




- @zzfive
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
vits官方gituhb项目--模型训练
Transformer-TTS
摘要: 聊天模板是用于结构化组织大模型对话数据的格式化规则,将用户、助手等角色信息通过特定标记(如特殊字符或Jinja模板)转换为模型训练时的统一输入格式。不同模型(如Alpaca、ChatML)的模板差异显著,例如使用[USER]或<|im_start|>等标记区分角色。模板不统一的原因包括研发团队的独立性、模型功能扩展(如多模态支持)的灵活性需求,以及避免硬性标准对创新的限制。尽管
wandb使用
DDPM将扩散模型在图片生成任务中做work后,大量研究人员开始对其进行迭代。虽然DDPM论文证明了扩散模型在图片生成任务中的潜力,但是其整体性能,特别是“有条件生成”,相较于当时的GAN系列模型还是存在差距,直到Openai的这篇论文出现,扩散模型在有条件图片生成任务上超过了GANs,而这篇论文对上篇论文中的核心思想进行优化,提高模型的性能和计算效率,该方法就是目前在扩散模型生成领域广泛使用的C
当前SOTA的音频驱动角色动画方法在语音和歌唱场景表现较好,但在影视制作所需的精细角色互动、真实肢体动作及动态镜头等复杂元素上存在不足;为此,研究团队提出基于Wan构建的音频驱动模型Wan-S2V,其在影视场景中的表现力和保真度显著优于现有方法,通过与Hunyuan-Avatar、Omnihuman等前沿模型的大量实验对比,结果一致证明该模型性能更优,同时还探索了其在长视频生成和精准视频唇同步编辑
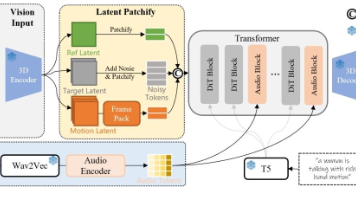
Ovi采用对称双主干网络设计,其音频分支与视频分支并行构建,且二者均基于完全相同的DiT架构。其中,视频分支由Wan2.2 5B模型初始化,而结构完全一致的音频分支则采用从头训练。因此,两个主干网络拥有相同数量的Transformer块、注意力头、注意力头维度以及前馈网络,实现了每一层级的对称性,具体细节如表 1 所示。表1 Ovi双主干网络的Transformer超参数每个Transformer
问答技术--IRQA
wandb使用