
计算机毕业设计对标硕论DeepSeek大模型+知识图谱Neo4J电商商品推荐系统 SpringBoot+Vue.js
计算机毕业设计对标硕论DeepSeek大模型+知识图谱Neo4J电商商品推荐系统 SpringBoot+Vue.js
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《DeepSeek大模型+知识图谱Neo4J电商商品推荐系统》的任务书框架,结合深度语义理解与图结构化知识推理,实现个性化推荐:
任务书:DeepSeek大模型+知识图谱Neo4J电商商品推荐系统开发
——基于语义理解与图神经网络的混合推荐引擎
一、项目背景与目标
- 背景
- 传统电商推荐系统依赖协同过滤(CF)或简单内容匹配,存在冷启动问题(新用户/商品无行为数据)和语义鸿沟(如“运动鞋”与“篮球鞋”关联性未被显式建模)。
- DeepSeek大模型(如DeepSeek-V2/R1)具备强大的自然语言理解能力,可解析用户查询的深层意图(如“送男友的生日礼物”隐含“男性、实用、仪式感”需求)。
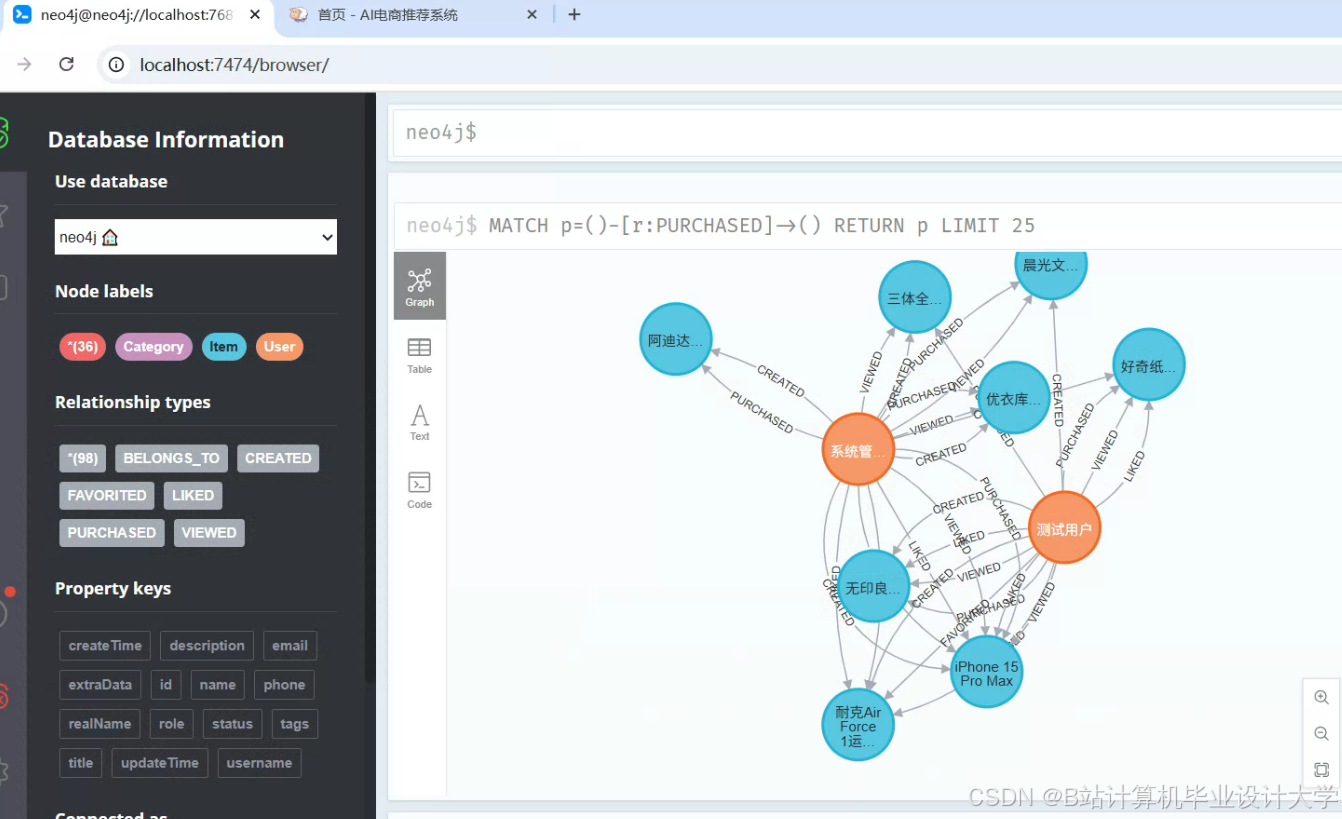
- Neo4J知识图谱能存储商品、用户、品牌、场景等实体及其关系(如“用户A→购买→商品B→属于→品类C→适用场景→户外运动”),支持可解释性推荐。
- 目标
- 构建混合推荐系统,融合DeepSeek的语义理解与Neo4J的图推理能力,实现:
- 多模态推荐:支持文本查询(“夏季透气跑鞋”)、图像搜索(上传鞋款图片找相似)、历史行为推荐。
- 动态场景适配:根据用户当前上下文(时间、地点、设备)调整推荐策略(如雨天推荐防水鞋)。
- 可解释性输出:生成推荐理由(如“根据您浏览的‘登山装备’和‘防水性能’需求,推荐此款冲锋衣”)。
- 构建混合推荐系统,融合DeepSeek的语义理解与Neo4J的图推理能力,实现:
二、任务分解与分工
模块1:数据治理与知识图谱构建
负责人:数据工程组
任务内容:
- 数据源整合:
- 结构化数据:商品属性(品牌、价格、材质)、用户行为(点击、购买、收藏)、订单信息。
- 非结构化数据:商品详情页文本、用户评价、客服对话记录。
- 外部数据:天气API(实时气温/降水)、节假日日历(促销场景触发)。
- 知识图谱设计:
- 实体类型:用户、商品、品类、品牌、场景、属性(如颜色、尺寸)。
- 关系类型:
- 用户行为:
购买、收藏、差评。 - 商品关联:
替代品(如“iPhone 14”→替代→“iPhone 13”)、互补品(如“手机”→互补→“手机壳”)。 - 语义关联:
适用场景(“运动鞋”→适用→“跑步”)、属性相似(“棉质T恤”→材质相似→“麻质衬衫”)。
- 用户行为:
- 图谱构建流程:
- 使用OpenIE(斯坦福开放信息抽取)从文本中提取三元组(如“这款耳机支持降噪”→
耳机-功能-降噪)。 - 人工校验核心关系(如品牌归属),确保图谱准确性。
- 导入Neo4J:通过
LOAD CSV或APOC库批量写入节点和关系。
- 使用OpenIE(斯坦福开放信息抽取)从文本中提取三元组(如“这款耳机支持降噪”→
交付物:
- Neo4J图数据库(含10万+节点、50万+关系)
- 数据字典(实体/关系定义)与ETL脚本
模块2:DeepSeek大模型集成与微调
负责人:算法组
任务内容:
- 模型选型与适配:
- 基础模型:DeepSeek-R1(67B参数,支持长文本理解)或DeepSeek-V2(轻量级,适合实时推理)。
- 微调任务:
- 语义匹配:将用户查询与商品标题/描述映射到同一向量空间(使用Sentence-BERT损失函数)。
- 意图分类:识别用户需求类型(如“价格敏感型”“品牌忠诚型”“探索型”)。
- 多模态扩展:
- 图像理解:接入CLIP模型,提取商品图片特征向量,支持“以图搜货”。
- 跨模态检索:联合文本与图像特征(如用户搜索“红色连衣裙”,匹配图片中红色占比>70%的商品)。
- 推理优化:
- 量化部署:将FP16模型转为INT8,减少GPU内存占用(推理速度提升2-3倍)。
- 缓存机制:对高频查询(如“iPhone 15 Pro”)预计算嵌入向量,存储至Redis。
交付物:
- 微调后的DeepSeek模型权重(
.safetensors格式) - 语义匹配API文档(输入:用户查询/商品文本,输出:Top-K相似商品ID)
模块3:混合推荐引擎开发
负责人:推荐系统组
任务内容:
- 推荐策略设计:
- 阶段1:粗排(高召回、低延迟):
- 基于DeepSeek语义匹配:计算用户查询与商品文本的余弦相似度,筛选Top 500商品。
- 基于Neo4J图遍历:从用户历史购买商品出发,通过
替代品/互补品关系扩展候选集(如用户买过“篮球”,推荐“篮球鞋”)。
- 阶段2:精排(高精度、个性化):
- 特征工程:
- 用户特征:年龄、性别、历史偏好品类(通过Neo4J聚合计算)。
- 商品特征:价格、销量、语义嵌入向量。
- 上下文特征:当前时间、天气、设备类型(手机/PC)。
- 排序模型:
- 使用XGBoost或DeepFM融合多源特征,输出推荐分数。
- 引入图神经网络(GNN):在Neo4J上运行GraphSAGE算法,聚合商品邻居节点信息(如“被同一用户购买过的商品”)。
- 特征工程:
- 阶段1:粗排(高召回、低延迟):
- 可解释性生成:
- 规则引擎:基于Neo4J路径查询生成推荐理由(如“您购买过‘运动耳机’,此款‘降噪耳机’被同品类用户高频搭配购买”)。
- 模板填充:预设理由模板(“根据您的[历史行为],推荐[商品名称],因其[属性/关系]”),通过DeepSeek填充变量。
交付物:
- 推荐引擎代码库(Python/Scala)
- 精排模型训练日志与AB测试报告(对比基线模型提升指标,如CTR+15%)
模块4:系统集成与性能优化
负责人:全栈开发组
任务内容:
- 架构设计:
- 微服务拆分:
- 语义服务:部署DeepSeek模型(TorchServe容器化)。
- 图服务:Neo4J集群(3节点,读写分离)。
- 推荐服务:Java/Spring Boot聚合各模块输出,生成最终推荐列表。
- 通信协议:
- 内部:gRPC(低延迟,支持流式推荐)。
- 外部:RESTful API(供电商APP/网页调用)。
- 微服务拆分:
- 性能优化:
- 图查询加速:对高频路径(如
用户→购买→商品→互补品)创建Neo4J索引。 - 异步处理:将非实时任务(如用户画像更新)放入Kafka消息队列,避免阻塞主流程。
- 图查询加速:对高频路径(如
- 监控体系:
- 指标监控:Prometheus采集推荐延迟(P99<200ms)、系统吞吐量(QPS≥1000)。
- 日志分析:ELK Stack追踪推荐失败案例(如图查询超时、模型输出异常)。
交付物:
- 部署文档(含Docker Compose配置、K8s YAML文件)
- 压测报告(模拟10万用户并发请求,系统稳定性≥99.9%)
三、技术栈与工具
| 模块 | 技术/工具 |
|---|---|
| 知识图谱 | Neo4j 5.x(社区版/企业版), APOC库, Cypher查询语言 |
| 大模型 | DeepSeek-R1/V2, HuggingFace Transformers, PyTorch |
| 推荐算法 | XGBoost, DeepFM, PyG(PyTorch Geometric) |
| 系统部署 | Docker, Kubernetes, Kafka, Prometheus+Grafana(监控) |
| 前端交互 | React(电商网页), Flutter(移动端), ECharts(数据可视化) |
四、时间计划
| 阶段 | 时间范围 | 里程碑 |
|---|---|---|
| 需求分析与设计 | 第1-2周 | 完成知识图谱模式设计、推荐策略文档、API接口定义 |
| 核心开发 | 第3-6周 | DeepSeek微调收敛(语义匹配准确率≥90%)、Neo4J图谱导入完成、推荐引擎初版上线 |
| 系统集成 | 第7-8周 | 微服务联调、压测优化、可解释性理由生成功能开发 |
| 测试与交付 | 第9周 | AB测试(对比传统协同过滤模型)、撰写技术白皮书、部署至生产环境 |
五、预期成果
- 推荐效果:
- 离线指标:AUC≥0.85,NDCG@10≥0.6(对比基线提升20%)。
- 在线指标:点击率(CTR)提升12%-18%,转化率(CVR)提升8%-15%。
- 系统性能:
- 平均推荐延迟<150ms(P99<300ms),支持百万级商品库实时推荐。
- 可解释性:
- 80%以上推荐结果附带理由,用户满意度调查得分≥4.2/5。
六、风险评估与应对
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 数据质量问题 | 商品描述缺失或用户行为数据稀疏 | 数据清洗规则(如填充缺失品类为“其他”)、合成数据生成(GAN模拟用户行为) |
| 模型偏见 | DeepSeek可能过度推荐热门商品,忽视长尾需求 | 引入多样性约束(如MMR算法平衡相关性与多样性)、长尾商品加权 |
| 图谱扩展性 | 商品/用户量增长后,Neo4J查询性能下降 | 分片存储(按品类拆分图数据库)、引入图缓存(RedisGraph) |
项目负责人签字:________________
日期:________________
此任务书可根据实际业务场景(如是否需要支持实时推荐、多语言商品描述)进一步调整,建议补充推荐流程图(如用户查询→语义匹配→图扩展→精排→可解释性生成)和成本估算(GPU资源、Neo4J企业版授权费用)。
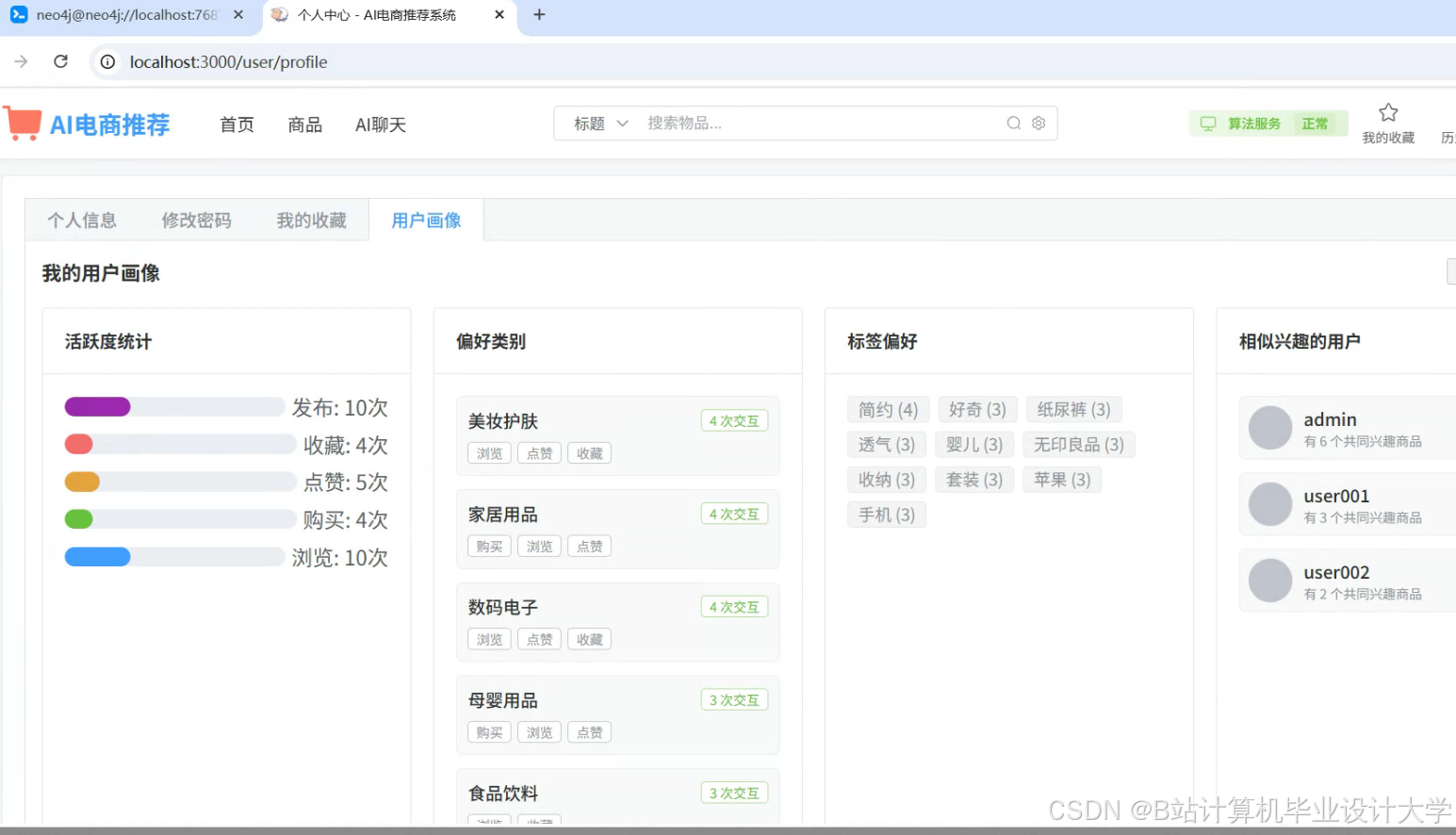
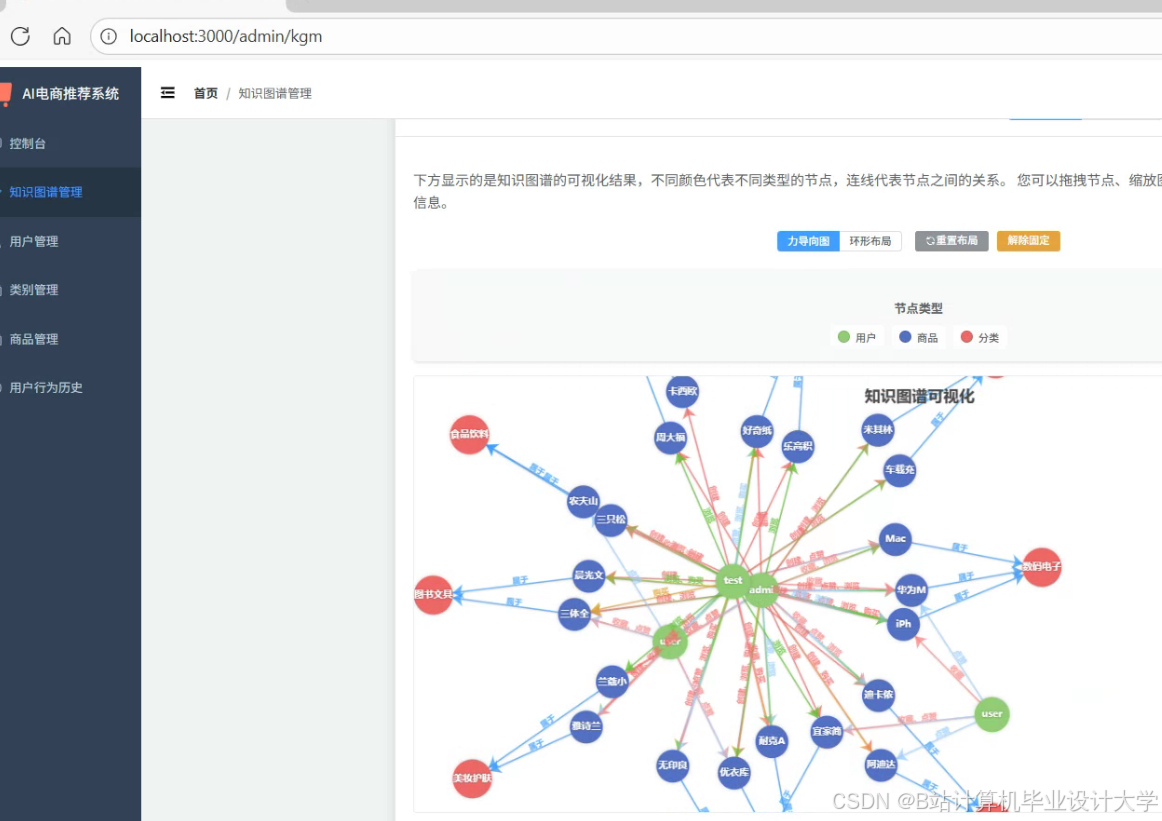
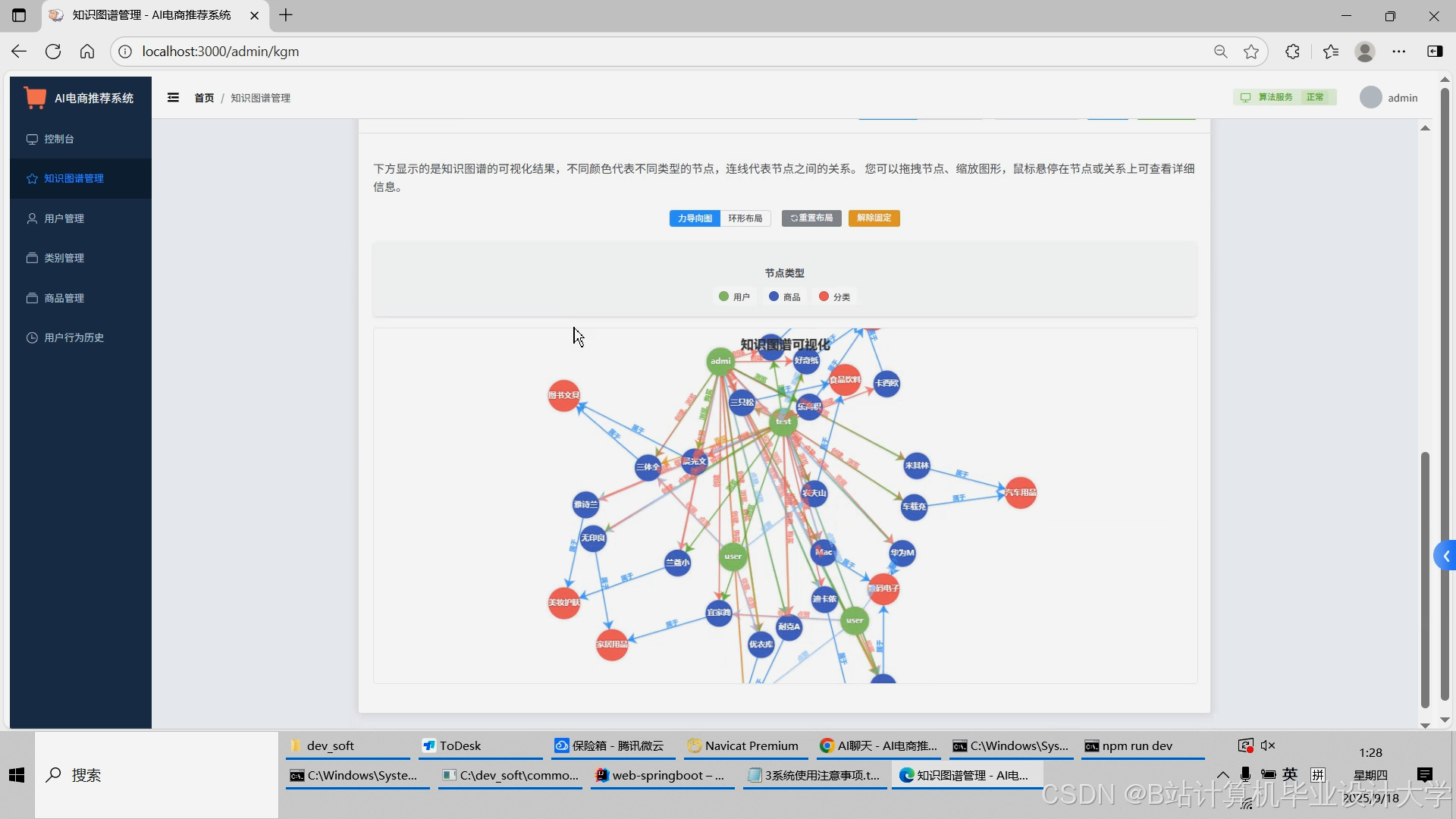
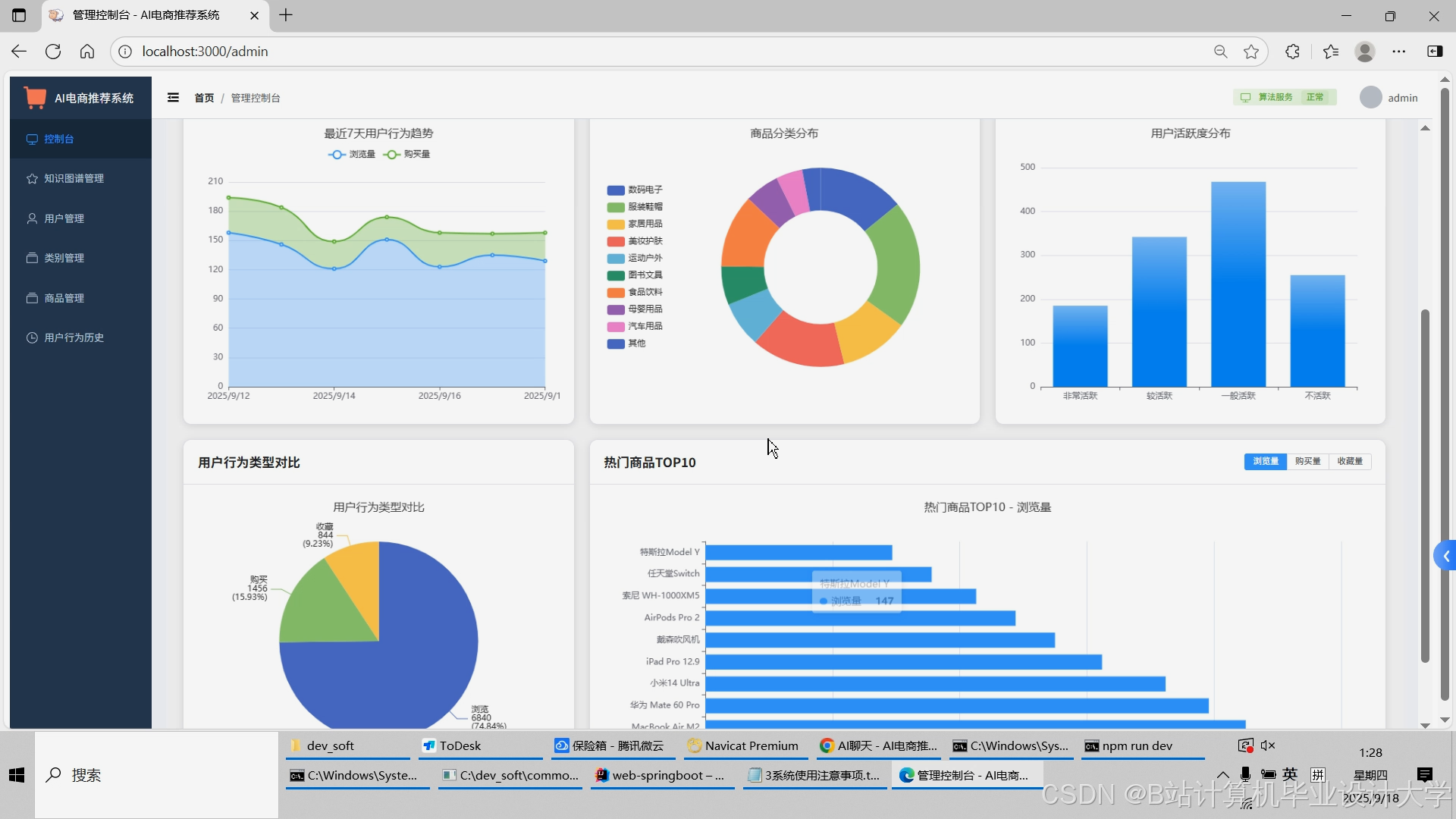
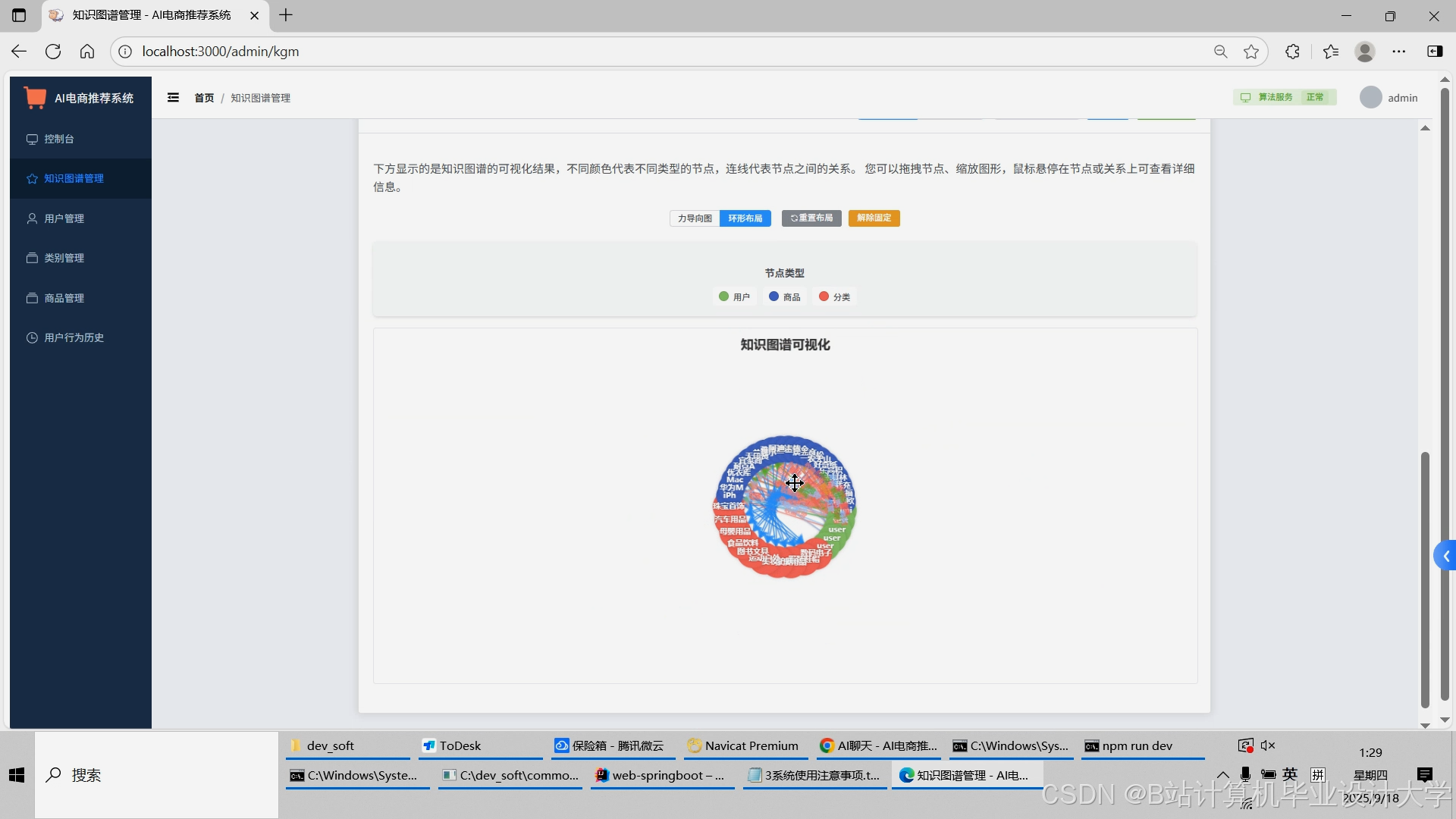
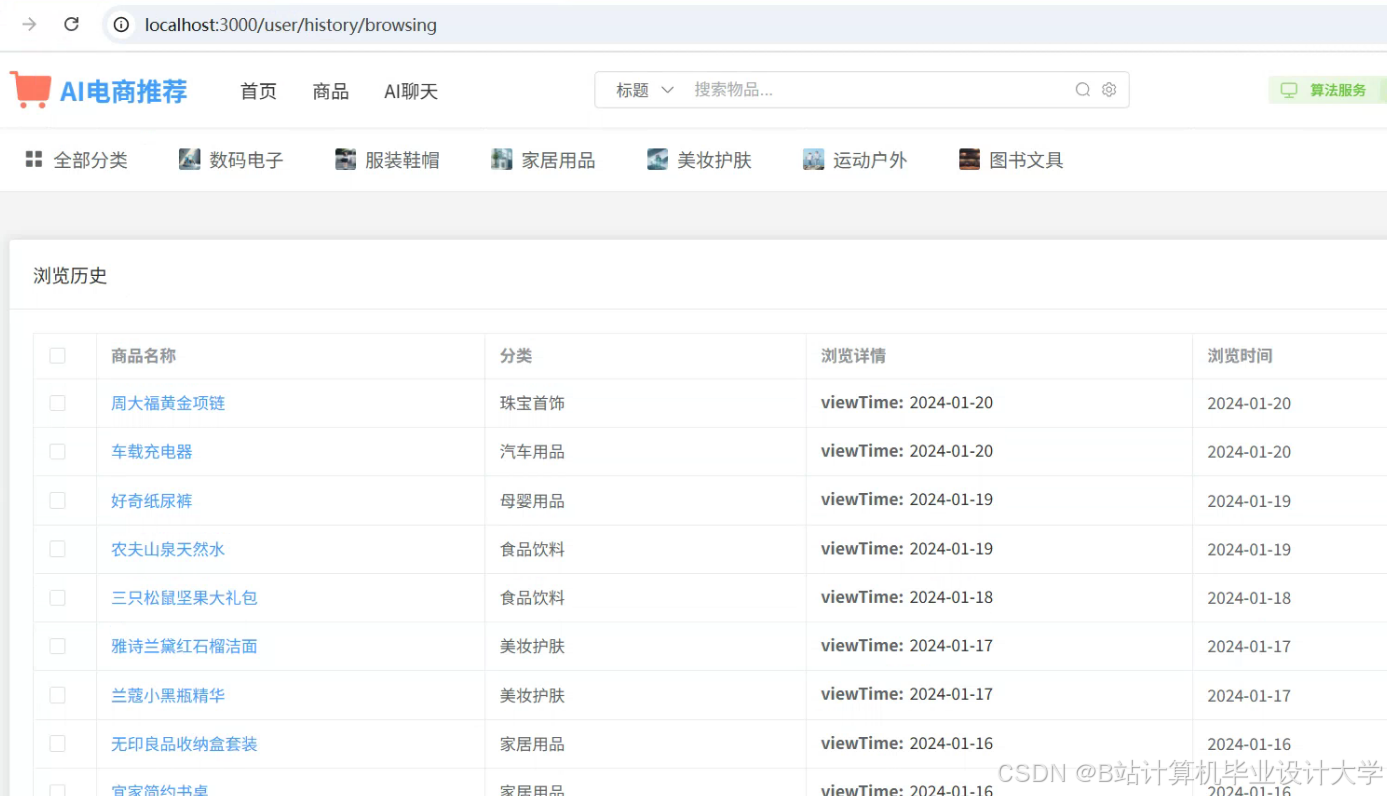
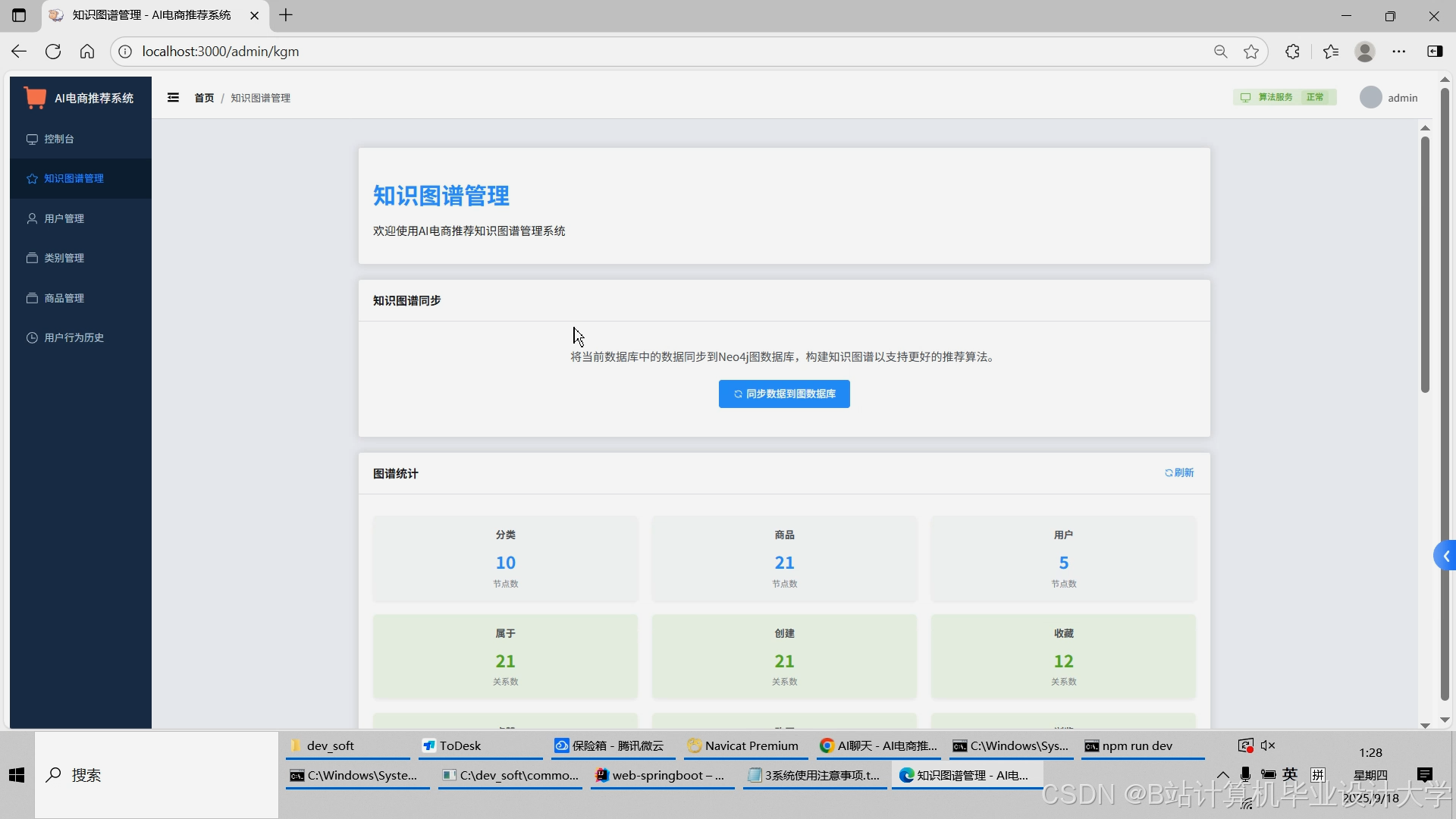
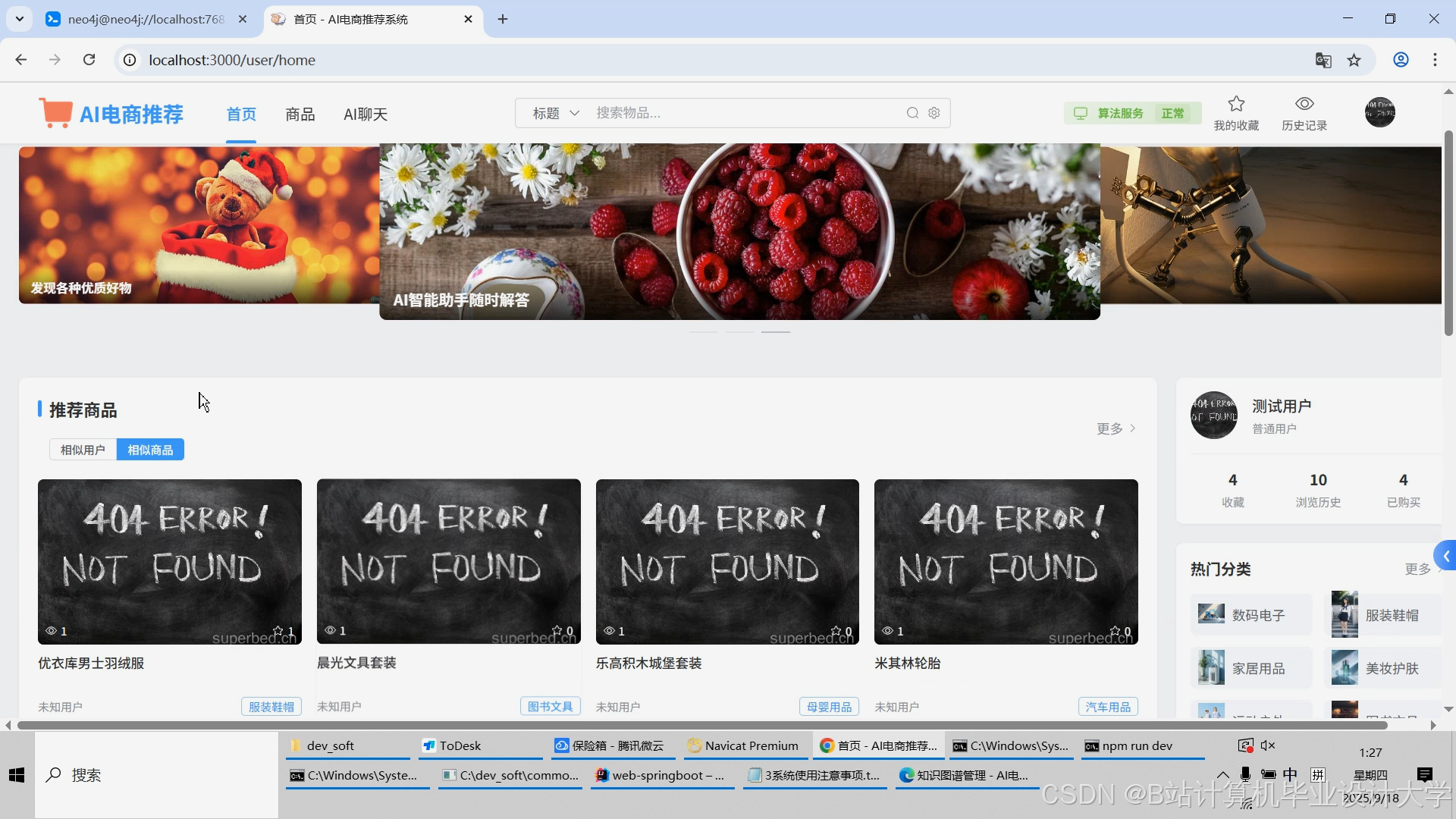
运行截图
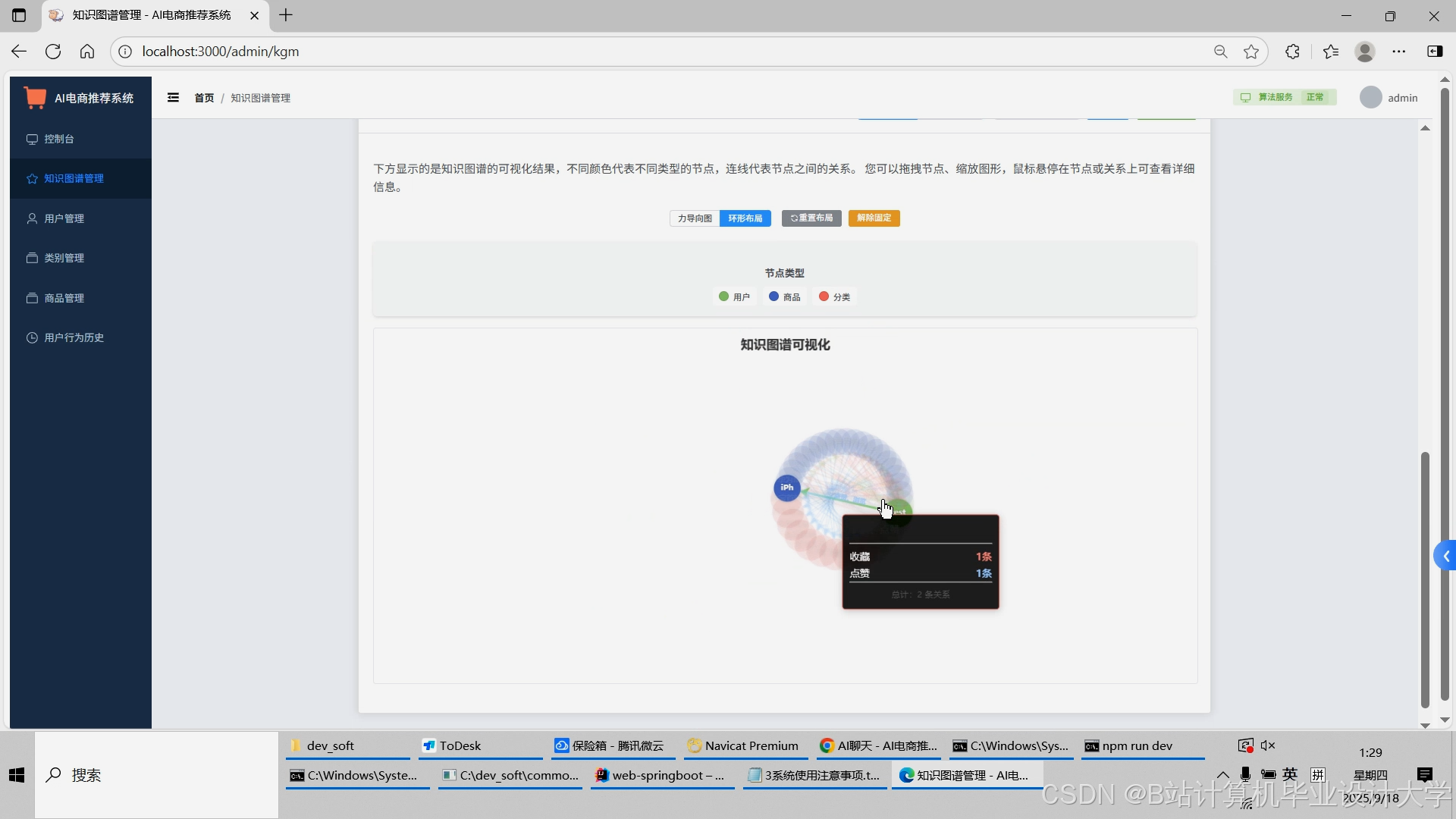
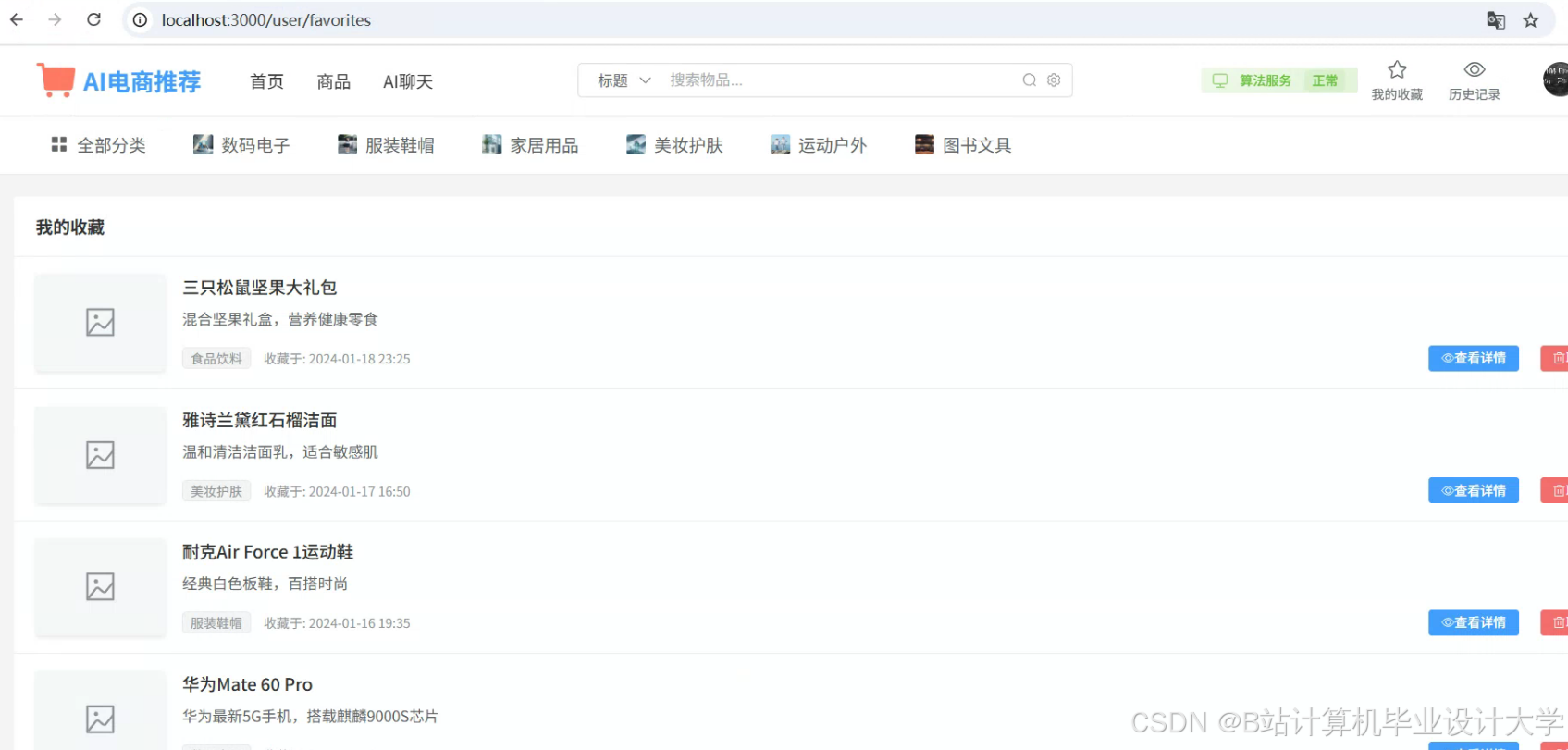
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
更多推荐
 25
25 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)