
必学收藏!GraphRAG技术详解:解锁大模型理解大规模文本的全新方式
必学收藏!GraphRAG技术详解:解锁大模型理解大规模文本的全新方式
1、 知识图谱(Knowledge Graph)的本质与价值
知识图谱(Knowledge Graph)是一种以结构化形式承载现实世界中各类“实体”及其关联关系的智能数据模型。它的核心目标,是将分散在文本、数据中的碎片化信息,转化为机器可理解的“实体-关系”网络,从而打破信息孤岛,实现对复杂关联的高效挖掘。
在知识图谱的体系中,“实体”是构成整个网络的基础单元,其范畴极为广泛,既可以是具象的事物(如“北京”“智能手机”“2024年奥运会”),也可以是抽象的概念(如“人工智能技术”“市场经济规律”“环境保护理念”)。而“关系”则是连接不同实体的“桥梁”,它不仅描述实体间的关联状态,更蕴含着背后的语义逻辑——例如“北京”与“中国”的“首都-国家”关系,“智能手机”与“人工智能技术”的“应用-支撑”关系,都通过明确的关系定义被精准刻画。

传统检索增强生成(RAG)技术之所以在复杂问题处理上效果受限,核心症结在于其对信息的“碎片化处理”模式:它将文档切割为独立的文本块并存储于向量数据库,查询时仅通过向量相似性匹配“可能相关”的片段,却无法捕捉片段间的深层关联。而知识图谱的出现,正是为了弥补这一缺陷——在检索过程中,系统不再是“大海捞针”式地筛选孤立信息,而是基于图谱中预设的实体关联,提取出一整条相互串联的“知识链”,交由大语言模型(LLM)进行整合分析,从而让回答更具逻辑性和完整性。
作为知识图谱与传统RAG的融合产物,GraphRAG(图谱增强检索生成)完美结合了两者的优势:既保留了RAG对海量文本的处理能力,又借助知识图谱的结构化特性,解决了传统RAG“关联缺失、解释性弱”的核心局限,成为处理复杂问题的新一代技术方案。
2、传统RAG与GraphRAG的核心差异对比
传统RAG与GraphRAG在技术逻辑、应用场景上存在本质区别,以下从五个关键维度进行详细对比:
| 对比维度 | 传统RAG | GraphRAG |
|---|---|---|
| 数据表示形式 | 依赖向量数据库,以孤立的文本块为基本单位,缺乏结构化关联 | 构建包含“实体-关系-社区”的知识图谱,数据以网状结构呈现,语义关联清晰 |
| 核心检索机制 | 基于文本向量的相似性匹配,本质是“语义相近性”筛选 | 融合图谱遍历(沿实体关系路径检索)、社区摘要(基于聚类群体提炼信息)与向量检索的混合模式 |
| 适配问题类型 | 适用于简单事实查询(如“某事件的时间地点”“某概念的基本定义”) | 擅长处理复杂问题:跨文档关联分析(如“某政策对不同行业的影响”)、多步骤逻辑推理(如“技术A如何通过B环节影响C领域”) |
| 上下文理解能力 | 仅能捕捉单文本块的局部上下文,难以形成全局认知 | 既能理解单个实体的细节,又能通过关系网络把握实体间的全局关联,实现“微观细节+宏观脉络”的双重理解 |
| 结果可解释性 | 输出结果由多个孤立文本片段组成,无法追溯“答案如何推导”,可解释性差 | 能清晰展示答案的来源(对应哪个文本单位、哪个社区)及推理路径(通过哪些实体关系得出结论),可解释性强 |
3、 GraphRAG知识模型的五大核心构成
GraphRAG构建的知识模型并非单一结构,而是由五个相互关联的核心模块组成,共同构成了层次化、可解释的知识体系:
-
实体(Entities):知识图谱的“节点”核心,是从原始文本中提取的关键对象。LLM会自动识别文本中的核心元素(如人物、机构、事件、概念等),并为每个实体标注标题(如“特斯拉公司”)、类型(如“企业”)和描述(如“一家美国电动汽车及清洁能源公司”),确保实体的唯一性和语义清晰度。
-
关系(Relationships):连接实体的“边”,是刻画实体间语义关联的关键。它不仅将两个或多个实体串联,还通过关系描述明确关联的性质——例如“特斯拉公司”与“埃隆·马斯克”的关系可定义为“创始人-企业”,并补充描述“埃隆·马斯克于2003年参与创立特斯拉公司”,让关系更具信息量。
-
文本单位(TextUnits):知识图谱的“信息源头”,是原始文档经过逻辑切分后的文本片段(如一篇文章的某一章节、一个报告的某一论点)。每个文本单位都与图谱中的实体、关系直接关联,在查询阶段,它会作为“证据来源”被引用,确保答案的可追溯性。
-
社区(Communities):实现“高层次认知”的核心模块,是通过层次化 Leiden 聚类算法生成的“实体群组”。系统会自动识别图谱中关联紧密的实体(如“电动汽车”“动力电池”“充电桩”等实体因产业关联形成“新能源汽车产业链”社区),并构建层次化的社区结构(如“新能源汽车产业链”下可细分“上游材料”“中游制造”“下游服务”子社区),支持从不同粒度解读数据。
-
社区报告(Community Reports):由LLM为每个社区生成的结构化摘要,是“社区知识”的浓缩呈现。报告不仅包含社区内的核心实体、关键关系,还会提炼出该社区的核心主旨(如“新能源汽车产业链社区的核心逻辑是‘技术迭代推动成本下降,政策支持加速市场渗透’”),为跨社区关联分析、全局问题解答提供高效支撑。
4、 GraphRAG的两大核心工作阶段与技术优势
GraphRAG的工作流程遵循“先构建、后应用”的逻辑,清晰分为索引阶段与查询阶段,两个阶段环环相扣,共同实现高效的知识检索与推理:
索引阶段(Indexing Phase):从“非结构化文本”到“结构化图谱”
这一阶段是GraphRAG的“知识构建期”,核心目标是将杂乱的非结构化文本(如文档、报告、网页内容等)转化为结构化的知识图谱。具体流程包括:
- 文本预处理:将原始文档按逻辑切分为多个文本单位(TextUnits);
- 实体与关系提取:通过LLM调用,自动识别每个文本单位中的实体、关系,并标注属性;
- 图谱构建:将提取的“实体-关系”组合成初步的知识图谱;
- 社区聚类与报告生成:利用层次化聚类算法划分社区,再由LLM为每个社区生成社区报告。
整个过程是自下而上的知识提炼——从零散的文本片段,逐步形成“文本单位-实体-关系-社区-报告”的多层次知识体系。
查询阶段(Querying Phase):从“问题输入”到“智能解答”
当知识图谱构建完成后,系统进入“知识应用期”,专注于通过结构化知识为用户提供精准答案。其核心逻辑是:
- 问题解析:LLM将用户的自然语言问题(如“新能源汽车政策如何影响动力电池企业的技术研发?”)拆解为“核心实体”(如“新能源汽车政策”“动力电池企业”“技术研发”)和“关联需求”(如“影响路径”);
- 混合检索:查询引擎结合“图谱遍历”(沿“政策-企业-研发”的关系路径检索相关实体)、“社区摘要”(提取“新能源汽车产业链”“动力电池技术”等社区的报告)与向量检索(匹配相关文本单位),获取全方位上下文;
- 答案生成:LLM基于检索到的结构化知识(实体关系、社区主旨)和原始证据(文本单位),生成逻辑连贯、可追溯的答案。
GraphRAG的核心技术优势:从“信息检索”到“知识推理”
GraphRAG的价值远不止于“更高效的检索”,其本质是为LLM打造了一个具有语义拓扑结构的“智能记忆库”。与传统RAG将信息视为“无关联的文本碎片”不同,GraphRAG通过LLM自动编织碎片间的关系网络,让LLM在回答时实现三大突破:
- 从“被动读取”到“主动推理”:不再是简单拼接文本片段,而是沿图谱关系路径进行“联想式推理”;
- 从“局部认知”到“全局视角”:既能聚焦单个实体的细节,又能通过社区结构把握整体脉络;
- 从“结果输出”到“过程透明”:通过展示推理路径和证据来源,解决了传统AI“黑箱问题”,让答案更可信。
这种技术特性,使得GraphRAG在需要深度分析、复杂推理的场景(如行业研究、政策解读、学术分析等)中,展现出远超传统RAG的优势。
5、 安装GraphRAG
为了调试方便,我直接拉源码下来
git clone https://github.com/microsoft/graphrag.git
当前的版本是v2.5.0
新建虚拟环境(这里使用uv作为包管理工具),使用Python3.11.9
uv venv -p 3.11.9
切换到新建的虚拟环境:
.venv\Scripts\activate
安装依赖:
uv sync
6、 使用方法
GraphRAG可以选择通过 CLI 或 Python API 来运行
6.1 CLI 命令行
这是我们体验的主要操作方式,如:graphrag index --root ./ragtest
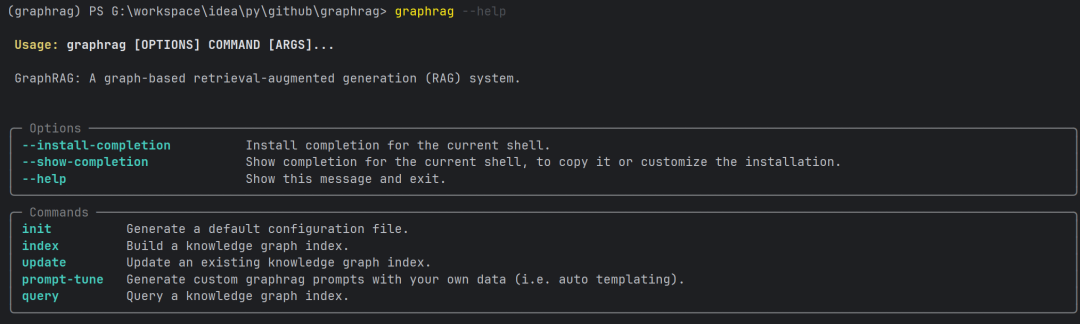
6.2 Python API
查看索引 API 的 Python 文件(https://github.com/microsoft/graphrag/blob/main/graphrag/api/index.py),了解从 Python 代码中直接调用的推荐方法。
7、 初始化
运行 graphrag init 命令
graphrag init --root ./ragtest
这将在 ./ragtest 目录中创建两个文件: .env 和 settings.yaml 和一个目录 prompts。
看一下结构:
> tree ragtest /f
G:\WORKSPACE\IDEA\PY\GITHUB\GRAPHRAG\RAGTEST
│ .env
│ settings.yaml
│
└─prompts
basic_search_system_prompt.txt
community_report_graph.txt
community_report_text.txt
drift_reduce_prompt.txt
drift_search_system_prompt.txt
extract_claims.txt
extract_graph.txt
global_search_knowledge_system_prompt.txt
global_search_map_system_prompt.txt
global_search_reduce_system_prompt.txt
local_search_system_prompt.txt
question_gen_system_prompt.txt
summarize_descriptions.txt
8、 修改配置
.env
.env 包含运行 GraphRAG 流程所需的环境变量。其中定义了一个环境变量, GRAPHRAG_API_KEY=<API_KEY> 。将 <API_KEY> 替换为您个人的模型密钥。(我这里用的阿里百炼)
settings.yaml
settings.yaml 通过修改此文件来更改所有的配置。
GraphRAG主要用到两个模型:一个语言模型,一个嵌入模型,以下是我使用的配置
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/
### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.
models:
default_chat_model:# 定义语言模型
type:openai_chat# or azure_openai_chat
api_base:https://dashscope.aliyuncs.com/compatible-mode/v1# 改为你的模型调用地址
# api_version: 2024-05-01-preview
auth_type:api_key# or azure_managed_identity
api_key:${GRAPHRAG_API_KEY}# set this in the generated .env file # 从.env读取key
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model:qwen-flash# 你使用的语言模型
# deployment_name: <azure_model_deployment_name>
encoding_model:cl100k_base# automatically set by tiktoken if left undefined # 确定分词编码方式
model_supports_json:true# recommended if this is available for your model.
concurrent_requests:25# max number of simultaneous LLM requests allowed
async_mode:threaded# or asyncio
retry_strategy:native
max_retries:10
tokens_per_minute:1000000# set to null to disable rate limiting # 确定TPM,可选
requests_per_minute:1000# set to null to disable rate limiting # 确定RPM,可选
default_embedding_model:
type:openai_embedding# or azure_openai_embedding # 嵌入模型
api_base:https://dashscope.aliyuncs.com/compatible-mode/v1# 改为你的模型调用地址
# api_version: 2024-05-01-preview
auth_type:api_key# or azure_managed_identity
api_key:${GRAPHRAG_API_KEY}# 从.env读取key
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model:text-embedding-v4# 你使用的嵌入模型
# deployment_name: <azure_model_deployment_name>
encoding_model:cl100k_base# automatically set by tiktoken if left undefined # 确定分词编码方式
model_supports_json:true# recommended if this is available for your model.
concurrent_requests:25# max number of simultaneous LLM requests allowed
async_mode:threaded# or asyncio
retry_strategy:native
max_retries:10
tokens_per_minute:1000000# set to null to disable rate limiting or auto for dynamic 确定TPM,可选
requests_per_minute:1500# set to null to disable rate limiting or auto for dynamic 确定RPM,可选
### Input settings ###
input:
storage:
type:file# or blob
base_dir:"input"
file_type:text# [csv, text, json]
chunks:
size:1200
overlap:100
group_by_columns:[id]
### Output/storage settings ###
## If blob storage is specified in the following four sections,
## connection_string and container_name must be provided
output:
type:file# [file, blob, cosmosdb]
base_dir:"output"
cache:
type:file# [file, blob, cosmosdb]
base_dir:"cache"
reporting:
type:file# [file, blob]
base_dir:"logs"
vector_store:
default_vector_store:
type:lancedb
db_uri:output\lancedb
container_name:default
overwrite:True
### Workflow settings ###
embed_text:
model_id:default_embedding_model
vector_store_id:default_vector_store
batch_size:10# 嵌入的批量大小,要符合API限制
batch_max_tokens:8191
extract_graph:
model_id:default_chat_model
prompt:"prompts/extract_graph.txt"
entity_types:[organization,person,geo,event]
max_gleanings:1
summarize_descriptions:
model_id:default_chat_model
prompt:"prompts/summarize_descriptions.txt"
max_length:500
extract_graph_nlp:
text_analyzer:
extractor_type:regex_english# [regex_english, syntactic_parser, cfg]
cluster_graph:
max_cluster_size:10
extract_claims:
enabled:false
model_id:default_chat_model
prompt:"prompts/extract_claims.txt"
description:"Any claims or facts that could be relevant to information discovery."
max_gleanings:1
community_reports:
model_id:default_chat_model
graph_prompt:"prompts/community_report_graph.txt"
text_prompt:"prompts/community_report_text.txt"
max_length:2000
max_input_length:8000
embed_graph:
enabled:true# if true, will generate node2vec embeddings for nodes
umap:
enabled:true# if true, will generate UMAP embeddings for nodes (embed_graph must also be enabled)
snapshots:
graphml:true
embeddings:false
### Query settings ###
## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned.
## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#query
local_search:
chat_model_id:default_chat_model
embedding_model_id:default_embedding_model
prompt:"prompts/local_search_system_prompt.txt"
global_search:
chat_model_id:default_chat_model
map_prompt:"prompts/global_search_map_system_prompt.txt"
reduce_prompt:"prompts/global_search_reduce_system_prompt.txt"
knowledge_prompt:"prompts/global_search_knowledge_system_prompt.txt"
drift_search:
chat_model_id:default_chat_model
embedding_model_id:default_embedding_model
prompt:"prompts/drift_search_system_prompt.txt"
reduce_prompt:"prompts/drift_search_reduce_prompt.txt"
basic_search:
chat_model_id:default_chat_model
embedding_model_id:default_embedding_model
prompt:"prompts/basic_search_system_prompt.txt"
prompts
prompts 目录中生成了将要使用到的所有提示词。
我们需要把extract_claims.txt和extract_graph.txt 中的“语言”修改为中文,避免生成英文内容。
extract_claims.txt
3. Return output in 中文 as a single list of all the claims identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
extract_graph.txt
3. Return output in 中文 as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
9、 准备数据
新建数据目录:
mkdir -p ./ragtest/input
我准备了《凡人修仙传》前125章,一共25万字左右,放到input目录中
10、创建索引
在命令行执行:
graphrag index --root ./ragtest
这个时间会比较长,我这里用了20分钟
GraphRAG的索引是其强大能力的来源,但同时也带来了显著的问题。
该过程被人们描述为“是一个昂贵的操作”,因为它涉及多次LLM调用,真的是“又贵又慢”。
这种高成本是其设计本身的直接结果。
系统不满足于简单的文本嵌入,而是通过LLM进行多轮次的文本解析、实体关系提取和社区摘要生成,每一步都是一次潜在的、昂贵的API调用。
因此,GraphRAG的“高成本”是其在复杂问题上实现“高精度”和提供“高洞察力”的直接代价。
对于希望在实践中部署GraphRAG的人而言,这是必须要考虑的一个问题.
10.1 索引阶段的Token使用情况
测试小说全文25万字,
语言模型 qwen-flash 的使用情况:
调用总次数1690次,输入Tokens总量3,890.1千Tokens,输出Tokens总量1,319.6千Tokens
嵌入模型 text-embedding-v4 的使用情况:
调用总次数301次,全部Tokens总量780.5千Tokens
11、 查询
这里的查询方式有两种:
局部查询:
通过将 AI 提取到知识图谱中的相关数据与原始文档的文本块相结合来生成答案,此方法适用于需要了解文档中提到的特定实体的问题。
全局查询:
全局查询方法通过以 map-reduce 方式搜索所有 AI 生成的社区报告来生成答案。这是一种资源密集型方法,需要LLM支持的context window足够大,但通常可以很好地回答需要了解整个数据集的问题。
那么我们现在就来用《凡人修仙传》问一些问题吧。
使用全局搜索来提出一个概括性问题的例子:
graphrag query --root ./ragtest --method global --query "韩立和墨大夫是什么关系?"
(graphrag) PS G:\workspace\idea\py\github\graphrag> graphrag query --root ./ragtest --method global --query "韩立和墨大夫是什么关系?"
韩立与墨大夫的关系极为复杂,呈现出多重身份交织的深层张力,既包含师徒传承、权力交接与医术继承的正面纽带,又暗藏敌对、控制与夺舍的致命冲突。这一关系并非单一维度,而是贯穿于修仙世界中的权谋、生存与自我觉醒的核心叙事主线。
从传承与身份的角度看,墨大夫是韩立的亲传师尊。他主持了韩立的入门考核,将其纳入七玄门正式弟子序列,传授《长春功》第一层法决与“引魂钟”这一关键法器,标志着韩立正式进入修真体系 [Data: Reports (19, 82, 158, 119, 167, 260, +more)]。墨大夫还通过“纹龙戒”这一信物认证韩立的身份,其与严氏戒指的契合进一步确认了韩立作为真传弟子的合法性,使他得以进入墨府、参与核心事务 [Data: Reports (80, 146, 157, 158, 146)]。此外,韩立在墨府期间承担了誊录《 医道心得》的重任,这不仅是对医术传承的履行,也标志着其从外部观察者向内部体系参与者的身份转变 [Data: Reports (216, 19, 146)]。墨大夫去世后,韩立 接任其职位,成为七玄门新的首席医师,完整继承了其医术权威与药园资源,并利用神秘瓶子大规模催生药材,展现出超越前任的掌控能力,完成了从弟子到领袖的权力交接 [Data: Reports (57, 65, 66, 3, 112, 185, 30, 36)]。
然而,这一表面的师徒关系之下,隐藏着深刻的敌对与控制本质。墨大夫对韩立的“教导”实为精心设计的夺舍计划。他通过传授《长春功》这一功法,实则植入了夺舍机制,意图借韩立的肉身实现自身元神的转移与长生 [Data: Reports (207, 115, 59, 60, 153)]。墨大夫更以“尸虫丸”与“缠香丝”等毒药进行双重控制,使韩立长期处于生死依赖状态——需服药以避免骨骼异变与瘫痪,从而确保其绝对服从 [Data: Reports (153, 82, 0, 55, 69, 257, 140, 1278, 597, 681, 625)]。此外,墨大夫通过“定”字咒语与黄纸符咒构建的法术体系,实施意识入侵与灵魂操控,试图在梦境中夺取韩立的神识 [Data: Reports (151, 28, 152, 45, 156)]。在“套
中套”情节中,墨大夫更主导了“七鬼噬魂大法”的夺舍仪式,其行为具有高度预谋性与攻击性,直接威胁韩立的自我意识完整性 [Data: Reports (31, 21, 45, 22, 152, 2452, +more)]。
使用局部搜索来询问关于某个特定角色的更具体问题的例子:
graphrag query --root ./ragtest --method local --query "墨大夫是个什么样的人"
(graphrag) PS G:\workspace\idea\py\github\graphrag> graphrag query --root ./ragtest --method local --query "墨大夫是个什么样的人"
墨大夫是一位复杂而深藏不露的角色,其形象贯穿于整个故事的多个层面,既是医术高超的象征,也是阴谋与权谋交织的核心人物。他是七玄门前任首席医师,被称
为“神医墨大夫”,以医术高明著称,能够救治内外伤及疑难杂症,甚至在药效上超越了前任医师,尽管其医术受限于药材资源 [Data: Entities (819); Sources (1
50)]. 他不仅医术精湛,还极富谋略与远见,其居所内藏有暗格,存放着虚假身份文件、亲笔证明、名单以及控制手段,显现出其在生前便已布局长远,为后人留下重重谜题 [Data: Entities (793); Relationships (1365)]。
墨大夫的个性极具矛盾性:他既是韩立的上司与前任,又是被韩立称为“墨老鬼”的令人畏惧的存在,反映出韩立对其既敬且畏的心理 [Data: Entities (482, 819);
Relationships (822)]. 他行事沉稳,善于隐藏真实意图,例如在与韩立对峙时,其“虚实掌法”看似凶猛却只用半成功力,实则是一种试探与保护 [Data: Entitie
s (620); Relationships (1070)]. 他在关键时刻出声阻止铁奴的攻击,展现出对局势的绝对掌控力,其声音具有压倒性的权威,足以让铁奴立即停手 [Data: Entities (655); Relationships (1140)]。
此外,墨大夫的死亡并非表面所见的简单事件。他的尸体被发现于屋内,其身上藏有香囊,且在临终前留下遗书,暗示其早已预料到未来变局,并为韩立安排了复杂
的任务与交易 [Data: Entities (776, 1348, 1350); Relationships (1340)]. 他甚至在临死前察觉到自身伤口异样,意识到中了“缠香丝”毒药,心理防线开始动 摇,这表明他并非毫无防备,而是身陷险境 [Data: Entities (650, 631, 632); Relationships (1124, 1098, 1099)]。
更耐人寻味的是,墨大夫身后还有一位神秘人,始终紧随其后,寸步不离,身份不明,可能为护卫或随从,暗示其生前并不孤单,背后或有更深的势力支撑 [Data:
Entities (461); Relationships (782)]. 他最终的故乡位于岚州,是韩立必须前往的地理节点,也是整个事件推动的关键所在 [Data: Entities (1159, 2188); Relationships (2228)]。
综上所述,墨大夫不仅是一位医术超群的医生,更是一位布局深远、心思缜密的智者,其生前行为与死后遗局深刻影响了韩立的命运,其形象融合了医者仁心、权谋深沉与神秘莫测的特质 [Data: Entities (1171, 819, 793, 1159); Relationships (1365, 1340, 1124, 1099, 2188, +more)].
GraphRAG代表了RAG技术发展的一个重要方向,它通过将非结构化文本转化为结构化知识图谱,实现了从简单的“信息检索”到基于“知识结构”的“智能推理”的范式转变。
问题是GraphRAG目前在成本、资源消耗和数据增量更新方面存在挑战。
不过他有效地解决了传统RAG在处理复杂、跨文档和全局性问题时所面临的核心局限。它提供了一种强大方式,使得LLM能够基于可验证的知识基础生成答案,从而显著减少了幻觉(hallucination)的风险。
对于希望为企业构建高精度、高可解释性生成式AI应用的开发者和研究人员来说,GraphRAG是一个值得深入探索和关注的前沿技术。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!
更多推荐

 26
26 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)