大数据ETL工具对比(Sqoop, DataX, Kettle)
DataX和Kettle都是通用的数据集成工具,支持多种数据源和目标,提供了强大的数据转换和清洗功能。DataX和Kettle的区别在于开发者和用户群体,DataX在阿里巴巴内部得到广泛应用,而Kettle则是一个独立的开源项目。Sqoop主要用于Hadoop和关系型数据库之间的数据传输,适用于大规模数据的导入导出任务。
前言
在实习过程中,遇到了数据库迁移项目,对于数据仓库,大数据集成类应用,通常会采用ETL工具辅助完成,公司和客户使用的比较多的是Sqoop, DataX和Kettle这三种工具。简单的对这三种ETL工具进行一次梳理。
ETL工具,需要完成对源端数据的抽取(exat), 交互转换(transform), 加载(load)至目标端的过程。
1. Sqoop
1.1 介绍
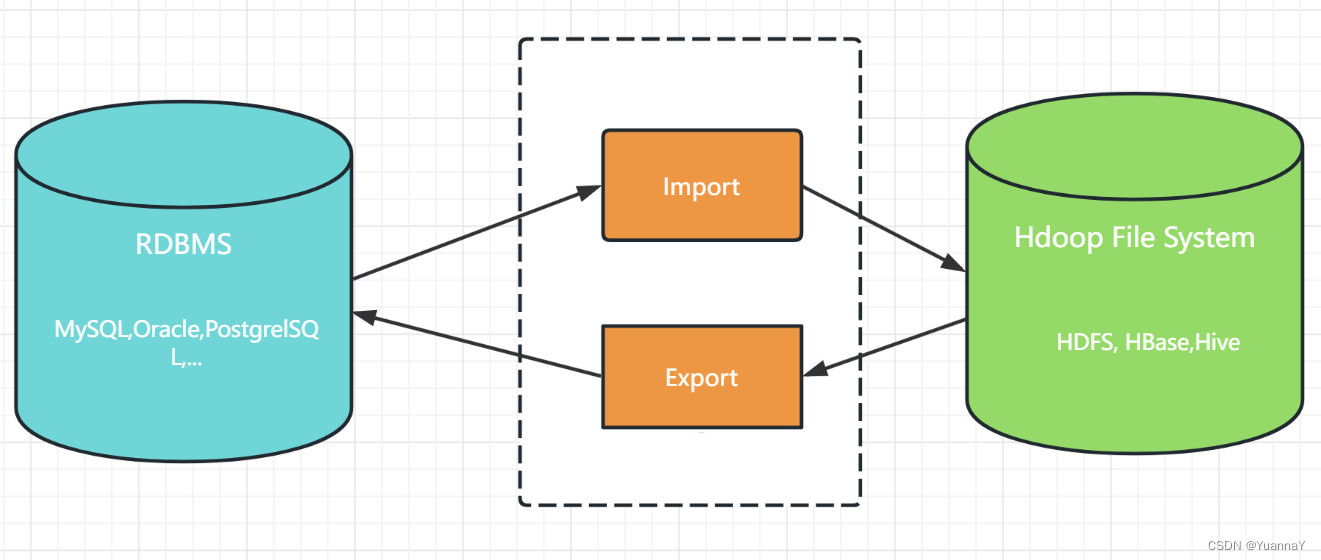
Sqoop, SQL to Hadoop, 可以实现SQL 和Hadoop之间的数据转换。
Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具,可以将一个关系型数据库(MySQL, Oracle等)中的数据库导入到Hadoop中的HDFS中,也可以将HDFS的数据导出到关系数据库中。
Sqoop命令的底层就是转化为MapReduce程序。 Sqoop分为import和export,策略分为table和query,模式分为增量和全量。

Sqoop支持全量数据导入和增量数据导入,增量数据导入又可以分为两种,一是基于递增列的增量式数据导入(Append),而是基于时间列的增量数据导入(LastModified),另外还可以指定数据是否以并发形式导入。
1.2 特点
- 可以将关系型数据库中的数据导入hdfs、hive或者hbase等组件中,也可以将hadoop组件中的数据导入到关系型数据库中。
- Sqoop采用map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。可以在多个节点进行import或者export操作,速度比单节点运行多个并行导入导出效率高,有良好的并发性和容错性。
2. DataX
2.1 介绍
DataX是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源,以此实现新数据源与已有数据源之间的无缝数据同步。

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象为Reader和Writer插件,纳入到整个同步框架中。
- Reader: 数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: 数据写入模块, 负责不断向Framework取数据,并将数据写入到目的端。

2.2 特点
- 异构数据库和文件系统之间的数据交换
- 采用Framework+plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问。
- 数据传输过程在单进程内完成,全内存操作。
- 拓展性强,开发者可以开发一个新插件支持新的数据库文件系统。
3. Kettle
3.1 介绍
一款国外开源免费的,可视化的,功能强大的ETL工具,纯Java编写,主流系统上都可以运行,数据抽取高效稳定,支持各种数据源,如关系型数据库、NoSQL、文件。
Kettle现在已经更名为PDI,Pentaho Data Integration-Pentaho数据集成。
kettle的执行分为两个层次:
- Transformatiobn:完成对数据的基本转换。
- Job: 完成整个工作流的控制。

简单理解, 一个转换(Trans)就是一个ETL的过程,而作业(Job)是多个转换的集合, 在作业中可以对转换或作业进行调度,定时任务。
核心组件
- Spoon是一个可视化的EPL设计工具,用户可以使用Spoon中的可视化界面来创建源、目标和转换的连接,以及定义数据集成的转换和逻辑。
- Pan:运行转换的命令工具。
- Kitchen: 运行作业的命令工具。
- Carte: 轻量级别的Web容器,用于建立专用、远程的ETL Server。
3.2 特点
- 免费开源,可跨平台(因为是纯java编写)
- 图形界面设计,无需写代码
- 两种脚本文件,trans负责数据转化,job负责整个工作流的调度控制。
- 支持作业调度和监控,可以自动化执行数据集成任务。
4. 工具对比
DataX 与 Sqoop
| 功能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程 多线程 | MR |
| 分布式 | 不支持 | 支持 |
| 流控 | 有流控功能 | 没有 |
| 统计信息 | 有部分统计,上报需定制 | 没有 |
| 数据校验 | 在core部分有 | 没有,分布式数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
| 功能 | DataX | Kettle |
|---|---|---|
| 数据源 | 少数关系型数据库和大数据非关系型数据库 | 多数关系型数据库 |
| 底层架构 | 支持单机部署和集群部署两种方式 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 |
| CDC机 | 离线批处理 | 基于时间戳、触发器等 |
| 对数据库的影响 | 通过sql select 采集数据,对数据源没有侵入性 | 对数据库表结构有要求,存在一定侵入性 |
| 数据清洗 | 需要根据自身清晰规则编写清洗脚本,进行调用(DataX3.0 提供的功能)。 | 围绕数据仓库的数据需求进行建模计算,清洗功能相对复杂,需要手动编程 |
| 抽取速度 | datax对于数据库压力比较小 | 小数据量的情况下差别不大,大数据量时datax比kettle快。 |
| 社区活跃度 | 阿里开源,社区活跃度低 | 开源软件,社区活跃度高 |
总结
- DataX和Kettle都是通用的数据集成工具,支持多种数据源和目标,提供了强大的数据转换和清洗功能。
- DataX和Kettle的区别在于开发者和用户群体,DataX在阿里巴巴内部得到广泛应用,而Kettle则是一个独立的开源项目。
- Sqoop主要用于Hadoop和关系型数据库之间的数据传输,适用于大规模数据的导入导出任务。

大数据从业者之家,一起探索大数据的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)