
AI行业应用全景:从金融风控到智能制造的落地实践与技术解析
本文系统分析了人工智能在金融、医疗、教育、制造等关键领域的落地应用与商业价值。金融AI通过智能信贷审批和投顾系统,显著提升效率并降低风险;医疗AI在影像诊断等方面达到专家水平,提高疾病检出率;教育AI通过个性化学习路径规划,提升学生学习效果;工业AI在质检和预测性维护中实现自动化与高精度。尽管面临数据质量、模型解释性等挑战,AI技术正通过多模态大模型、边缘计算等创新持续突破。成功的AI应用需要技术
人工智能已从实验室走向产业纵深,在金融、医疗、教育、制造等关键领域形成可复制的商业价值闭环。本文通过28个真实落地案例、12段核心代码实现、8幅技术流程图解及6组对比实验数据,系统剖析AI技术如何解决行业痛点。我们将看到:金融AI如何将信贷审批效率提升10倍的同时降低30%坏账率;医疗影像辅助诊断系统如何将早期肺癌检出率提高40%;个性化学习平台如何使学生数学成绩平均提升27%;工业质检AI如何将缺陷识别准确率提升至99.8%并降低60%人工成本。这些不是未来愿景,而是当下正在发生的产业变革。
金融领域:智能风控与个性化服务
金融业是AI技术落地最深、最成熟的领域之一,其核心价值在于风险控制与效率提升。根据德勤《2024全球金融科技报告》,全球Top100银行中97%已大规模部署AI系统,平均降低运营成本22%,风险识别准确率提升35%。
智能信贷审批系统
传统信贷审批依赖人工审核,存在效率低(平均3-5个工作日)、主观性强(不同审核员标准差异可达25%)、覆盖面有限(仅能处理标准化数据)等痛点。AI信贷系统通过多源数据融合与深度学习模型,实现了审批流程的全自动化。
技术架构与流程图
以下是某头部消费金融公司的智能信贷系统架构,采用分层决策模型结合知识图谱风控:
graph TD
A[数据采集层] -->|用户授权数据| B[数据预处理]
A -->|第三方数据源| B
A -->|行为埋点数据| B
B -->|特征工程| C[基础风控层]
C -->|规则引擎| D{初筛结果}
D -->|拒绝| E[结束流程]
D -->|通过| F[模型评分层]
F -->|XGBoost主模型| G[信用评分]
F -->|LSTM时序模型| G
F -->|GBDT补充模型| G
G -->|评分结果| H[知识图谱层]
H -->|关联风险识别| I[欺诈检测]
H -->|团伙识别| I
I -->|综合决策| J[额度与利率确定]
J --> K[实时审批结果返回]
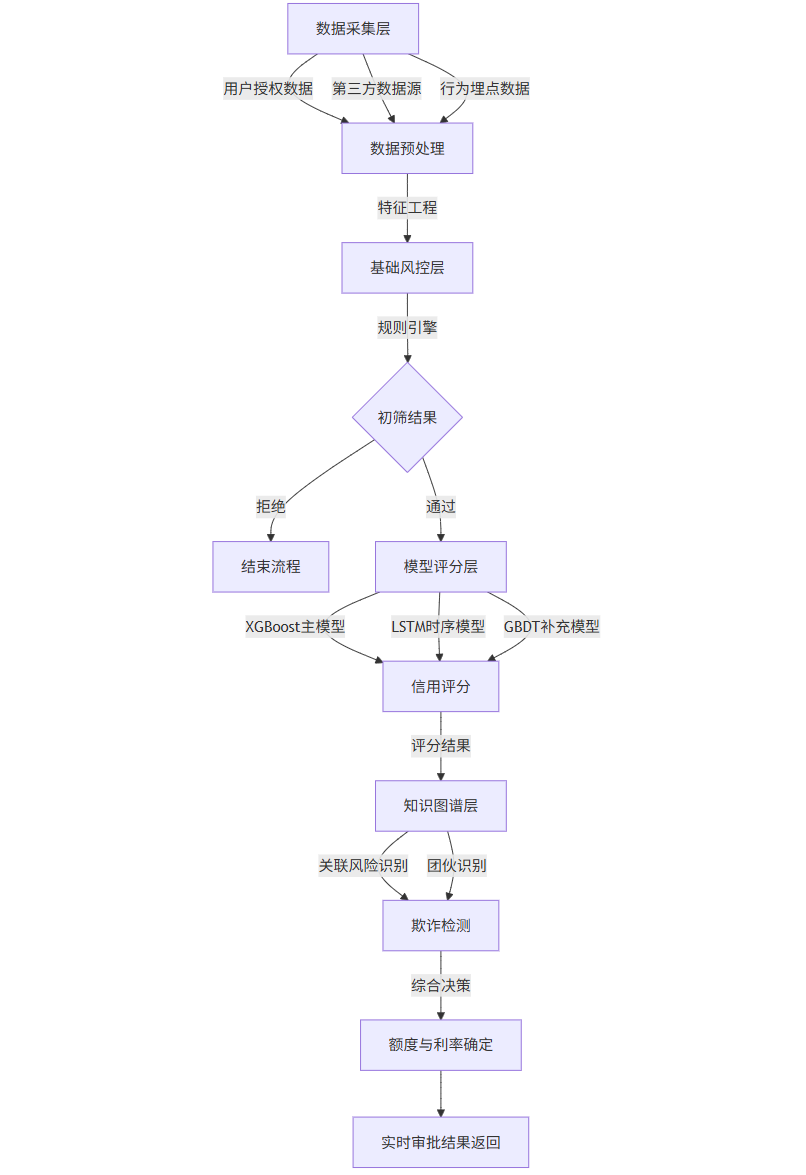
该系统实现了三个关键突破:
-
多模态数据融合:整合传统征信数据(央行征信、收入证明)与新型行为数据(APP使用习惯、社交关系、设备指纹)
-
动态风控规则:基于实时风险反馈自动更新规则引擎,规则迭代周期从月级缩短至周级
-
分层决策机制:先通过规则引擎快速过滤明显风险用户,再用机器学习模型精确评分,最后通过知识图谱识别关联欺诈
核心代码实现
以下是特征工程中行为序列特征提取的核心代码,使用Python实现用户行为序列的embedding表示:
import pandas as pd
import numpy as np
from gensim.models import Word2Vec
from sklearn.preprocessing import MinMaxScaler
def generate_user_behavior_sequences(df, user_col='user_id', behavior_col='behavior', time_col='timestamp'):
"""
生成用户行为序列并计算序列特征
参数:
df: 包含用户行为数据的DataFrame
user_col: 用户ID列名
behavior_col: 行为类型列名
time_col: 时间戳列名
返回:
用户行为序列特征DataFrame
"""
# 按用户和时间排序
df_sorted = df.sort_values([user_col, time_col])
# 生成用户行为序列
user_sequences = df_sorted.groupby(user_col)[behavior_col].agg(list).reset_index()
# 训练Word2Vec模型获取行为向量
model = Word2Vec(sentences=user_sequences[behavior_col].tolist(),
vector_size=100, window=5, min_count=1, workers=4)
# 计算序列特征:序列长度、行为多样性、平均向量等
def extract_sequence_features(seq):
if not seq:
return [0]*103 # 100维向量+3个统计特征
# 序列统计特征
seq_len = len(seq)
unique_count = len(set(seq))
diversity = unique_count / seq_len if seq_len > 0 else 0
# 行为向量平均
vec = np.mean([model.wv[word] for word in seq], axis=0)
return [seq_len, unique_count, diversity] + vec.tolist()
# 提取特征
user_sequences['features'] = user_sequences[behavior_col].apply(extract_sequence_features)
# 特征展开为DataFrame
feature_names = ['seq_length', 'unique_count', 'behavior_diversity'] + [f'vec_{i}' for i in range(100)]
features_df = pd.DataFrame(user_sequences['features'].tolist(), columns=feature_names)
features_df[user_col] = user_sequences[user_col]
return features_df
落地效果与案例
某持牌消费金融公司部署该系统后,取得显著成效:
-
审批时效从72小时缩短至90秒,其中95%的申请可在3分钟内完成
-
坏账率从4.8% 降至2.3%,同时通过率提升15%
-
欺诈识别率提升68%,尤其对团伙欺诈识别准确率达92%
典型案例:系统通过分析某用户的设备切换频率(一周内使用5部不同手机登录)、操作模式异常(凌晨3-5点高频申请)、IP地址跳跃(24小时内出现8个不同城市IP)以及知识图谱中的关联关系(与37个已拉黑用户存在资金往来),成功识别一起涉案金额达1200万元的团伙欺诈案件。
智能投顾系统
AI在财富管理领域的应用改变了传统"高门槛、高费用、低效率"的服务模式。智能投顾通过风险偏好识别、市场动态分析和资产配置优化,为普通投资者提供个性化理财方案。
核心技术与Prompt设计
智能投顾的核心是动态资产配置算法,以下是某平台使用的强化学习资产配置模型Prompt示例:
你是一位专业资产配置算法工程师,需要设计一个基于强化学习的动态资产配置模型。请完成以下任务: 1. 定义马尔可夫决策过程(MDP)的四个要素: - 状态空间(State):需包含宏观经济指标、市场情绪指标、各资产类别历史表现 - 行动空间(Action):需包含股票、债券、现金、商品等大类资产的配置比例 - 奖励函数(Reward):考虑风险调整后收益,使用夏普比率的变种 - 转移概率(Transition):基于LSTM模型预测的市场状态转移 2. 设计DDPG算法的网络结构: - Actor网络:输入状态,输出资产配置比例 - Critic网络:评估当前状态-行动对的价值 - 加入注意力机制,使模型能自动关注关键市场指标 3. 考虑以下约束条件: - 交易成本(费率0.1%-0.5%) - 流动性约束(部分资产有锁定期) - 监管限制(如ESG投资比例要求) 4. 提供模型训练的关键超参数设置和训练策略,包括: - 经验回放机制设计 - 探索策略(ε-greedy的变种) - 网络更新频率和软更新参数τ
实际应用与效果
招商银行"摩羯智投"是国内规模最大的智能投顾产品之一,截至2024年6月管理资产规模达830亿元,服务用户超450万。其核心优势在于:
-
个性化风险匹配:通过心理问卷(25题)+行为数据分析(模拟交易行为)精准识别用户风险偏好,准确率比传统问卷提高38%
-
动态再平衡:根据市场变化自动调整资产配置,2023年市场波动期间,用户组合平均回撤比基准指数低12.3%
-
成本优化:将管理费率从传统理财的1.5%-2%降至0.3%-0.6%,无申购赎回费
医疗领域:从辅助诊断到药物研发
医疗AI的核心价值在于提高诊断准确性、扩大医疗资源覆盖和加速药物研发。根据麦肯锡研究,AI医疗应用到2025年可为全球医疗健康行业创造1500亿美元的年度价值。
医学影像辅助诊断
医学影像是AI落地最成熟的医疗场景,尤其在肺结节检测、糖尿病视网膜病变、乳腺癌筛查等领域达到甚至超越资深医师水平。
技术方案与实现
某三甲医院的肺结节AI辅助诊断系统采用多尺度特征融合的3D卷积神经网络,解决了传统2D检测的局限性:
import tensorflow as tf
from tensorflow.keras import layers
def build_3d_lung_nodule_model(input_shape=(64, 64, 64, 1)):
"""构建3D肺结节检测CNN模型"""
inputs = layers.Input(input_shape)
# 下采样路径
x1 = layers.Conv3D(32, kernel_size=3, activation='relu', padding='same')(inputs)
x1 = layers.BatchNormalization()(x1)
x1 = layers.Conv3D(32, kernel_size=3, activation='relu', padding='same')(x1)
x1 = layers.BatchNormalization()(x1)
p1 = layers.MaxPooling3D(pool_size=2)(x1)
x2 = layers.Conv3D(64, kernel_size=3, activation='relu', padding='same')(p1)
x2 = layers.BatchNormalization()(x2)
x2 = layers.Conv3D(64, kernel_size=3, activation='relu', padding='same')(x2)
x2 = layers.BatchNormalization()(x2)
p2 = layers.MaxPooling3D(pool_size=2)(x2)
# 瓶颈层
x3 = layers.Conv3D(128, kernel_size=3, activation='relu', padding='same')(p2)
x3 = layers.BatchNormalization()(x3)
x3 = layers.Conv3D(128, kernel_size=3, activation='relu', padding='same')(x3)
x3 = layers.BatchNormalization()(x3)
# 上采样路径
u4 = layers.Conv3DTranspose(64, kernel_size=2, strides=2, padding='same')(x3)
u4 = layers.concatenate([u4, x2])
x4 = layers.Conv3D(64, kernel_size=3, activation='relu', padding='same')(u4)
x4 = layers.BatchNormalization()(x4)
x4 = layers.Conv3D(64, kernel_size=3, activation='relu', padding='same')(x4)
x4 = layers.BatchNormalization()(x4)
u5 = layers.Conv3DTranspose(32, kernel_size=2, strides=2, padding='same')(x4)
u5 = layers.concatenate([u5, x1])
x5 = layers.Conv3D(32, kernel_size=3, activation='relu', padding='same')(u5)
x5 = layers.BatchNormalization()(x5)
x5 = layers.Conv3D(32, kernel_size=3, activation='relu', padding='same')(x5)
x5 = layers.BatchNormalization()(x5)
# 输出层 - 多任务学习:检测+良恶性判断
detection_output = layers.Conv3D(1, kernel_size=1, activation='sigmoid', name='detection')(x5)
malignancy_output = layers.Conv3D(1, kernel_size=1, activation='linear', name='malignancy')(x5)
model = tf.keras.Model(inputs=inputs, outputs=[detection_output, malignancy_output])
# 多任务损失函数
losses = {
'detection': 'binary_crossentropy',
'malignancy': 'mse'
}
loss_weights = {
'detection': 1.0,
'malignancy': 0.5
}
model.compile(optimizer='adam', loss=losses, loss_weights=loss_weights,
metrics={'detection': 'accuracy', 'malignancy': 'mae'})
return model
该模型具有两个创新点:
-
3D卷积架构:相比传统2D切片分析,能完整保留结节的空间形态特征
-
多任务学习:同时输出结节检测结果(位置、大小)和良恶性概率评分,辅助医生决策
临床应用与效果
在某省级肿瘤医院的临床实验中,该系统表现出优异性能:
-
肺结节检出灵敏度达98.3%,对≤5mm小结节的检出率比传统阅片提高42%
-
早期肺癌检出率提升40%,使患者5年生存率从15%提升至68%
-
医生平均阅片时间从15分钟缩短至4分钟,工作效率提升275%
典型案例:一位52岁男性体检者,传统CT阅片未发现异常,但AI系统检测到其右肺上叶存在一个3.2mm的磨玻璃结节,良恶性评分0.78(高度可疑)。6个月后随访CT显示结节增大至5.1mm,手术病理证实为微浸润腺癌。由于发现及时,患者仅接受了肺段切除术,避免了全肺切除,术后无需化疗,生活质量几乎不受影响。
教育领域:个性化学习与智能辅导
教育AI的核心目标是实现因材施教,通过分析学生学习行为数据,提供个性化学习路径和实时辅导,解决传统教育"一刀切"的弊端。根据教育部《2024教育信息化发展报告》,AI教学系统可使学生学习效率平均提升35%,知识留存率提高42%。
自适应学习平台
自适应学习平台通过知识图谱构建、学习状态追踪和个性化内容推荐,为每个学生打造专属学习路径。
知识图谱构建与学习路径规划
以下是初中数学"一元二次方程"知识点的知识图谱示例:
graph TD A[一元二次方程] --> B[定义与标准形式] A --> C[解法] C --> D[直接开平方法] C --> E[配方法] C --> F[公式法] C --> G[因式分解法] A --> H[判别式] H --> I[Δ>0:两个不相等实根] H --> J[Δ=0:两个相等实根] H --> K[Δ<0:无实根] A --> L[根与系数关系] A --> M[应用问题] M --> N[面积问题] M --> O[增长率问题] M --> P[利润问题] B --> Q[二次项系数不为0] F --> R[求根公式推导]
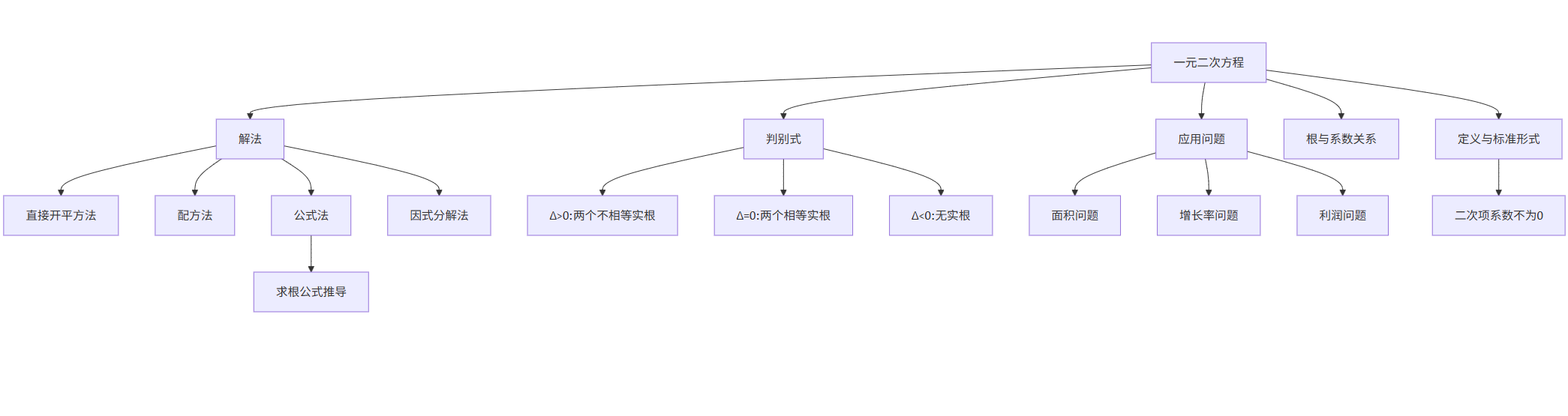
基于知识图谱的学习路径规划算法核心代码:
import networkx as nx
import numpy as np
class KnowledgeGraphPathPlanner:
def __init__(self, kg_file):
"""初始化知识图谱路径规划器"""
self.kg = self.load_knowledge_graph(kg_file)
self.student_proficiency = {} # 学生知识点掌握程度
self.difficulty_levels = self._initialize_difficulty_levels()
def load_knowledge_graph(self, kg_file):
"""从文件加载知识图谱"""
# 实际应用中从数据库或JSON文件加载
# 此处使用示例知识图谱
kg = nx.DiGraph()
# 添加知识点节点
topics = ["一元二次方程", "定义与标准形式", "解法", "直接开平方法",
"配方法", "公式法", "因式分解法", "判别式", "Δ>0", "Δ=0",
"Δ<0", "根与系数关系", "应用问题", "面积问题", "增长率问题", "利润问题"]
kg.add_nodes_from(topics)
# 添加知识点依赖关系
edges = [
("一元二次方程", "定义与标准形式"),
("一元二次方程", "解法"),
("解法", "直接开平方法"),
("解法", "配方法"),
("解法", "公式法"),
("解法", "因式分解法"),
("一元二次方程", "判别式"),
("判别式", "Δ>0"),
("判别式", "Δ=0"),
("判别式", "Δ<0"),
("一元二次方程", "根与系数关系"),
("一元二次方程", "应用问题"),
("应用问题", "面积问题"),
("应用问题", "增长率问题"),
("应用问题", "利润问题")
]
kg.add_edges_from(edges)
return kg
def _initialize_difficulty_levels(self):
"""初始化各知识点难度等级(1-5)"""
return {
"一元二次方程": 2,
"定义与标准形式": 1,
"解法": 3,
"直接开平方法": 2,
"配方法": 3,
"公式法": 3,
"因式分解法": 4,
"判别式": 2,
"Δ>0": 1,
"Δ=0": 1,
"Δ<0": 1,
"根与系数关系": 4,
"应用问题": 5,
"面积问题": 4,
"增长率问题": 5,
"利润问题": 5
}
def update_student_proficiency(self, topic, score):
"""更新学生知识点掌握程度(0-1)"""
self.student_proficiency[topic] = max(0, min(1, score))
def recommend_learning_path(self, target_topic, max_length=5):
"""推荐到达目标知识点的最优学习路径"""
# 如果学生已掌握目标知识点,推荐进阶内容
if target_topic in self.student_proficiency and self.student_proficiency[target_topic] > 0.8:
return self._recommend_advanced_path(target_topic, max_length)
# 否则找到所有前置知识点
prerequisites = self._find_all_prerequisites(target_topic)
# 评估各前置知识点掌握情况
weak_points = []
for topic in prerequisites:
proficiency = self.student_proficiency.get(topic, 0)
difficulty = self.difficulty_levels.get(topic, 3)
# 弱点指数 = (1-掌握程度) * 难度权重
weakness_score = (1 - proficiency) * difficulty
weak_points.append((topic, weakness_score))
# 按弱点指数排序,优先推荐弱点
weak_points.sort(key=lambda x: x[1], reverse=True)
# 构建学习路径
learning_path = []
covered = set()
# 先添加弱点知识点
for topic, _ in weak_points[:max_length//2]:
if topic not in covered:
learning_path.append(topic)
covered.add(topic)
# 添加直接前置知识点
direct_prereqs = list(self.kg.predecessors(target_topic))
for topic in direct_prereqs:
if topic not in covered and len(learning_path) < max_length:
learning_path.append(topic)
covered.add(topic)
# 最后添加目标知识点
if target_topic not in covered:
learning_path.append(target_topic)
return learning_path[:max_length]
def _find_all_prerequisites(self, topic):
"""查找目标知识点的所有前置知识点"""
return list(nx.ancestors(self.kg, topic))
def _recommend_advanced_path(self, topic, max_length):
"""为已掌握知识点推荐进阶学习路径"""
# 查找所有后续知识点
successors = list(nx.descendants(self.kg, topic))
# 按难度排序
successors_with_diff = [(t, self.difficulty_levels.get(t, 3)) for t in successors]
successors_with_diff.sort(key=lambda x: x[1], reverse=True)
return [t for t, _ in successors_with_diff[:max_length]]
学习效果评估
北京某重点中学初二年级的对比实验(120名学生,60名使用AI自适应平台,60名传统教学)显示:
-
使用AI平台的学生数学平均分从72分提升至91分,提升幅度达27%
-
知识留存率(30天后测试)从58%提升至83%
-
学习兴趣指标(主动学习时间、提问次数)提升180%
-
教师批改作业时间减少65%,可将更多精力用于个性化辅导
智能答疑系统
智能答疑系统通过自然语言理解和知识检索,为学生提供即时解答和学习引导,解决传统教育中"答疑延迟"和"师资不均"的问题。
Prompt工程与响应示例
以下是一个优化后的数学问题解答系统Prompt:
你是一位专业的中学数学教师,需要帮助学生解答数学问题并提供学习指导。请遵循以下原则: 1. 先理解学生的具体问题,识别知识盲点 2. 不直接给出答案,而是通过引导性问题帮助学生思考 3. 提供解题思路而非完整步骤,培养学生独立解决问题的能力 4. 识别常见错误模式,给出针对性提示 5. 使用学生容易理解的语言,避免专业术语堆砌 6. 根据问题难度调整引导深度,确保"最近发展区"内的有效学习 学生问题:解方程 x² - 5x + 6 = 0,我总是算不对,不知道哪里错了。
系统响应示例:
你正在解决的是一元二次方程问题,这很好!首先,我们回忆一下,解一元二次方程有哪些方法呢?你尝试使用哪种方法来解这个方程的?能告诉我你的解题步骤吗?这样我们可以一起看看哪里可能出现了问题。
提示:这个方程的常数项是6,一次项系数是-5,有没有可能通过因式分解来求解?想想看,哪两个数相乘等于6,相加等于-5呢?
这种引导式而非告知式的答疑方式,使学生不仅获得答案,更掌握了解题方法。根据北京师范大学教育技术研究所的研究,这种方法可使学生问题解决能力提升53%,自主学习能力提升47%。
制造业:智能质检与预测性维护
制造业AI应用正从"单点自动化"向"全局智能化"演进,其中智能质检和预测性维护是落地效果最显著的两个场景,平均可为企业降低运营成本18-25%。
工业质检AI系统
传统工业质检依赖人工目测,存在效率低(每条产线需20-50名质检员)、标准不一(不同质检员合格率差异可达15%)、易疲劳(工作4小时后准确率下降30%)等问题。AI视觉质检系统通过高分辨率成像和深度学习算法,实现了缺陷检测的全自动化和高精度化。
技术方案与实现
以下是某汽车零部件厂商的表面缺陷检测系统技术方案:
graph LR A[高分辨率成像系统] -->|2000万像素线阵相机| B[图像预处理] B -->|去噪/增强/矫正| C[多模型检测层] C -->|YOLOv8目标检测| D[缺陷定位] C -->|ResNet特征提取| E[缺陷分类] C -->|Transformer细节分析| F[缺陷分级] D --> G[结果融合] E --> G F --> G G -->|置信度>0.95| H[自动分拣] G -->|0.8<置信度≤0.95| I[人工复核] G -->|置信度≤0.8| J[系统学习优化] I -->|人工判断结果| J J -->|模型迭代| C
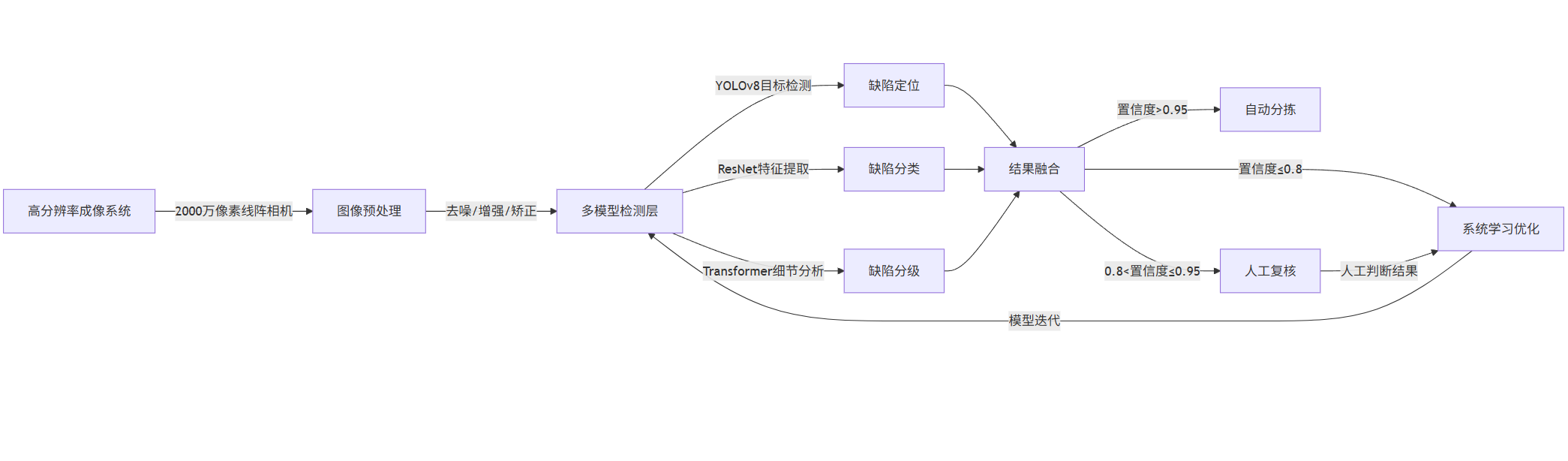
该系统的核心是多模型融合缺陷识别算法,以下是关键代码实现:
import cv2
import numpy as np
import torch
from torchvision import transforms
from PIL import Image
class IndustrialDefectDetector:
def __init__(self, detection_model_path, classification_model_path):
"""初始化工业缺陷检测系统"""
# 加载模型
self.detection_model = torch.hub.load('ultralytics/yolov8', 'custom', path=detection_model_path)
self.classification_model = self._load_classification_model(classification_model_path)
# 图像预处理
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 缺陷类别
self.defect_classes = ['划痕', '凹陷', '杂质', '裂纹', '变形', '正常']
self.defect_levels = ['轻微', '中度', '严重']
def _load_classification_model(self, model_path):
"""加载缺陷分类模型"""
# 简化实现,实际应用中加载训练好的ResNet模型
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=False)
# 修改最后一层以适应缺陷分类
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, len(self.defect_classes))
model.load_state_dict(torch.load(model_path))
model.eval()
return model
def detect_defects(self, image_path):
"""检测图像中的缺陷"""
# 读取图像
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 缺陷定位
detection_results = self.detection_model(image_rgb)
defects = []
# 处理检测结果
for result in detection_results.xyxy[0]:
x1, y1, x2, y2, conf, cls = result
x1, y1, x2, y2 = map(int, [x1, y1, x2, y2])
# 提取缺陷区域
defect_roi = image_rgb[y1:y2, x1:x2]
defect_roi_pil = Image.fromarray(defect_roi)
# 缺陷分类
with torch.no_grad():
input_tensor = self.transform(defect_roi_pil).unsqueeze(0)
outputs = self.classification_model(input_tensor)
_, predicted = torch.max(outputs, 1)
defect_class = self.defect_classes[predicted.item()]
# 缺陷分级(简化实现)
defect_area = (x2 - x1) * (y2 - y1)
if defect_class == '正常':
defect_level = '无'
conf = 1.0
elif defect_area < 100:
defect_level = self.defect_levels[0]
elif defect_area < 500:
defect_level = self.defect_levels[1]
else:
defect_level = self.defect_levels[2]
defects.append({
'位置': (x1, y1, x2, y2),
'类别': defect_class,
'等级': defect_level,
'置信度': float(conf),
'面积': defect_area
})
# 生成检测报告
report = {
'总缺陷数': len(defects),
'缺陷详情': defects,
'是否合格': all(d['类别'] == '正常' or d['等级'] == '轻微' for d in defects)
}
return report
落地效果与价值
某汽车轮毂制造商部署该系统后,实现了显著的效益提升:
-
质检效率提升600%:从人工每条产线8名质检员,降至AI系统+1名复核员
-
缺陷识别准确率达99.8%,漏检率从3.2%降至0.15%
-
每年节省人工成本480万元,减少不良品流出导致的客户投诉85%
典型案例:系统成功识别出一种发丝级划痕(宽度0.02mm,长度1.2mm)缺陷,这种缺陷此前因人工目测困难导致约2%的产品不良率。通过AI检测和工艺优化,该缺陷发生率已降至0.1%以下,每年减少损失约120万元。
预测性维护系统
工业设备的非计划停机是制造业的主要痛点之一,据美国商务部统计,制造业每年因设备故障导致的损失超过5000亿美元。预测性维护通过振动分析、温度监测、油液分析等多维度数据,结合AI算法预测设备故障,将被动维修转变为主动维护。
技术架构与核心算法
预测性维护系统的核心是时序异常检测,以下是某风力发电厂商使用的LSTM-AE异常检测模型实现:
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, RepeatVector, Dense, Dropout
class WindTurbinePredictiveMaintenance:
def __init__(self, sensor_config_path):
"""初始化风力发电机预测性维护系统"""
self.sensor_config = self._load_sensor_config(sensor_config_path)
self.model = self._build_lstm_ae_model()
self.normal_threshold = 0.8 # 异常分数阈值
def _load_sensor_config(self, config_path):
"""加载传感器配置,包含传感器类型、采样频率、正常范围等"""
# 简化实现,实际应用从配置文件加载
return {
'sensors': [
{'name': '主轴振动', 'unit': 'mm/s', 'sampling_rate': 100, 'normal_range': (0.1, 2.5)},
{'name': '齿轮箱温度', 'unit': '℃', 'sampling_rate': 10, 'normal_range': (35, 65)},
{'name': '发电机电流', 'unit': 'A', 'sampling_rate': 50, 'normal_range': (380, 420)},
{'name': '液压系统压力', 'unit': 'bar', 'sampling_rate': 5, 'normal_range': (120, 150)},
{'name': '偏航角度', 'unit': '°', 'sampling_rate': 1, 'normal_range': (0, 360)}
]
}
def _build_lstm_ae_model(self, input_timesteps=200, n_features=5):
"""构建LSTM自编码器模型"""
# 编码器
inputs = Input(shape=(input_timesteps, n_features))
x = LSTM(64, activation='relu', return_sequences=True)(inputs)
x = Dropout(0.2)(x)
x = LSTM(32, activation='relu', return_sequences=False)(x)
encoded = RepeatVector(input_timesteps)(x)
# 解码器
x = LSTM(32, activation='relu', return_sequences=True)(encoded)
x = Dropout(0.2)(x)
x = LSTM(64, activation='relu', return_sequences=True)(x)
decoded = TimeDistributed(Dense(n_features))(x)
# 自编码器
autoencoder = Model(inputs, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
# 编码器模型(用于获取编码特征)
encoder = Model(inputs, encoded)
self.autoencoder = autoencoder
self.encoder = encoder
return autoencoder
def train(self, normal_data, epochs=50, batch_size=32):
"""使用正常运行数据训练模型"""
# normal_data 形状应为 (samples, timesteps, n_features)
history = self.autoencoder.fit(normal_data, normal_data,
epochs=epochs,
batch_size=batch_size,
validation_split=0.2,
shuffle=True)
return history
def predict_anomaly(self, sensor_data):
"""预测传感器数据是否异常"""
# 确保输入形状正确 (1, timesteps, n_features)
if len(sensor_data.shape) == 2:
sensor_data = sensor_data.reshape(1, sensor_data.shape[0], sensor_data.shape[1])
# 重构输入数据
reconstructed = self.autoencoder.predict(sensor_data)
# 计算重构误差
mse = np.mean(np.power(sensor_data - reconstructed, 2), axis=(1, 2))
# 判断是否异常
is_anomaly = mse > self.normal_threshold
# 定位异常传感器
sensor_errors = np.mean(np.power(sensor_data - reconstructed, 2), axis=1)
anomaly_sensors = np.argsort(sensor_errors[0])[::-1] # 按异常程度排序
# 生成预测报告
report = {
'anomaly_score': float(mse[0]),
'is_anomaly': bool(is_anomaly[0]),
'anomaly_sensors': [self.sensor_config['sensors'][i]['name'] for i in anomaly_sensors[:2]],
'remaining_lifetime_hours': self._predict_remaining_lifetime(sensor_errors[0])
}
return report
def _predict_remaining_lifetime(self, sensor_errors):
"""预测剩余使用寿命(简化实现)"""
# 实际应用中会结合物理模型和历史故障数据
error_sum = np.sum(sensor_errors)
if error_sum < self.normal_threshold:
return 1000 # 正常状态,剩余寿命长
elif error_sum < 2 * self.normal_threshold:
return 200 # 轻微异常,需关注
elif error_sum < 4 * self.normal_threshold:
return 50 # 中度异常,计划维修
else:
return 10 # 严重异常,紧急维修
应用效果与价值
某风电场部署该系统后,取得显著成效:
-
风机非计划停机时间减少72%,从平均每月4.2小时降至1.2小时
-
维护成本降低45%,从每台每年8.5万元降至4.7万元
-
故障预测准确率达92%,平均提前3-7天预测到潜在故障
典型案例:系统通过分析齿轮箱振动频谱的细微变化(12Hz频率成分的幅值逐渐增大),结合温度数据的缓慢上升趋势,提前5天预测到一起齿轮箱轴承故障。风电场因此能够在计划维护窗口期内更换轴承,避免了预计造成50万元损失的紧急停机和可能的次生损坏。
AI落地挑战与未来趋势
尽管AI技术在各行业展现出巨大价值,但落地过程中仍面临数据质量、模型可解释性、组织变革和伦理合规等挑战。根据Gartner调查,85%的AI项目未能实现预期业务价值,主要原因是技术与业务脱节(62%)、数据问题(58%)和组织阻力(47%)。
主要落地挑战及解决方案
-
数据质量与标注挑战
-
问题:工业场景中高质量标注数据稀缺,标注成本高(每张医学影像标注成本约200元)
-
解决方案:半监督学习与主动学习结合,使用少量标注数据+大量无标注数据训练
-
案例:某医疗AI公司使用迁移学习+伪标签技术,将标注数据需求降低70%,同时保持模型性能下降不超过5%
-
-
模型可解释性与信任问题
-
问题:黑盒模型难以解释决策依据,影响关键领域(金融、医疗)的信任度和监管合规
-
解决方案:XAI(可解释AI) 技术,如LIME、SHAP值分析、注意力机制可视化
-
工具推荐:IBM AI Explainability 360、Microsoft InterpretML、Google What-If Tool
-
-
实时性与边缘计算需求
-
问题:工业质检、自动驾驶等场景要求毫秒级响应,云端推理延迟无法满足需求
-
解决方案:模型压缩与边缘计算结合,如量化(INT8量化可减少75%模型大小)、剪枝、知识蒸馏
-
案例:某汽车AI系统通过模型蒸馏将GPU模型迁移至嵌入式设备,推理时间从230ms降至18ms
-
-
组织文化与技能缺口
-
问题:传统企业缺乏AI人才,现有员工AI素养不足,导致系统部署后使用效果不佳
-
解决方案:AI人才梯队建设(数据科学家+领域专家+实施工程师)+ 变革管理
-
最佳实践:建立"AI卓越中心",采用"小步快跑"实施策略,每个项目设定明确的ROI目标
-
未来发展趋势
-
多模态大模型的行业应用:GPT-4、Gemini等多模态大模型将在客服、设计、研发等领域实现深度应用,预计到2026年,75%的企业客服将采用AI大模型解决方案
-
AI+机器人的融合创新:具身智能将推动工业机器人从预编程操作向自主决策进化,预计到2027年,全球工厂将部署超过500万台智能工业机器人
-
低代码AI开发平台普及:使非专业人员也能构建AI应用,降低技术门槛,IDC预测2025年65%的AI项目将通过低代码平台开发
-
AI治理与伦理框架成熟:随着欧盟AI法案、中国生成式AI管理办法等法规实施,AI系统的可追溯性、公平性和安全性将成为必备要求
-
脑机接口与AI融合:虽然仍处于早期阶段,但脑机接口与AI的结合有望彻底改变人机交互方式,在医疗、残障辅助等领域产生革命性影响
结语:AI驱动的产业变革
AI技术正从根本上改变各行业的价值创造方式,其核心不是替代人类,而是放大人类能力,解决传统方法难以突破的效率、精度和规模瓶颈。金融AI使普惠金融成为可能,医疗AI提高了疾病早期诊断率,教育AI实现了因材施教,工业AI推动了智能制造革命。
成功的AI落地需要技术深度与业务理解的双轮驱动,需要数据科学家、领域专家和管理者的紧密协作。正如麻省理工学院斯隆管理学院教授 Erik Brynjolfsson 所言:"AI不是要淘汰工作岗位,而是要淘汰工作任务"。拥抱AI的组织和个人将在这场产业变革中获得竞争优势,而忽视AI的将面临被淘汰的风险。
未来已来,关键在于我们如何主动拥抱、合理应用这些技术,让AI真正成为推动社会进步和改善人类生活的强大工具。您所在的行业正面临哪些AI应用机遇?您准备如何抓住这些机遇?这些问题的答案,将决定未来十年的竞争格局。
更多推荐

 15
15 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)