一文吃透检索增强生成(RAG):原理、LangChain 实战及企业级优化方案
一文吃透检索增强生成(RAG):原理、LangChain 实战及企业级优化方案
一. 什么是检索增强生成(RAG)
检索增强生成(Retrieval Augmented Generation, RAG)是一种融合外部知识库与语言模型能力的技术框架。它的核心价值在于解决大语言模型(LLM)的固有局限:模型训练数据是固定的时间切片(例如2023年之前的数据),无法实时更新;且对于专业领域知识覆盖有限,容易产生"幻觉"(生成错误信息)。
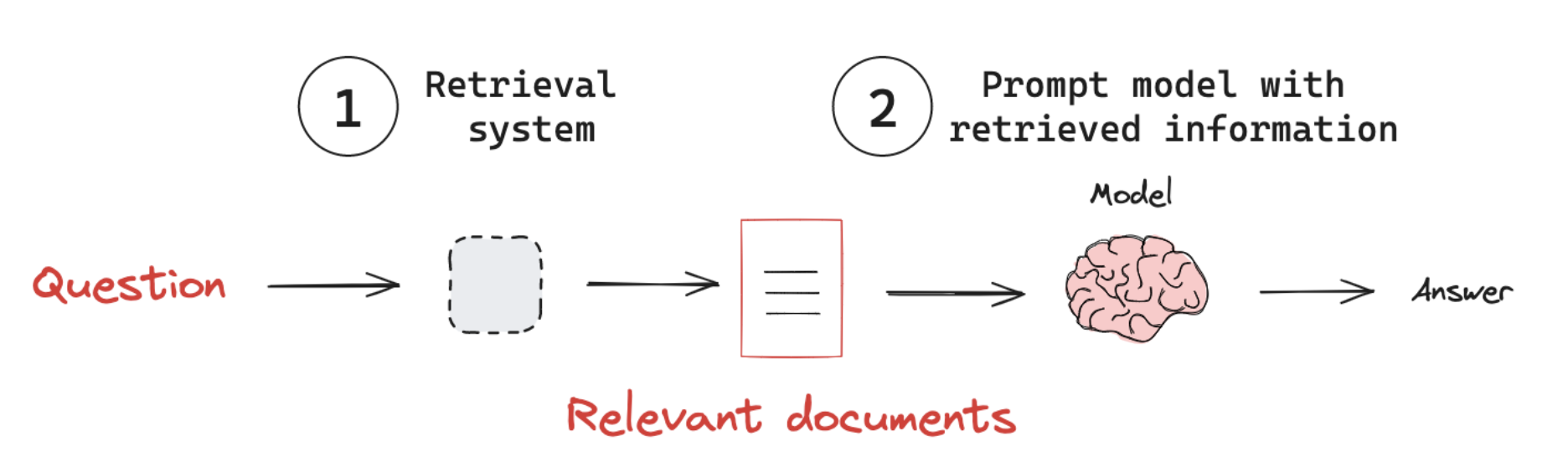
RAG的工作流程可概括为四步闭环:
- 接收用户的自然语言查询(如"2024年人工智能领域有哪些突破?")
- 检索系统根据查询语义,从外部知识库中定位最相关的信息片段
- 将检索到的信息作为上下文,与原始查询整合成新的提示词(Prompt)
- 语言模型基于增强后的上下文生成准确、有据可依的回答
这种机制让模型既能发挥生成能力,又能依托实时更新的外部知识,尤其适合需要精准信息支撑的场景(如客服问答、专业咨询等)。
二. RAG的核心技术模块
示例代码可参考:rag.ipynb,推荐使用Jupyter Notebook进行交互式调试。
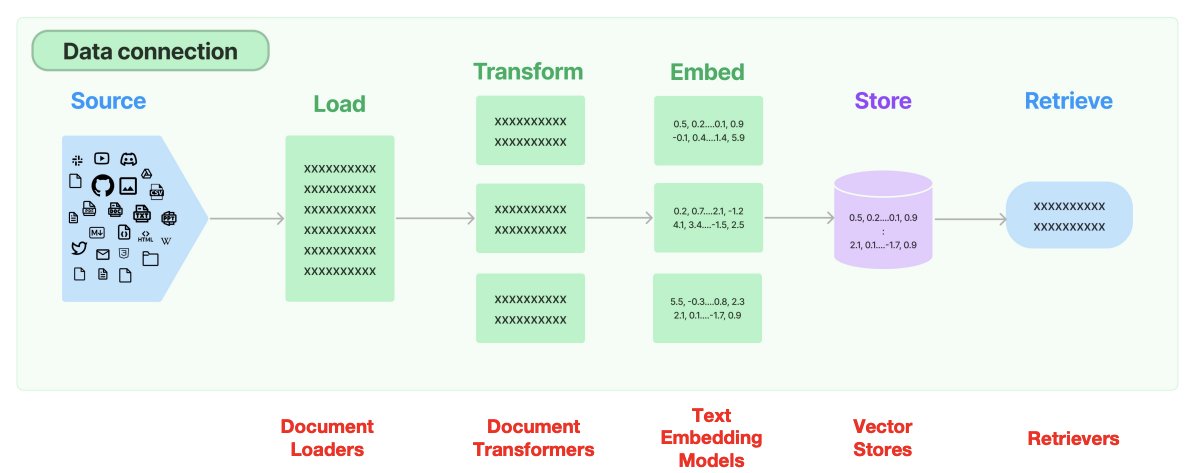
一个完整的RAG系统需经历从数据接入到智能检索的全链路处理,每个环节都有其技术要点:
- 文档加载与格式适配
- 文本智能分割
- 语义向量化转换
- 向量存储与索引优化
- 精准检索与结果过滤
2.1 文档加载:多源数据接入
LangChain框架提供了丰富的文档加载器,支持PDF、Word、Markdown、网页等多种格式。以PDF加载为例,可通过异步加载控制资源占用:
# PDF文档加载示例
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./DeepSeek_R1.pdf")
pages = []
# 异步加载前11页,避免一次性加载过大文件
async for page in loader.alazy_load():
if len(pages) >= 11: # 控制加载页数
break
pages.append(page)
print(f"元数据信息:{pages[0].metadata}\n") # 包含页码、文件路径等
print(f"第一页内容:{pages[0].page_content[:200]}...") # 预览内容
扩展说明:实际应用中,需根据文档类型选择加载器(如UnstructuredWordDocumentLoader处理Word,WebBaseLoader爬取网页),并处理加密文档、扫描件(需结合OCR工具)等特殊情况。
2.2 文本分割:语义单元划分
文本分割的核心是将长文档拆分为适合模型处理的语义单元(Chunk),既要保证单个单元的完整性,又要避免信息碎片化。
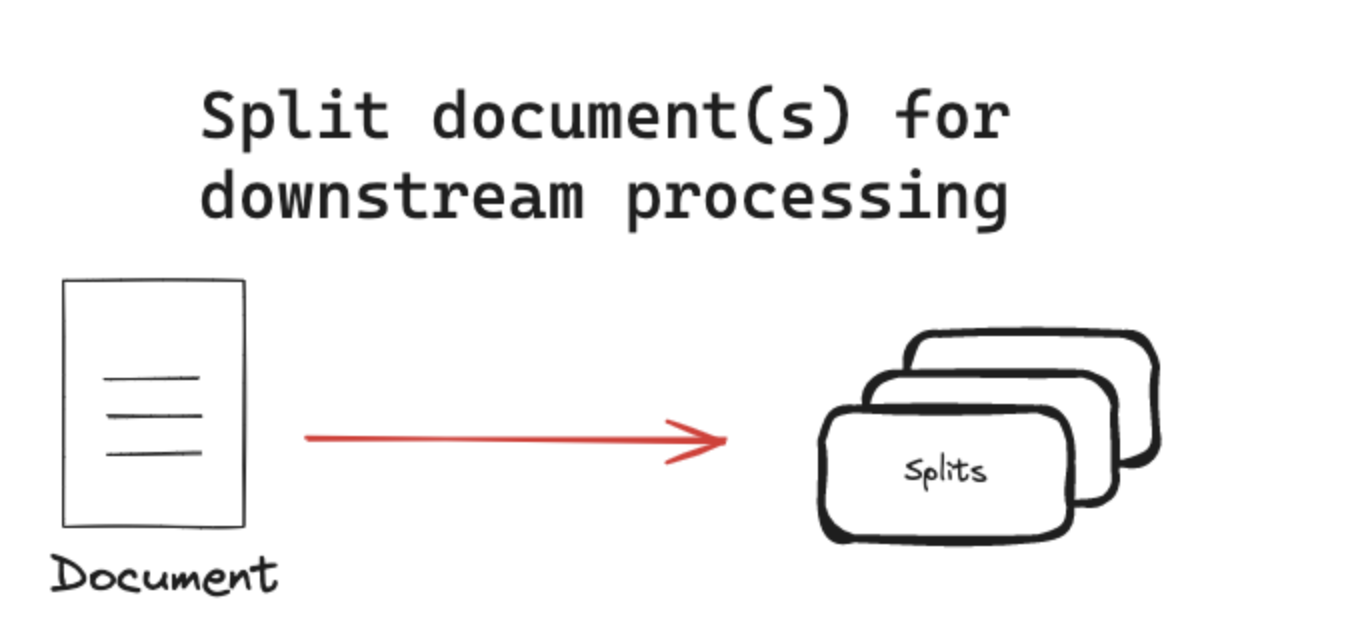
2.2.1 基于长度的分割:按字符/Token划分
这种策略适合结构简单的文本,直接按固定长度切割:
- Token-based:按语言模型的Token数分割(如GPT模型的Token),与模型处理能力匹配度高
- Character-based:按字符数分割,适用于对长度精度要求高的场景
from langchain_text_splitters import CharacterTextSplitter
# 基于tiktoken编码器的分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", # 与GPT-4同编码器
chunk_size=200, # 每个片段200Token
chunk_overlap=20 # 片段重叠20Token,保持上下文连贯
)
texts = text_splitter.split_text(pages[0].page_content)
print(f"分割后片段数:{len(texts)},首个片段:{texts[0]}")
小知识:1个Token约等于0.75个英文单词或1.5个中文字符。分割时需预留空间(如模型支持4096Token,可将chunk_size设为2000-3000),避免后续拼接时超出上限。
2.2.2 基于文本结构的分割:按语义边界划分
利用文本固有的段落、句子结构分割,更符合人类阅读逻辑,RecursiveCharacterTextSplitter是常用工具:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 最大字符数
chunk_overlap=100, # 重叠部分,保证语义连贯
separators=["\n\n", "\n", ". ", ",", " "] # 优先按段落分割,再按句子、标点
)
chunks = text_splitter.split_documents(pages)
print(f"文档被分割为 {len(chunks)} 个语义单元")
适用场景:新闻报道、散文等段落清晰的文本。
2.2.3 基于文档结构的分割:按格式标签划分
对HTML、Markdown等结构化文档,可按标签层级分割(如Markdown的#、##标题):
# Markdown文档分割示例
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 加载文档
loader = UnstructuredMarkdownLoader("产品说明.md")
documents = loader.load()
# 按标题层级分割(保留标题作为元数据)
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=[
("#", "一级标题"),
("##", "二级标题"),
("###", "三级标题")
])
chunks = splitter.split_text(documents[0].page_content)
# 输出结果(包含标题元数据)
for chunk in chunks[:2]:
print(f"元数据:{chunk.metadata},内容:{chunk.page_content[:100]}...")
2.2.4 基于语义的分割:按内容相关性划分
通过NLP模型计算句子间的语义相似度,在相似度突变处分割,适合专业论文、技术文档等复杂文本:
# 语义分割思路示例(需结合Sentence-BERT等模型)
from sentence_transformers import SentenceTransformer, util
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["句子1...", "句子2...", "句子3..."] # 先按句子拆分
embeddings = model.encode(sentences, convert_to_tensor=True)
# 计算句子间余弦相似度
similarities = [util.cos_sim(embeddings[i], embeddings[i+1]).item()
for i in range(len(sentences)-1)]
# 设定阈值,低于阈值处为分割点
threshold = 0.5
split_points = [i+1 for i, sim in enumerate(similarities) if sim < threshold]
优势:能最大程度保留语义完整性,减少"断句"问题。
2.3 向量化:语义的数字表达
向量化(Embedding)是将文本转换为固定长度向量的过程,向量的数值分布反映文本的语义特征。这种转换让计算机能通过向量距离(如余弦相似度)判断文本相关性。
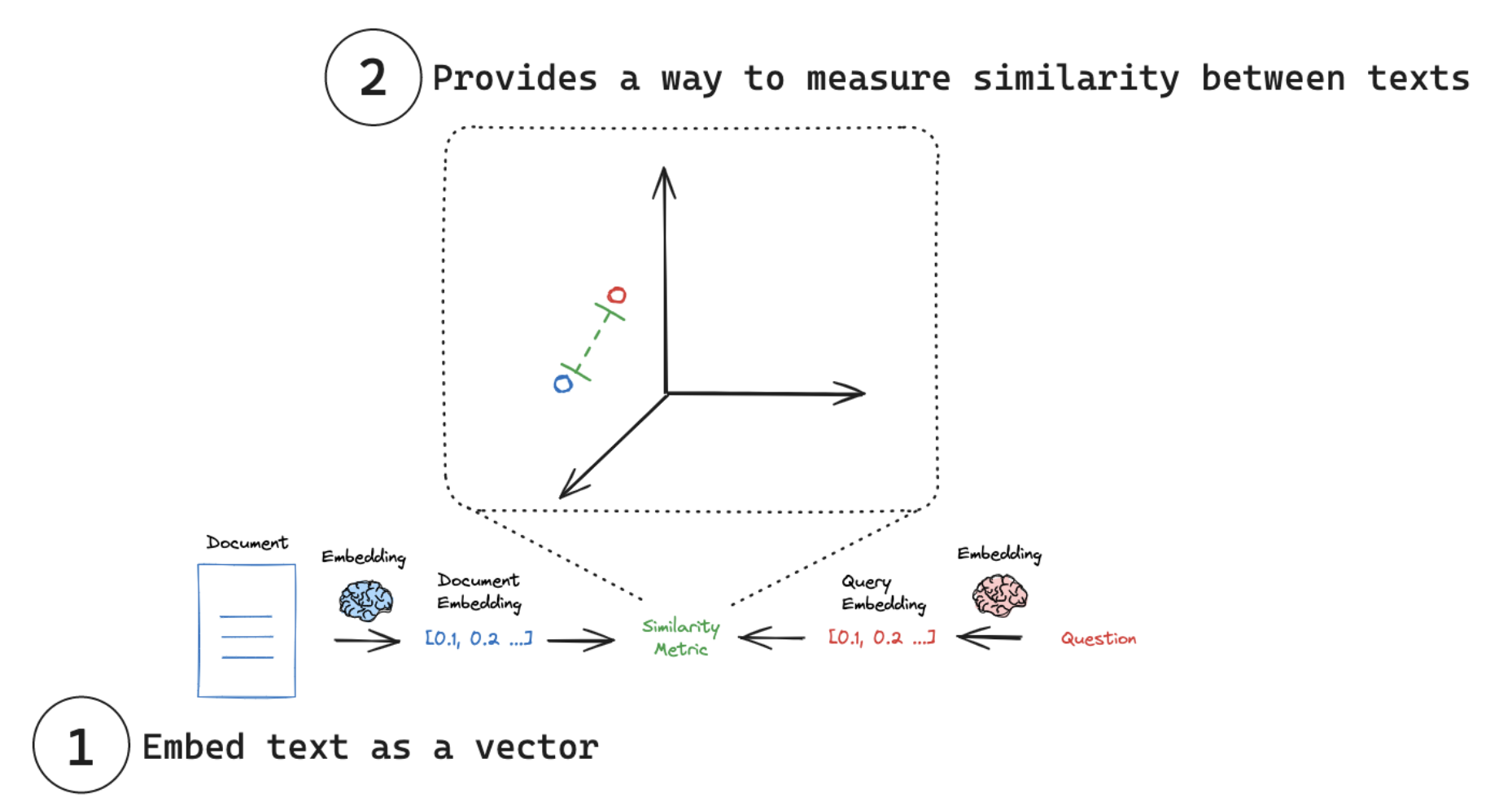
LangChain统一了向量化接口,支持OpenAI、讯飞、智谱等多种模型:
from langchain_openai import OpenAIEmbeddings
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") # 常用模型
# 对分割后的文档片段向量化
doc_embeddings = embeddings.embed_documents([chunks[0].page_content])
print(f"向量维度:{len(doc_embeddings[0])}(ada-002模型输出1536维向量)")
# 对用户查询向量化
query = "DeepSeek模型有哪些版本?"
query_embedding = embeddings.embed_query(query)
选型建议:开源场景可选BAAI/bge-large-en-v1.5(英文)、shibing624/text2vec-base-chinese(中文);商业场景可考虑OpenAI的text-embedding-3-large(更高精度)。
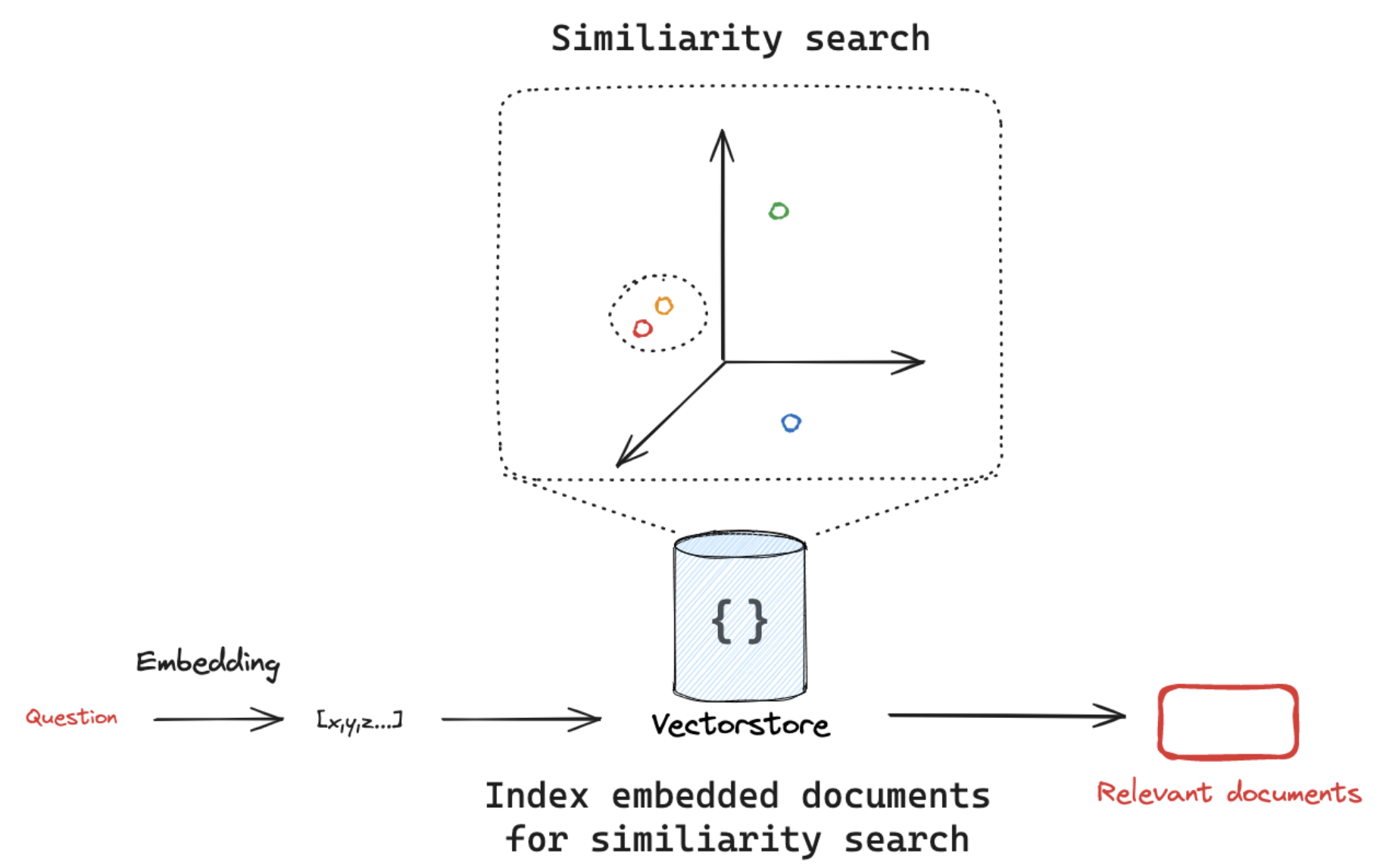
2.4 向量存储:语义数据库
向量存储(Vector Store)是专门存储和管理向量的数据库,支持高效的相似度检索。LangChain兼容数十种向量存储(如FAISS、Milvus、Pinecone等)。
# 基于内存的向量存储示例(适合小数据量测试)
from langchain_core.vectorstores import InMemoryVectorStore
# 初始化向量存储(关联嵌入模型)
vector_store = InMemoryVectorStore(embeddings)
# 存入分割后的文档向量
doc_ids = vector_store.add_documents(documents=chunks)
print(f"已存储 {len(doc_ids)} 个文档向量")
# 基本操作:删除、查询
vector_store.delete(ids=[doc_ids[0]]) # 删除指定文档
results = vector_store.similarity_search("DeepSeek的技术特点", k=3) # 检索 top3 相关文档
向量存储的扩展应用:
- 语义搜索:替代传统关键词搜索,支持"同义不同词"查询(如"如何退款"与"退货流程")
- 内容聚类:自动将相似文档分组(如按产品类别聚类用户反馈)
- 多模态检索:结合图像、音频向量,实现"以图搜文"等跨模态功能
2.5 检索器:精准定位信息
检索器(Retriever)是连接向量存储与上层应用的接口,负责根据查询向量从数据库中召回最相关的文档。LangChain提供了统一的检索接口,支持多种检索策略。
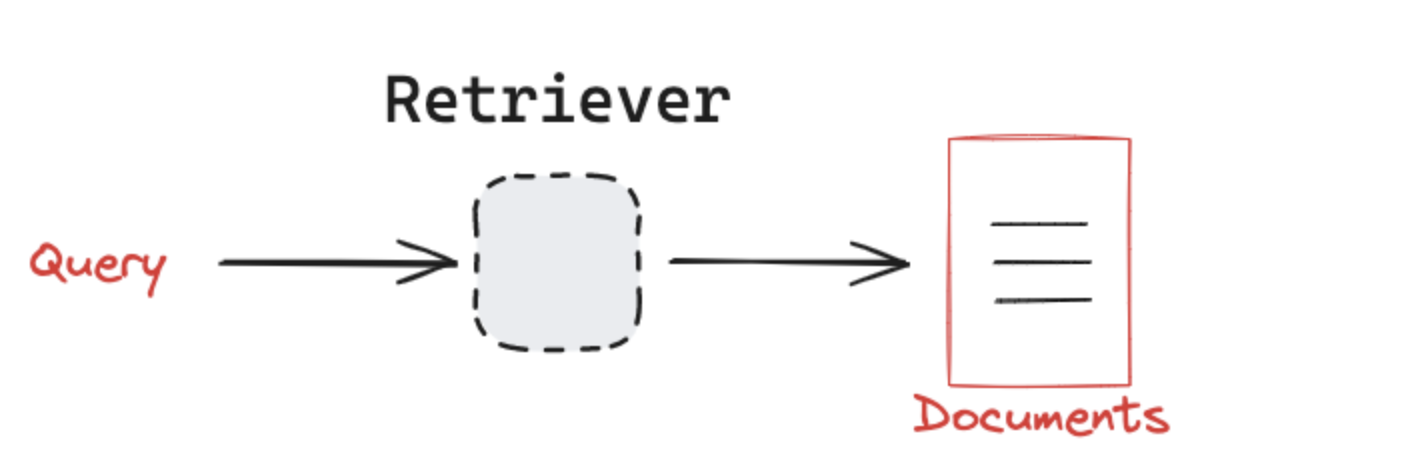
2.5.1 基础检索策略
通过as_retriever()方法配置检索参数,核心策略包括:
# 检索器配置示例
retriever = vector_store.as_retriever(
search_type="mmr", # 检索策略:similarity/mmr/similarity_score_threshold
search_kwargs={
"k": 5, # 返回结果数量
"lambda_mult": 0.3 # MMR策略的多样性参数(0-1,越小越多样)
}
)
# 执行检索
docs = retriever.invoke("Transformer与CNN的区别")
三种基础策略对比:
| 策略类型 | 核心逻辑 | 适用场景 | 优势 |
|---|---|---|---|
similarity |
按向量相似度排序,返回top-k结果 | 事实性问答(如"公司地址是什么") | 精准匹配,速度快 |
mmr(最大边际相关性) |
在相似度基础上增加多样性控制,避免结果重复 | 综合性查询(如"产品的优缺点") | 覆盖多维度信息 |
similarity_score_threshold |
只返回相似度超过阈值的结果 | 高精度场景(如法律条文检索) | 过滤低相关内容 |
2.5.2 高级检索增强技术
为提升检索效果,可结合以下增强工具:
- MultiQueryRetriever:通过LLM生成多个相似查询,扩大检索范围
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
# 基于LLM的多查询扩展
llm = ChatOpenAI(temperature=0) # 零温度保证生成稳定性
multi_retriever = MultiQueryRetriever.from_llm(
retriever=retriever,
llm=llm
)
# 原始查询:"如何申请报销"
# 扩展查询可能包括:"报销流程是什么"、"怎样提交报销申请"等
docs = multi_retriever.invoke("如何申请报销")
- ContextualCompressionRetriever:过滤检索结果中的冗余信息
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 用LLM压缩文档(保留核心信息)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
# 检索结果已被压缩
compressed_docs = compression_retriever.invoke("请假规定")
三. RAG实战案例
3.1 企业员工手册检索系统
场景需求:构建一个能快速查询员工手册(含PDF、Word、TXT)的问答系统,支持员工自助查询规章制度。
技术方案:
- 多格式文档加载(PyPDFLoader、UnstructuredWordDocumentLoader等)
- FAISS向量存储(轻量级,适合中小规模数据)
- MultiQueryRetriever提升召回率
- RetrievalQA链实现"检索-生成"闭环
代码结构:
员工手册的检索系统/
├── docs/ # 原始文档与向量存储文件
│ ├── 员工手册.pdf
│ ├── 福利政策.docx
│ └── index.faiss # 预生成的向量索引
├── Langchain_QA.ipynb # 交互式调试脚本
└── Langchain_QA.py # 可直接运行的脚本
关键代码片段:
# 加载预生成的向量存储(避免重复向量化)
from langchain_community.vectorstores import FAISS
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
vector_store = FAISS.load_local(
folder_path="./docs",
embeddings=embedding,
allow_dangerous_deserialization=True
)
# 构建问答链
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0), # 零温度确保回答严谨
chain_type="stuff", # 将检索结果直接填入prompt
retriever=vector_store.as_retriever(search_kwargs={"k": 3})
)
# 测试查询
print(qa_chain.run("应聘时需要提供哪些材料?"))
运行效果:
- 支持模糊查询(如"入职材料"与"应聘资料"均可触发正确结果)
- 回答附带来源页码(方便员工核对原始文档)
3.2 网页内容多轮对话系统
场景需求:加载指定网页(如技术博客)内容,支持基于该内容的多轮对话(如"上文提到的Agent架构有哪些模块?")。
技术方案:
- WebBaseLoader加载网页内容
- ConversationBufferMemory保存对话历史
- 自定义Prompt模板整合上下文
- 流式输出提升交互体验
核心实现:
# 加载网页内容
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
# 构建带记忆的对话链
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 对话历史存储键
return_messages=True # 返回Message对象而非字符串
)
# 多轮对话链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0.3),
retriever=vector_store.as_retriever(),
memory=memory,
chain_type="refine" # 基于历史回答优化新回答
)
# 流式输出
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
streaming_llm = ChatOpenAI(
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
temperature=0
)
运行效果:
- 系统能理解上下文依赖(如"它的核心功能是什么"中的"它"指代前文提到的模型)
- 流式输出让回答过程更自然(类似人类打字)
四. 企业级RAG系统的进阶考量
基础RAG流程适用于原型开发,企业级系统需在各环节进行强化,以应对大规模数据、高并发请求和严格的准确性要求。
4.1 数据预处理:从"能用"到"好用"
企业文档往往存在格式混乱、噪声多等问题,需强化预处理:
- 多模态处理:对含图片的文档(如产品手册),用OCR工具(如PaddleOCR)提取图片文字,避免信息丢失
- 噪声清洗:去除文档中的冗余内容(如页眉页脚、重复水印)、修正错别字(结合
pycorrector等工具) - 结构化转换:将非结构化文本(如邮件、聊天记录)转换为统一格式(如JSON),便于后续分割
4.2 文本分割:分层索引策略
企业文档常包含多级结构(如"公司制度-部门规范-操作细则"),可采用分层索引:
- 一级索引:文档级向量(用于快速定位相关文档)
- 二级索引:章节级向量(缩小检索范围)
- 三级索引:段落级向量(精确匹配细节)
# 分层索引示例(伪代码)
# 1. 文档级向量存储
doc_level_store = FAISS.from_documents(full_docs, embeddings)
# 2. 对每个文档分割为章节,构建章节级存储
chapter_level_stores = {}
for doc in full_docs:
chapters = split_into_chapters(doc) # 按标题分割章节
chapter_level_stores[doc.id] = FAISS.from_documents(chapters, embeddings)
4.3 向量存储:分布式与混合存储
- 大规模数据:采用分布式向量数据库(如Milvus、Zilliz),支持水平扩展
- 混合存储:结合向量库与关系数据库(如PostgreSQL+pgvector插件),既支持语义检索,又能通过SQL进行结构化条件过滤(如"检索2024年后发布的产品文档")
4.4 检索优化: query理解与重写
用户查询常存在模糊、口语化问题(如"我想知道那个报销的事"),需通过LLM优化:
# 查询重写示例
def rewrite_query(query):
prompt = f"""将用户的模糊查询改写为精准的检索词:
用户查询:{query}
改写结果:"""
return llm.invoke(prompt).content
# 优化前:"那个请假的规定"
# 优化后:"员工请假的申请流程、审批条件及假期时长规定"
refined_query = rewrite_query(user_input)
docs = retriever.invoke(refined_query)
4.5 缓存与监控
- 结果缓存:对高频查询(如"上下班时间")缓存结果,降低计算成本
- 效果监控:记录检索准确率(如人工标注相关度)、用户反馈,持续优化分割策略与检索参数
总结
RAG技术通过"检索增强生成"的模式,有效弥补了大语言模型在实时性、专业性上的不足,已成为企业构建智能问答系统的核心方案。从基础流程到企业级落地,需重点关注数据预处理的完整性、文本分割的合理性、检索策略的精准性,以及系统的可扩展性。
随着技术发展,RAG正与多模态理解、智能Agent等领域融合,未来将在更复杂的场景(如智能客服、专业咨询)中发挥更大价值。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)