
Xception卷积神经网络动物识别
一随着人工智能技术的飞速发展,图像识别在众多领域都有着广泛的应用。动物识别作为图像识别的一个重要分支,对于野生动物保护、宠物管理、生态研究等诸多方面都有着重要的意义。例如,在野生动物保护中,通过自动识别动物种类,可以更高效地进行物种监测和保护工作;在宠物管理方面,能够快速准确地识别宠物种类,有助于宠物走失后的快速找回等。本项目旨在利用深度学习中的卷积神经网络(Xception)来实现动物识别功能,
随着人工智能技术的飞速发展,图像识别在众多领域都有着广泛的应用。动物识别作为图像识别的一个重要分支,对于野生动物保护、宠物管理、生态研究等诸多方面都有着重要的意义。例如,在野生动物保护中,通过自动识别动物种类,可以更高效地进行物种监测和保护工作;在宠物管理方面,能够快速准确地识别宠物种类,有助于宠物走失后的快速找回等。本项目旨在利用深度学习中的卷积神经网络(Xception)来实现动物识别功能,以提高动物识别的准确性和效率,为相关领域提供一种有效的技术解决方案。
数据来源与预处理
数据来源为Kaggle上的动物识别数据集。我们使用了“Animals-10”数据集,该数据集包含十种动物(狗、猫、马、大象、蝴蝶、鸡、牛、羊、蜘蛛、松鼠)的图片,每种动物有大约一两千张图片,图片格式为JPEG。此外,我们还参考了Kaggle上的猫狗识别数据集,该数据集共包含25000张JPEG图片,其中猫和狗的照片各占12500张。
Xception是谷歌公司继Inception后,提出的InceptionV3的一种改进模型,其中Inception模块已被深度可分离卷积(depthwise separable convolution)替换。它与Inception-v1(23M)的参数数量大致相同。
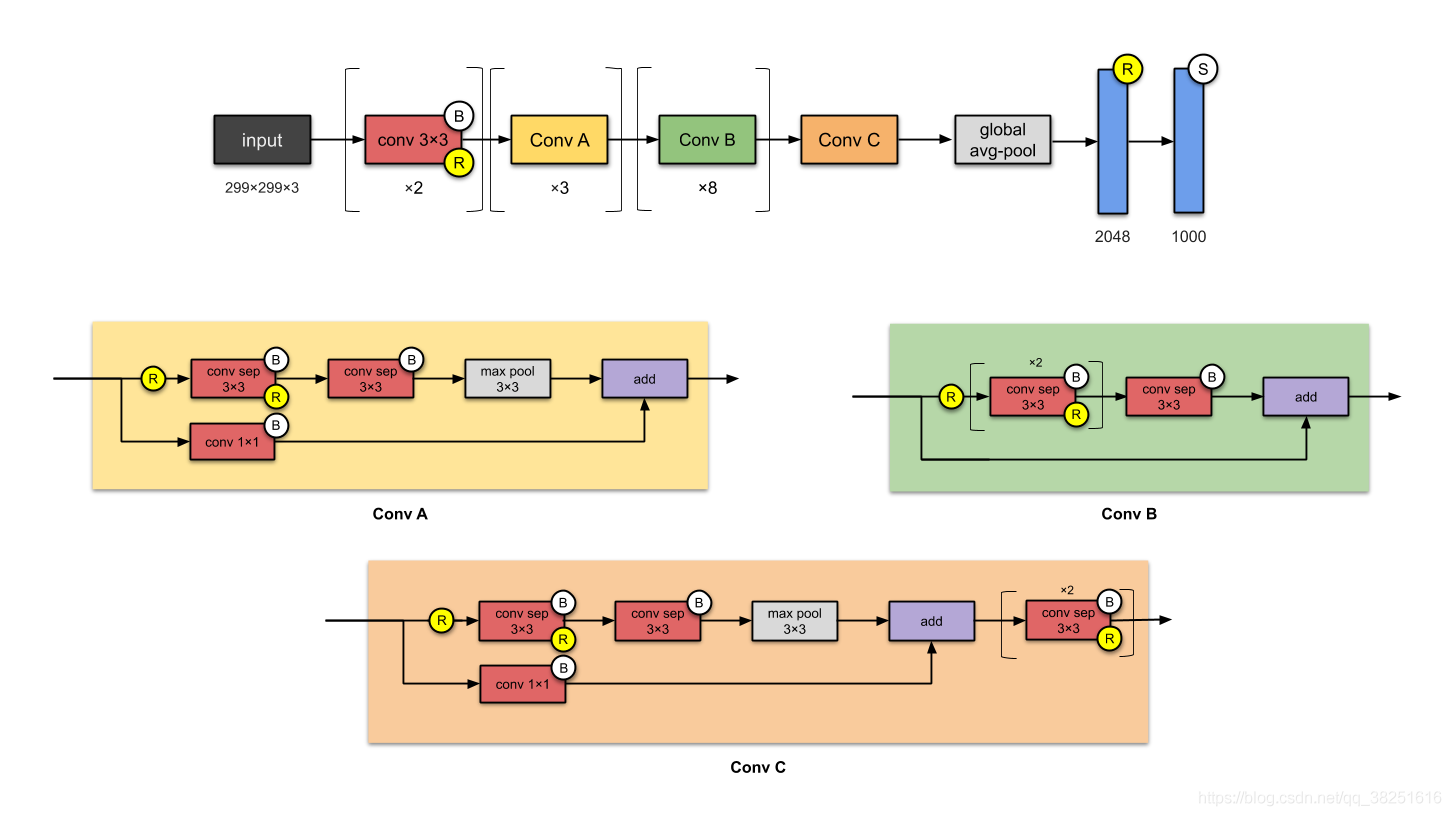
1. 深度可分离卷积
深度可分离卷积其实是一种可分解卷积操作(factorized convolutions)。其可以分解为两个更小的操作:depthwise convolution 和
olution。
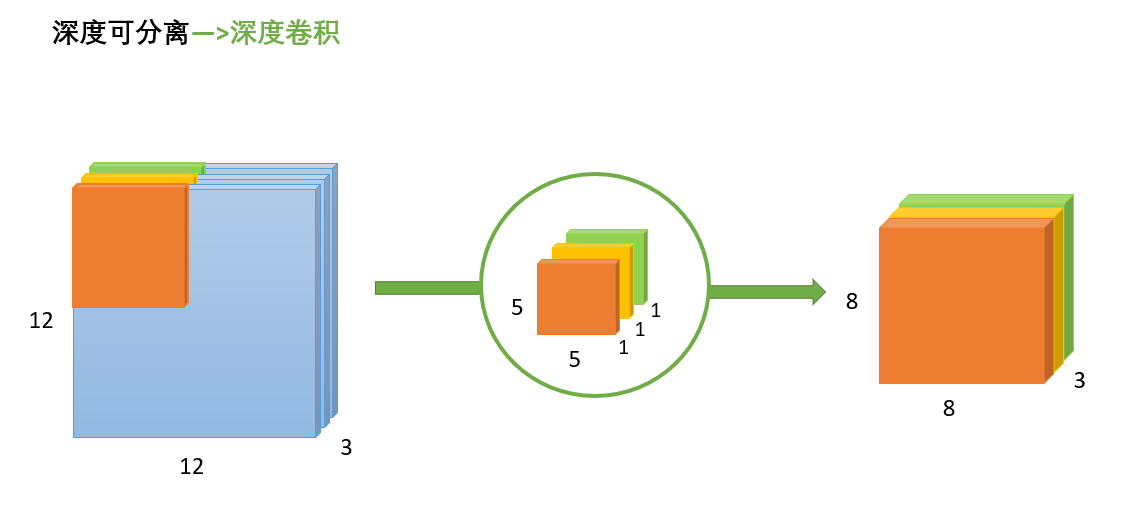
(2)深度卷积
(3)逐点卷积
逐点卷积就是1*1卷积,主要作用就是对特征图进行升维和降维,如下图:
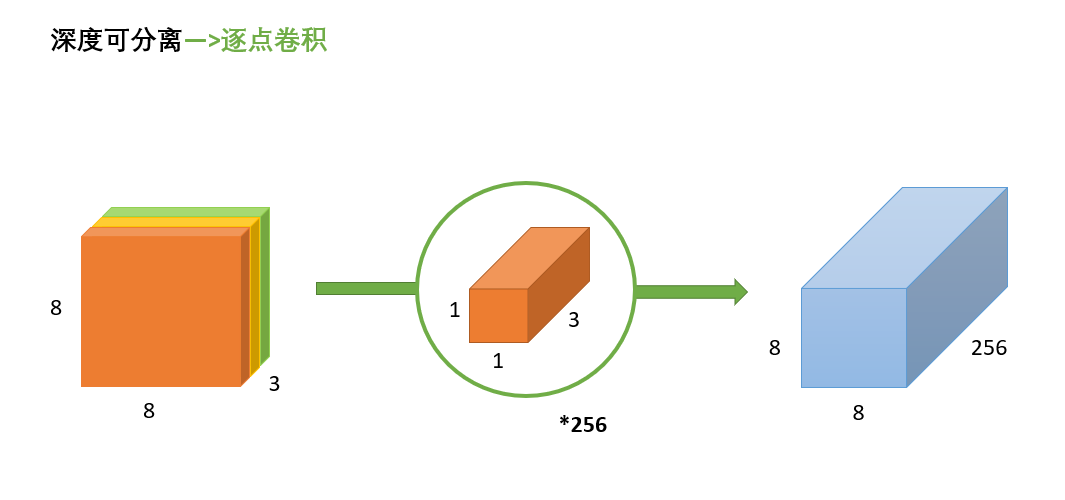
在深度卷积的过程中,我们得到了883的输出特征图,我们用256个113的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样都是88256了。
标准卷积与深度可分离卷积的过程对比如下:
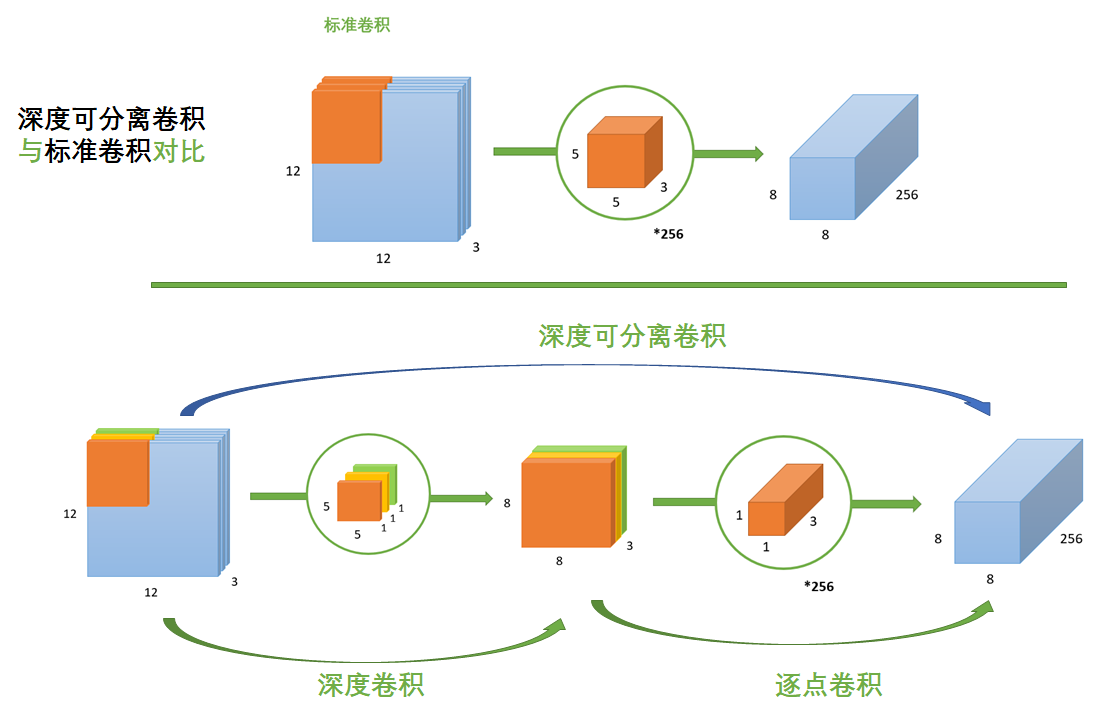
(4)为什么要用深度可分离卷积?
深度可分离卷积可以实现更少的参数,更少的运算量。
一、构建Xception模型
#====================================#
# Xception的网络部分
#====================================#
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras import layers
from tensorflow.keras.layers import Dense,Input,BatchNormalization,Activation,Conv2D,SeparableConv2D,MaxPooling2D
from tensorflow.keras.layers import GlobalAveragePooling2D,GlobalMaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.applications.imagenet_utils import decode_predictions
def Xception(input_shape = [299,299,3],classes=1000):
img_input = Input(shape=input_shape)
#=================#
# Entry flow
#=================#
# block1
# 299,299,3 -> 149,149,64
x = Conv2D(32, (3, 3), strides=(2, 2), use_bias=False, name='block1_conv1')(img_input)
x = BatchNormalization(name='block1_conv1_bn')(x)
x = Activation('relu', name='block1_conv1_act')(x)
x = Conv2D(64, (3, 3), use_bias=False, name='block1_conv2')(x)
x = BatchNormalization(name='block1_conv2_bn')(x)
x = Activation('relu', name='block1_conv2_act')(x)
# block2
# 149,149,64 -> 75,75,128
residual = Conv2D(128, (1, 1), strides=(2, 2), padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False, name='block2_sepconv1')(x)
x = BatchNormalization(name='block2_sepconv1_bn')(x)
x = Activation('relu', name='block2_sepconv2_act')(x)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False, name='block2_sepconv2')(x)
x = BatchNormalization(name='block2_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block2_pool')(x)
x = layers.add([x, residual])
# block3
# 75,75,128 -> 38,38,256
residual = Conv2D(256, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block3_sepconv1_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False, name='block3_sepconv1')(x)
x = BatchNormalization(name='block3_sepconv1_bn')(x)
x = Activation('relu', name='block3_sepconv2_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False, name='block3_sepconv2')(x)
x = BatchNormalization(name='block3_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block3_pool')(x)
x = layers.add([x, residual])
# block4
# 38,38,256 -> 19,19,728
residual = Conv2D(728, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block4_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block4_sepconv1')(x)
x = BatchNormalization(name='block4_sepconv1_bn')(x)
x = Activation('relu', name='block4_sepconv2_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block4_sepconv2')(x)
x = BatchNormalization(name='block4_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block4_pool')(x)
x = layers.add([x, residual])
#=================#
# Middle flow
#=================#
# block5--block12
# 19,19,728 -> 19,19,728
for i in range(8):
residual = x
prefix = 'block' + str(i + 5)
x = Activation('relu', name=prefix + '_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv1')(x)
x = BatchNormalization(name=prefix + '_sepconv1_bn')(x)
x = Activation('relu', name=prefix + '_sepconv2_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv2')(x)
x = BatchNormalization(name=prefix + '_sepconv2_bn')(x)
x = Activation('relu', name=prefix + '_sepconv3_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv3')(x)
x = BatchNormalization(name=prefix + '_sepconv3_bn')(x)
x = layers.add([x, residual])
#=================#
# Exit flow
#=================#
# block13
# 19,19,728 -> 10,10,1024
residual = Conv2D(1024, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block13_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block13_sepconv1')(x)
x = BatchNormalization(name='block13_sepconv1_bn')(x)
x = Activation('relu', name='block13_sepconv2_act')(x)
x = SeparableConv2D(1024, (3, 3), padding='same', use_bias=False, name='block13_sepconv2')(x)
x = BatchNormalization(name='block13_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block13_pool')(x)
x = layers.add([x, residual])
# block14
# 10,10,1024 -> 10,10,2048
x = SeparableConv2D(1536, (3, 3), padding='same', use_bias=False, name='block14_sepconv1')(x)
x = BatchNormalization(name='block14_sepconv1_bn')(x)
x = Activation('relu', name='block14_sepconv1_act')(x)
x = SeparableConv2D(2048, (3, 3), padding='same', use_bias=False, name='block14_sepconv2')(x)
x = BatchNormalization(name='block14_sepconv2_bn')(x)
x = Activation('relu', name='block14_sepconv2_act')(x)
x = GlobalAveragePooling2D(name='avg_pool')(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
inputs = img_input
model = Model(inputs, x, name='xception')
return modelmodel = Xception()
# 打印模型信息
model.summary() 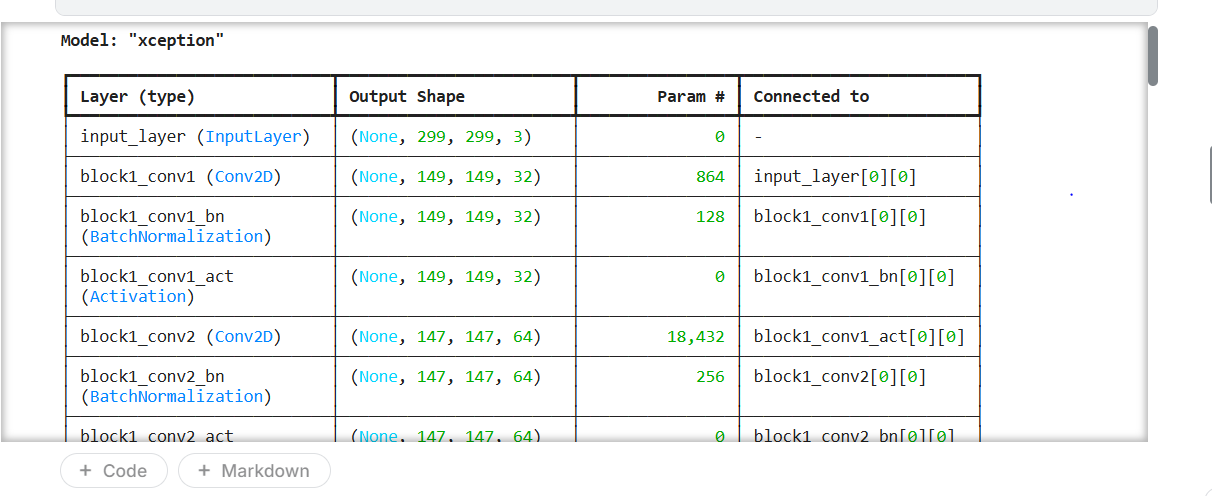
二、设置动态学习率
这里先罗列一下学习率大与学习率小的优缺点。
-
学习率大
- 优点: 1、加快学习速率。 2、有助于跳出局部最优值。
- 缺点: 1、导致模型训练不收敛。 2、单单使用大学习率容易导致模型不精确。
-
学习率小
- 优点: 1、有助于模型收敛、模型细化。 2、提高模型精度。
- 缺点: 1、很难跳出局部最优值。 2、收敛缓慢。
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=300,
decay_rate=0.96,
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)三、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 损失函数(loss):用于估量预测值与真实值的不一致程度。
- 评价函数(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer=optimizer,
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])四、训练模型
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)五、模型评估
1. Accuracy与Loss图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()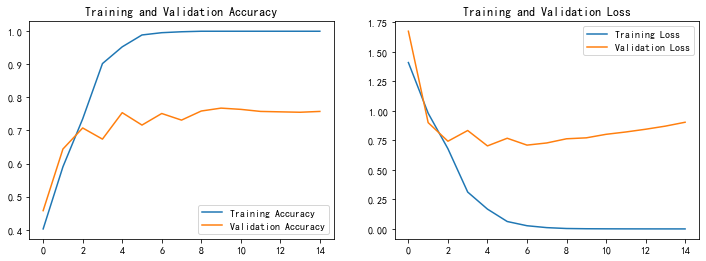
2. 混淆矩阵
Seaborn 是一个画图库,它基于 Matplotlib 核心库进行了更高阶的 API 封装,可以让你轻松地画出更漂亮的图形。Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):
# 生成混淆矩阵
conf_numpy = confusion_matrix(labels, predictions)
# 将矩阵转化为 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('混淆矩阵',fontsize=15)
plt.ylabel('真实值',fontsize=14)
plt.xlabel('预测值',fontsize=14)val_pre = []
val_label = []
for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵
for image, label in zip(images, labels):
# 需要给图片增加一个维度
img_array = tf.expand_dims(image, 0)
# 使用模型预测图片中的人物
prediction = model.predict(img_array)
val_pre.append(class_names[np.argmax(prediction)])
val_label.append(class_names[label])plot_cm(val_label, val_pre)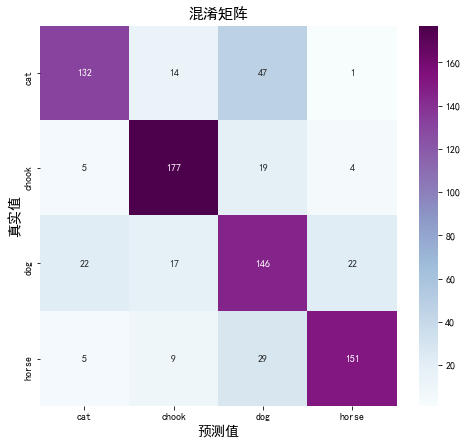
六、保存和加载模型
# 保存模型
model.save('model/24_model.h5')
# 加载模型
new_model = tf.keras.models.load_model('model/24_model.h5')
经过本项目的实践,我们成功构建了一个基于Xception卷积神经网络的动物识别模型,不仅深入理解了深度学习在图像识别领域的应用,还掌握了数据处理、模型优化等关键技能。未来,我们计划进一步优化模型结构,探索更高效的数据增强方法,以提高模型的准确率和泛化能力

欢迎加入北京社区
更多推荐



 49
49 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)