

【2】机器学习算法面试八股
频率派认为模型参数是固定的,一个模型在无数次抽样后,参数是不变的;频率派认为模型不存在先验贝叶斯学派认为数据才是固定的而参数并不是。贝叶斯派认为模型存在先验。支持向量机为一个二分类模型,它的基本模型定义为特征空间上的间隔最大的线性分类器。而它的学习策略为最大化分类间隔,最终可转化为凸二次规划问题求解。LR是参数模型,SVM为非参数模型。LR采用的损失函数为logisticalloss,而SVM采用
11面试中的概率问题
概率链接
切比雪夫不等式
最大似然估计:
最大后验概率估计:

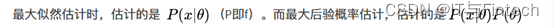
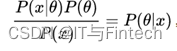
所以最大后验概率就是估计 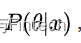
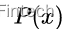
12各种分布及其期望、方差、分布函数
13什么是共轭先验分布

14频率学派和贝叶斯学派的区别
频率派认为模型参数是固定的,一个模型在无数次抽样后,参数是不变的;频率派认为模型不存在先验
贝叶斯学派认为数据才是固定的而参数并不是。贝叶斯派认为模型存在先验。
15. 0~1均匀分布的随机器如何变化成均值为0,方差为1的随机器
16Lasso的损失函数

17线性代数
 若矩阵所有特征值均不小于0,则判定为半正定。若矩阵所有特征值均大于0,则判定为正定。在判断优化算法的可行性时Hessian矩阵的正定性起到了很大的作用,若Hessian正定,则函数的二阶偏导恒大于0,函数的变化率处于递增状态,在牛顿法等梯度下降的方法中,Hessian矩阵的正定性可以很容易的判断函数是否可收敛到局部或全局最优解。
若矩阵所有特征值均不小于0,则判定为半正定。若矩阵所有特征值均大于0,则判定为正定。在判断优化算法的可行性时Hessian矩阵的正定性起到了很大的作用,若Hessian正定,则函数的二阶偏导恒大于0,函数的变化率处于递增状态,在牛顿法等梯度下降的方法中,Hessian矩阵的正定性可以很容易的判断函数是否可收敛到局部或全局最优解。
18欧拉公式

19PCA

20拟牛顿法

21交叉熵与logistic回归

22SVM中什么时候用线性核什么时候用高斯核?
当数据的特征提取的较好,所包含的信息量足够大,很多问题是线性可分的那么可以采用线性核。若特征数较少,样本数适中,对于时间不敏感,遇到的问题是线性不可分的时候可以使用高斯核来达到更好的效果。
23什么是支持向量机,SVM与LR的区别?
支持向量机为一个二分类模型,它的基本模型定义为特征空间上的间隔最大的线性分类器。而它的学习策略为最大化分类间隔,最终可转化为凸二次规划问题求解。
LR是参数模型,SVM为非参数模型。LR采用的损失函数为logisticalloss,而SVM采用的是hingeloss。在学习分类器的时候,SVM只考虑与分类最相关的少数支持向量点。LR的模型相对简单,在进行大规模线性分类时比较方便
24监督学习和无监督学习的区别
输入的数据有标签则为监督学习,输入数据无标签为非监督学习
25机器学习中的距离计算方法?



26朴素贝叶斯(naive Bayes)法的要求是?
贝叶斯定理、特征条件独立假设
解析:朴素贝叶斯属于生成式模型,学习输入和输出的联合概率分布。给定输入x,利用贝叶斯概率定理求出最大的后验概率作为输出y。
27训练集中类别不均衡,哪个参数最不准确?
准确度(Accuracy)
解析:举例,对于二分类问题来说,正负样例比相差较大为99:1,模型更容易被训练成预测较大占比的类别。因为模型只需要对每个样例按照0.99的概率预测正类,该模型就能达到99%的准确率。
28问题:SVM的作用,基本实现原理;
SVM可以用于解决二分类或者多分类问题,此处以二分类为例。SVM的目标是寻找一个最优化超平面在空间中分割两类数据,这个最优化超平面需要满足的条件是:离其最近的点到其的距离最大化,这些点被称为支持向量


29SVM的物理意义是什么;
构造一个最优化的超平面在空间中分割数据
30SVM使用对偶计算的目的是什么,如何推出来的,手写推导;
目的有两个:一是方便核函数的引入;二是原问题的求解复杂度与特征的维数相关,而转成对偶问题后只与问题的变量个数有关。由于SVM的变量个数为支持向量的个数,相较于特征位数较少,因此转对偶问题。通过拉格朗日算子发使带约束的优化目标转为不带约束的优化函数,使得W和b的偏导数等于零,带入原来的式子,再通过转成对偶问题。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)