扩散模型(diffusion model)快速理解
一. 序言
笔者最近学习多模态相关的论文,有些基础知识和模型再论文或者其他的文章中都体现的很复杂。但是台大李宏毅教授对这些知识的解释都很通俗,且非常清晰,因此这文章的是以他的视频为基础解释的。
二. 模型结构
1. 前向传播
概念
前向传播的过程通过生成的噪音通过马尔科夫链给原始图片加噪,相当于是在生成训练样本和标签。这里样本是每一步生成的带噪音的图片,标签则是给每一步加上的噪音值。因为需要预测每张图片所对应的噪音,让噪音图片减去噪音来实现去噪才是模型训练的最终目的。
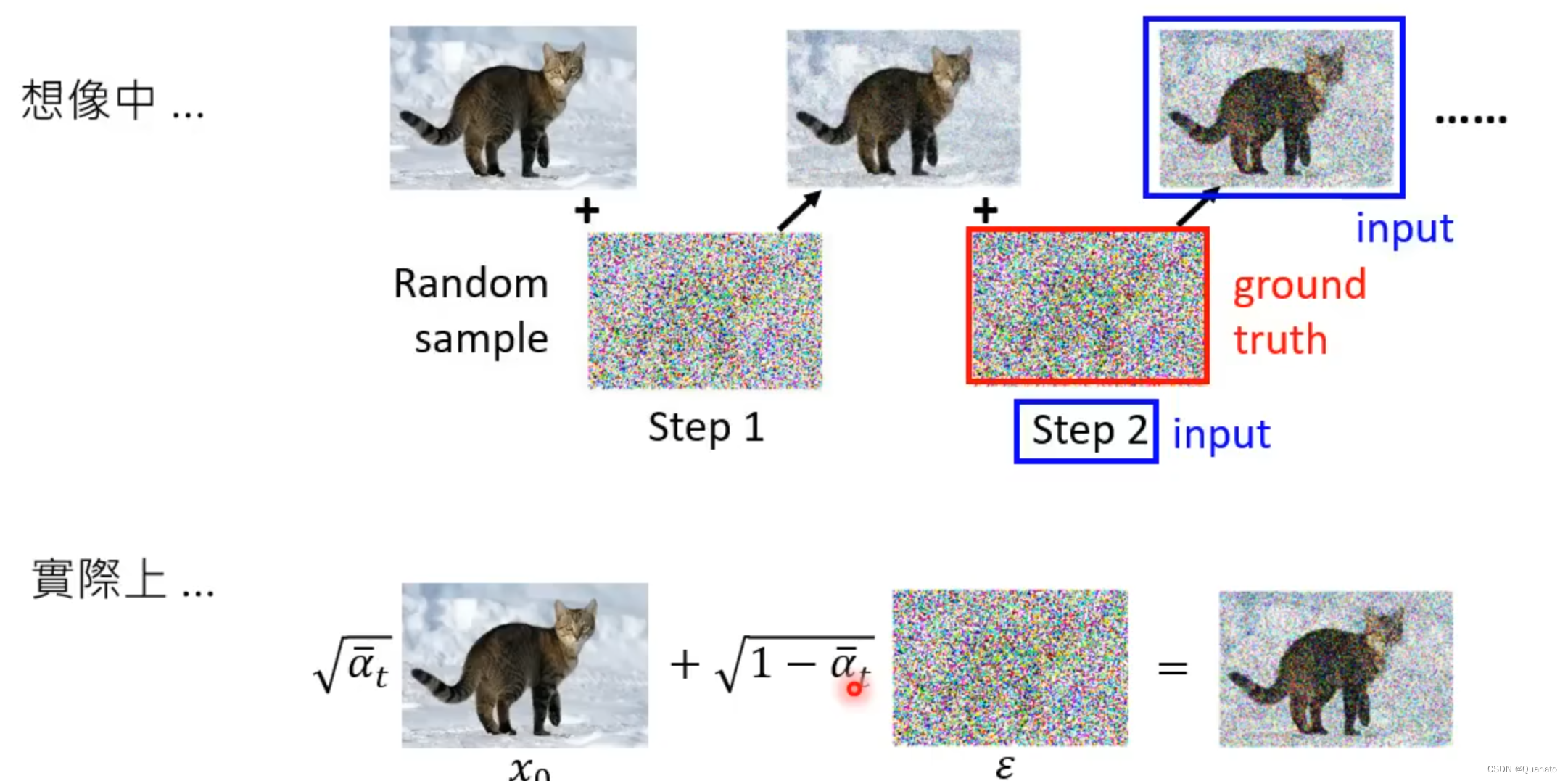
具体实现(U-net 模型训练)
标注都有,非常清晰

2. 逆向传播
逆向传播的过程相当于借助训练好的模型预测第t-1张图片到t张图片所添加的噪音,通过第t张图片和预测的噪音运算得到第t-1张图片。最终,连续进行逆向传播得到无噪声图片。
逆向传播的训练即为模型提取图像特征,从纯噪音无图像信息的图片借助提取的特征逐步生成一张图片。
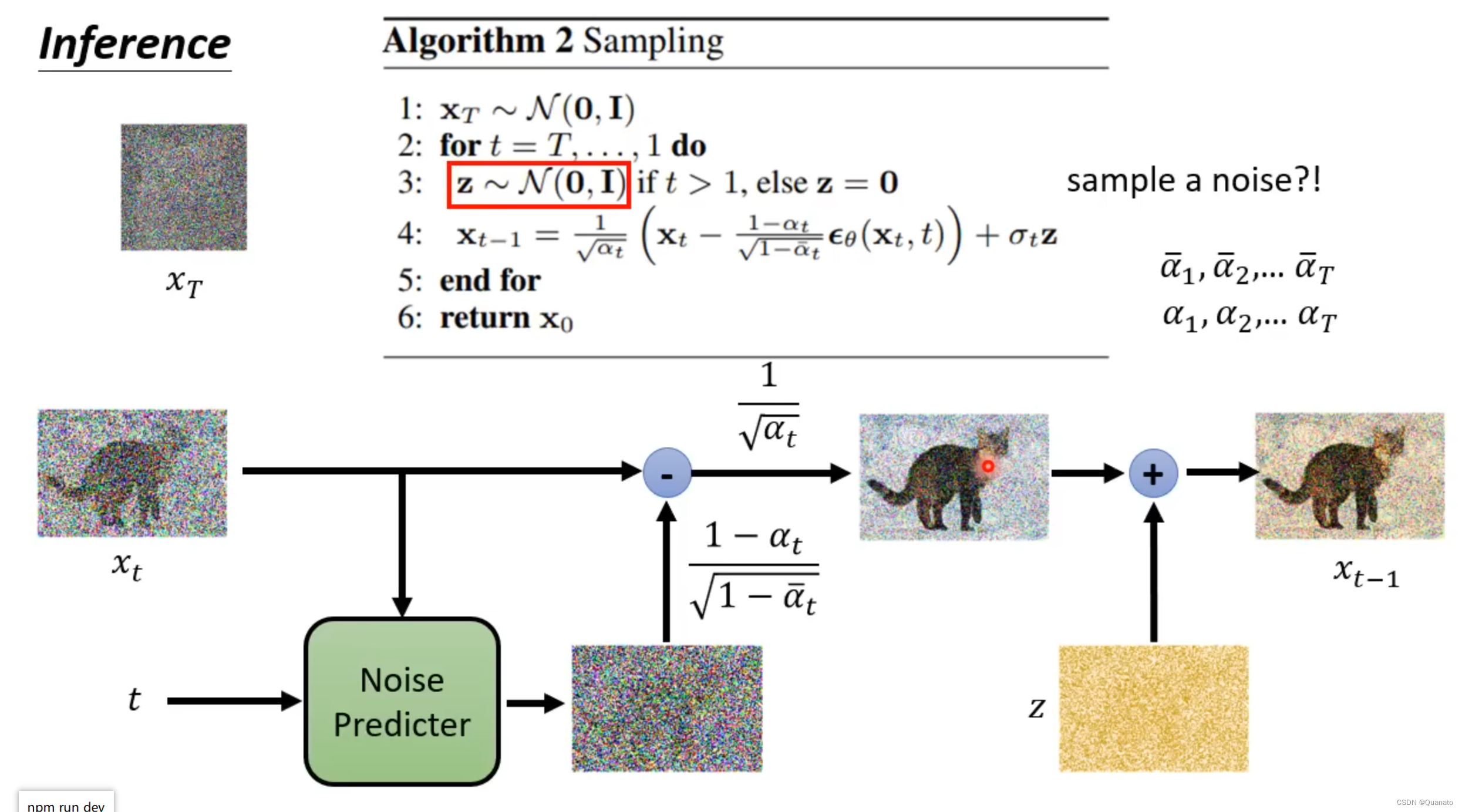
三. 特殊的模型结构解释
1. 为什么要一步一步训练而不是直接通过Xt和X0进行训练呢?z又是为何存在呢?
类似于形成语言和声音的模型,通过在每一步中添加不确定的噪音提高模型的表现,更加接近人类的视觉和表达。
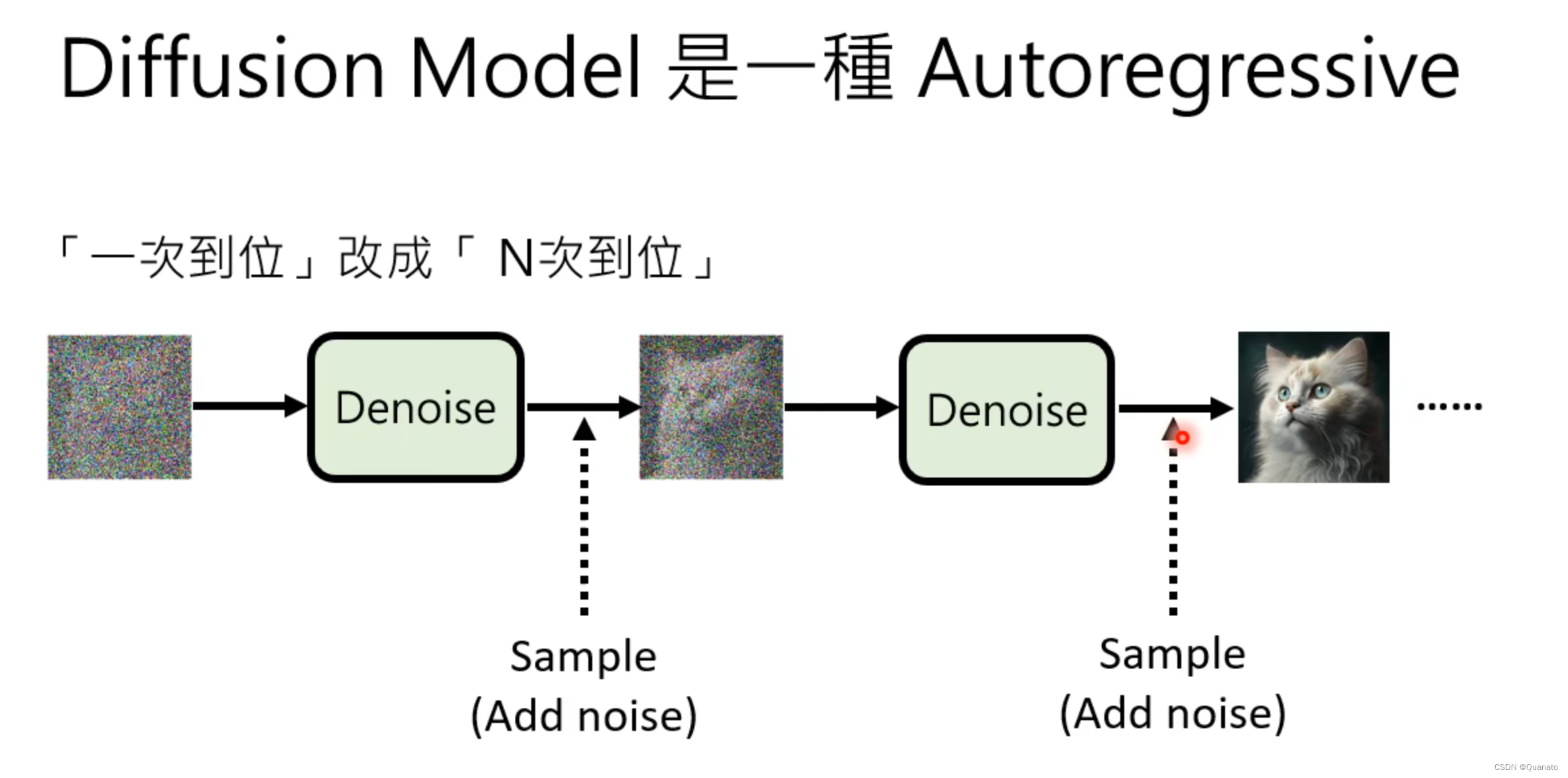
论证的实验:
增加噪音z后可以正常生成图片但是去除噪音后就效果不佳
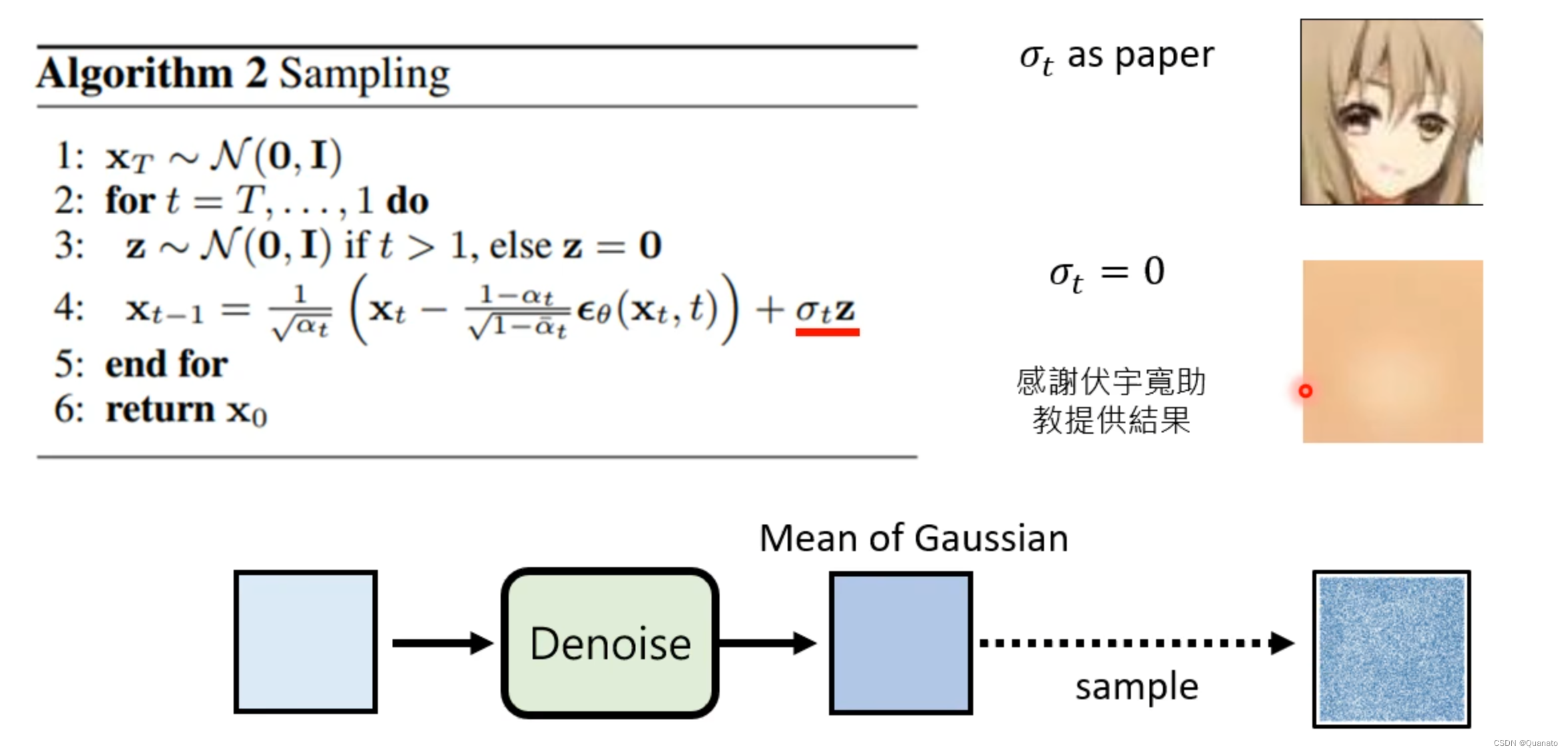
2. 纯噪声没有图片信息也能通过扩散模型还原出一张带信息图片?
不能,在扩散模型中,我们通常所说的“纯噪声”其实是指含有大量噪声的图片,而不是完全没有任何信息的噪声。这些噪声图片在经过扩散模型处理后,可以恢复出原始的、含有丰富信息的图片。
这里的纯噪音应该只是含有大量噪音的具有图片信息的图片,而预测的噪音则带有图片信息所以噪音也可以作为原图的特征图,因为扩散模型是借助带噪声图片生成噪音的,说明扩散模型可以提取图片信息因此噪声带有图片信息。
这也给后续许多模型借助扩散模型自监督提取图片特征打下了基础。而且训练时并不是采取整个模型的loss去训练扩散模型的参数,而是通过扩散模型自带的噪音预测网络的损失来训练。噪音预测网络的根本是借助带噪声图片预测噪声,因此具有泛化性,不会拟合于特定图片。
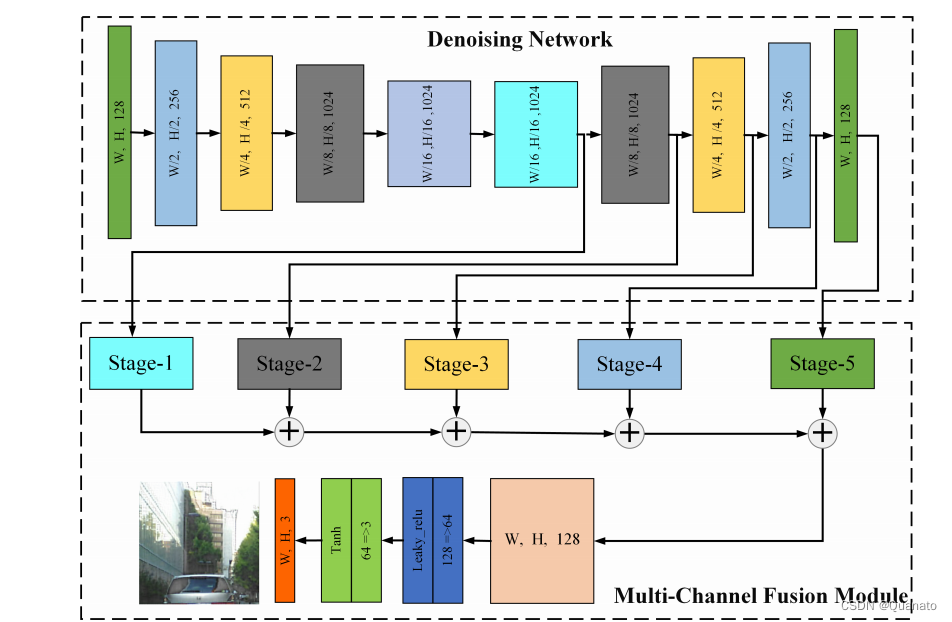
Dif-Fusion
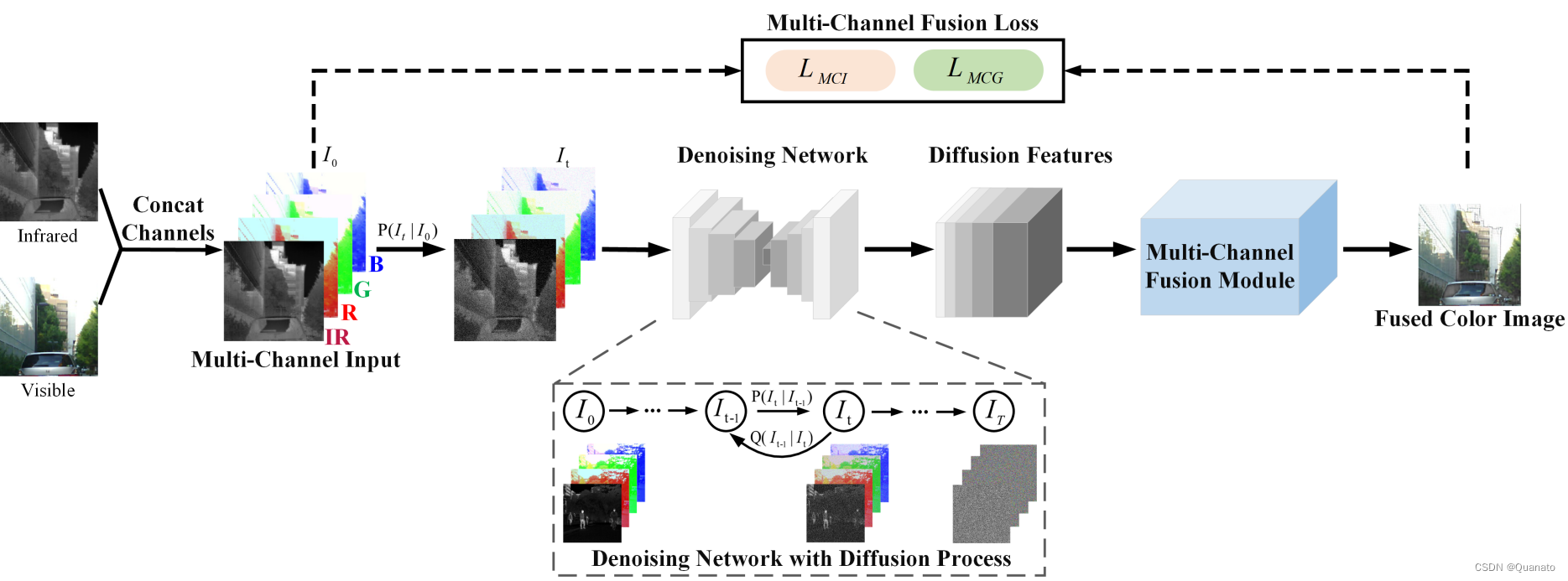
通过模型中各个阶段提取的图像特征结合获取提取的图像特征

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)