
手把手教你全参数微调Qwen3:Transformer小白也能看懂的大模型实战
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
一、为什么选择 Qwen3?先看硬实力
二、核心概念:什么是 “全参数微调”?
三、实战步骤:从 0 到 1 微调医学对话模型
3.1 环境搭建
3.2 数据集准备
3.3 加载模型
3.4 训练配置:用 SwanLab 监控训练过程
3.5 训练结果:模型学会 “先思考再回答”
四、完整代码
4.1 训练代码
4.2 推理代码
本文以「医学对话微调」为例,走一遍 Qwen3 全参数微调的完整流程,从环境搭建到训练监控,再到最终效果验证!
一、为什么选择 Qwen3?先看硬实力
在开始之前,我们得先搞清楚:为什么选 Qwen3 做微调基座?看一组数据就懂了
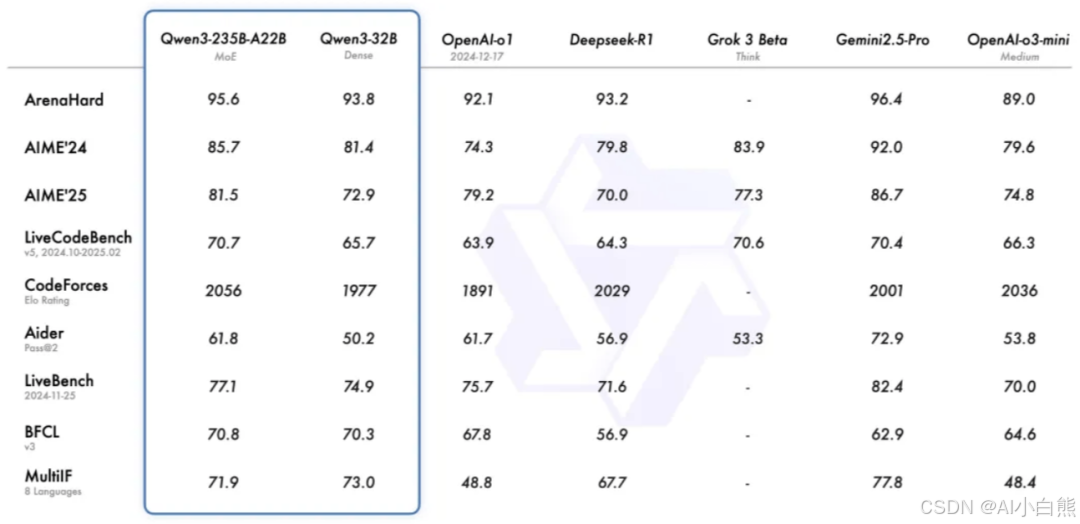
Qwen3 在多个权威评测榜单中表现突出,比如在 ArenaHard(硬难度对话评测)中,Qwen3-235B-A22B MoE 版本得分 95.6,超过 OpenAI o1 的 92.1;在代码能力评测 CodeForces Elo Rating 中,它以 2056 分领先众多开源模型。更重要的是,Qwen3 系列支持从 0.6B 到 235B 的多尺寸模型,从小模型练手到工业级部署都能覆盖。
简单说:性能强、开源免费、尺寸灵活,Qwen3 堪称微调入门的 “最优解” 之一。
二、核心概念:什么是 “全参数微调”?
微调是让大模型适配垂直领域的关键技术,而我们这次用的是「全参数微调」,得先搞懂它的核心逻辑:
- 全参数微调:更新预训练模型的所有参数(包括词嵌入、特征提取层、任务适配层),让模型整体适应新任务。
- 优势:能深度适配复杂任务(比如带推理过程的专业对话),充分利用预训练模型的泛化能力。
- 注意点:需要较多算力(约 32GB 显存),小数据集下容易过拟合,需配合学习率调整、正则化等策略。
如果你的显卡显存不足,也可以用 Qwen3-0.6B 小模型,或换成 LoRA 等参数高效微调方法。
三、实战步骤:从 0 到 1 微调医学对话模型
接下来进入实操环节,我们的目标是:基于 Qwen3-1.7B 模型,在医学数据集上微调,让模型能像专业医生一样,给出 “先思考、再回答” 的带推理过程的对话。
3.1 环境搭建
首先准备好运行环境,需要的工具包清单如下(建议 Python 3.8+):
- 核心框架:
transformers>=4.50.0(模型训练)、datasets==3.2.0(数据处理) - 算力支持:
pytorch+CUDA(需提前安装,确保显卡支持) - 辅助工具:
modelscope==1.22.0(国内模型下载)、swanlab(训练监控)、accelerate(分布式训练支持)
一键安装命令:
pip install swanlab modelscope==1.22.0 "transformers>=4.50.0" datasets==3.2.0 accelerate pandas addict
3.2 数据集准备
我们用的是医学领域数据集delicate_medical_r1_data,数据集下载链接:https://modelscope.cn/datasets/krisfu/delicate_medical_r1_data。包含 2000 + 条标注数据,每条数据有 3 个核心字段:
question:用户的医学问题(如 “儿童黄疸的遗传因素有哪些?”)think:医生的推理过程(类似 “先回忆遗传性黄疸类型,再分析代谢机制…”)answer:最终专业回答
关键处理步骤:
第一步:从 ModelScope 下载数据集:
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('krisfu/delicate_medical_r1_data', subset_name='default', split='train')
第二步:划分训练集和验证集(9:1),保存为 JSONL 格式:
import jsonimport random
data_list = list(ds)random.shuffle(data_list)split_idx = int(len(data_list)*0.9)# 保存训练集with open('train.jsonl', 'w', encoding='utf-8') as f: for item in data_list[:split_idx]: json.dump(item, f, ensure_ascii=False) f.write('\n')# 保存验证集with open('val.jsonl', 'w', encoding='utf-8') as f: for item in data_list[split_idx:]: json.dump(item, f, ensure_ascii=False) f.write('\n')
第三步:格式转换。将think和answer组合成模型输出,用特殊符号分隔推理过程和最终回答(方便模型区分):
# 示例格式:用「<think> </think>」包裹思考过程output = f"<think>{data['think']}</think> \n {data['answer']}"
3.3 加载模型
用 ModelScope 下载 Qwen3-1.7B 模型(国内下载速度快、稳定性高),再用 Transformers 加载:
from modelscope import snapshot_download, AutoTokenizerfrom transformers import AutoModelForCausalLM
# 下载模型到本地model_dir = snapshot_download("Qwen/Qwen3-1.7B", cache_dir="./", revision="master")# 加载tokenizer和模型tokenizer = AutoTokenizer.from_pretrained("./Qwen/Qwen3-1.7B", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained( "./Qwen/Qwen3-1.7B", device_map="auto", # 自动分配设备 torch_dtype=torch.bfloat16 # 用bfloat16节省显存)model.enable_input_require_grads() # 开启梯度计算(必要步骤)
3.4 训练配置:用 SwanLab 监控训练过程
训练过程中需要实时监控 loss、学习率等指标,这里用开源工具 SwanLab(被称为 “国产版 W&B”),配置步骤超简单:
核心训练参数设置
from transformers import TrainingArguments, Trainer
args = TrainingArguments( output_dir="./output/Qwen3-1.7B", # 模型保存路径 per_device_train_batch_size=1, # 单设备批次大小 gradient_accumulation_steps=4, # 梯度累积(显存不足时用) eval_strategy="steps", # 按步数验证 eval_steps=100, # 每100步验证一次 logging_steps=10, # 每10步打一次日志 num_train_epochs=2, # 训练轮次 learning_rate=1e-4, # 学习率 report_to="swanlab", # 用SwanLab监控 run_name="qwen3-1.7B-medical" # 实验名称)
启动训练
trainer = Trainer( model=model, args=args, train_dataset=train_dataset, # 处理好的训练集 eval_dataset=eval_dataset, # 处理好的验证集 data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True))trainer.train() # 开始训练
首次使用 SwanLab 需注册账号并输入 API Key,之后就能在网页端实时看到训练曲线啦~
3.5 训练结果:验证模型学会 “先思考再回答”
微调后的 Qwen3 能清晰区分 “思考过程” 和 “最终回答”,比如用户问 “抗溃疡药物分类”,模型会先拆解问题、回忆知识点,再给出结构化回答:
Question:医生,抗溃疡药物有哪些分类?作用机制是什么? LLM: <think>用户问抗溃疡药物的分类和作用机制,首先得回忆主要类别…抑酸药应该包括H2受体拮抗剂和质子泵抑制剂,比如雷尼替丁、奥美拉唑…胃黏膜保护剂比如硫糖铝,作用是形成保护膜…还要考虑抗幽门螺杆菌药物,通常是抗生素+PPI联合使用… </think>抗溃疡药物主要分为四类: 1. 抑酸药(如奥美拉唑):抑制胃酸分泌,减少黏膜损伤; 2. 胃黏膜保护剂(如硫糖铝):形成保护膜,增强黏膜屏障; 3. 促胃动力药(如多潘立酮):加速胃排空,减少反流; 4. 抗幽门螺杆菌药(如阿莫西林+PPI):杀灭病菌,降低复发风险。
四、完整代码
代码来自:https://developer.aliyun.com/article/1663178
4.1 训练代码
import jsonimport pandas as pdimport torchfrom datasets import Datasetfrom modelscope import snapshot_download, AutoTokenizerfrom transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seqimport osimport swanlab
os.environ["SWANLAB_PROJECT"]="qwen3-sft-medical"
PROMPT = "你是一个医学专家,你需要根据用户的问题,给出带有思考的回答。"MAX_LENGTH = 2048swanlab.config.update({ "model": "Qwen/Qwen3-1.7B", "prompt": PROMPT, "data_max_length": MAX_LENGTH, })
def dataset_jsonl_transfer(origin_path, new_path): """ 将原始数据集转换为大模型微调所需数据格式的新数据集 """ messages = [] # 读取旧的JSONL文件 with open(origin_path, "r") as file: for line in file: # 解析每一行的json数据 data = json.loads(line) input = data["question"] output = f"<think>{data["think"]}</think> \n {data["answer"]}" message = { "instruction": PROMPT, "input": f"{input}", "output": output, } messages.append(message) # 保存重构后的JSONL文件 with open(new_path, "w", encoding="utf-8") as file: for message in messages: file.write(json.dumps(message, ensure_ascii=False) + "\n")
def process_func(example): """ 将数据集进行预处理 """ input_ids, attention_mask, labels = [], [], [] instruction = tokenizer( f"<|im_start|>system\n{PROMPT}<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False, ) response = tokenizer(f"{example['output']}", add_special_tokens=False) input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id] attention_mask = ( instruction["attention_mask"] + response["attention_mask"] + [1] ) labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id] if len(input_ids) > MAX_LENGTH: # 做一个截断 input_ids = input_ids[:MAX_LENGTH] attention_mask = attention_mask[:MAX_LENGTH] labels = labels[:MAX_LENGTH] return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def predict(messages, model, tokenizer): device = "cuda" text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=MAX_LENGTH, ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] return response
# 在modelscope上下载Qwen模型到本地目录下model_dir = snapshot_download("Qwen/Qwen3-1.7B", cache_dir="/root/autodl-tmp/", revision="master")# Transformers加载模型权重tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/Qwen/Qwen3-1.7B", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("/root/autodl-tmp/Qwen/Qwen3-1.7B", device_map="auto", torch_dtype=torch.bfloat16)model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法# 加载、处理数据集和测试集train_dataset_path = "train.jsonl"test_dataset_path = "val.jsonl"train_jsonl_new_path = "train_format.jsonl"test_jsonl_new_path = "val_format.jsonl"if not os.path.exists(train_jsonl_new_path): dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)if not os.path.exists(test_jsonl_new_path): dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)# 得到训练集train_df = pd.read_json(train_jsonl_new_path, lines=True)train_ds = Dataset.from_pandas(train_df)train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)# 得到验证集eval_df = pd.read_json(test_jsonl_new_path, lines=True)eval_ds = Dataset.from_pandas(eval_df)eval_dataset = eval_ds.map(process_func, remove_columns=eval_ds.column_names)args = TrainingArguments( output_dir="/root/autodl-tmp/output/Qwen3-1.7B", per_device_train_batch_size=1, per_device_eval_batch_size=1, gradient_accumulation_steps=4, eval_strategy="steps", eval_steps=100, logging_steps=10, num_train_epochs=2, save_steps=400, learning_rate=1e-4, save_on_each_node=True, gradient_checkpointing=True, report_to="swanlab", run_name="qwen3-1.7B",)trainer = Trainer( model=model, args=args, train_dataset=train_dataset, eval_dataset=eval_dataset, data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),)trainer.train()# 用测试集的前3条,主观看模型test_df = pd.read_json(test_jsonl_new_path, lines=True)[:3]test_text_list = []for index, row in test_df.iterrows(): instruction = row['instruction'] input_value = row['input'] messages = [ {"role": "system", "content": f"{instruction}"}, {"role": "user", "content": f"{input_value}"} ] response = predict(messages, model, tokenizer) response_text = f""" Question: {input_value} LLM:{response} """ test_text_list.append(swanlab.Text(response_text)) print(response_text)swanlab.log({"Prediction": test_text_list})swanlab.finish()
4.2 推理代码
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizer
def predict(messages, model, tokenizer): device = "cuda" text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs = tokenizer([text], return_tensors="pt").to(device) generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=2048) generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)] response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] return response
# 加载原下载路径的tokenizer和modeltokenizer = AutoTokenizer.from_pretrained("./output/Qwen3-1.7B/checkpoint-1000", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("./output/Qwen3-1.7B/checkpoint-1000", device_map="auto", torch_dtype=torch.bfloat16)test_texts = { 'instruction': "你是一个医学专家,你需要根据用户的问题,给出带有思考的回答。", 'input': "医生,我最近被诊断为糖尿病,听说碳水化合物的选择很重要,我应该选择什么样的碳水化合物呢?"}instruction = test_texts['instruction']input_value = test_texts['input']messages = [ {"role": "system", "content": f"{instruction}"}, {"role": "user", "content": f"{input_value}"}]response = predict(messages, model, tokenizer)print(response)
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

欢迎加入北京社区
更多推荐



 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)