




- @zishuijing_dd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenClaw标志着人工智能从“对话式交互”迈入“自主行动”的第三阶段,是一个“本地优先、隐私至上、多渠道集成”的自托管AI助手平台。以ReAct循环为执行范式,以解耦的“大脑+躯干”为架构基础,以丰富的技能插件为执行手段,以多层次的记忆系统为上下文支撑。通过极低的部署门槛,OpenClaw正在推动自主Agent的平民化,让用户仅凭自然语言就能实现轻量化自动化工作(如文件整理、日程管理、跨工具协
LightRAG是***大学开发的轻量级检索增强生成框架,通过结合知识图谱和向量检索技术优化传统RAG系统。其核心流程包括实体关系提取、图基文本索引、双层检索和答案生成
sklearn库是用于机器学习一个工具包,有了它,可以帮我们用简单的函数实现传统机器学习中的分类、聚类等任务。

国内从官网下载ollama经常遇到下载不下来,或者卡住的问题,今天给大家分享解决这个问题的方法。

OpenClaw标志着人工智能从“对话式交互”迈入“自主行动”的第三阶段,是一个“本地优先、隐私至上、多渠道集成”的自托管AI助手平台。以ReAct循环为执行范式,以解耦的“大脑+躯干”为架构基础,以丰富的技能插件为执行手段,以多层次的记忆系统为上下文支撑。通过极低的部署门槛,OpenClaw正在推动自主Agent的平民化,让用户仅凭自然语言就能实现轻量化自动化工作(如文件整理、日程管理、跨工具协
浅谈,作为一个黑盒,上亿参数的大语言模型究竟能否有解释性

大型语言模型的幻觉、偏见等问题,简介解决方案

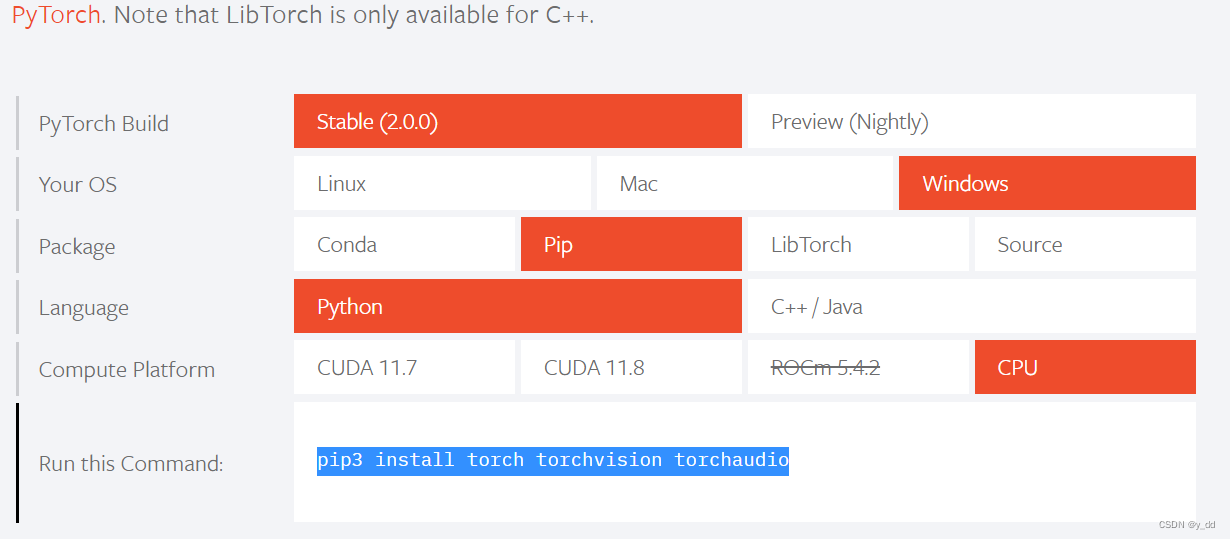
可以修改whi文件名安装即可。(有些64系统尾缀为win32,实际指的是win32接口,实质还是64位,总之修改成符合当前要求的命名规则的whl即可)ps:python版本3.11 ,3.7版本安装时,遇到了如下报错osError找不到asmjit.dll的报错,升级3.11即可。从这里下载 https://download.pytorch.org/whl/torch_stable.html。无G
OpenClaw标志着人工智能从“对话式交互”迈入“自主行动”的第三阶段,是一个“本地优先、隐私至上、多渠道集成”的自托管AI助手平台。以ReAct循环为执行范式,以解耦的“大脑+躯干”为架构基础,以丰富的技能插件为执行手段,以多层次的记忆系统为上下文支撑。通过极低的部署门槛,OpenClaw正在推动自主Agent的平民化,让用户仅凭自然语言就能实现轻量化自动化工作(如文件整理、日程管理、跨工具协
本章用sklearn库进行代码实战一下,实现无监督学习的聚类。
