
【LlamaIndex核心组件指南 | 模型篇】一文通晓 LlamaIndex 模型层:LLM、Embedding 及多模态应用
在人工智能技术快速发展的背景下,大语言模型(LLM)虽然能力强大,但其知识往往局限于训练数据,无法直接访问我们私有的、实时的外部数据源。如何安全、高效地将 LLM 与我们的数据连接起来,构建强大的检索增强生成(RAG)应用,已成为开发者的核心议题。LlamaIndex正是为解决这一问题而生的。
【LlamaIndex核心组件指南 | 模型篇】一文通晓 LlamaIndex 模型层:LLM、Embedding 及多模态应用
原创 吴师兄AI纪要 [吴师兄AI纪要](javascript:void(0)😉 2025年06月26日 20:16 北京
前言
在人工智能技术快速发展的背景下,大语言模型(LLM)虽然能力强大,但其知识往往局限于训练数据,无法直接访问我们私有的、实时的外部数据源。如何安全、高效地将 LLM 与我们的数据连接起来,构建强大的检索增强生成(RAG)应用,已成为开发者的核心议题。LlamaIndex正是为解决这一问题而生的。
LlamaIndex 是一个领先的开源数据框架,旨在帮助开发者轻松构建、优化和部署基于自定义数据的 LLM 应用。通过 LlamaIndex,开发者可以无缝集成数据加载、索引构建、查询引擎、响应合成等一系列复杂功能,极大地简化了 RAG 应用的开发流程。
LlamaIndex 的核心组件
LlamaIndex 由一系列高度模块化的组件构成,每个组件都专注于 RAG 流程中的特定任务:
-
\1. Loading (数据加载)
-
- • 提供数百个数据连接器(Data Connectors),用于从各种来源(如本地文件、Notion、数据库、API)摄取数据。
- • 将加载的数据统一转换为标准的
Document对象,便于后续处理。
-
\2. Indexing (索引构建)
-
- • 负责将非结构化或结构化的
Document数据转换为 LLM 能够高效查询的数据结构(即索引)。 - • 支持多种索引类型,如
向量存储索引 (VectorStoreIndex)、知识图谱索引 (PropertyGraphIndex)等。
- • 负责将非结构化或结构化的
-
\3. Storing (持久化存储)
-
- • 管理数据和索引的持久化,确保应用的可扩展性和状态保持。
- • 包含
文档存储 (Docstore)、索引存储 (IndexStore)和向量存储 (VectorStore)三大组件。
-
\4. Querying (查询引擎)
-
- • 是 RAG 的核心执行者,接收用户查询,并从索引中检索相关信息。
- • 通过
响应合成 (Response Synthesis)模块将检索到的上下文和用户查询整合,生成最终答案。
-
\5. Models (模型)
-
- • 提供与各种
大语言模型 (LLMs)、嵌入模型 (Embeddings)和多模态模型 (Multi-modal Models)交互的统一接口。 - • 是驱动整个应用理解、表示和生成信息的大脑。
- • 提供与各种
-
\6. Agents (智能体)
-
- • 赋予 LLM 超越简单问答的能力,使其能够使用外部工具(如 API 调用、数据库查询)来执行多步骤的复杂任务。
- • 是构建自动化工作流和实现更高级别自主性的关键。
LlamaIndex 的应用场景
LlamaIndex 的模块化和 RAG 专注设计使其在以下场景中表现出色:
- • 智能问答与知识库:构建基于海量私有文档(PDF、Word、Notion)、数据库或企业知识图谱的智能问答机器人。
- • 文档理解与摘要:对大量、复杂的非结构化文档进行深度分析、信息提取和自动化摘要。
- • 结构化数据分析:连接到 SQL 或图数据库,用自然语言查询结构化数据并获得分析结果。
- • 自主研究智能体:创建能够主动查询外部数据源、执行代码、并综合信息生成研究报告的自动化智能体。
- • 多模态 RAG 应用:构建能够同时理解文本和图像内容,并基于图文信息进行问答的应用。
本文主题
本篇文章将深度聚焦于 LlamaIndex 的核心驱动组件:模型 (Models)。我们将详细拆解 LlamaIndex 如何管理和应用模型,并通过丰富的代码示例,帮助您彻底理解如何为您的应用选择和配置正确的大脑。
通过阅读本文,您将学会:
- \1. LlamaIndex 中
模型 (Models)组件的核心作用和三大分类。 - \2. 如何配置和使用不同的
大语言模型 (LLMs),包括实现完全自定义的模型。 - \3. 如何选择和应用
嵌入模型 (Embeddings)来实现高质量的语义检索。 - \4. 如何利用
多模态模型 (Multi-modal Models)构建能够理解图像的下一代 RAG 应用。
在深入探讨之前,让我们先通过一个流程图来了解 LlamaIndex 中一个典型 RAG 应用的生命周期,以及模型在其中扮演的关键角色。
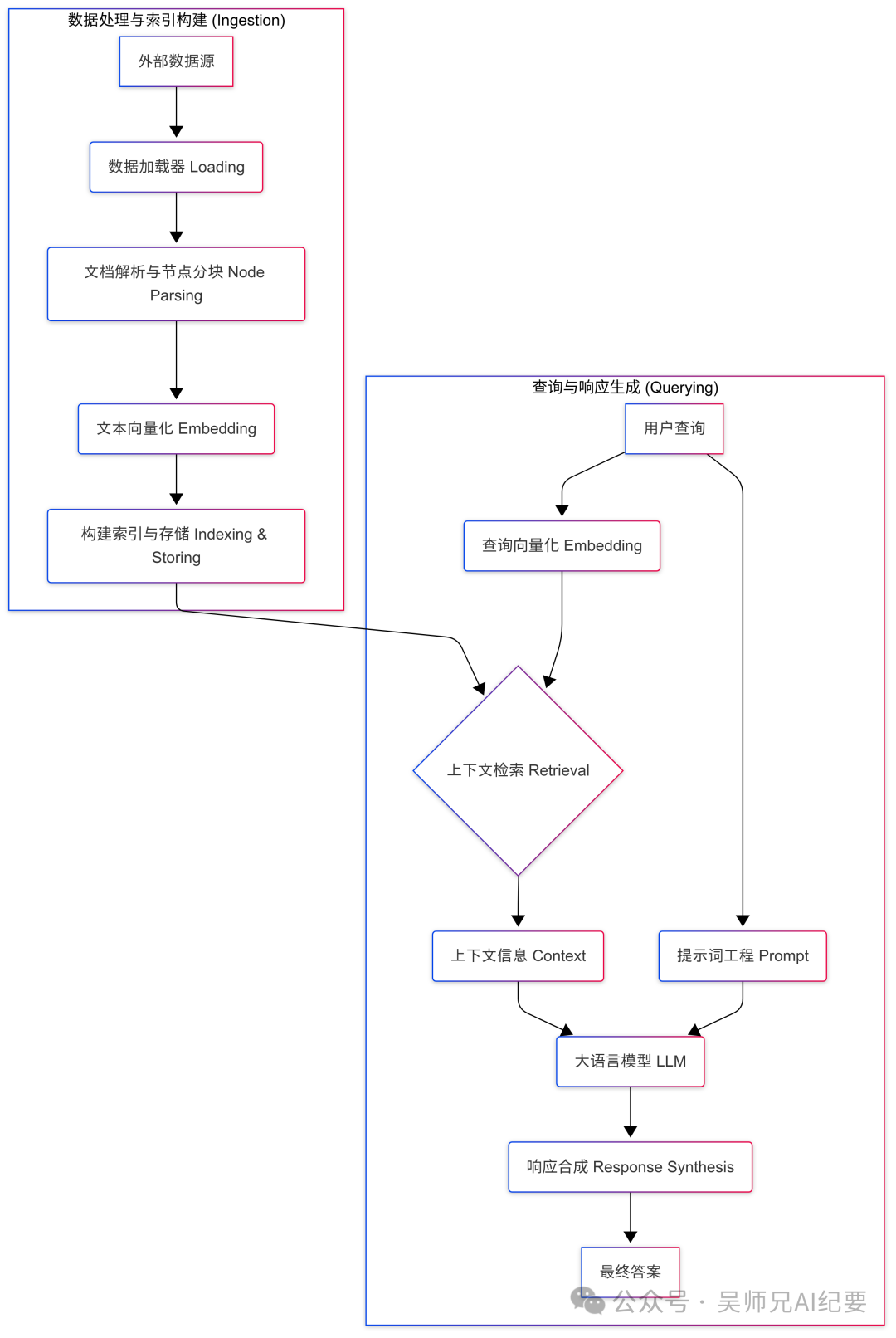
图:LlamaIndex RAG 核心工作流
从上图可以看出,模型(特别是 Embedding 和 LLM)贯穿了数据处理和查询响应的整个流程,是实现智能化的基石。接下来,让我们逐一揭开它们的神秘面纱。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、大语言模型 (LLMs)
大语言模型(LLM)是任何 LLM 应用的核心引擎,负责文本生成和逻辑推理。在 LlamaIndex 中,LLM 不仅用于在检索到相关上下文后生成最终答案,还可能在索引构建、节点插入和查询路由等多个环节发挥作用。
1.1 LLM 组件的核心作用
选择一个合适的 LLM 是构建应用的第一步。LlamaIndex 的设计哲学是提供一个统一、简洁的 LLM 接口,使开发者可以无缝切换和使用来自 OpenAI, Hugging Face, LangChain 等不同来源的模型,而无需关心底层的样板代码。
这个统一接口主要提供以下支持:
- • 文本补全与聊天模式:支持
complete(针对文本续写) 和chat(针对多轮对话) 两种主流交互模式。 - • 流式与非流式传输:支持
stream_complete等流式接口,可实现打字机效果,提升用户体验。 - • 同步与异步调用:全面支持同步和异步编程,方便集成到不同架构的应用中。
1.2 LLM 的基本用法
LlamaIndex 允许通过 Settings 模块设置全局默认的 LLM,也可以在具体任务中(如查询引擎)局部指定 LLM。
(1) 安装依赖
首先,确保已安装所需的 LLM Python 包。以 OpenAI 为例:
pip install llama-index-llms-openai
(2) 使用模式
下面是几种常见的使用方式:
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
# 模式一:设置全局默认 LLM
# 这样一来,所有后续的 LlamaIndex 操作都将默认使用 gpt-3.5-turbo
Settings.llm = OpenAI()
# 模式二:作为独立模块使用
# 直接调用 llm 实例的 complete 方法
llm_instance = OpenAI()
resp = llm_instance.complete("Paul Graham is ")
print(resp)
# 模式三:在特定组件中覆盖 LLM
# 假设已经有了一个 index 对象
# 在创建查询引擎时,通过 llm 参数传入一个特定的模型实例
custom_llm = OpenAI(model="gpt-4o-mini", temperature=0.1)
query_engine = index.as_query_engine(llm=custom_llm)
chat_engine = index.as_chat_engine(llm=custom_llm)
1.3 独立使用 LLM 模块
即使脱离 LlamaIndex 的索引和查询流程,其 LLM 模块本身也非常好用。
(1) 文本补全示例 (Text Completion)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o-mini")
# 非流式调用:一次性获取完整结果
response = llm.complete("The best thing about AI is ")
print(f"非流式输出: {response}")
# 流式调用:逐个 token 打印,实现实时效果
print("\n流式输出: ", end="")
stream_response = llm.stream_complete("The best thing about AI is ")
for delta in stream_response:
print(delta.delta, end="")
print()
(2) 聊天模式示例 (Chat)
聊天模式更适合多轮对话场景,它接收一个消息列表作为输入。
from llama_index.core.llms import ChatMessage
from llama_index.llms.openai import OpenAI
messages = [
ChatMessage(
role="system", content="You are a pirate with a colorful personality who loves to say 'Ahoy!'"
),
ChatMessage(role="user", content="What is your name, captain?"),
]
resp = OpenAI(model="gpt-4o-mini").chat(messages)
print(resp.message.content)
1.4 在 LlamaIndex 抽象中自定义 LLM
LlamaIndex 默认使用 OpenAI 的 gpt-3.5-turbo 模型。但在实际项目中,我们常常需要根据成本、性能和任务需求更换模型。
(1) 更换预置 LLM 模型
例如,我们想将默认模型更换为性能更强、成本也更高的 gpt-4o-mini,并设置较低的 temperature 以获得更稳定的输出。
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
# 1. 定义一个新的 LLM 实例,指定模型和参数
llm = OpenAI(temperature=0.1, model="gpt-4o-mini")
# 2. 将其设置为全局默认 LLM
Settings.llm = llm
# 3. 加载数据并构建索引(此时会使用 gpt-4o-mini)
documents = SimpleDirectoryReader("your_data_directory").load_data()
index = VectorStoreIndex.from_documents(documents)
# 4. 创建查询引擎(默认继承全局设置)
query_engine = index.as_query_engine()
# 5. 当然,也可以在查询时再次局部覆盖
# query_engine = index.as_query_engine(llm=another_llm)
response = query_engine.query(
"What did the author do after his time at Y Combinator?"
)
print(response)
(2) 实现完全自定义的 LLM (高级)
如果需要集成一个私有部署的模型或 LlamaIndex 尚未官方支持的模型,可以通过继承 CustomLLM 基类来实现。这要求你自行处理模型调用逻辑。
核心步骤:
- \1. 创建一个继承自
CustomLLM的类。 - \2. 实现
metadata属性,提供模型的元信息(如上下文窗口大小、模型名称等)。 - \3. 实现
complete和stream_complete方法,在这两个方法中调用你的模型 API 并返回CompletionResponse或CompletionResponseGen对象。 - \4. 使用
@llm_completion_callback()装饰器可以获得更好的可观测性。
下面是一个简化的样板代码,演示了如何包装一个“虚拟”的本地模型:
from typing import Optional, List, Mapping, Any
from llama_index.core import SimpleDirectoryReader, SummaryIndex, Settings
from llama_index.core.callbacks import CallbackManager
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
class MyPrivateLLM(CustomLLM):
context_window: int = 4096
num_output: int = 256
model_name: str = "my-private-model-v1"
dummy_response: str = "This is a response from my very own private LLM!"
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据。"""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
# 在这里实现对你的私有模型API的调用
print(f"--- Calling my private model with prompt: {prompt[:50]}... ---")
return CompletionResponse(text=self.dummy_response)
@llm_completion_callback()
def stream_complete(
self, prompt: str, **kwargs: Any
) -> CompletionResponseGen:
# 实现流式响应逻辑
response = ""
for token in self.dummy_response:
response += token
yield CompletionResponse(text=response, delta=token)
# --- 使用自定义LLM ---
# 设置全局LLM为我们的私有模型
Settings.llm = MyPrivateLLM()
# 为实现完全离线,建议也设置一个本地 embedding 模型
Settings.embed_model = "local:BAAI/bge-base-en-v1.5"
# 加载数据、构建索引和查询
documents = SimpleDirectoryReader("./your_data_directory").load_data()
index = SummaryIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Tell me something interesting.")
print(response)
注意:使用自定义模型时,可能需要调整 LlamaIndex 内部使用的 默认提示词,以适配你的模型特性,从而获得最佳性能。
1.5 关于 Tokenizer 的重要提示
LlamaIndex 默认使用一个全局的 Tokenizer (tiktoken的cl100k) 来计算 token 数量,这与默认的 LLM (gpt-3.5-turbo) 相匹配。如果你更换了 LLM,务必也要更新 Tokenizer,以确保 token 计数、文本切块和提示词长度的准确性。
一个合法的 Tokenizer 只需要是一个可调用对象,它接收一个字符串,返回一个 token ID 列表。
from llama_index.core import Settings
# 示例1:为其他 OpenAI 模型设置 tiktoken
import tiktoken
Settings.tokenizer = tiktoken.encoding_for_model("gpt-4o-mini").encode
# 示例2:为 Hugging Face 模型设置
from transformers import AutoTokenizer
# 这里的模型名称应与你使用的 Hugging Face LLM 匹配
Settings.tokenizer = AutoTokenizer.from_pretrained(
"HuggingFaceH4/zephyr-7b-beta"
).encode # 注意,这里我们直接使用 encode 方法
1.6 支持的 LLM 集成列表
LlamaIndex 生态非常丰富,支持海量模型集成,以下是部分列表:
| 类型 | 厂商/模型 |
|---|---|
| 主流云服务 | OpenAI, Azure OpenAI, Anthropic, Bedrock, Google Gen AI, SageMaker |
| 开源/本地化 | HuggingFace, Llama CPP, vLLM, Ollama, LocalAI, Nvidia TensorRT-LLM |
| 新兴平台 | Groq, MistralAI, Perplexity, Together.ai, Fireworks, Replicate |
| 其他 | LangChain, Cohere, Dashscope, Yi, AI21, … |
完整的列表请查阅官方文档。
二、嵌入模型 (Embeddings)
如果说 LLM 是大脑,那么 Embedding 模型就是连接物理世界(文本)和数字世界(向量)的桥梁。它负责将文本转换成高维的数字向量,这些向量能够捕捉文本的语义信息。
2.1 Embedding 的核心概念
Embedding 模型接收文本输入,输出一个固定长度的浮点数列表(即向量)。这些模型经过训练,能将语义相近的文本映射到向量空间中相近的位置。例如,“关于狗的问题”的查询向量,会与“讨论犬类动物”的文档块向量在空间上非常接近。
LlamaIndex 默认使用余弦相似度 (cosine similarity) 来度量向量间的相似性,从而找出与用户查询最相关的文档。默认的 Embedding 模型是 OpenAI 的 text-embedding-ada-002。
2.2 Embedding 的标准用法
与 LLM 类似,Embedding 模型通常在 Settings 中进行全局配置,然后在构建向量索引 (VectorStoreIndex) 时使用。
(1) 安装与基础配置
首先安装依赖:
# 如果使用 OpenAI
pip install llama-index-embeddings-openai
# 如果使用 HuggingFace 本地模型
pip install llama-index-embeddings-huggingface sentence-transformers
然后配置和使用:
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# --- 方案一:使用 OpenAI (默认) ---
# 全局设置
Settings.embed_model = OpenAIEmbedding()
# 局部使用/独立调用
embedding_module = OpenAIEmbedding()
text_embedding = embedding_module.get_text_embedding("hello world")
print(f"单个文本嵌入向量 (前5维): {text_embedding[:5]}")
list_embeddings = embedding_module.get_text_embeddings(["hello world", "this is a test"])
print(f"嵌入了 {len(list_embeddings)} 个文本")
# --- 方案二:使用本地 Hugging Face 模型 (节省成本) ---
# BAAI/bge-small-en-v1.5 是一个性能优异且快速的轻量级模型
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
# --- 在索引构建中使用 ---
documents = SimpleDirectoryReader("your_data_directory").load_data()
# VectorStoreIndex 在构建时会自动使用 Settings.embed_model
index = VectorStoreIndex.from_documents(documents)
# 也可以在构建时局部指定
# index = VectorStoreIndex.from_documents(documents, embed_model=custom_embed_model)
在查询时,查询文本也会被同一个 Embedding 模型转换成向量,以便在向量数据库中进行相似度搜索。
2.3 Embedding 模型深度定制
(1) 调整批处理大小 (Batch Size)
向 OpenAI 等 API 发送嵌入请求时,LlamaIndex 默认的批处理大小是 10。如果遇到速率限制,可以调小它;如果需要处理大量文档,可以适当调大以提高效率。
from llama_index.embeddings.openai import OpenAIEmbedding
# 将批处理大小设置为 42
embed_model = OpenAIEmbedding(embed_batch_size=42)
Settings.embed_model = embed_model
(2) 使用本地 Embedding 模型
使用本地模型可以有效降低成本并保护数据隐私。HuggingFaceEmbedding 是最便捷的方式。
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5" # 可替换为任何 Sentence Transformers 模型
)
HuggingFaceEmbedding 构造函数接受的额外参数(如 backend, model_kwargs, truncate_dim)会被传递给底层的 SentenceTransformer 实例,提供了丰富的自定义空间。
(3) 使用 ONNX 或 OpenVINO 进行推理加速
LlamaIndex 支持通过 Optimum 库利用 ONNX 或 OpenVINO 对本地模型进行加速。
首先安装所需依赖:
pip install llama-index-embeddings-huggingface
# 根据你的硬件选择安装
pip install optimum[onnxruntime-gpu] # GPU 上的 ONNX
pip install optimum[onnxruntime] # CPU 上的 ONNX
pip install optimum-intel[openvino] # Intel CPU 上的 OpenVINO
使用时,只需在 HuggingFaceEmbedding 中指定 backend:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
backend="onnx", # 或者 "openvino"
)
如果模型仓库中不存在预转换的 ONNX/OpenVINO 模型,Optimum 会自动进行转换。
(4) 集成 LangChain 的 Embedding
LlamaIndex 与 LangChain 兼容良好,可以直接使用 LangChain 提供的 Embedding 类。
pip install llama-index-embeddings-langchain langchain-community
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from llama_index.core import Settings
# 注意这里导入的是 LangChain 的类
Settings.embed_model = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-base-en")
(5) 实现完全自定义的 Embedding 模型
当需要使用特殊模型(如需要指令微调的 Instructor Embeddings)或私有模型时,可以继承 BaseEmbedding 类。
以下是为 Instructor Embeddings 创建自定义包装类的示例,它允许在嵌入时提供一个“指令”来引导模型关注特定领域的语义。
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR # 需要先 pip install InstructorEmbedding
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core import Settings
class InstructorEmbeddings(BaseEmbedding):
def __init__(
self,
instructor_model_name: str = "hkunlp/instructor-large",
instruction: str = "Represent the Computer Science documentation or question:",
**kwargs: Any,
) -> None:
super().__init__(**kwargs)
self._model = INSTRUCTOR(instructor_model_name)
self._instruction = instruction
def _get_query_embedding(self, query: str) -> List[float]:
# 为查询生成带指令的嵌入
embeddings = self._model.encode([[self._instruction, query]])
return embeddings[0].tolist()
def _get_text_embedding(self, text: str) -> List[float]:
# 为文档生成带指令的嵌入
embeddings = self._model.encode([[self._instruction, text]])
return embeddings[0].tolist()
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
# 批量处理
embeddings = self._model.encode(
[[self._instruction, text] for text in texts]
)
return embeddings.tolist()
async def _aget_query_embedding(self, query: str) -> List[float]:
# 异步版本
return self._get_query_embedding(query)
async def _aget_text_embedding(self, text: str) -> List[float]:
# 异步版本
return self._get_text_embedding(text)
# 使用自定义的 Instructor Embedding 模型
Settings.embed_model = InstructorEmbeddings()
2.4 支持的 Embedding 集成列表
LlamaIndex 支持广泛的 Embedding 模型,包括但不限于:OpenAI, Azure OpenAI, Cohere, HuggingFace, Google PaLM, MistralAI, VoyageAI, JinaAI, Nomic 等。
三、多模态模型 (Multi-modal)
传统 LLM 是纯文本模型,而多模态大模型(LMMs)则将输入和输出扩展到了文本之外的模态,如图像。例如,GPT-4V 可以同时接收文本和图像作为输入,并生成文本作为输出。
3.1 多模态模型的核心概念
LlamaIndex 通过 MultiModalLLM 抽象来支持文图混合模型。这为构建能够理解图像内容的 RAG 应用打开了大门。
3.2 多模态模型基本用法
以 OpenAI 的 GPT-4V (Vision) 为例,展示如何使用多模态模型来描述一张图片。
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core.multi_modal_llms.generic_utils import load_image_urls
from llama_index.core import SimpleDirectoryReader
# 方式一:从 URL 加载图片
image_urls = [
"https://www.popsci.com/uploads/2023/10/10/porsche-mission-x-front.jpg?auto=webp"
]
image_documents = load_image_urls(image_urls)
# 方式二:从本地目录加载图片
# image_documents = SimpleDirectoryReader("./image_folder/").load_data()
# 初始化多模态 LLM
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", max_new_tokens=300
)
# 发送请求,同时传入文本提示和图片文档
response = openai_mm_llm.complete(
prompt="What car is this? Describe its color and key features.",
image_documents=image_documents
)
print(response)
3.3 构建多模态向量索引
为了实现对图像内容的检索,我们需要构建一个多模态向量索引。MultiModalVectorStoreIndex 支持将文本和图像分别存储在不同的向量存储中。
import qdrant_client
from llama_index.core import SimpleDirectoryReader, StorageContext
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.vector_stores.qdrant import QdrantVectorStore
# 1. 初始化 Qdrant 客户端作为向量数据库
client = qdrant_client.QdrantClient(path="qdrant_mm_db")
# 2. 为文本和图像分别创建向量存储
text_store = QdrantVectorStore(client=client, collection_name="text_collection")
image_store = QdrantVectorStore(client=client, collection_name="image_collection")
# 3. 创建存储上下文
storage_context = StorageContext.from_defaults(
vector_store=text_store, image_store=image_store
)
# 4. 加载包含文本和图像的文档
# 假设 ./data_folder/ 目录下有 .txt 文件和 .jpg/.png 文件
documents = SimpleDirectoryReader("./data_folder/").load_data()
# 5. 构建多模态索引
# LlamaIndex 会自动识别文档类型,并使用相应的 embedding 模型处理
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)
3.4 多模态检索与查询
构建好多模态索引后,就可以创建检索器和查询引擎来执行图文联合查询。
from llama_index.core import PromptTemplate
# 1. 从索引创建多模态检索器
retriever = index.as_retriever(
similarity_top_k=3, image_similarity_top_k=3
)
# 2. 使用文本查询进行检索,可以同时返回相关的文本和图像
retrieval_results = retriever.retrieve("Tell me more about the Porsche")
# 3. 创建一个多模态查询引擎
# openai_mm_llm 是之前创建的 GPT-4V 实例
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm
)
# 4. 执行端到端的查询
# LlamaIndex 会先进行检索,然后将检索到的文本和图像信息喂给多模态LLM
response = query_engine.query("Tell me more about the Porsche based on the images")
print(response)
3.5 多模态 RAG 工作流概览
下表总结了 LlamaIndex 在多模态 RAG 各个环节的支持情况(✅: 支持, ⚠️: 可能需调试, 🛑: 暂不支持)。
端到端工作流
| 查询类型 | 数据源 | 多模态 Embedding | 检索器 | 查询引擎 | 输出 |
|---|---|---|---|---|---|
| 文本 | 文本✅, 图像✅ | 文本✅, 图转文✅ | Top-k✅, 融合检索✅ | 简单引擎✅ | 检索文本✅, 生成文本✅ |
| 图像 | 文本✅, 图像✅ | 图像✅, 图转文✅ | Top-k✅, 融合检索✅ | 简单引擎✅ | 检索图像✅, 生成图像🛑 |
| 音频 | 音频🛑 | 音频🛑 | 🛑 | 🛑 | 音频🛑 |
| 视频 | 视频🛑 | 视频🛑 | 🛑 | 🛑 | 视频🛑 |
主流多模态模型支持
| 模型 | 单图推理 | 多图推理 | 图像Embedding | 简单查询引擎 | Pydantic结构化输出 |
|---|---|---|---|---|---|
| GPT-4V (OpenAI) | ✅ | ✅ | 🛑 | ✅ | ✅ |
| GPT-4V (Azure) | ✅ | ✅ | 🛑 | ✅ | ✅ |
| Gemini (Google) | ✅ | ✅ | 🛑 | ✅ | ✅ |
| CLIP (Local) | 🛑 | 🛑 | ✅ | 🛑 | 🛑 |
| LLaVa (Replicate) | ✅ | 🛑 | 🛑 | ✅ | ⚠️ |
3.6 支持的多模态模型与向量存储
- • 多模态LLM模块:已集成 OpenAI, Gemini, Anthropic (Opus, Sonnet), Replicate (LLaVA, Fuyu-8B), CogVLM 等。
- • 多模态向量存储:LlamaIndex 内置的
MultiModalVectorStoreIndex可以与任何标准向量库(如 Chroma, Qdrant, Weaviate)结合,通过分离存储文本和图像向量来实现多模态。ChromaDB 本身也提供了对多模态数据的原生支持。
四、LlamaIndex 其他核心组件概览
除了模型,LlamaIndex 还包含一系列其他核心组件,共同构成了一个完整的 RAG 框架。这里简要介绍,我们将在后续文章中详细展开。
- • 数据加载 (Loading): 提供了
SimpleDirectoryReader和大量Data Connectors,用于从各种数据源(文件、数据库、API)加载数据,并转换为Document对象。 - • 提示词 (Prompts): 强大的提示词工程能力,允许你定制、优化和管理与 LLM 交互的各种提示模板。
- • 索引 (Indexing): 将
Document转换为可供高效检索的数据结构。除了VectorStoreIndex,还包括Property Graph Index等多种索引类型。 - • 存储 (Storing): 负责持久化数据,包括
Vector Stores(存储嵌入向量),Document Stores(存储原始文档), 和Index Stores(存储索引元数据)。 - • 查询 (Querying): 框架的执行核心,包括
Query Engines(处理查询),Chat Engines(构建对话机器人),Retrieval(检索上下文), 和Response Synthesis(合成答案)。 - • 智能体 (Agents): 赋予 LLM 使用工具 (Tools) 和拥有记忆 (Memory) 的能力,以执行更复杂的、多步骤的任务。
- • 工作流 (Workflows): 用于构建和编排复杂的多步骤 AI 流程。
- • 评估 (Evaluation): 提供了一套评估框架和标准数据集 (
LlamaDatasets),用于测试和改进你的应用性能。 - • 可观测性 (Observability): 通过
Instrumentation帮助你监控和调试应用的内部运行状态。 - • 全局配置与部署 (Settings & Llama Deploy): 提供了全局配置 (
Settings) 和将应用部署到生产环境的工具 (Llama Deploy)。
五、总结
本文深入探讨了 LlamaIndex 框架中最核心的“模型”组件,希望能为您构建下一代智能应用提供坚实的基础。
以下是本文的核心要点总结:
- \1. 模型是 LlamaIndex 的基石:LlamaIndex 通过统一的接口抽象了 LLM、Embedding 和多模态模型,它们分别负责推理生成、语义表示和跨模态理解,是 RAG 系统智能化的关键。
- \2. LLM (大语言模型):作为核心引擎,LlamaIndex 提供了极大的灵活性。你可以轻松地进行全局或局部配置,更换默认模型,甚至通过继承
CustomLLM来集成私有模型。切记,更换 LLM 时需同步更新Tokenizer以保证计数的准确性。 - \3. Embedding (嵌入模型):是实现语义检索的桥梁。LlamaIndex 支持从 OpenAI 到本地 Hugging Face 模型(可通过 ONNX/OpenVINO 加速)的多种选择。通过继承
BaseEmbedding,可以实现对特殊模型(如 Instructor)的自定义集成。 - \4. Multi-modal (多模态模型):LlamaIndex 正在积极拥抱多模态的未来。通过
MultiModalLLM、MultiModalVectorStoreIndex和相应的检索器/查询引擎,开发者已经可以构建能够理解和检索图像内容的初级多模态 RAG 应用。 - \5. 实践驱动:本文提供了丰富的代码示例,涵盖了从基本用法到高级定制的各种场景,旨在帮助读者将理论知识转化为实际操作能力。
掌握了模型层,你就掌握了控制 LlamaIndex 应用“大脑”的能力。在接下来的文章中,我们将继续探索数据加载、索引、查询等其他核心组件,敬请期待!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

欢迎加入北京社区
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)