

本教程整理自我的 Github 仓库 pyflink_learn 的第 5 个案例。
业务场景
利用实时数据,在线训练一个机器学习模型,并实现对模型训练过程的实时监控。
本案例展示了如何用 PyFlink + Scikit-Learn 进行在线机器学习,以及提供实时的模型预测服务。
1、在线学习背景介绍
准确地说,在线学习并不是一种模型,而是一种模型的训练方法。 能够根据线上反馈数据,实时快速地进行模型调整,形成闭环的系统,同时也使得模型能够及时反映线上的变化,提高线上预测的准确率。
在线学习与离线学习,在数据的输入与利用上有明显的区别:
- 在线学习的训练数据是一条条(或者是 mini-batch 微批少量)进来的,不像离线学习时可以一次性加载大量的数据。
- 在线学习的数据只能被训练一次,过去了就不会再回来,不像离线学习可以反复地在数据集上训练模型。
很容易发现,对于在线学习,模型每次只能沿着少量数据产生的梯度方向进行下降,而非基于全局梯度进行下降,整个寻优过程变得随机,因此在线学习的效率并没有离线学习的高。但同时由于它每次参与训练的样本量很小,我们并不需要再用大内存、高性能的机器了,直接好处就是省钱呀。
对在线学习有兴趣的同学可以看一下这篇文章:在线学习(Online Learning)导读
2、实现逻辑详解

本案例相比于案例 4 要更复杂。这里稍微解释一下上面的数据流向图,以便于理解整个在线学习的流程。
在线学习项目,分为 3 个部分:
- 模型的训练 Online Learning :利用有标签的流式训练数据,来进行增量学习,不断地更新模型参数。
- 模型的监控 Model Monitor :在 UDF 里自定义监控指标,然后利用 Flink 的 Metric 机制,可以在自带的 WebUI 里实时查看。
- 模型的服务 Online Serving :在 UDF 里设定模型的加载与保存逻辑,并利用 Flask 加载 Redis 里的最新模型以提供服务。
下面拆开来介绍。
2.1、模型的训练
-
数据准备:利用kafka_producer.py脚本,读取 Scikit-Learn 提供的手写数字数据集 digits ,随机打乱后写到 Kafka 里,模拟线上【已经做了特征工程】的实时数据,等待流处理任务来消费。
{
"ts": "2020-01-01 01:01:01", # 当前时间
"x": [0, 1, 2, 16, ...], # 展平后的图像灰度数据,包含有 64 个整数的数组,整数的定义域为 [0, 16]
"actual_y": 1, # 真实标签
}-
数据读取:提交 PyFlink 作业后,Flink 利用连接器从 Kafka 里消费数据,强调一下本作业主要用于模型训练,不应该把特征工程耦合进来。 -
模型加载:UDF 在初始化的时候,会先从 Redis 里尝试加载预训练好的模型,如果 Redis 里不存在模型数据,则会初始化一个。 -
模型训练:每来一条数据,则会调用一次 UDF 的 eval 方法,方法内部会调用模型的partial_fit方法来训练,更新模型的参数。 -
模型预测:在 UDF 的 eval 方法里,完成本次的训练后,还会对训练用到的样本做个预测,预测结果一方面作为 UDF 的输出,写回到 Kafka ,另一方面用于计算相关的指标,以实时监控模型的效果。 -
模型备份:如果不对模型进行备份,那么模型只会在内存中,如果作业挂掉就前功尽弃了;在 UDF 中同样要设定模型的备份规则,我这里是 10 秒一次,备份到 Redis。
2.2、模型的监控
指标注册:在 UDF 的 open 方法里,对几个监控指标( Metric )进行注册。指标计算:在 UDF 的 eval 方法里,完成模型预测后,再计算之前定义的监控指标。指标收集:这一步是 Flink 自动完成的,Flink 会利用 Metric Reporter 收集指标到存储或分析系统。-
指标可视化:在 Flink Dashboard (http://localhost:8081 )可以看到指标的当前值和历史变化趋势,下面是我在案例中实现的其中 3 个指标。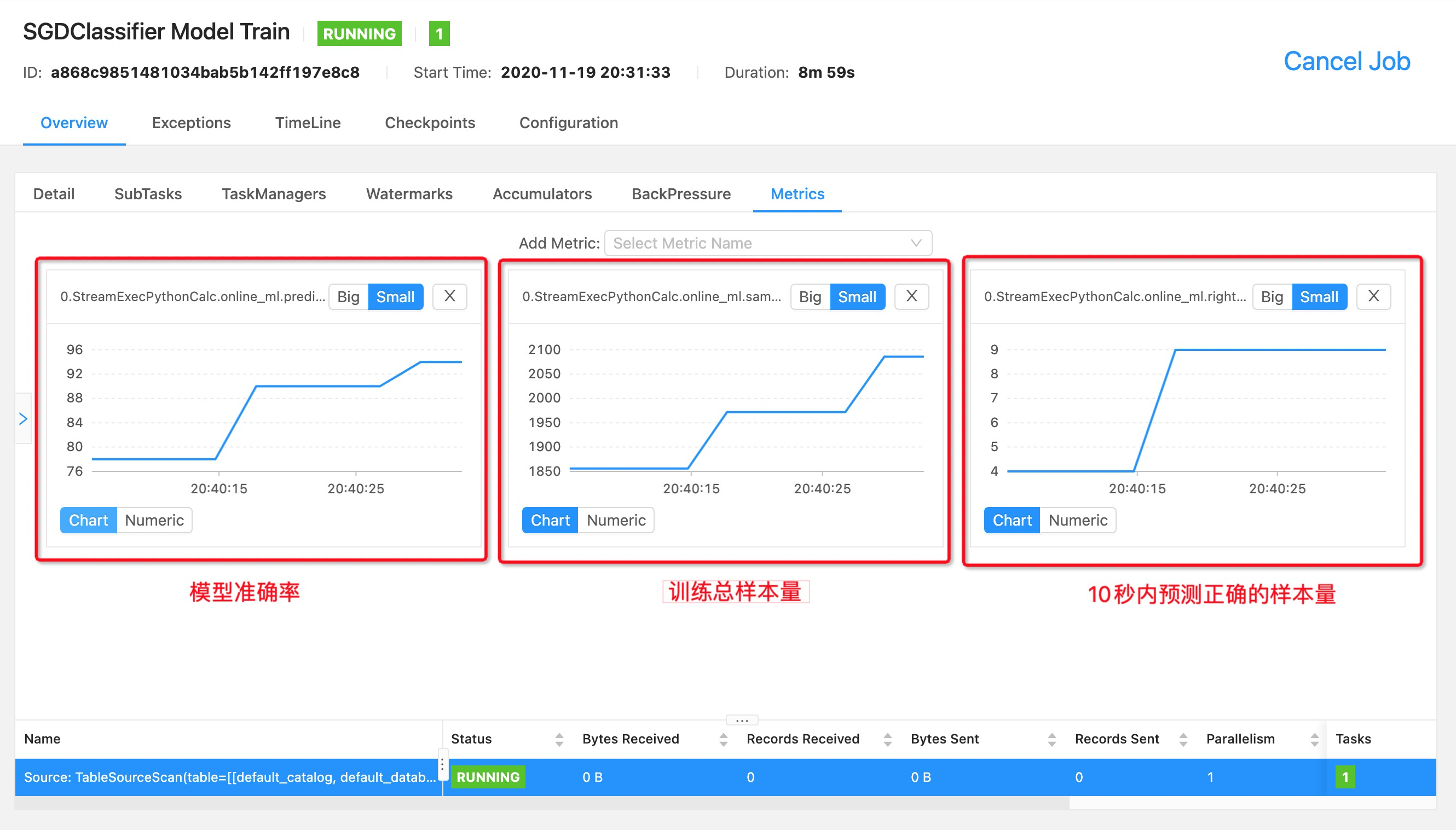
告警通知: 本案例里没有做,但在生产环境很重要,如果模型的某些指标出现了超过预期的异常,会影响到线上的预测服务,也就影响了用户体验。
2.3、模型的服务
-
Web框架:本案例基于 Flask 框架,实现网页的渲染和提供预测 API 服务,Flask 相比于 Django 更轻量也更易开发。运行model_server.py后打开主页 http://localhost:8066 。

-
模型加载:由于模型体积很小,因此无论是否有在实时训练,每次调用预测 API 时都会从 Redis 里动态加载最新的模型;实际线上运行时,需要异步地确认模型版本、异步地加载模型。 -
特征工程:线上传过来的手写数据是类型为image/svg+xml;base64的字符串,而模型需要的数据为 1 * 64 的灰度数组,因此需要做数据转换,这里就统称为特征工程,主要用到了PIL/Svglib/numpy等框架。 -
模型预测:数据处理完成后,直接喂给加载好的模型,调用模型的predict方法得到预测结果,再用 Flask 的 jsonify 函数序列化后返回给前端。
3、准备1:数据生成器
就像案例 4 一样,在运行脚本之前,我们先准备好数据和相关脚本。
首先,请保证基于 docker 运行的 kafka 服务是正常运行的,且映射到 localhost:9092 。
在 5_online_machine_learning 目录下的 kafka_producer.py 脚本,提供了数据模拟器的功能。
它会往 kafka 服务的 handwritten_digit 主题里,每秒写入 10 条 Scikit-Learn 的 digits 数据集里的样本,数据格式为 json 字符串,如下:
{
"ts": "2020-01-01 01:01:01", # 当前时间
"x": [0, 1, 2, 16, ...], # 展平后的图像灰度数据,包含有 64 个整数的数组,整数的定义域为 [0, 16]
"actual_y": 1, # 真实标签
}运行命令如下:
python kafka_producer.py4、准备2:模型预测服务
难道一定要等模型训练好了,我们才可以使用模型吗?NoNoNo,都 0202 年了,在线学习过程中的模型,也可以直接使用!
在流处理脚本 stream.py 中,我定义的 UDF 会每隔 10 秒往 Redis 里备份模型数据,我们可以把模型拿出来!
首先,请保证基于 docker 运行的 redis 服务是正常运行的,且映射到 localhost:6379 。
然后,预测服务需要做一些跟图像有关的预处理(把 base64 图片数据转为模型支持的矩阵),需要额外安装一些图形处理包,我把这些依赖整理在了案例目录下的 server_requirements.txt 文件内,pip 安装:
pip install -r server_requirements.txt最后,启动 Flask App :
python model_server.py打开网页 http://127.0.0.1:8066/,可以看到一个很简单的画板,我们在蓝框里使用鼠标来手写一个数字,再点击【预测】看看。
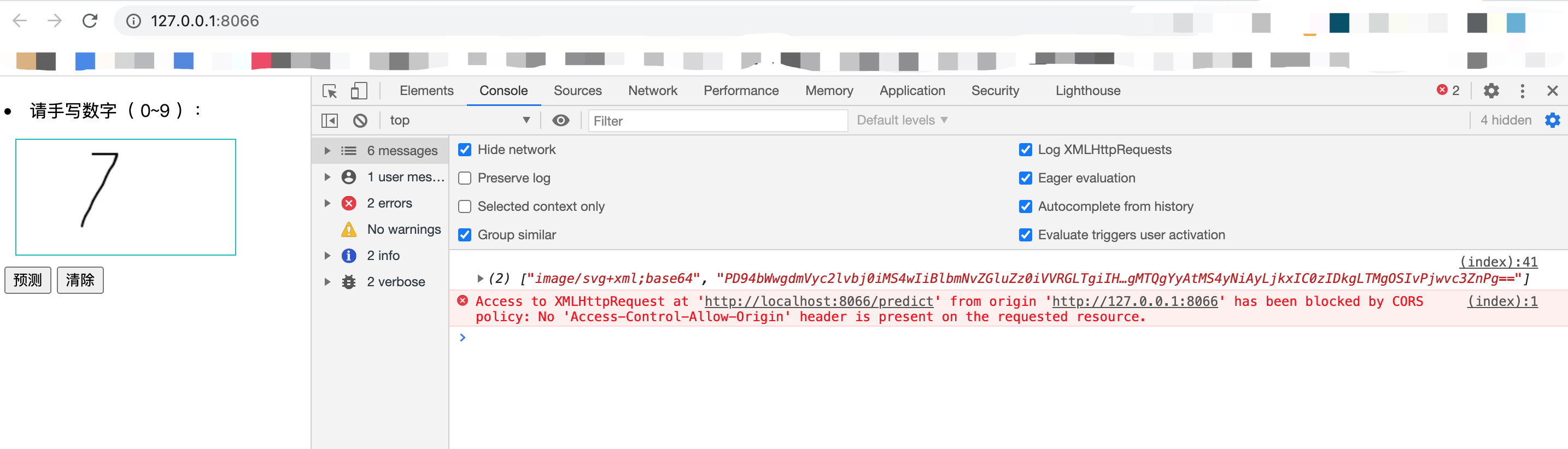
可以看到控制台的两条消息,一条是你手写数字的 base64 编码,另一条的报错是因为 Redis 没有启动,或者 Redis 里还没有任何模型数据。
别着急,接下来,让我们边训练模型,边在网页上查看模型的预测能力是怎么实时进化的吧!
5、运行
cd 到 examples/5_online_machine_learning 路径下,运行命令为:
flink run -m localhost:8081 -py stream.py运行之后,我们就可以在前面提供的 Web 应用 http://127.0.0.1:8066 里,手动地测试模型效果。
重新训练:
- 首先请在 WebUI 里关闭任务( 如果不知道怎么关闭,可参考 4.4、运行 ),防止模型持续地备份到 Redis。
- 然后清空 Redis 里的模型备份数据,防止模型被重新加载,我在本案例目录下准备了一个
redis_clear.py脚本,直接运行即可清空 Redis 。
# 如果在脚本后面传入多个 key,则会逐个删除 redis 里的这些 key
# python redis_clear.py aaa bbb ccc
python redis_clear.py6、模型监控
进入 WebUI http://localhost:8081,可以看到提交的名为 Classifier Model Train 的 Flink 作业,点击。
然后按下面的步骤,找到自定义的监控指标,自动生成监控报表。

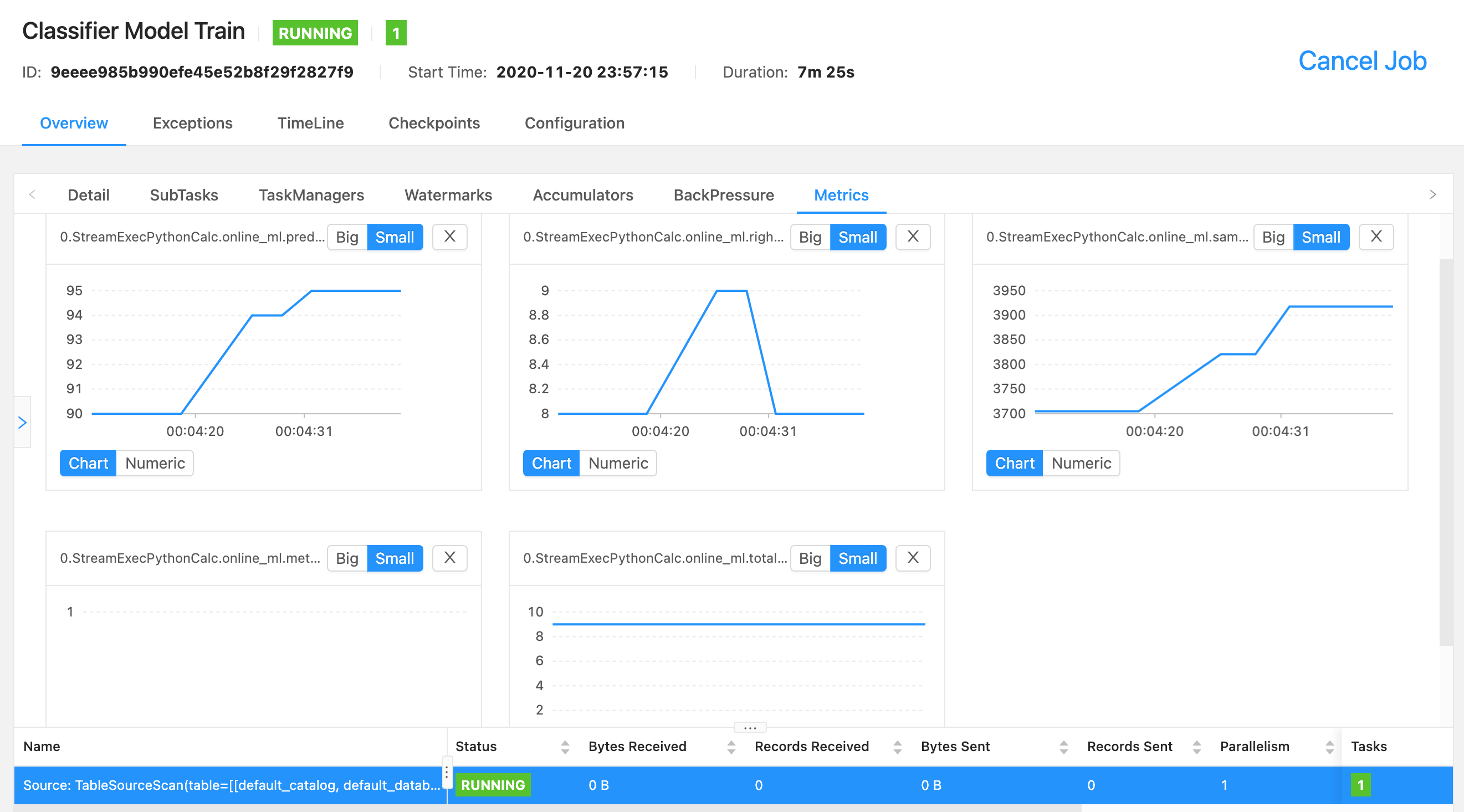
目前监控指标的可视化功能还在完善过程中,体验可能不是很好。我们也可以按照 官方文档 ,把指标交给应用很成熟的 Prometheus 来管理。
最后,总结一下,通过本案例,可以学到:
- 如何在 Flink UDF 中使用 Scikit-Learn 包
- 在 UDF 中连接 Redis,以加载模型和保存模型
- 在 UDF 中训练模型
- 在 UDF 中注册指标和计算指标
- 在 Web 页面上实时查看指标,了解算法的运行情况
- 开发 Flask 应用,并基于 Redis 里的最新模型提供预测服务。





 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)