScore基准测试中,Voyager在多个关键指标上均取得了优异的成绩。其中,它在物体控制(66.92)、风格一致性(84.89)和主观质量(71.09)方面表现出色,尽管在摄像机控制(85.95)方面排名第二,落后于WonderWorld的92.98。具体表现如下表所示: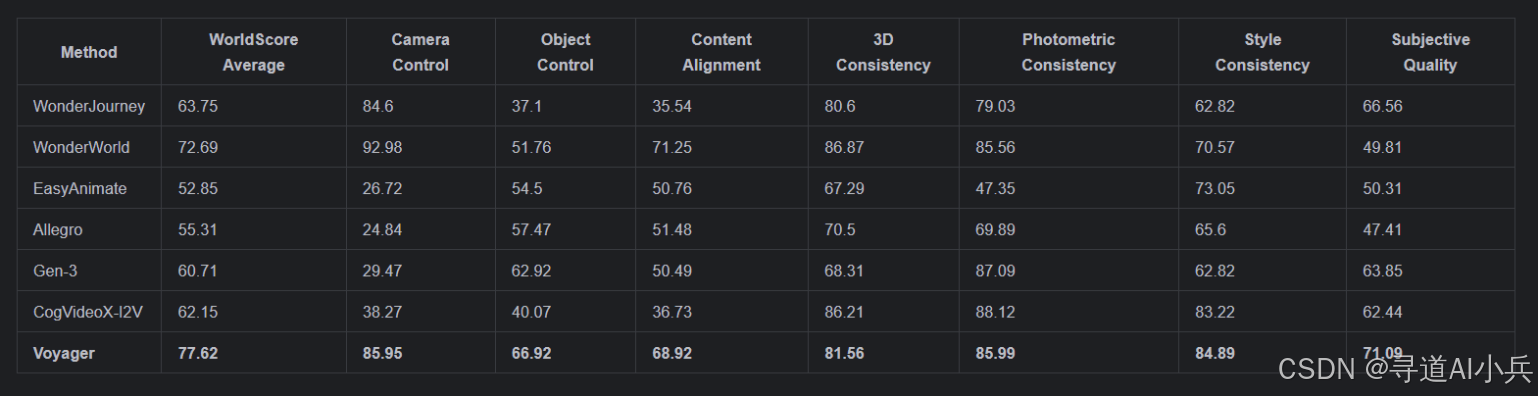
五、应用场景
(一)视频重建
Voyager通过生成对齐的RGB和深度视频,实现高效且直接的3D重建,无需额外的重建工具。生成的3D模型在几何一致性方面表现更为出色。
(二)图像到3D生成
从单张图片生成3D一致的点云序列,支持从2D图像到3D场景的转换,可用于虚拟场景的快速构建。生成的3D场景在细节和真实感上都优于现有的3D生成方法。
(三)视频深度估计
生成与RGB视频对齐的深度信息,可用于视频分析和3D理解任务。在用户研究中,Voyager的深度投影结果在户外场景中更受用户青睐。
(四)虚拟现实(VR)和增强现实(AR)
生成的3D场景和视频可用于创建沉浸式的VR体验或增强现实应用。为用户提供了更加真实和丰富的交互体验。
(五)游戏开发
生成的3D场景资产可无缝接入主流游戏引擎,为游戏开发提供丰富的创意和内容支持。降低了游戏开发中的美术和建模成本。
(六)3D建模和动画
生成的3D点云和视频可作为3D建模和动画制作的输入,提高创作效率。为3D艺术家和设计师提供了更加快速和便捷的创作工具。
六、快速使用
(一)硬件配置要求
Voyager需要强大的计算能力才能运行,540p分辨率至少需要60GB GPU内存,腾讯建议80GB以获得更好的结果。对于需要更快处理的用户,系统支持多GPU并行推理,八个GPU的处理速度比单GPU快6.69倍。
(二)安装依赖
# 1.克隆GitHub仓库
git clone https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager
cd HunyuanWorld-Voyager
# 2.创建虚拟环境
conda create -n voyager python==3.11.9
conda activate voyager
# 3. Install PyTorch and other dependencies using conda
# For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 4. 安装依赖
python -m pip install -r requirements.txt
python -m pip install transformers==4.39.3
# 5. Install flash attention v2 for acceleration (requires CUDA 11.8 or above)
python -m pip install flash-attn
# 6. Install xDiT for parallel inference (It is recommended to use torch 2.4.0 and flash-attn 2.6.3)
python -m pip install xfuser==0.4.2
(三)下载预训练模型
huggingface-cli download tencent/HunyuanWorld-Voyager --local-dir ./ckpts
(四)模型推理示例
cd HunyuanWorld-Voyager
python3 sample_image2video.py \
--model HYVideo-T/2 \
--input-path "examples/case1" \
--prompt "An old-fashioned European village with thatched roofs on the houses." \
--i2v-stability \
--infer-steps 50 \
--flow-reverse \
--flow-shift 7.0 \
--seed 0 \
--embedded-cfg-scale 6.0 \
--use-cpu-offload \
--save-path ./results
七、结语
HunyuanWorld-Voyager作为腾讯推出的一款具有创新性的超长漫游世界模型,凭借其强大的功能和卓越的性能,在3D场景生成领域展现出了巨大的潜力和应用价值。它不仅为研究人员和开发者提供了一个强大的工具,也为3D内容创作和相关行业的未来发展开辟了新的道路。相信随着技术的不断进步和应用的不断拓展,Voyager将在更多的领域发挥出更大的作用。
项目地址
- 项目官网:https://3d-models.hunyuan.tencent.com/world/
- GitHub仓库:https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager
- Hugging Face模型库:https://huggingface.co/tencent/HunyuanWorld-Voyager
- 技术报告:https://3d-models.hunyuan.tencent.com/voyager/voyager_en/assets/HYWorld_Voyager.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!
更多推荐

 37
37 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)