
在Mac M1笔记本上跑大语言模型llama3的4个步骤?(install、pull、run、ask)
实操下来,因为ollma非常简单,只需要3个步骤就能使用模型,更多模型只需要一个pull就搞定。一台稍微不错的笔记本+网络,就能把各种大模型都用起来,快速上手吧。
·
要点
- Ollama一个功能强大的本地大语言模型LLM运行工具,支持很多模型,并且操作极其简单
- 快速回忆步骤:
下载ollama工具:https://ollama.com/download
下载模型:ollama pull llama3 #根据libs列表直接指定名字
运行模型:ollama run llama3
测试:直接问他问题(可以关闭网络)
步骤
Step1. 下载ollama(根据平台选择)
https://ollama.com/download
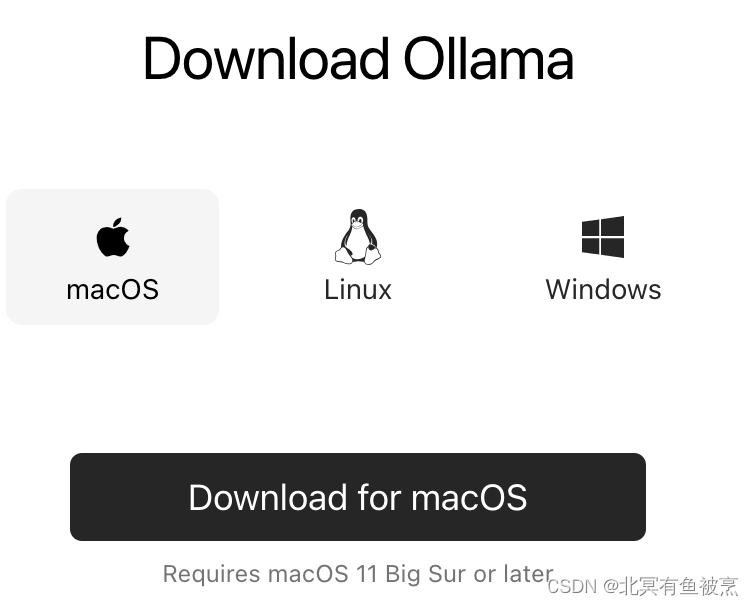
下载后将软件安装,解压后拷贝到应用程序:

安装用户态命令:(点击install)

Step2:下载模型文件
支持的模型列表:https://ollama.com/library
比如llama3:
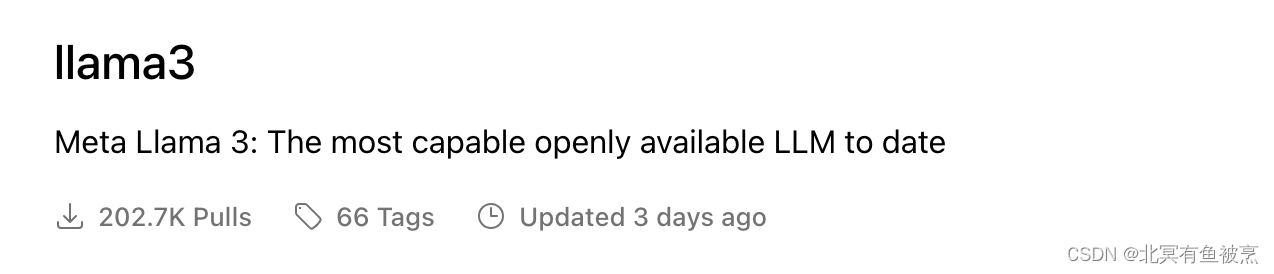
安装步骤:命令行直接安装
ollama pull llama3
实操:
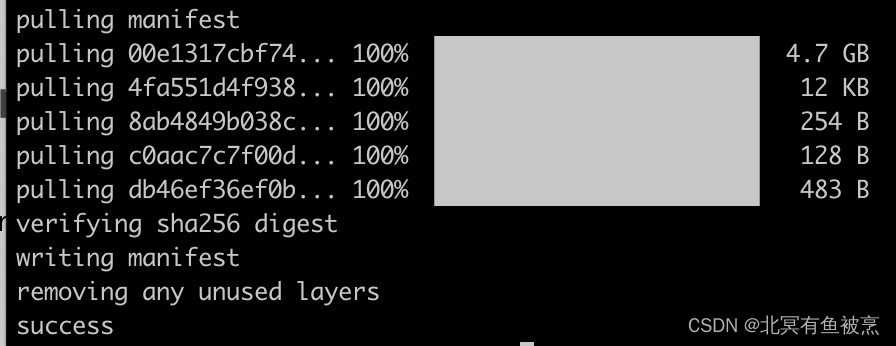
这里需要耗费一些时间,具体根据网络和模型大小确定,模型大小参考:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Solar | 10.7B | 6.1GB | ollama run solar |
官方的参考资源:
8 GB 内存跑 7B models
16 GB to run the 13B models
32 GB to run the 33B models
比如M1有16G内存,可以跑7B的模型。
Step:运行模型
ollama run llama3
实操:(在M1的笔记本大概是s级别的,其他比如intel笔记本可能需要十几秒,M3等笔记本应该非常快)
并且测试的时候可以尝试关闭网络。
比如让他回答一个 gcc编译的问题:

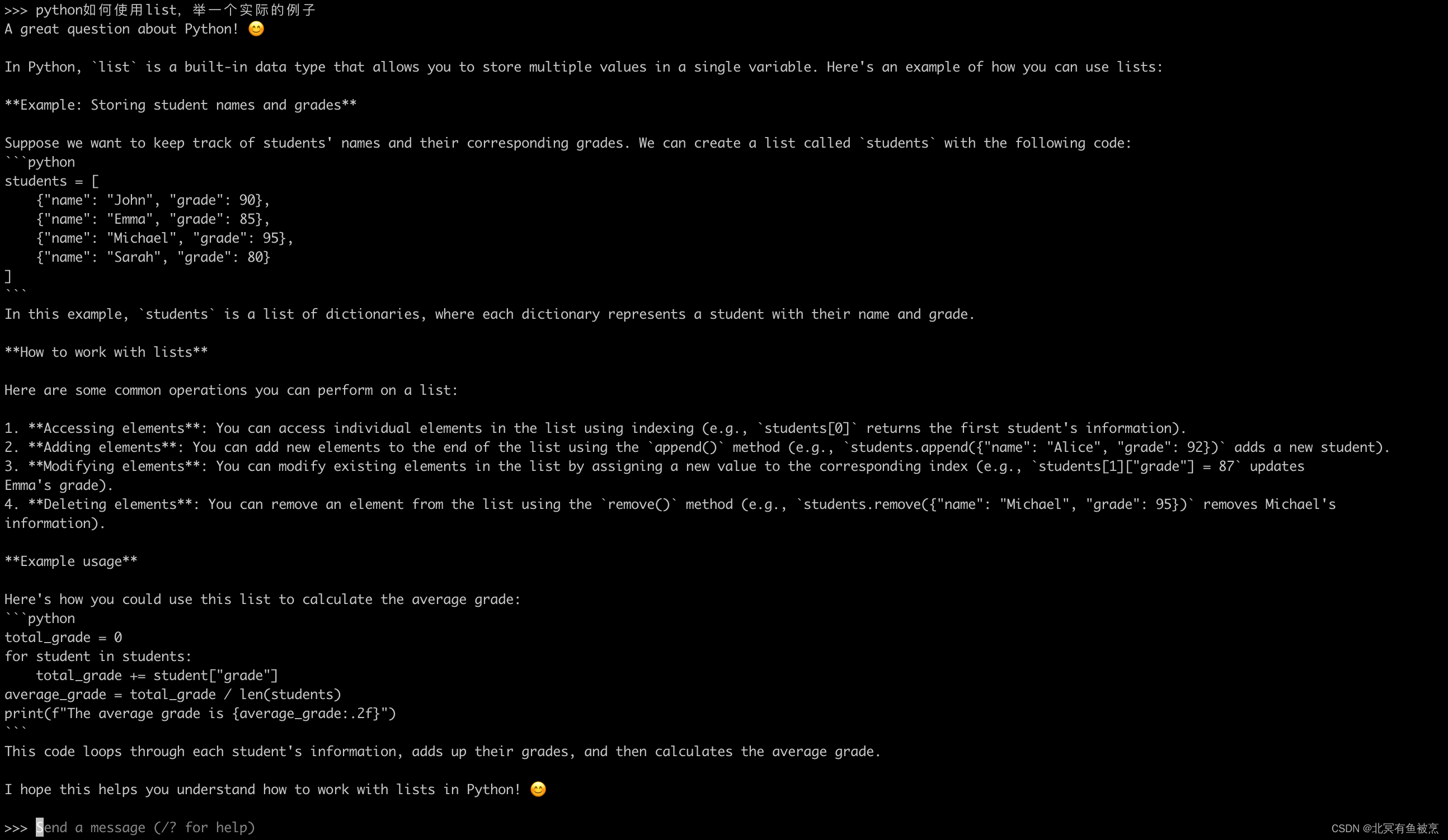
再来一个:“python如何使用list,举一个实际的例子”
Step:退出聊天
Ctrl + d 或者 /bye退出聊天
其他
- ollama的github:https://github.com/ollama/ollama
- ollama在mac本地是以类似git的方式存储的,存储的模型都是以blobs的形式,和git底层原理类似。
 - ollama在mac上模型存储的地址: ~/.ollama/models/blobs/
- ollama在mac上模型存储的地址: ~/.ollama/models/blobs/ - 在models/manifests中存储了配置信息,比如llama的blob是哪个等信息
- 运行以后会自动启动RESTful的接口,也就是可以通过局域网访问,端口是11434,比如:
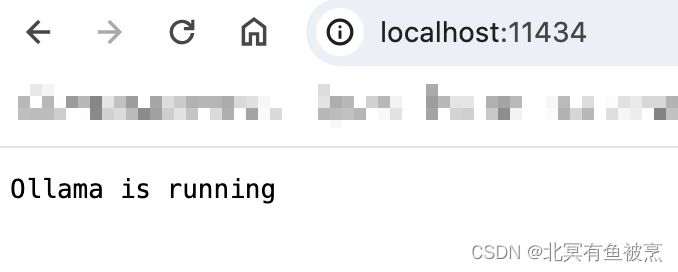
- 可以通过curl使用restful方式访问:比如:
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'
- 端侧的模型也具有记忆能力,还能反馈错误并且修改正
- 查看当前使用的模型等信息 /show info

最后
实操下来,因为ollma非常简单,只需要3个步骤就能使用模型,更多模型只需要一个pull就搞定。一台稍微不错的笔记本+网络,就能把各种大模型都用起来,快速上手吧。

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)