万字长文总结,带你零基础入门深度学习实战教程 [环境配置&代码&教程] 含各种坑解决办法
基于深度学习的遥感图像分类实战教程
概述
这是博主遥感课程大作业选题 基于深度学习的遥感图像分类 的总结,因为是第一次接触深度学习,从环境配置到数据集获取到代码实现运行都踩了很多坑,于是将整个过程做了个总结,对于0基础想学习深度学习的,可以参考从头到尾按照我下面的内容过一遍,涉及环境配置、教程链接(含源码和数据集,一个很不错的深度学习实战教程)、代码讲解、运行结果等多个方面。
深度学习遥感图像分类
环境配置
1、安装anaconda
2、切换镜像源(可忽略)
如果网络能下载境外资源可忽略,一直保持vpn就行。切换镜像源后需要关掉vpn,后续有的操作还是需要境外的资源,可能会卡慢很多(亲测对于有的包conda install速度可能会相差数小时)或者需要开关vpn
清华镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
中科大镜像
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
注意!如果切换镜像后当出现下载不了的情况,就先切换默认源,然后再修改另一个可以使用的conda源(一定要先恢复默认,再换另一个!!!)
切回默认源
conda config --remove-key channels
3、安装虚拟环境
安装
conda create -n your-define-name python=3.6
中途输入 y
速度太慢切换镜像
虚拟环境相关命令
查看虚拟环境
conda env list
下载的环境在本地路径 E:\Tools\Anaconda3-2023.03-1\Anaconda3\envs(你下载的Anaconda3的envs目录下)
默认下载到c盘的可参考这个 url
删除虚拟环境
conda remove --name your-define-name --all
激活虚拟环境
activate your-define-name
关闭虚拟环境
conda deactivate
4、conda安装tensorflow
安装包前需要先切换到需要用到的虚拟环境
activate your-define-name
CPU版输入 conda install tensorflow
GPU版输入 conda install tensorflow-gpu
卸载同理 conda uninstall tensorflow
conda uninstall tensorflow-gpu
这里我下载cpu版本的
conda install tensorflow
(重点!)选择conda安装而不用pip安装,是因为在安装tensorFlow-gpu版的过程中,它会自动配置对应版本号的cuda和cudnn,而不需要再单独安装
等待安装完成即可。
5、查看安装是否完成
方法一:Anaconda Prompt
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KXdVfI2T-1688114195612)(%E9%81%A5%E6%84%9F.assets/image-20230624102744891.png)]](https://img-blog.csdnimg.cn/3f42587cc7f54c6e9f84ffabf33d6c50.png)
在Anaconda Prompt窗口中输入:
activate your-define-name
进入刚安装好tensorflow的虚拟环境
输入
python
进入python后输入:
import tensorflow as tf
sess = tf.Session()
a = tf.constant(10)
b= tf.constant(12)
sess.run(a+b)
# 得到下面的结果,证明安装成功
22
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vxXLl5gY-1688114195616)(%E9%81%A5%E6%84%9F.assets/image-20230624103228891.png)]](https://img-blog.csdnimg.cn/09ef31aa70ae49ddab35425cf8d80c29.png)
方法二:
在Anaconda Navigator中可以直接查看虚拟环境中已下载的包,这个软件安装Anaconda时已默认下载,打开就行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZM62ZnOW-1688114195618)(%E9%81%A5%E6%84%9F.assets/image-20230623111944060.png)]](https://img-blog.csdnimg.cn/655a663403824f49835a3562dea3acb0.png)
其他的包也可以在这个软件中下载。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UJZbrBke-1688114195622)(%E9%81%A5%E6%84%9F.assets/image-20230623114639085.png)]](https://img-blog.csdnimg.cn/cc6a66e55d7642d199f7a2c18f08da6b.png)
6、工具选择
Jupyter和PyCharm是两种不同的开发环境,它们在特点和使用方式上有一些区别。
- 交互性 vs. 集成开发环境(IDE): Jupyter是一种交互式计算环境,主要用于探索性数据分析、教学和快速原型开发。它通过Notebook提供了一个可交互的界面,让你可以在单元格中逐步执行代码并查看结果。PyCharm是一个功能强大的集成开发环境(IDE),专注于Python开发。它提供了丰富的功能和工具,包括代码编辑器、调试器、版本控制等,适合大型项目的开发和维护。
- 文档展示和可视化 vs. 代码编辑和调试: Jupyter注重于文档展示和可视化输出,可以在Notebook中编写文本、添加图表和图像,并实时展示结果。这使得Jupyter非常适合于数据分析和展示工作。PyCharm则更专注于代码编辑和调试功能,提供了强大的代码补全、静态分析、代码导航和调试器等功能,适合开发和维护复杂的Python项目。
- 灵活性和可移植性 vs.功能完备性: Jupyter提供了广泛的支持,可用于多种编程语言,并具有广泛的社区支持和第三方库。它的灵活性和可移植性使得它在快速原型开发、教学和数据科学领域非常受欢迎。PyCharm则是专为Python开发而设计,提供了许多Python特定的功能和工具,使得开发Python项目更高效和便捷。
- 团队协作 vs.个人开发: Jupyter的Notebook可以轻松共享,并支持多人协作。你可以将Notebook分享给其他人,并且其他人可以在其基础上进行编辑和运行代码。这对于团队合作、教学和报告编写非常有用。PyCharm则更适合个人开发和独立工作,它提供了更强大的开发和调试工具,适应大型项目的需求。
Jupyter和PyCharm在目标和使用方式上有所不同。Jupyter注重于交互性、文档展示和数据科学领域,适合快速原型开发和数据分析。PyCharm则是一款专注于Python开发的集成开发环境,提供了丰富的功能和工具,适合大型项目的开发和维护。
这里我两个都用了。感觉还是jupyter比较方便,因为需要修改的时候不需要重新把程序全跑一遍,节省不少时间。
Pycharm
在Pycharm中使用安装的虚拟环境
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7JnPCGUj-1688114195625)(%E9%81%A5%E6%84%9F.assets/20210521152354944.png)]](https://img-blog.csdnimg.cn/c25b33086b56499e936c1e49be64df37.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LDhoxjDF-1688114195630)(%E9%81%A5%E6%84%9F.assets/image-20230623195359623.png)]](https://img-blog.csdnimg.cn/ba6e56e241f141b98506871fc59b9a3d.png)
完成!
Jupyter
Jupyter是一种基于Web的交互式计算环境,它允许你创建和共享包含代码、文本、图像和可视化输出的文档。Jupyter的名称来源于三个主要支持的编程语言:Julia、Python和R(即Ju-Pyt-e-R)。
Jupyter的核心组件是Notebook(笔记本),它以.ipynb文件格式存储,并且可以在Jupyter环境中打开和编辑。Notebook由一系列的单元格组成,每个单元格可以包含代码、文本说明或Markdown格式的内容。
Jupyter提供了许多功能和优势,包括:
- 交互式编程环境:你可以在单元格中编写和执行代码,逐步执行并查看中间结果,这对于数据分析、机器学习和可视化非常有用。
- 丰富的文档展示:你可以在Markdown单元格中编写文本,使用标记语言添加标题、段落、链接、图像和公式等,使得文档更加清晰和易读。
- 可视化输出:Jupyter支持在Notebook中显示图表、图像和其他可视化输出,你可以直接在Notebook中生成和查看数据可视化结果。
- 即时反馈:由于Jupyter的交互性,你可以立即看到代码的输出结果,这有助于调试和迭代代码。
- 支持多种编程语言:除了Julia、Python和R,Jupyter还支持其他编程语言的内核,如Scala、Haskell、Ruby等,你可以根据需要选择适合你的编程语言。
- 易于共享和展示:你可以将Jupyter Notebook导出为HTML、PDF或Markdown格式,方便与他人分享和展示你的工作。
Jupyter的安装非常方便,可以通过Anaconda、pip等包管理工具进行安装。一旦安装完成,你可以在终端中启动Jupyter服务器,然后在浏览器中打开Notebook界面开始编写代码和文档。
总的来说,Jupyter提供了一个强大而灵活的平台,使得数据分析、科学计算和交互式编程更加便捷和可视化。无论是学习、教学还是实际工作中,Jupyter都是一个非常有用的工具。
在安装 Anaconda 的同时会安装Python 和 Jupyter Notebooks这两个工具,并且还包含相当多数据科学和机器学习社区常用的软件包。
Jupyter的默认工作空间在C盘,如想更改,参考链接
切换python虚拟环境
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EEuUgFBb-1688114195633)(%E9%81%A5%E6%84%9F.assets/image-20230630152928232.png)]](https://img-blog.csdnimg.cn/18ba485dd1554b148d73faff1bd1d11a.png)
# 查看当前conda中的虚拟环境,默认为base
conda env list
# conda environments:
#
base * E:\Tools\Anaconda3-2023.03-1\Anaconda3
py36 E:\Tools\Anaconda3-2023.03-1\Anaconda3\envs\py36
tensorflow E:\Tools\Anaconda3-2023.03-1\Anaconda3\envs\tensorflow
# * 为当前选中的环境
# 切换你想使用的虚拟环境
conda activate py36
# 下载ipykernel
pip install ipykernel
# 第一个py36是环境的名称,第二个py36是Notebook中显示的环境名称
python -m ipykernel install --user --name py36 --display-name py36
# 启动jupyter
jupyter notebook
这样即可在jupyter中切换python虚拟环境
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7gZVduz-1688114195633)(%E9%81%A5%E6%84%9F.assets/image-20230630154256316.png)]](https://img-blog.csdnimg.cn/154e776a0bb149d38898d2ffd04f019b.png)
相关库包
建议先看一下问题汇总。
下载指定版本的包可参考 url
pip install patchify
pip install -U segmentation-models
Keras
Keras为tensorflow的简化,将tensorflow中的很多功能封装为api,方便使用
pip install keras
cuda(自选)
安装cuda后可以使用gpu来进行模型训练,可以减轻cpu的压力,减少训练时间。这里因为cpu模型训练时间太长我进行了cuda安装,但是因为gpu太拉了配置好了跑不了,还不如cpu勉强能跑,后面又切换回cpu跑,我的GPU是NVIDIA 1650 4g显存,显存比我大的可以试试。
下面是配置方法:
参考教程:注意教程开头说到的操作顺序,如果遇到一些问题,比如没有Visual Studio或VS没有CUDA11.1的配置,教程底部有解决办法或,我下面也给出了我遇到的一些问题的解决办法,尽量不要忽略问题直接NEXT。
注意自己cuda对应的vs版本,如我的cuda8.0版本,可支持的是2015 2017 2019的vs,不要直接在VS官网下载最新版,极大可能用不了,尽量选择2019之前的版本。安装教程
安装成功:
cuda安装问题
没有VS
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r8yJiiCg-1688114195634)(%E9%81%A5%E6%84%9F.assets/image-20230629210812824.png)]](https://img-blog.csdnimg.cn/af12ba69af394cff97dc7d2ee6655c0d.png)
这个问题,是因为电脑上没有安装Visual Studio,安装以后继续就行,注意自己cuda对应的vs版本,如我的cuda8.0版本,可支持的是2015 2017 2019的vs。安装教程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SYGMdaUF-1688114195634)(%E9%81%A5%E6%84%9F.assets/image-20230629221810049.png)]](https://img-blog.csdnimg.cn/a2d52153b8524e13918da1944eb70566.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2zfyE0Zk-1688114195646)(%E9%81%A5%E6%84%9F.assets/image-20230629221840590.png)]](https://img-blog.csdnimg.cn/e730b694327142d390a8aa2aabf0757d.png)
然后可以配置SDK,如果不成功,可以按照教程最底部的办法操作。
操作完以后,配置SDK还是有问题:
找不到导入的项目“D:\Tools\DevelopTools\VisualStudio2022\Community2019\MSBuild\Microsoft\VC\v160\BuildCustomizations\CUDA 11.1.props”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qkPUM5JF-1688114195647)(%E9%81%A5%E6%84%9F.assets/image-20230630103126337.png)]](https://img-blog.csdnimg.cn/768ef30fcbe44e1982a6bd35e194667b.png)
解决:参考教程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qIH2rWBp-1688114195648)(%E9%81%A5%E6%84%9F.assets/image-20230630103437564.png)]](https://img-blog.csdnimg.cn/41af4135b52b4b13b5a1c0ecd8543ad1.png)
这一步进行完就可以继续生成SDK的操作了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p4LXcQzD-1688114195648)(%E9%81%A5%E6%84%9F.assets/image-20230630104930296.png)]](https://img-blog.csdnimg.cn/20ee4ab913634c80af199abce3ea9baf.png)
版本不兼容
cuDNN和Tensorflow
运行代码时发现不仅程序没加速无法利用GPU,反而出错了,根据报错,是tensorflow版本和cuDNN版本不一致造成的,可以选择去查看二者对应版本,选择修改一个的版本即可。我选择修改cuDNN版本,下载一个8.1.0的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-itoE1zhA-1688114195648)(%E9%81%A5%E6%84%9F.assets/image-20230630110737040.png)]](https://img-blog.csdnimg.cn/2bcae30a61bc4c568c2810f8d4509976.png)
无法分配gpu内存
前面的问题都解决了,代码还是无法运行,报错如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ij4EzZhI-1688114195649)(%E9%81%A5%E6%84%9F.assets/image-20230630112015929.png)]](https://img-blog.csdnimg.cn/efdba9df34d74572bdd04ac745ebed2c.png)
在程序开头添加如下代码,配置GPU利用参数
import tensorflow as tf
# 配置GPU利用参数
# ①指定GPU使用量,占用GPU90%的显存
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.per_process_gpu_memory_fraction = 0.9
# ②设置GPU使用量最小,动态分配现存
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
如果还是跑不了,那就老老实实换cpu跑吧,删掉上面的gpu配置,换成这个
import os
os.environ["CUDA_VISIBLE_DEVICES"] = " "
opencv
pip install opencv-python
我这里下载一直ERROR,所以去下载了whl包后从本地下载
下载地址 url
pip install D:\Python\Tools\whl\opencv_python-3.4.1.15-cp36-cp36m-win_amd64.whl
kears、scikit-learn
conda install kears scikit-learn
numpy
介绍:作为 Python 语言的一个扩展程序库,NumPy 支持大量的维度数组与矩阵运算,也针对数组运算提供大量的数学函数库。自初代版本上线之后,NumPy 已经成为 Python 科学计算的扩展包。如今,在计算多维数组和大型数组方面,它是使用最广的。此外,它还提供多个函数,操作起数组来效率很高,还可用来实现高级数学运算。
版本:对于较低版本的tensorflow,numpy的版本应小于1.2*。因为numpy从1.20版本开始对一些其内基本数据类型的别名和方法进行了修改,而低版本的tensorflow中还在使用建议使用默认下载的版本
matplotlib
conda install -c conda-forge matplotlib
scikit-image
pip install D:\Python\Tools\whl\scikit_image-0.18.3-cp39-cp39-win_amd64.whl
scikit-learn
同上网址下载
pip install D:\Python\Tools\whl\scikit_learn-0.24.2-cp39-cp39-win_amd64.whl
scipy
同上网址下载
pip install D:\Python\Tools\whl\scipy-1.7.3-cp39-cp39-win_amd64.whl
问题汇总
pycharm下载包时Available Packages为空
可能和安装的Anaconda环境有关,这里介绍一下解决方法。我们回到包管理,点击Anaconda图标(原本是选中状态,点击之后就是未选中状态),在未选中状态下,打开下载页面就可以正常的显示了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jljjPBNK-1688114195649)(%E9%81%A5%E6%84%9F.assets/image-20230623164534343.png)]](https://img-blog.csdnimg.cn/7d0f00a40bc748b78a0e8c24811a85c0.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EFyWBwBF-1688114195649)(%E9%81%A5%E6%84%9F.assets/image-20230623164615158.png)]](https://img-blog.csdnimg.cn/68e6b873cc824cceb000263e660b74b8.png)
pip
对于本地已经有python环境的,使用pip时可能并不会将包下载到虚拟环境而是下载到本地的python环境。
解决:调整环境变量的位置,将conda的环境变量移到本地python的环境变量上方或删除本地python的环境变量
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c5ZBC728-1688114195650)(%E9%81%A5%E6%84%9F.assets/image-20230624105605483.png)]](https://img-blog.csdnimg.cn/270cb8e84adb47edb4d45fdbf7a0ed38.png)
conda install 速度缓慢
这是软件本身的问题,加上使用conda下载时要检索冲突选择合适的版本,本身速度就比较慢,如果想解决可以参考下面的教程或自行搜索。
参考教程:url
Jupyter闪退
可能是因为系统用户名(工作目录)有中文,一种方法是修改用户名,另一种是下载较低版本的pyzmq。
这里我试了降低pyzmq和jupyter-client的版本,并尝试了多个版本,还是没用。然后将系统用户名修改为了英文,解决。
大作业代码剖析
因为是参考油管上的英文教程,有的地方因为翻译问题理解的不是很好。
参考教程
https://github.com/prodramp/DeepWorks/tree/main/DL-SatelliteImagery
https://www.youtube.com/watch?v=3Xn21RT-y7Y
dataset
https://www.kaggle.com/datasets/humansintheloop/semantic-segmentation-of-aerial-imagery?resource=download
数据集准备和处理
创建和处理 数据集
分割过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xDlAx09z-1688114195654)(%E9%81%A5%E6%84%9F.assets/image-20230627101820202.png)]](https://img-blog.csdnimg.cn/01c28dde0339476ea2102bef1978c09d.png)
1、确定patch的大小
2、确保所有图像和蒙版大小是patch的整数倍
3、将所有图像和蒙版按patch大小进行分割,将分割后的数据存入numpy数组
裁剪
opencv读取到的image类型为ndarray(<class 'numpy.ndarray>),导入PIL包的image将之转换为PIL.Image.Image类型,然后调用crop方法对图像进行裁剪操作,image.crop()函数可以用于从给定的图像中提取特定区域,它接受一个四元组参数,表示裁剪区域的左上角和右下角的坐标。
这样,我们就得到了大小为patch整数倍的图像。
# 读取图片后
# image是一个n为数组
# image.shape结果示例为(644, 797, 3),代表图片的高、宽和颜色类型
# image.shape[i]可以获取到宽高的值
# 需要将所有图像数据分割成patch大小的整数倍,需要尽可能分割出较多的块
size_x = (image.shape[1]//image_patch_size)*image_patch_size # 分割宽:取最大分割
size_y = (image.shape[0]//image_patch_size)*image_patch_size # 分割高:取最大分割
#print("{} --- {} - {}".format(image.shape, size_x, size_y))
# 上面读取到的image类型为ndarray(<class 'numpy.ndarray>)
# 导入PIL包的image将之转换为PIL.Image.Image类型
image = Image.fromarray(image)
image = image.crop((0,0, size_x, size_y)) # 按照前面得到的倍数裁剪图像
分割
为了分割图像,我们导入patchify包,因为patchify的输入图片数据要求为ndarray类型,再次转换为ndarry类型,然后进行分割
image = np.array(image)
patched_images = patchify(image, (image_patch_size, image_patch_size, 3), step=image_patch_size)
patchify是一个自定义函数,用于将图像分割成块。该函数采用三个参数:
image:输入的图像(NumPy数组)。(image_patch_size, image_patch_size, 3):表示每个块(patch)的尺寸。在这个例子中,每个块的宽度和高度都是image_patch_size,并且图像是RGB格式,所以最后的3表示三个颜色通道(红、绿、蓝)。step=image_patch_size:表示块之间的步长。在这个例子中,块之间的横向和纵向间隔都是image_patch_size,也就是没有重叠。
函数的返回值是一个包含所有块的NumPy数组,其中每个块的形状是 (image_patch_size, image_patch_size, 3)。
通过执行这段代码,我们将得到一个名为 patched_images 的NumPy数组,其中包含了图像被分割成的多个块。这种分块的操作在图像处理中常用于局部处理、批处理或其他类型的图像分析任务。
得到单独的patch图像
for i in range(patched_images.shape[0]):
for j in range(patched_images.shape[1]):
individual_patched_image = patched_images[i,j,:,:]
这段代码使用了嵌套的for循环来遍历patched_images数组的每个块。
patched_images.shape[0]和patched_images.shape[1]分别表示patched_images数组的第一维和第二维的大小,也就是块的行数和列数。
通过这两个嵌套的for循环,我们可以逐个访问patched_images数组中的每个块。对于每个块,我们将其存储在individual_patched_image变量中。
在循环内部,我们对individual_patched_image进行进一步的处理。这个循环遍历的过程可以帮助你在处理大图像时逐个处理每个小块,以提高效率或执行特定的局部操作。
最小-最大归一化
进行最小-最大归一化操作的目的是将数据缩放到一个指定的范围内,通常是[0, 1]之间。
这样的归一化可以带来以下几个好处:
- 特征缩放:最小-最大归一化可以将数据的特征缩放到相同的尺度范围内。在很多机器学习算法中,不同特征的尺度差异较大可能会影响算法的性能。通过归一化处理,可以确保各个特征对模型的影响相对均衡,避免某些特征在计算过程中占据主导地位。
- 梯度下降优化:在使用梯度下降等优化算法进行模型训练时,数据范围的差异可能导致梯度计算过程不稳定,收敛速度慢或无法收敛。通过归一化,可以使得梯度计算更加稳定,并提高优化算法的效果。
- 图像处理:在图像处理中,最小-最大归一化可以将图像的像素值映射到指定的范围内,例如[0, 255]之间。这样可以保证图像的亮度和对比度适宜,并方便进行后续的图像处理操作。
综上所述,通过最小-最大归一化操作,可以提高数据处理和机器学习算法的性能,并确保数据在相同的尺度范围内进行处理,从而避免尺度差异导致的问题。
from sklearn.preprocessing import MinMaxScaler, StandardScaler
minmaxscaler = MinMaxScaler()
individual_patched_image = minmaxscaler.fit_transform(individual_patched_image.reshape(-1, individual_patched_image.shape[-1])).reshape(individual_patched_image.shape)
通过sklearn.preprocessing模块中的MinMaxScaler类对individual_patched_image进行最小-最大归一化,首先,通过MinMaxScaler()创建一个minmaxscaler对象,它将用于对数据进行归一化处理。
接下来,individual_patched_image.reshape(-1, individual_patched_image.shape[-1])将individual_patched_image重塑为二维数组。reshape(-1, individual_patched_image.shape[-1])的作用是将最后一个维度(颜色通道维度)展平为列,而保持前面的维度不变。这样做是为了适应MinMaxScaler的输入要求,它期望接收二维数组作为输入。
然后,minmaxscaler.fit_transform()方法将对重塑后的二维数组进行最小-最大归一化操作。fit_transform()方法将同时拟合(计算最小值和最大值)并进行归一化转换。
最后,通过reshape(individual_patched_image.shape)将归一化后的二维数组重新恢复为原来的形状,即恢复为individual_patched_image的形状。这是为了保持归一化后的数据与原始块的形状一致。
通过执行这段代码,你将获得经过最小-最大归一化处理后的individual_patched_image,其中的像素值将被缩放到指定的范围内。这种归一化处理可以在一些机器学习或图像处理任务中使用,以确保数据在相同的尺度范围内,避免不同特征或像素值之间的差异引起的问题。
将结果存储到数据集中
image_dataset.append(individual_patched_image)
对蒙版图片不需要进行归一化处理。
蒙版图像不需要进行归一化处理的原因是归一化主要用于对数据的特征缩放和统一尺度。对于蒙版图像,其像素值通常只表示不同类别或区域的标签或二值信息,并没有具体的数值含义。因此,在语义分割任务中,对于蒙版图像而言,其像素值本身已经是离散的、有意义的分类信息,不需要进行归一化处理。
相反,对于训练图像,像素值表示图像中不同位置的颜色信息,而这些像素值通常需要归一化处理,以便在训练模型时使得不同特征具有相似的数值范围,以避免某些特征对模型的训练产生过大或过小的影响。因此,在代码中对训练图像执行了最小-最大归一化处理。
颜色格式转换
opencv的官方文档
https://www.w3cschool.cn/artificial_intelligence/artificial_intelligence-jb4l3cdl.html
在OpenCV中,图像不是使用传统的RGB颜色存储的,而是以相反的顺序存储的,即以BGR顺序存储。因此,读取图像时的默认颜色代码是BGR。cvtColor()颜色转换函数用于将图像从一个颜色代码转换为其他颜色代码。
if image_type == 'masks':
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
将数据转化为numpy数组存储
导入matplotlib(可以展示图片)
from matplotlib import pyplot as plt
处理标签并添加单热编码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4xZB48J-1688114195657)(%E9%81%A5%E6%84%9F.assets/image-20230627201655626.png)]
将16进制颜色表示的颜色代码转换为RGB颜色值。数据集的官网上注明了该图像数据中有几类元素和他们的颜色(16进制),将之转换为RGB,方便后续和图像集和label集中的RGB处理。
创建一个和label形状大小相同的全零数组label_segment,用于存储转换后的标签图像。
将label中的图像根据像素点与前面的分类所得RGB比对,结合数据集中提供的json文件,得到存储每个像素点在json中对应索引的np.array
label = individual_patched_mask
def rgb_to_label(label):
label_segment = np.zeros(label.shape, dtype=np.uint8)
label_segment[np.all(label == class_water, axis=-1)] = 0
label_segment[np.all(label == class_land, axis=-1)] = 1
label_segment[np.all(label == class_road, axis=-1)] = 2
label_segment[np.all(label == class_building, axis=-1)] = 3
label_segment[np.all(label == class_vegetation, axis=-1)] = 4
label_segment[np.all(label == class_unlabeled, axis=-1)] = 5
#print(label_segment)
label_segment = label_segment[:,:,0]
#print(label_segment)
return label_segment
labels = []
for i in range(mask_dataset.shape[0]):
label = rgb_to_label(mask_dataset[i])
labels.append(label)
labels = np.array(labels)
labels = np.expand_dims(labels, axis=3)
np.unique(labels)
total_classes = len(np.unique(labels)):计算标签数据集中不重复的类别数量,即总共有多少个类别。这里使用np.unique(labels)获取标签数组中的唯一值,并使用len()函数计算其长度,即类别数量。
from tensorflow.keras.utils import to_categorical:导入to_categorical函数,该函数用于将整数标签转换为独热编码(one-hot encoding)的形式。
labels_categorical_dataset = to_categorical(labels, num_classes=total_classes):调用to_categorical函数将整数标签数据集labels转换为独热编码形式的标签数据集labels_categorical_dataset。num_classes参数指定了总共的类别数量。
total_classes = len(np.unique(labels))
total_classes
from tensorflow.keras.utils import to_categorical
labels_categorical_dataset = to_categorical(labels, num_classes=total_classes)
分割训练数据集和测试数据集
我们可以引入sklearn来学习趋势,测试分割方法,将主训练集分割为训练数据集和测试数据集
使用train_test_split函数将主训练集(master_trianing_dataset)和标签数据集(labels_categorical_dataset)划分为训练集和测试集,并将划分后的数据分配给X_train、X_test、y_train和y_test四个变量。
具体解释如下:
train_test_split(master_trianing_dataset, labels_categorical_dataset, test_size=0.15, random_state=100):调用train_test_split函数进行数据集划分操作。其中,master_trianing_dataset是主训练集,labels_categorical_dataset是标签数据集,test_size=0.15表示测试集所占比例为15%,即将数据集的15%作为测试集,而剩下的85%作为训练集。random_state=100是随机数种子,用于控制数据集的随机划分过程,保证每次划分结果一致。X_train, X_test, y_train, y_test:将train_test_split函数返回的四个数据集分配给对应的变量。X_train表示训练集的特征数据,X_test表示测试集的特征数据,y_train表示训练集的标签数据,y_test表示测试集的标签数据。
通过这行代码,主训练集和标签数据集被划分为训练集和测试集,并分别存储在X_train、X_test、y_train和y_test中,以便后续进行模型的训练和评估。训练集将用于训练模型的参数,而测试集将用于评估模型在新数据上的性能。
master_trianing_dataset = image_dataset
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(master_trianing_dataset, labels_categorical_dataset, test_size=0.15, random_state=100)
现在,我们已经基本完成了对数据集的预处理。
深度学习
U-Net
U-Net是一种经典的卷积神经网络架构,用于图像语义分割任务。它的网络结构由对称的编码器(下采样路径)和解码器(上采样路径)组成,中间还有一个跳跃连接(skip connection)的连接。编码器部分由多个卷积和池化层组成,用于逐步缩小图像尺寸并提取高层次的特征表示。解码器部分通过上采样和卷积层逐步恢复图像尺寸,并将低层次的特征与高层次的特征进行合并,利用跳跃连接实现特征的重用和融合。最后,使用一个适当的输出层对每个像素进行分类,生成与输入图像尺寸相同的分割结果。
U-Net 的独特之处在于它能够同时提取局部细节和全局语义信息,并且通过跳跃连接可以融合不同层次的特征。这使得 U-Net 在处理边缘、细小结构和不完整目标等具有挑战性的分割任务中表现出色。U-Net 在医学图像分割、自然图像分割和其他领域的图像分割任务中广泛应用,并成为了许多后续模型的基础和参考。
相关链接:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
代码中的深度学习模型将根据下图创建。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YDGMlJlL-1688114195659)(%E9%81%A5%E6%84%9F.assets/u-net-architecture.png)]](https://img-blog.csdnimg.cn/197f9c9a3b804d1bb34439854a5c20f9.png)
netron深度学习模型可视化工具:可以在改工具中验证每一层及其参数配置,连接到其他层的串联和我们在代码中所在的所有其他事情,我们通过模型可视化工具验证所有内容并确保我们所做的所有事情都已在架构中描述并在我们的代码中创建。
https://github.com/lutzroeder/netron
U-Net模型架构
导入库包
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, Conv2DTranspose
from keras.layers import concatenate, BatchNormalization, Dropout, Lambda
from keras import backend as K
这段代码导入了Keras库中的一些模块和函数。具体解释如下:
from keras.models import Model:从Keras库的models模块中导入Model类,用于构建模型。from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, Conv2DTranspose:从Keras库的layers模块中导入一些常用的卷积神经网络层类,如Input、Conv2D、MaxPooling2D、UpSampling2D、Conv2DTranspose等,用于构建模型的层。from keras.layers import concatenate, BatchNormalization, Dropout, Lambda:从Keras库的layers模块中导入一些其他常用的层类,如concatenate(用于特征拼接)、BatchNormalization(批量归一化)、Dropout(随机失活)和Lambda(自定义层),用于构建模型的层。from keras import backend as K:导入Keras库的backend模块,并将其命名为K,用于处理底层的张量操作和计算。这个模块提供了一些与底层引擎(如TensorFlow、Theano等)相关的函数和操作。
这些导入的模块和函数是构建和定义深度学习模型所需的基本组件,它们将在后续的代码中使用。
评估指标 Jaccard
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OBhRvh0z-1688114195660)(%E9%81%A5%E6%84%9F.assets/image-20230627223103973.png)]](https://img-blog.csdnimg.cn/023bb240d1cf40729252c7a440268d26.png)
https://en.wikipedia.org/wiki/Jaccard_index
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-un5PIPqk-1688114195660)(%E9%81%A5%E6%84%9F.assets/image-20230629101933705.png)]](https://img-blog.csdnimg.cn/b40bb2234e6d4703a1530a3d2c6f69f4.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Urwlc8Q-1688114195660)(%E9%81%A5%E6%84%9F.assets/image-20230629102339475.png)]](https://img-blog.csdnimg.cn/5030b268f3884b479cdc2143b9b19bda.png)
利用评估指标来对分类结果进行评估。我采用Jaccard系数(也称IOU,交并比),即将代码分类结果和人工分类好的结果对比,用二者的交集比二者并集得出IOU做评估,如果IOU值接近于1,代表这次分类结果近乎完美,如果值非常小,那么代表结果很差。通过这个值可以反应出模型训练的程度。
实现代码:
def jaccard_coef(y_true, y_pred):
y_true_flatten = K.flatten(y_true)
y_pred_flatten = K.flatten(y_pred)
intersection = K.sum(y_true_flatten * y_pred_flatten)
final_coef_value = (intersection + 1.0) / (K.sum(y_true_flatten) + K.sum(y_pred_flatten) - intersection + 1.0)
return final_coef_value
这段代码定义了一个名为 jaccard_coef 的函数,用于计算 Jaccard 系数(也称为 IoU,交并比)。
具体解释如下:
def jaccard_coef(y_true, y_pred)::定义了一个函数jaccard_coef,它接受两个参数y_true和y_pred,分别表示真实标签和预测标签。y_true_flatten = K.flatten(y_true):将真实标签y_true进行扁平化操作,将其转换为一维向量。y_pred_flatten = K.flatten(y_pred):将预测标签y_pred进行扁平化操作,将其转换为一维向量。intersection = K.sum(y_true_flatten * y_pred_flatten):计算真实标签和预测标签的交集,通过将两个一维向量逐元素相乘,然后求和得到交集的数量。final_coef_value = (intersection + 1.0) / (K.sum(y_true_flatten) + K.sum(y_pred_flatten) - intersection + 1.0):根据 Jaccard 系数的公式,计算 Jaccard 系数的值。分子部分是交集加上一个平滑项,分母部分是真实标签和预测标签的总和减去交集再加上一个平滑项。return final_coef_value:返回计算得到的 Jaccard 系数的值。
这个函数的作用是计算真实标签和预测标签之间的 Jaccard 系数,用于评估预测结果与真实结果之间的相似度。Jaccard 系数的取值范围是 0 到 1,数值越接近 1 表示预测结果与真实结果的重叠程度越高。
U-Net模型编码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kNjk9FFo-1688114195661)(%E9%81%A5%E6%84%9F.assets/u-net-architecture.png)]](https://img-blog.csdnimg.cn/5a09ec1055b34a76b3ed502a33e4b743.png)
根据图例来实现模型代码,可以看出不同层之间的参数关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J9H2B7jt-1688114195663)(%E9%81%A5%E6%84%9F.assets/image-20230628111803603.png)]](https://img-blog.csdnimg.cn/f6b25891500642c6b290ab5390c13f95.png)
该图是原作者用于医学影像分类的,对于我们要进行的遥感图像分类,具体的参数设置需要根据前面计算的评估指标进行调整。
因为我们使用的数据集上已经有人给出了U-Net最佳的参数设置,可以拿来使用,救了我大作业大命了,感谢前辈们的工作和无私奉献。
https://www.kaggle.com/code/enesaltun/u-net
def multi_unet_model(n_classes=5, image_height=256, image_width=256, image_channels=1):
inputs = Input((image_height, image_width, image_channels))
source_input = inputs
c1 = Conv2D(16, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(source_input)
c1 = Dropout(0.2)(c1)
c1 = Conv2D(16, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c1)
p1 = MaxPooling2D((2,2))(c1)
c2 = Conv2D(32, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(p1)
c2 = Dropout(0.2)(c2)
c2 = Conv2D(32, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c2)
p2 = MaxPooling2D((2,2))(c2)
c3 = Conv2D(64, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(p2)
c3 = Dropout(0.2)(c3)
c3 = Conv2D(64, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c3)
p3 = MaxPooling2D((2,2))(c3)
c4 = Conv2D(128, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(p3)
c4 = Dropout(0.2)(c4)
c4 = Conv2D(128, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c4)
p4 = MaxPooling2D((2,2))(c4)
c5 = Conv2D(256, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(p4)
c5 = Dropout(0.2)(c5)
c5 = Conv2D(256, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c5)
u6 = Conv2DTranspose(128, (2,2), strides=(2,2), padding="same")(c5)
u6 = concatenate([u6, c4])
c6 = Conv2D(128, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(u6)
c6 = Dropout(0.2)(c6)
c6 = Conv2D(128, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c6)
u7 = Conv2DTranspose(64, (2,2), strides=(2,2), padding="same")(c6)
u7 = concatenate([u7, c3])
c7 = Conv2D(64, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(u7)
c7 = Dropout(0.2)(c7)
c7 = Conv2D(64, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c7)
u8 = Conv2DTranspose(32, (2,2), strides=(2,2), padding="same")(c7)
u8 = concatenate([u8, c2])
c8 = Conv2D(32, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(u8)
c8 = Dropout(0.2)(c8)
c8 = Conv2D(32, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c8)
u9 = Conv2DTranspose(16, (2,2), strides=(2,2), padding="same")(c8)
u9 = concatenate([u9, c1], axis=3)
c9 = Conv2D(16, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(u9)
c9 = Dropout(0.2)(c9)
c9 = Conv2D(16, (3,3), activation="relu", kernel_initializer="he_normal", padding="same")(c9)
outputs = Conv2D(n_classes, (1,1), activation="softmax")(c9)
model = Model(inputs=[inputs], outputs=[outputs])
return model
metrics = ["accuracy", jaccard_coef]
def get_deep_learning_model():
return multi_unet_model(n_classes=total_classes,
image_height=image_height,
image_width=image_width,
image_channels=image_channels)
model = get_deep_learning_model()
这段代码定义了一个 U-Net 模型。以下是代码的主要部分解释:
multi_unet_model是一个函数,用于创建 U-Net 模型。它接受一些参数,如类别数量n_classes、图像高度image_height、图像宽度image_width和图像通道数image_channels。- 首先,创建一个输入层
inputs,其形状为(image_height, image_width, image_channels)。 - 接下来,定义 U-Net 的编码器部分。使用一系列的卷积层(
Conv2D)、激活函数(relu)、批归一化层(BatchNormalization)、dropout 层(Dropout)和最大池化层(MaxPooling2D)来提取图像特征。编码器部分包括五个阶段,每个阶段都会对特征进行下采样。 - 然后,定义 U-Net 的解码器部分。使用转置卷积层(
Conv2DTranspose)和跳跃连接(concatenate)来逐步进行上采样和特征融合。解码器部分也包括五个阶段,每个阶段都会对特征进行上采样。 - 最后,通过一个具有 softmax 激活函数的 1x1 卷积层(
Conv2D)生成最终的输出。这里的输出通道数等于类别数量n_classes,每个像素点预测属于各个类别的概率。 - 创建模型对象
model,将输入层和输出层连接起来,并返回该模型。 metrics = ["accuracy", jaccard_coef]: 这里定义了一个列表metrics,其中包含了两个指标名称,分别是准确性accuracy和Jaccard系数jaccard_coef。在训练和评估模型时,将使用这两个指标来衡量模型的性能。- 通过
get_deep_learning_model()来获取模型,定义这个函数的优点是能够方便我们获取模型,不需要在获取时再填入参数。
自定义损失函数
焦点损失
为了生成焦点损失我们需要系数差异函数(Dice loss)
Dice loss(Dice损失)是一种用于图像分割任务的损失函数。它在分割任务中被广泛使用,特别适用于处理类别不平衡的情况。
Dice loss基于Dice系数(也称为Sørensen-Dice系数),它是衡量预测结果与真实标签之间相似度的指标。Dice系数的取值范围为0到1,其中0表示完全不相似,1表示完全相同。
Dice loss的计算方式是通过将预测结果和真实标签的交集与它们的并集进行比较来衡量相似度。具体而言,对于每个像素或每个类别,计算预测结果和真实标签的交集的大小,然后将其除以预测结果和真实标签的总像素数(或总类别数)。最后,将1减去该值,得到Dice系数。
Dice loss是通过最小化Dice系数的补数来定义的。这意味着Dice loss越小,Dice系数越大,模型的性能越好。在训练过程中,优化器会尝试最小化Dice loss,以促使模型生成更接近真实标签的分割结果。
总而言之,Dice loss是一种衡量图像分割模型性能的损失函数,它通过比较预测结果和真实标签之间的相似度来指导模型的训练。它在解决类别不平衡问题时特别有效,并且在医学图像分割等领域得到广泛应用。
D
i
c
e
L
o
s
s
=
2
∣
X
∩
Y
∣
∣
X
∣
+
∣
Y
∣
DiceLoss = \frac{2|X\cap Y |}{|X| + |Y|}
DiceLoss=∣X∣+∣Y∣2∣X∩Y∣
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UA6lSIjn-1688114195665)(%E9%81%A5%E6%84%9F.assets/image-20230629102322895.png)]
注:Jaccard指数基本上是并交交集 (IoU)。如果用 1 减去 Jaccard Index,就会得到 Jaccard Loss(或 IoU loss)。同样,如果您对 Dice Coef 执行相同操作,您将得到 Dice Loss。这里不要把Dice Loss和前面的评估指标Jaccard系数搞混了。对于 IoU(或 Jaccard)和 Dice 的比较,我建议阅读这篇文章。:https://karan-jakhar.medium.com/100-days-of-code-day-7-84e4918cb72c
代码实现:
weights = [0.1666, 0.1666, 0.1666, 0.1666, 0.1666, 0.1666]
import segmentation_models as sm
dice_loss = sm.losses.DiceLoss(class_weights = weights)
focal_loss = sm.losses.CategoricalFocalLoss()
total_loss = dice_loss + (1 * focal_loss)
在这段代码中,首先导入了 segmentation_models 库,然后使用 segmentation_models.losses 模块中的 DiceLoss 类来定义 Dice Loss,用于衡量模型预测结果与真实标签之间的相似度。
通过 class_weights 参数传入了一个权重列表 [0.1666, 0.1666, 0.1666, 0.1666, 0.1666, 0.1666],这些权重将应用于 Dice Loss 计算中的不同类别。这可以用于平衡不同类别之间的重要性或样本不平衡问题,我的训练数据集和测试数据集一共有6类,所以平均权重为0.1666。
接下来,定义了一个 CategoricalFocalLoss 对象,这是另一种常见的损失函数。与 Dice Loss 不同,CategoricalFocalLoss 是基于 Focal Loss 的一种分类损失函数,用于处理类别不平衡和难易样本的问题。
最后,将 Dice Loss 和 Focal Loss 相加,以得到总的损失函数 total_loss。这意味着模型将使用 Dice Loss 和 Focal Loss 之和作为训练过程中的优化目标。这样做可以帮助模型更好地学习并适应不同类别和样本分布的数据。
编译和可视化模型
import tensorflow as tf
tf.keras.backend.clear_session()
model.compile(optimizer="adam", loss=total_loss, metrics=metrics)
model.summary()
from keras.utils.vis_utils import plot_model
# 展示模型架构
plot_model(model, to_file="satellite_model_plot.png", show_shapes=True, show_layer_names=True)
导入 TensorFlow 库,使用 tf.keras.backend.clear_session() 来清除之前可能存在的 Keras 会话。
接下来,你使用 model.compile() 编译模型,设置了优化器为 Adam,并将损失函数设置为 total_loss(在之前的问题中定义的自定义损失函数),添加评估指标metrics(也已在之前定义)用于模型训练过程中的监控。
然后,使用 model.summary() 打印模型的摘要信息,该信息包含了模型的层次结构、输出形状以及参数数量等详细信息。
接下来,从 keras.utils.vis_utils 中导入 plot_model 函数。用于可视化模型的架构图。
调用 plot_model() 来生成模型的架构图,并将其保存为 "satellite_model_plot.png" 文件。show_shapes=True 参数用于显示每个层次的输入输出形状,show_layer_names=True 参数用于显示每个层次的名称。
import keras
from IPython.display import clear_output
# plt.show()
class PlotLoss(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.i = 0
self.x = []
self.losses = []
self.val_losses = []
self.jaccard_coef = []
self.val_jaccard_coef = []
self.fig = plt.figure()
self.logs = []
def on_epoch_end(self, epoch, logs={}):
self.logs.append(logs)
self.x.append(self.i)
# self.losses.append(logs.get('loss'))
# self.val_losses.append(logs.get('val_loss'))
self.jaccard_coef.append(logs.get('jaccard_coef'))
self.val_jaccard_coef.append(logs.get('val_jaccard_coef'))
self.i += 1
clear_output(wait=True)
# plt.plot(self.x, self.losses, label="loss")
# plt.plot(self.x, self.val_losses, label="val_loss")
plt.plot(self.x, self.jaccard_coef, label="jaccard_coef")
plt.plot(self.x, self.val_jaccard_coef, label="val_jaccard_coef")
plt.legend()
plt.show();
plot_loss = PlotLoss()
class PlotLossEx(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.i = 0
self.x = []
self.losses = []
self.val_losses = []
self.jaccard_coef = []
self.val_jaccard_coef = []
self.fig = plt.figure()
self.logs = []
def on_epoch_end(self, epoch, logs={}):
self.logs.append(logs)
self.x.append(self.i)
self.losses.append(logs.get('loss'))
self.val_losses.append(logs.get('val_loss'))
self.jaccard_coef.append(logs.get('jaccard_coef'))
self.val_jaccard_coef.append(logs.get('val_jaccard_coef'))
self.i += 1
plt.figure(figsize=(14,8))
f, (graph1, graph2) = plt.subplots(1,2, sharex=True)
clear_output(wait=True)
graph1.set_yscale('log')
graph1.plot(self.x, self.losses, label="loss")
graph1.plot(self.x, self.val_losses, label="val_loss")
graph1.legend()
graph2.set_yscale('log')
graph2.plot(self.x, self.jaccard_coef, label="jaccard_coef")
graph2.plot(self.x, self.val_jaccard_coef, label="val_jaccard_coef")
graph2.legend()
plt.show();
plot_loss = PlotLossEx()
model_history = model.fit(X_train, y_train,
batch_size=16,
verbose=1,
epochs=10,
validation_data=(X_test, y_test),
callbacks=[plot_loss],
shuffle=False)
model_history = model.fit(X_train, y_train,
batch_size=16,
verbose=1,
epochs=10,
validation_data=(X_test, y_test),
callbacks=[plot_loss],
shuffle=False)
history_a = model_history
history_a.history
loss = history_a.history['loss']
val_loss = history_a.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'y', label="Training Loss")
plt.plot(epochs, val_loss, 'r', label="Validation Loss")
plt.title("Training Vs Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
jaccard_coef = history_a.history['jaccard_coef']
val_jaccard_coef = history_a.history['val_jaccard_coef']
epochs = range(1, len(jaccard_coef) + 1)
plt.plot(epochs, jaccard_coef, 'y', label="Training IoU")
plt.plot(epochs, val_jaccard_coef, 'r', label="Validation IoU")
plt.title("Training Vs Validation IoU")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
model_history.params
y_pred = model.predict(X_test)
len(y_pred)
y_pred
y_pred_argmax = np.argmax(y_pred, axis=3)
len(y_pred_argmax)
y_pred_argmax
y_test_argmax = np.argmax(y_test, axis=3)
y_test_argmax
import random
test_image_number = random.randint(0, len(X_test))
test_image = X_test[test_image_number]
ground_truth_image = y_test_argmax[test_image_number]
test_image_input = np.expand_dims(test_image, 0)
prediction = model.predict(test_image_input)
predicted_image = np.argmax(prediction, axis=3)
predicted_image = predicted_image[0,:,:]
plt.figure(figsize=(14,8))
plt.subplot(231)
plt.title("Original Image")
plt.imshow(test_image)
plt.subplot(232)
plt.title("Original Masked image")
plt.imshow(ground_truth_image)
plt.subplot(233)
plt.title("Predicted Image")
plt.imshow(predicted_image)
model.save("satellite_segmentation_full.h5")
首先导入必要的库,包括 Keras 和 Matplotlib。clear_output 函数是从 IPython.display 中导入的,用于在每个 epoch 结束后清除输出。
然后,定义两个自定义的回调函数 PlotLoss 和 PlotLossEx,这些回调函数将在每个 epoch 结束时记录训练过程中的损失和指标,并在图形上进行可视化。
PlotLoss 类只绘制了 jaccard_coef 和 val_jaccard_coef 的曲线,而 PlotLossEx 类则同时绘制了 loss、val_loss、jaccard_coef 和 val_jaccard_coef 的曲线。
接下来,使用 model.fit 函数进行模型的训练。我提供了训练数据 X_train 和标签数据 y_train,设置了批次大小、训练周期数和验证数据。并将之前定义的回调函数 plot_loss 添加到了 callbacks 参数中,以便在每个 epoch 结束时可视化训练过程。
之后,通过绘制训练和验证损失的曲线来展示训练过程中的性能。使用 history_a 对象的 history 属性获取了训练过程中的损失和指标记录,并使用 Matplotlib 绘制了训练损失和验证损失的曲线。
接下来,使用训练好的模型对测试集 X_test 进行预测,并将预测结果保存在 y_pred 中。然后,使用 np.argmax 将预测结果转换为类别标签,并保存在 y_pred_argmax 中。同样地,将测试集标签转换为类别标签并保存在 y_test_argmax 中。
随后,从测试集中随机选择一张图像,并使用模型对该图像进行预测。使用 plt.subplot 函数将原始图像、原始掩膜图像和预测图像以子图的形式显示出来,最后使用 plt.imshow 进行图像的显示。
将模型保存到磁盘
使用 model.save 将训练好的模型保存到名为 "satellite_segmentation_full.h5" 的文件中。
模型可视化
模型导出后,可以再Netron上可视化查看。(将.h5格式的模型文件拖动到浏览器中即可)
https://netron.app/
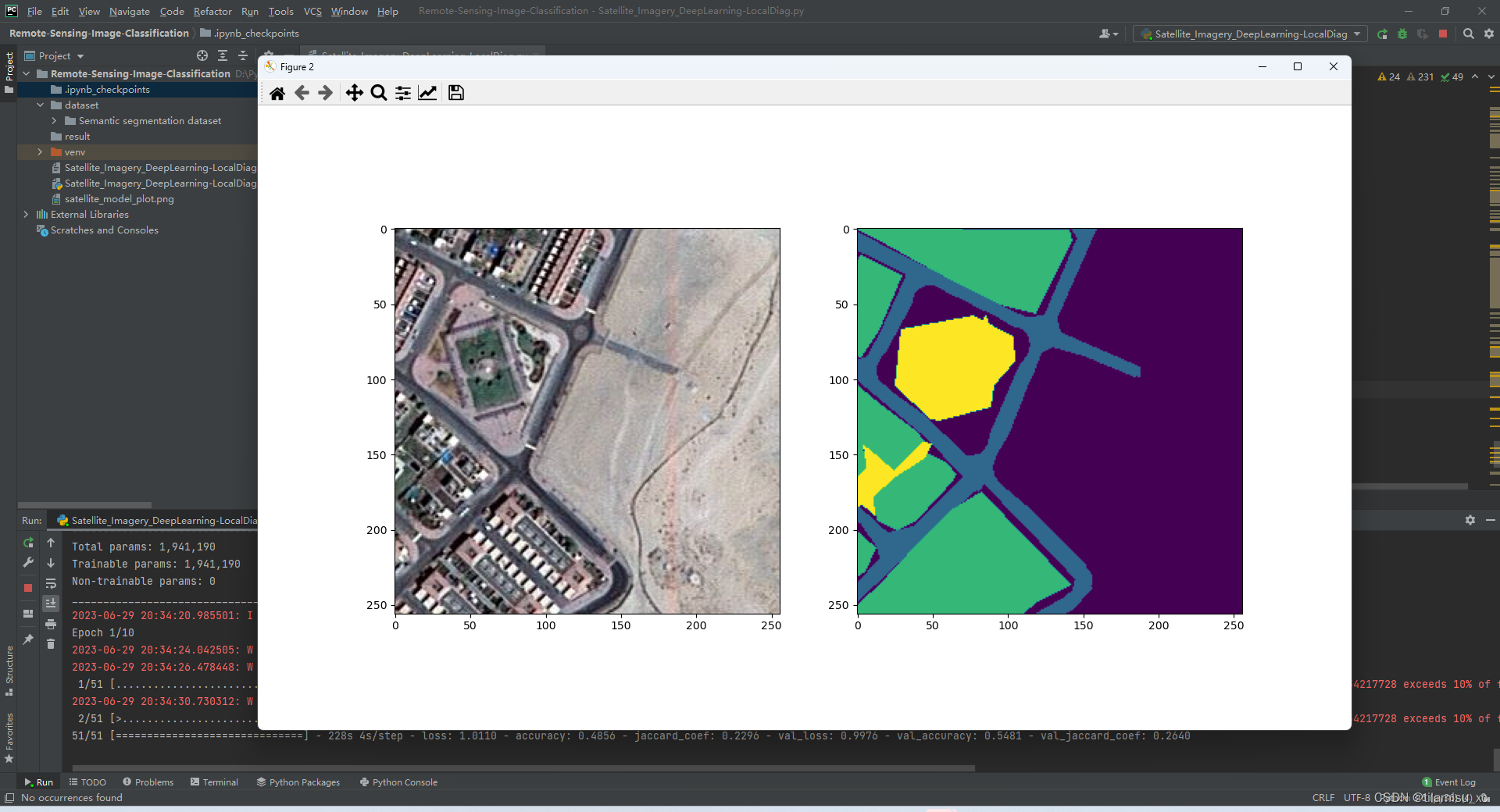
运行结果
Jupyter
见JupyterResult.pdf或.ipynb文件
Pycharm

Epoch 1/10
51/51 [==============================] - 201s 4s/step - loss: 1.0037 - accuracy: 0.5382 - jaccard_coef: 0.2545 - val_loss: 0.9942 - val_accuracy: 0.5913 - val_jaccard_coef: 0.2871
Epoch 2/10
51/51 [==============================] - 197s 4s/step - loss: 0.9827 - accuracy: 0.6595 - jaccard_coef: 0.3588 - val_loss: 0.9739 - val_accuracy: 0.6620 - val_jaccard_coef: 0.3872
Epoch 3/10
51/51 [==============================] - 191s 4s/step - loss: 0.9703 - accuracy: 0.6988 - jaccard_coef: 0.4137 - val_loss: 0.9675 - val_accuracy: 0.6951 - val_jaccard_coef: 0.3934
Epoch 4/10
51/51 [==============================] - 189s 4s/step - loss: 0.9651 - accuracy: 0.7114 - jaccard_coef: 0.4364 - val_loss: 0.9618 - val_accuracy: 0.7276 - val_jaccard_coef: 0.4445
Epoch 5/10
51/51 [==============================] - 188s 4s/step - loss: 0.9588 - accuracy: 0.7316 - jaccard_coef: 0.4663 - val_loss: 0.9717 - val_accuracy: 0.6627 - val_jaccard_coef: 0.4023
Epoch 6/10
51/51 [==============================] - 188s 4s/step - loss: 0.9527 - accuracy: 0.7483 - jaccard_coef: 0.5049 - val_loss: 0.9807 - val_accuracy: 0.6184 - val_jaccard_coef: 0.3851
Epoch 7/10
51/51 [==============================] - 196s 4s/step - loss: 0.9487 - accuracy: 0.7569 - jaccard_coef: 0.5242 - val_loss: 0.9722 - val_accuracy: 0.6627 - val_jaccard_coef: 0.4278
Epoch 8/10
51/51 [==============================] - 187s 4s/step - loss: 0.9444 - accuracy: 0.7699 - jaccard_coef: 0.5473 - val_loss: 0.9650 - val_accuracy: 0.7025 - val_jaccard_coef: 0.4662
Epoch 9/10
51/51 [==============================] - 186s 4s/step - loss: 0.9408 - accuracy: 0.7824 - jaccard_coef: 0.5680 - val_loss: 0.9634 - val_accuracy: 0.7243 - val_jaccard_coef: 0.4822
Epoch 10/10
51/51 [==============================] - 187s 4s/step - loss: 0.9382 - accuracy: 0.7878 - jaccard_coef: 0.5781 - val_loss: 0.9526 - val_accuracy: 0.7506 - val_jaccard_coef: 0.5295
Epoch 1/10
51/51 [==============================] - 190s 4s/step - loss: 0.9358 - accuracy: 0.7960 - jaccard_coef: 0.5927 - val_loss: 0.9503 - val_accuracy: 0.7557 - val_jaccard_coef: 0.5542
Epoch 2/10
51/51 [==============================] - 186s 4s/step - loss: 0.9316 - accuracy: 0.8068 - jaccard_coef: 0.6140 - val_loss: 0.9481 - val_accuracy: 0.7634 - val_jaccard_coef: 0.5640
Epoch 3/10
51/51 [==============================] - 186s 4s/step - loss: 0.9295 - accuracy: 0.8117 - jaccard_coef: 0.6211 - val_loss: 0.9565 - val_accuracy: 0.7445 - val_jaccard_coef: 0.5387
Epoch 4/10
51/51 [==============================] - 204s 4s/step - loss: 0.9312 - accuracy: 0.8059 - jaccard_coef: 0.6126 - val_loss: 0.9383 - val_accuracy: 0.7884 - val_jaccard_coef: 0.5943
Epoch 5/10
51/51 [==============================] - 198s 4s/step - loss: 0.9268 - accuracy: 0.8184 - jaccard_coef: 0.6356 - val_loss: 0.9395 - val_accuracy: 0.7859 - val_jaccard_coef: 0.5928
Epoch 6/10
51/51 [==============================] - 196s 4s/step - loss: 0.9245 - accuracy: 0.8235 - jaccard_coef: 0.6400 - val_loss: 0.9367 - val_accuracy: 0.7848 - val_jaccard_coef: 0.6009
Epoch 7/10
51/51 [==============================] - 193s 4s/step - loss: 0.9239 - accuracy: 0.8245 - jaccard_coef: 0.6458 - val_loss: 0.9429 - val_accuracy: 0.7828 - val_jaccard_coef: 0.5968
Epoch 8/10
51/51 [==============================] - 196s 4s/step - loss: 0.9230 - accuracy: 0.8265 - jaccard_coef: 0.6441 - val_loss: 0.9368 - val_accuracy: 0.7908 - val_jaccard_coef: 0.6139
Epoch 9/10
51/51 [==============================] - 185s 4s/step - loss: 0.9207 - accuracy: 0.8316 - jaccard_coef: 0.6571 - val_loss: 0.9339 - val_accuracy: 0.7973 - val_jaccard_coef: 0.6212
Epoch 10/10
51/51 [==============================] - 190s 4s/step - loss: 0.9189 - accuracy: 0.8363 - jaccard_coef: 0.6640 - val_loss: 0.9314 - val_accuracy: 0.8018 - val_jaccard_coef: 0.6249
val_loss: 0.9565 - val_accuracy: 0.7445 - val_jaccard_coef: 0.5387
Epoch 4/10
51/51 [==============================] - 204s 4s/step - loss: 0.9312 - accuracy: 0.8059 - jaccard_coef: 0.6126 - val_loss: 0.9383 - val_accuracy: 0.7884 - val_jaccard_coef: 0.5943
Epoch 5/10
51/51 [==============================] - 198s 4s/step - loss: 0.9268 - accuracy: 0.8184 - jaccard_coef: 0.6356 - val_loss: 0.9395 - val_accuracy: 0.7859 - val_jaccard_coef: 0.5928
Epoch 6/10
51/51 [==============================] - 196s 4s/step - loss: 0.9245 - accuracy: 0.8235 - jaccard_coef: 0.6400 - val_loss: 0.9367 - val_accuracy: 0.7848 - val_jaccard_coef: 0.6009
Epoch 7/10
51/51 [==============================] - 193s 4s/step - loss: 0.9239 - accuracy: 0.8245 - jaccard_coef: 0.6458 - val_loss: 0.9429 - val_accuracy: 0.7828 - val_jaccard_coef: 0.5968
Epoch 8/10
51/51 [==============================] - 196s 4s/step - loss: 0.9230 - accuracy: 0.8265 - jaccard_coef: 0.6441 - val_loss: 0.9368 - val_accuracy: 0.7908 - val_jaccard_coef: 0.6139
Epoch 9/10
51/51 [==============================] - 185s 4s/step - loss: 0.9207 - accuracy: 0.8316 - jaccard_coef: 0.6571 - val_loss: 0.9339 - val_accuracy: 0.7973 - val_jaccard_coef: 0.6212
Epoch 10/10
51/51 [==============================] - 190s 4s/step - loss: 0.9189 - accuracy: 0.8363 - jaccard_coef: 0.6640 - val_loss: 0.9314 - val_accuracy: 0.8018 - val_jaccard_coef: 0.6249
Process finished with exit code 0

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)