




- @zephyr_wang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Drain是一个在线实时日志解析方法,其采用的是固定长度的树模型
1.介绍1.1.介绍在论文《NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING》中首次提出了NAS(神经网络架构搜索NEURAL ARCHITECTURE SEARCH),本文首先翻译总结了下此篇内容。接着根据《Efficient Neural Architecture Search via Parameter Sharing》写了EN..
强化学习分类与汇总介绍
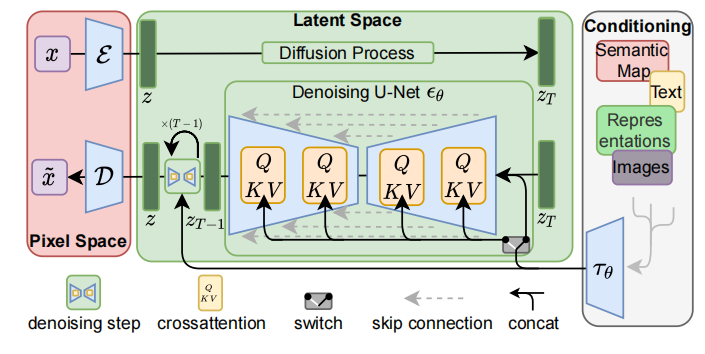
我们模型latent diffusion models (LDMs)是两阶段的。第一部分就是下面左半部分(红色),对图片进行压缩,将图片压缩为隐变量表示(latent),这样可以减少计算复杂度;第二部分还是扩散模型(diffusion与denoising),中间绿色部分。此外引入了cross-attention机制,下图右半部分,方便文本或者图片草稿图等对扩散模型进行施加影响,从而生成我们想要的图
1 简介本文根据2019年《ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks》翻译总结的。主要是同时处理视觉和文本输入,多模态模型。ViLBERT ( Vision-and-Language BERT),我们将流行的BERT模型扩展到多模双流模型,首先以分
语音识别预训练模型Hidden-Unit BERT (HuBERT)
1 简介本文根据2020年《Self-training with Noisy Student improves ImageNet classification》翻译总结。自训练(Self-training)使用标注数据训练一个好的teacher模型,然后使用该teacher模型对未标注的数据进行标注,最后使用标注数据和非标注数据联合训练一个student模型。如下图所示。本文提出的Noisy St
1.6FacenetFacenet主要是采用的欧几里得距离(欧式距离)来衡量两张图片或者两张人脸的相似度,欧式距离越小代表图片越相似,欧式距离越大,代表图片越不相似。所以先将一副图片x,采用函数f(x)将其变成128维的embedding(embedding:多维数组来表示不同的类别),然后计算embedding之间的距离。在比较embedding的欧式距离时,将图片的欧式距离与真的(pos...
1 简介GPT先是非监督的预训练,然后进行监督训练微调。而GPT-2,是想只需要非监督训练即可,不用再监督训练。本文根据2019《Language Models are Unsupervised Multitask Learners》翻译总结。从标题就可以看出来,作者尝试只使用非监督学习。监督学习是脆弱、敏感的,比如当数据分布稍微改变,或者只针对的某个特定任务。我们本文描述语言模型可以不需要任何监