




- @zuodaoyong
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
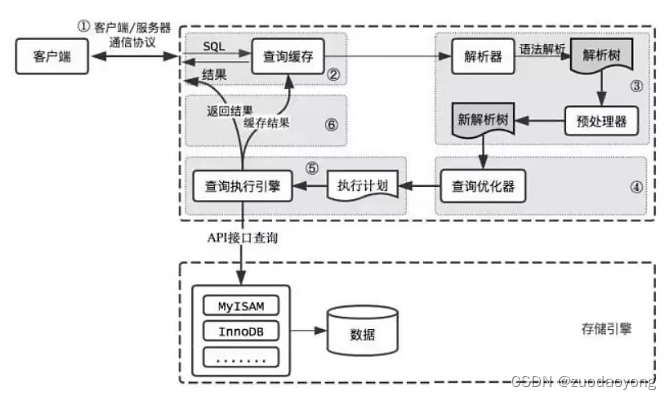
既然是缓存,缓存失效也要考虑,MYSQL的缓存系统会检测涉及到的每张表,只要该表的结构或者数据被修改,出现如下操作(insert,update,delete,truncat table,alter table,drop table,drop database等)时所有缓存查询将变为无效,对于更新压力大的数据库来说,查询缓存命中率更低。key是查询语句,value是查询的结果,如果查询能够直接在缓存
1、自动创建如果kafka broker中的config/server.properties配置文件中配置了auto.create.topics.enable参数为true(默认值就是true),那么当生产者向一个尚未创建的topic发送消息时,会自动创建一个num.partitions(默认值为1)个分区和default.replication.factor(默认值为1)个副本的对应to...
在上一篇match query讨论了全文检索比如,有如下查询{"match": {"content": "java spark"}}match query,只能搜索到包含java和spark的document,但是不知道java和spark是不是离的很近。如果希望搜索java spark,中间不能插入任何其他的字符,那这个时候match去做全文检索是无法做到的,此时需要使用match_phrase
InnoDB存储引擎是以页为单位来管理空间的,我们进行的增删改查操作其实本质都是在访问页面(读页面,写页面,创建新页面)等,磁盘IO需要消耗的时间很多,而在内存中进行操作,效率会高,为了能让数据表或者索引中的数据随时被使用,DBMS会申请占用内存来作为数据缓冲池,在真正访问页面之前,需要把磁盘上的页缓存到内存中的buffer pool中之后才可以访问。这样做的好处可以让磁盘活动量最小,从而减少与磁

如果在缓存中不存在已经加载的单例Bean,就需要从头开始bean的加载过程。Spring中使用getSingleton的重载方法实现bean的加载过程。public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(beanName, "Bean name mu
在java中数据类型分为基本数据类型和引用数据类型。基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载。按照java虚拟机规范,从class文件到加载进入内存中的类,再到类卸载出内存为止,整个生命周期如下一、加载将java类的字节码文件加载到机器内存中,并在内存中构建出java类的原型(类模板对象)1、加载类时,java虚拟机加载步骤(1)通过类的全名,获取类的二进制数据流(2)解析类的
在java中数据类型分为基本数据类型和引用数据类型。基本数据类型由虚拟机预先定义,引用数据类型则需要进行类的加载。按照java虚拟机规范,从class文件到加载进入内存中的类,再到类卸载出内存为止,整个生命周期如下一、加载将java类的字节码文件加载到机器内存中,并在内存中构建出java类的原型(类模板对象)1、加载类时,java虚拟机加载步骤(1)通过类的全名,获取类的二进制数据流(2)解析类的