




- @zhangjin1222
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了在信创环境下使用瀚高数据库的实践方法。作者详细演示了通过Docker安装瀚高数据库的全过程,包括镜像加载、容器启动和数据库创建。文章重点讲解了如何将瀚高数据库与Kettle工具集成,包括插件安装、驱动程序配置、转换设计等关键步骤,并展示了将瀚高数据库作为Kettle资源仓库的具体实现方法。该教程为Java开发者在国产数据库环境下的数据集成工作提供了实用指导。
《Kettle团队协作解决方案:xkg-pdi数据库资源库实战》 本文由Java资深工程师分享Kettle团队协作的解决方案。详细介绍了使用xkg-pdi管理Kettle脚本的完整流程:从创建数据库资源仓库、设计trans脚本,到配置资源库、拉取脚本、作业调度和日志监控。重点演示了如何通过数据库资源仓库实现团队协作,包括脚本共享、任务调度和节点执行监控。文章还预告了后续将介绍基于Git的团队协作方
摘要:Java小金刚分享使用PDI(Kettle)连接达梦数据库的经验。测试发现Kettle 9.2能正常连接达梦资源库,但9.4版本登录失败。通过使用DmJdbcDriver18.jar驱动和自研达梦插件,成功创建46张资源库表(关键数量)。特别提醒:Kettle 9.3版本存在兼容性问题,可能导致只生成25张表而无法使用。建议使用9.2/9.4/9.5版本,并注意插件配置细节(如资源库描述避免
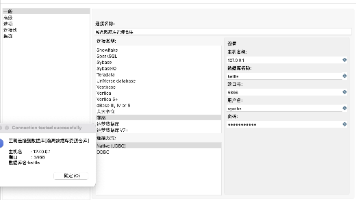
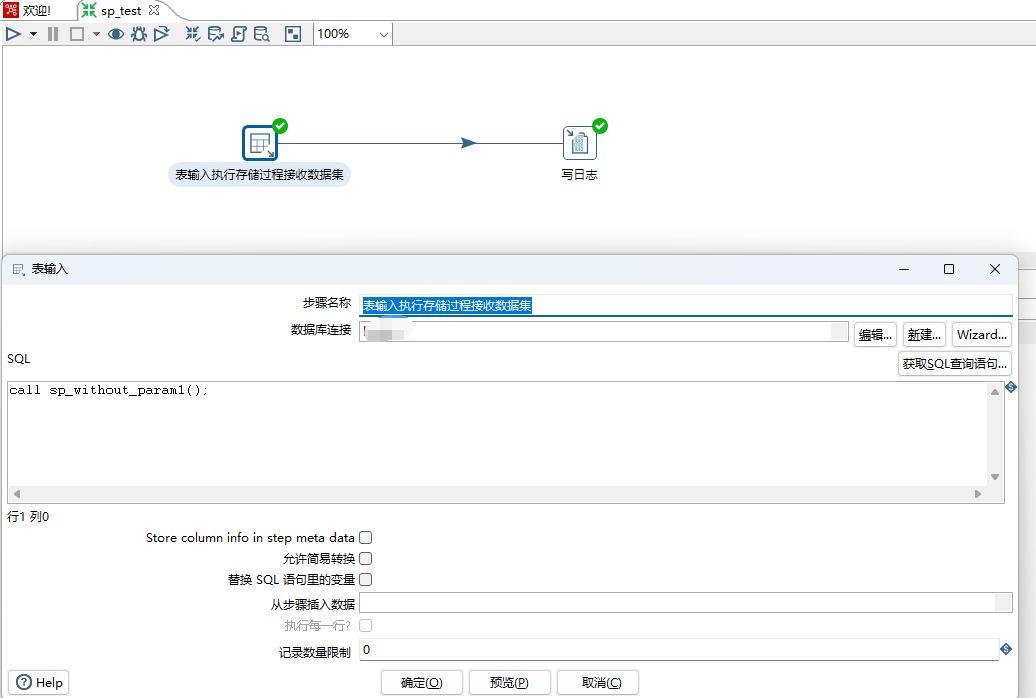
场景:kettle调用存储过程,存储过程中通过select * from table 方式返回结果集,kettle接收结果集。2、创建一个只有入参的存储过程,脚本中通过select * from t1 where id=pId;表输入步骤sql填写call sp_without_param2("1"),保存&点击运行按钮,数据集正常打印。使用表输入步骤单独获取out参数,sql为select @o
本文介绍了DataX-Web的安装部署流程:1)下载源码并编译生成管理端、执行器和完整部署包;2)部署需准备MySQL数据库,执行初始化SQL脚本;3)配置application.yml后启动datax-admin服务(默认端口8080,账号admin/123456);4)配置执行器参数后启动datax-executor服务完成注册。文中指出原启动脚本仅支持Linux,建议将项目改造为Spring
《Kettle团队协作解决方案:xkg-pdi数据库资源库实战》 本文由Java资深工程师分享Kettle团队协作的解决方案。详细介绍了使用xkg-pdi管理Kettle脚本的完整流程:从创建数据库资源仓库、设计trans脚本,到配置资源库、拉取脚本、作业调度和日志监控。重点演示了如何通过数据库资源仓库实现团队协作,包括脚本共享、任务调度和节点执行监控。文章还预告了后续将介绍基于Git的团队协作方
【Java小金刚分享Kettle Docker镜像部署方案】文章详细介绍了基于CentOS7构建Kettle9.4镜像的全过程:1)通过Dockerfile配置JDK8、SSH及Kettle环境;2)包含镜像构建命令和双服务启动示例;3)提供SSH登录排错指南;4)说明Carte服务访问方式。作者表示已完成镜像制作,并将共享至专业群供开发者使用。该方案适合需要快速部署Kettle服务的开发团队参考
摘要:本文介绍了在信创环境下使用瀚高数据库的实践方法。作者详细演示了通过Docker安装瀚高数据库的全过程,包括镜像加载、容器启动和数据库创建。文章重点讲解了如何将瀚高数据库与Kettle工具集成,包括插件安装、驱动程序配置、转换设计等关键步骤,并展示了将瀚高数据库作为Kettle资源仓库的具体实现方法。该教程为Java开发者在国产数据库环境下的数据集成工作提供了实用指导。
《Java小金刚分享WebSpoon部署方案》摘要:拥有10年互金行业经验的Java技术专家分享两种WebSpoon部署方案。1)Docker部署:提供现成镜像文件,解决网络下载问题,特别适合跨平台需求;2)Tomcat免配置版:预打包解决常见问题如汉化失败等,提供完整启动指南。作者指出WebSpoon9.0存在稳定性问题,建议优先使用Docker方式,并分享了MySQL8连接技巧及插件适配经验。
摘要:Java小金刚分享使用PDI(Kettle)连接达梦数据库的经验。测试发现Kettle 9.2能正常连接达梦资源库,但9.4版本登录失败。通过使用DmJdbcDriver18.jar驱动和自研达梦插件,成功创建46张资源库表(关键数量)。特别提醒:Kettle 9.3版本存在兼容性问题,可能导致只生成25张表而无法使用。建议使用9.2/9.4/9.5版本,并注意插件配置细节(如资源库描述避免