
从理论到实战!吴信东院士详解BEKO:大模型+知识图谱双向增强,收藏这篇就够了!
这篇文章要解决的问题是如何解决大型语言模型(LLMs)在生成内容时的幻觉现象和长尾知识遗忘问题。LLMs虽然在多种任务中展现了巨大潜力,但仍存在生成内容不准确和不完整的问题。

关键词:知识图谱;大语言模型;检索增强生成;双向增强;关系推理
核心速览
研究背景
-
研究问题
:这篇文章要解决的问题是如何解决大型语言模型(LLMs)在生成内容时的幻觉现象和长尾知识遗忘问题。LLMs虽然在多种任务中展现了巨大潜力,但仍存在生成内容不准确和不完整的问题。
-
研究难点
:该问题的研究难点包括:知识图谱构建复杂、语义丢失以及知识单向流动。现有方法通过结合知识图谱等外部知识显著增强LLMs的生成能力,但这些方法存在上述难点。
-
相关工作
:该问题的研究相关工作包括利用知识图谱增强LLMs的生成能力,以及利用LLMs构建知识图谱的方法。然而,这些方法大多表现为知识的单向流动,未能实现双向互补。
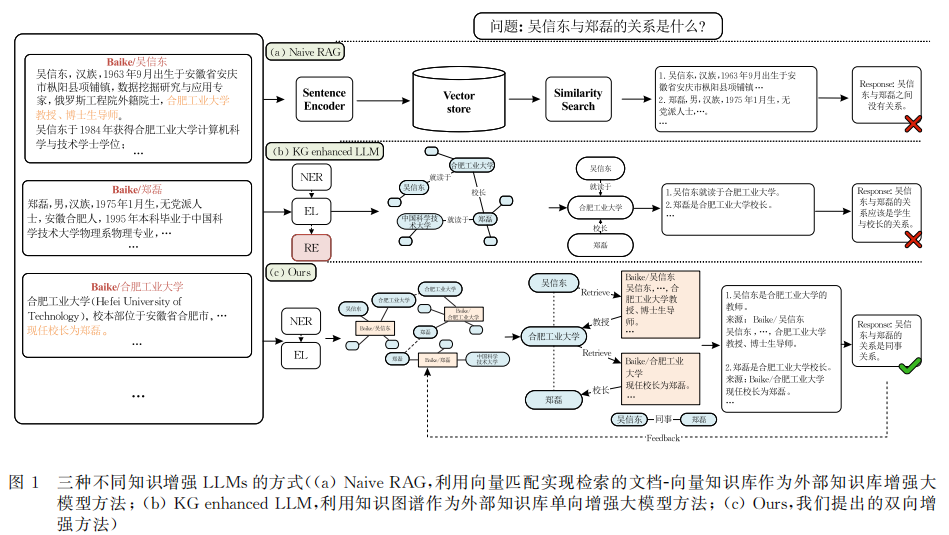
研究方法
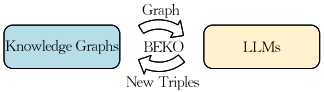
这篇论文提出了一种双向增强框架,称为BEKO(Bidirectional Enhancement with a Knowledge Ocean),用于解决LLMs生成内容不准确和不完整的问题。具体来说,
-
增强知识图谱(EKG):首先,设计了一种新的知识表示方式——增强知识图谱(EKG)。EKG在构建时仅需进行命名实体识别,保留实体与原始文档的链接,并将关系抽取推迟到推理阶段。这一方式大幅降低了知识图谱的构建成本与复杂性,缓解了知识图谱构建困难的问题。
-
双向增强机制:其次,设计了一个双向增强机制。一方面,利用EKG中的知识增强LLMs的推理能力;另一方面,将LLMs的推理结果反馈至知识图谱中,补充丰富知识,实现了知识在知识图谱与大模型之间的双向流动。
-
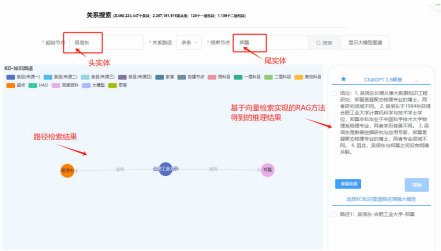
知识检索:此外,设计了一种从增强知识图谱(EKG)中获取结构化路径信息和非结构化文本信息的检索方法。通过结合知识图谱中的推理路径和原始文本,能够更全面地理解和推断头尾实体之间的复杂关系。
-
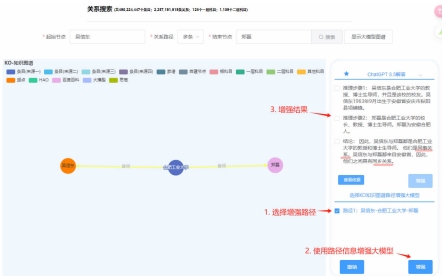
关系推理:通过以上步骤,得到多条关系路径,并基于这些路径信息利用大模型推理出头尾实体的关系。推理分为单路径推理和多路径融合两步。
-
反馈增强:最后,将大模型的推理结果以及中间推理过程为知识图谱补充有价值的知识,从而形成知识在知识图谱与大模型之间的双向流动,形成循环正反馈,持续优化系统的效果。
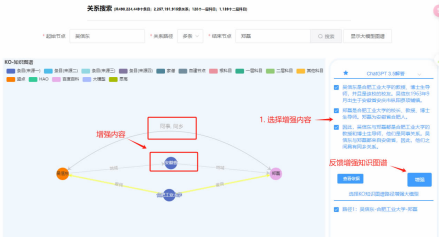
实验设计
为了验证BEKO方法的有效性,作者在两个公开的关系抽取数据集上进行了全面实验:
-
数据集
:实验基于跨文档关系抽取的CodRED数据集和文档关系抽取的DocRED数据集。CodRED数据集用于评估模型从多个文档中检索关系证据并推理实体关系的能力,DocRED数据集用于评估模型从单一文档中推断跨句实体关系的能力。
-
对比方法
:实验中比较了多种方法,包括仅使用大模型推理的方法(Only LLM)、基于向量相似性检索的文档增强方法(Naive RAG)、结合知识图谱增强大模型的方法(GraphRAG)以及BEKO方法。
-
评价指标
:在CodRED和DocRED数据集上的实验中,采用宏观指标(Macro Metrics)进行评价,包括精确率(Precision)、召回率(Recall)和F1分数。
结果与分析
- RQ1: BEKO方法是否在关系推理任务中优于现有单向增强和无增强方法?
-
在CodRED数据集上,基于GPT-4o的BEKO方法的F1值为0.776,相比于GraphRAG提高了2.4%,比Naive RAG提升了2.8%,比Only LLM方法提升了6.8%。
-
在DocRED数据集上,基于GPT-4o的BEKO方法的F1值为0.743,相比于GraphRAG提高了1.2%,比Naive RAG提升了5.1%,比Only LLM方法提升了3.5%。
-
定性分析中,BEKO方法得到的推理结果相较于其他方法也更加准确和完整。
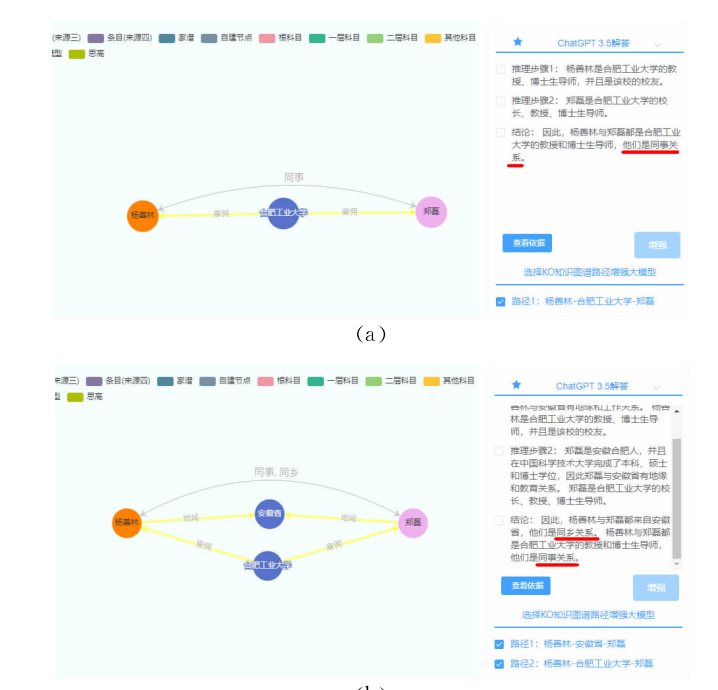
- RQ2: BEKO方法对大模型的增强效果是否具有泛化性?
- BEKO方法在不同的大模型上均表现出显著的增强效果。无论是基于当前最先进的大模型之一GPT-4o,还是性能较弱的GPT-4o-mini,BEKO方法在两个数据集上的实验结果均优于其他方法。
- 例如,在DocRED数据集上,基于GPT-4o的BEKO方法的F1值为0.743,比同样基于GPT-4o的GraphRAG方法提升了1.2%;基于GPT-4o-mini的BEKO方法的F1值为0.637,比同样基于GPT-4o-mini的GraphRAG方法提升了5.1%。
- RQ3: 多轮双向增强机制是否能够持续优化系统的效果?
-
多轮双向增强机制显著提升了关系抽取任务的综合性能。随着双向增强的不断进行,推理效果得以持续优化。
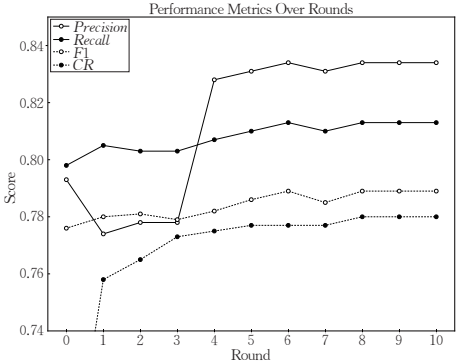
-
例如,在CodRED数据集上,基于GPT-4o模型实现的BEKO+MRE方法将F1分数从未进行多轮双向增强前的0.776提升至0.789,增幅为1.3%。
总体结论
本文提出的BEKO方法在关系推理任务中表现优异,验证了其创新性和有效性。该方法基于增强知识图谱(EKG)的检索机制,能够有效提取与问题相关的细粒度分散事实知识,从而实现了比现有主流方法更强的推理能力。其多轮双向增强机制将大模型的推理结果反馈至知识图谱,不仅丰富了知识图谱内容,还提升了大模型的推理能力,形成双向知识循环,持续优化推理效果。在CodRED和DocRED数据集上的实验结果充分证明了BEKO方法的优越性及其双向增强机制的有效性。未来研究将致力于将该方法扩展到如通用问答和事实验证等更多任务中,并探索其实际应用潜力。
论文评价
优点与创新
-
双向增强框架
:提出了知识图谱与大语言模型(LLMs)之间的双向增强框架,实现了知识的循环流动。
-
增强知识图谱(EKG)
:设计了增强知识图谱(EKG),通过命名实体识别和实体链接构建初始的EKG,并将关系抽取推迟到推理阶段,降低了知识图谱的构建成本与复杂性,缓解了知识图谱构建困难的问题。
-
多轮双向增强机制
:通过多轮双向增强机制,将大模型的推理结果反馈至知识图谱,不断补充和丰富知识图谱内容,优化系统效果。
-
实际系统BEKO
:构建了一个实际应用系统BEKO,并在公开网站部署,验证了双向增强框架的可行性和有效性。
-
实验验证
:在CodRED和DocRED数据集上的实验结果表明,BEKO方法在处理复杂关系推理任务时,性能显著优于传统方法。
-
泛化性
:BEKO方法在不同的大模型上均表现出显著的增强效果,具有较强的泛化能力。
不足与反思
-
长推理链路的局限性
:当关系推理链路过长时,基于参数量较小的模型可能会出现推理错误,这是因为过长的推理链路导致最终输入到大模型的上下文过长,使得部分内容在推理过程中被遗忘。
-
知识图谱内容饱和
:随着双向增强的持续进行,从相同样本的推理过程以及结果中获得的知识逐渐减少,导致添加到知识图谱中的知识也相应减少,关系推理性能的提升逐渐减小并趋于稳定。
-
下一步工作
:未来研究将致力于将该方法扩展到如通用问答和事实验证等更多任务中,并探索其实际应用潜力。
关键问题及回答
问题1:BEKO方法中的增强知识图谱(EKG)是如何构建的?其优点是什么?
增强知识图谱(EKG)在构建时仅需进行命名实体识别(NER),保留实体与原始文档的链接,并将关系抽取推迟到推理阶段。具体步骤如下:
-
实体抽取
:对语料库中的文档进行命名实体识别,提取出文档中的实体。
-
实体链接
:利用实体链接技术将不同文档中提及的相同实体关联起来。
-
构建EKG
:将所有文档中提取的实体集合进行实体链接,构建出增强知识图谱(EKG)。
EKG的优点包括:
-
降低构建成本
:仅需进行命名实体识别和实体链接,显著降低了知识图谱的构建成本与复杂性。
-
缓解语义丢失
:通过保留实体与原始文档的链接,EKG在推理过程中可溯源至原始文本,减少了在构建知识图谱过程中的语义丢失。
-
提高推理准确性
:EKG在构建初期无需进行关系抽取,显著降低了初期构建的复杂性和成本,并且在使用过程中可以逐步完善和补全图谱中的关系。
问题2:BEKO方法中的双向增强机制是如何设计的?其具体实现步骤是什么?
BEKO方法的双向增强机制包括以下几个方面:
-
知识检索
:从增强知识图谱(EKG)中获取结构化路径信息和非结构化文本信息。通过结合知识图谱中的推理路径和原始文本,能够更全面地理解和推断头尾实体之间的复杂关系。
-
知识增强推理
:利用EKG中的知识增强大型语言模型(LLMs)的推理能力。具体步骤包括:
- 构建Prompt,将关系路径和问题结合起来,生成一个综合性的输入提示。
- 将Prompt输入LLMs,得到头尾实体在路径上表达的关系。
- 通过融合多条路径上表达的关系,得到头尾实体的关系。
-
反馈增强
:将LLMs的推理结果以及中间推理过程为知识图谱补充有价值的知识,从而形成知识在知识图谱与大模型之间的双向流动。具体步骤包括:
- 将大模型的推理结果作为新的知识反馈增强EKG。
- 使用更强大的模型(如GPT-4)对关系及其证据进行一致性验证,确保提取的三元组与相应的关系证据一致。
问题3:BEKO方法在实验中表现如何?与其他方法相比有哪些优势?
-
CodRED数据集
:
- 基于GPT-4o的BEKO方法的F1值为0.776,相比于GraphRAG提高了2.4%,比Naive RAG提升了2.8%,比Only LLM方法提升了6.8%。
- 基于GPT-4o-mini的BEKO方法的F1值为0.669,相比于GraphRAG提高了3.0%,比Naive RAG提升了7.7%,比Only LLM方法提升了9.2%。
-
DocRED数据集
:
- 基于GPT-4o的BEKO方法的F1值为0.743,相比于GraphRAG提高了1.2%,比Naive RAG提升了5.1%,比Only LLM方法提升了3.5%。
- 基于GPT-4o-mini的BEKO方法的F1值为0.637,相比于GraphRAG提高了5.1%,比Naive RAG提升了8.0%,比Only LLM方法提升了8.6%。
-
定性分析
:BEKO方法得到的推理结果相较于其他方法也更加准确和完整。例如,在阿诺德·施瓦辛格与约翰·肯尼迪关系推理任务中,BEKO方法成功推理出两者的“家族联姻-政治”双重关系,而其他方法未能完整推理出这些关系。
优势:
-
更高的推理准确性
:BEKO方法通过获取从头实体到尾实体的多跳关系路径信息以及与路径中关系的关系证据文本信息,实现了更全面和准确的关系推理。
-
更好的泛化性
:BEKO方法在不同的大模型上均表现出显著的增强效果,无论是在基于当前最先进的大模型GPT-4o,还是在性能较弱的GPT-4o-mini上,BEKO方法的表现均优于其他方法。
-
持续优化的双向增强机制
:BEKO方法通过多轮双向增强机制,将大模型的推理结果反馈至知识图谱,不仅丰富了知识图谱内容,还提升了大模型的推理能力,形成双向知识循环,持续优化推理效果。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐
 22
22 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)