




- @zyun360
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
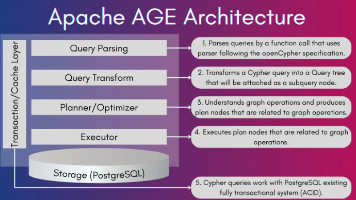
PostgreSQL 擅长事务型数据管理。Apache AGE 通过扩展方式将图数据库能力引入 PostgreSQL,使其在保持原有稳定性与生态优势的同时,补齐了图数据建模与查询能力的短板。这种“关系型数据库 + 图模型”的融合架构,为需要同时处理强事务与复杂关系的数据场景提供了一种务实且高性价比的技术路径。
专业用户再也不怕通用模型不懂业务术语了!TLP开放模型自定义能力——不再是被动的标注工具使用者,而是标注AI的共建者。用户可以引入热门的开源模型,可自己训练模型并应用到标注中。不同的项目可独立维护专属标注模型,灵活切换、按需部署,真正打造贴合企业场景的“专属AI标注大脑”。四. 为什么选择天纪标注平台TLP需求维度TLP产品能力效率AI预标+人工精修,70%+效率提升;支持标注规则自动生成、快捷键
在鸿蒙APP的开发中,音视频能力作为核心交互载体,其应用场景深度融入各行各业的数字化进程,成为连接用户、场景与服务的关键纽带,如实时互动、远程协作、短视频/自媒体、电商直播带货等场景都需要音视频的采集或播放等能力。
而在这一变革背后,“API市场的模型"正作为隐形的"超级引擎”,以前所未有的速度重塑AI客服场景,为企业打造极致的客户体验。360智汇云是企业智数云底座,以“智-数-云”三大核心底座为支柱,以贯穿全程的 “观测与管控” 为神经中枢,全链路赋能企业数智基建在 “用、运、管、看、维” 五维生命周期中实现价值闭环。过去的客服机器人往往只能进行机械的关键词匹配,而接入API市场中的大模型后,AI客服具备了
AIMI 不是替代 IM,而是补齐业务化能力IM 和 AIMI 的定位并不冲突。IM 适合轻量沟通、个人使用和即时问答;AIMI 适合业务嵌入、过程展示、会话管理、数据观测和多智能体编排。当龙虾只是一个个人助手时,IM 已经很好。当龙虾要进入业务页面、参与业务流程、服务真实用户、支撑后台运营时,就需要 AIMI 这样的智能体对话平台。龙虾让智能体有了能力,IM 让用户可以快速聊起来,而 AIMI
指标语义层让AI会查数,本体化语义层让AI开始理解业务。Skill将领域认知编码为可执行方法论,但若没有本体化语义层作为统一的事实基座,Skill体系迟早会陷入"口径分散、规则重复、知识不可复用"的维护黑洞。从Skill到本体语义层,不是换一个更高级的词,而是让Agent从"能干活"走向"值得信赖"。
指标语义层让AI会查数,本体化语义层让AI开始理解业务。Skill将领域认知编码为可执行方法论,但若没有本体化语义层作为统一的事实基座,Skill体系迟早会陷入"口径分散、规则重复、知识不可复用"的维护黑洞。从Skill到本体语义层,不是换一个更高级的词,而是让Agent从"能干活"走向"值得信赖"。
比如"销售额"到底怎么定义?退货/退款是否要扣除?赠品、小样算不算?零售电商场景下,优惠券、消费券的抵扣算不算销售额?这些问题本质上是业务口径问题,但大模型并不知道企业内部的统一口径。数仓设计的data agent架构设计是:NL → 关键词提取 → ES/向量化检索 → LLM生成MQL → 规则后处理 → 校验 → 编译SQL → 执行 → 解释。多层防护(规则+LLM+验证+回环)为此,我们
想要实现一个“语音输入+大模型处理+图像生成”的功能,可能需要企业去走三家不同平台的采购与注册流程,研发人员要研读多套不同的API文档,处理各自迥异的鉴权机制。所有的API都采用了标准化的协议封装。但在实际开发中,无论是负责创新原型的单个员工,还是讲究协同的研发团队,在接入多模态功能时都会遇到一个共同的问题:为了给项目加上文本、语音、图像等能力,往往需要在多个服务商平台之间频繁切换。无论你是想快速

PD分离(Prefill-Decode Disaggregation)正是为解决这一痛点而生的架构理念:它将Prefill和Decode两个阶段物理分离到不同的硬件资源池,让专业设备做专业的事。用一个生活化的类比:传统的混合部署就像让一个人同时当厨师和服务员——他做菜的时候无法接待客人,接待客人的时候厨房只能闲置。而PD分离就是让专职厨师专注做菜,专职服务员专注上菜,各司其职,效率倍增。