- @yjh_SE007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSpeed Zero-3的核心功能就是在显存不足的情况下,使用CPU内存。
manus:Peak在 Manus 项目伊始,我和团队就面临一个关键抉择:是利用开源基础模型训练一个端到端的智能体,还是依托前沿模型的上下文学习能力,在其之上构建智能体?在我投身 NLP 的第一个十年里,我们并没有这种奢侈的选择。遥想当年 BERT 问世(没错,那已是七年前),模型必须先经过微调——还要评估——才能迁移到新任务。每次迭代往往耗时数周,尽管那时的模型体积与今日的 LLMs 相比微不足
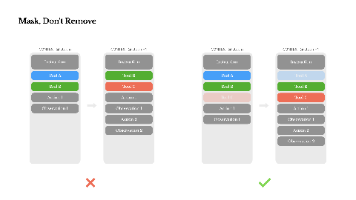
VLMs 性能的持续提升,视觉 token 的消耗呈指数级增长。例如,一张 2048× 1024的智能手机照片在 LLaVA 1.5中需要 576 个视觉 token,而在 Qwen2.5-VL中则需2678 个视觉 token。因此,避免过度使用视觉 token 显得尤为重要。大多数方法使用预定的Threshold 来修剪或合并固定数量的视觉 Token。然而,不同问题和图像中的冗余程度各不相同
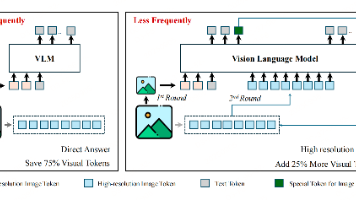
多模态大模型在推理上虽然效果好,但会强制执行 “逐步思考” 流程,导致输出 token 量激增,冗余思考过程不会提升简单任务的准确性,反而可能因 “过度推理” 引入噪声。现有模型无法根据任务复杂度自主选择 “思考模式”(需推理)或 “非思考模式”(直接回答),需要手动触发是否思考的条件(如qwen3的开关控制)或者如Keye-VL 通过人工标注 “任务复杂度标签” 触发思考模式,但人工标注成本高、
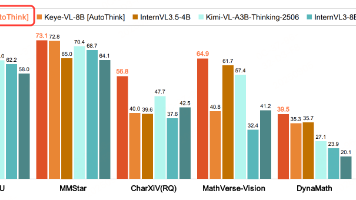
标题一次,非Qwen3-VL-0.6B官方。最近手里有一台昇腾910B的服务器,顺便摸索下国产芯片的训练都有哪些坑,笔者时隔一年对Reyes《》进行了改造,原本的Reyes由8B的参数构成(InternViT-300M-448px-V2_5+Qwen2.5-7B-Instruct),随着端侧模型的发展与手里资源的限制,最终笔者将Reyes参数量设置成0.6B,训练了一个轻量化的多模态模型,最终在M
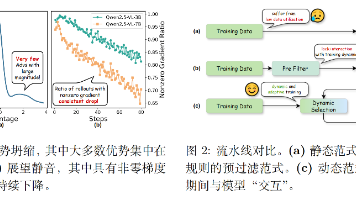
LLM/MLLM RL微调的时大概率都踩过这个致命的坑:90%的GPU算力都花在了rollout采样上,可模型精度就是纹丝不动;训到后期看梯度,几乎全是接近0的无效值,烧了算力,全做了无用功。没有卷更复杂的策略梯度算法,也没有堆更花哨的奖励函数设计,而是回归「数据」这个最本质的问题,用一套简单的方案提升RL训练效率。
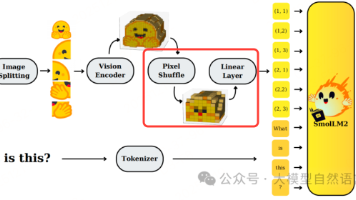
继续跟进【】解析进展。在前期专栏中总结过,文档解析范式分三个:(1)基于ocr-pipeline;(2)基于layout+vlm的两阶段;(3)基于vlm端到端;Qianfan-OCR是一个4B参数量的端到端的多模态文档解析模型,,其方法体系围绕四大核心展开,下面来看看方案。
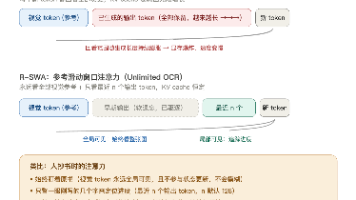
这次介绍的技术方案架构是站在前期《》所介绍的DeepSeek-OCR的改进,主要引入了【R-SWA(Reference Sliding Window Attention,参考滑动窗口注意力)】。下面来具体看看。
在大模型的生成过程中,部分原生的大语言模型未经过特殊的对齐训练,往往会“胡说八道”的生成一些敏感词语等用户不想生成的词语,最简单粗暴的方式就是在大模型生成的文本之后,添加敏感词库等规则手段进行敏感词过滤,但是在生成过程中,生成敏感词仍然耗费了时间和算力成本。本文以chatglm2-6B为例,通过自定义,实践大模型在生成过程中控制一些词语的生成。回到正题,如何自定义LogitsProcessor控制
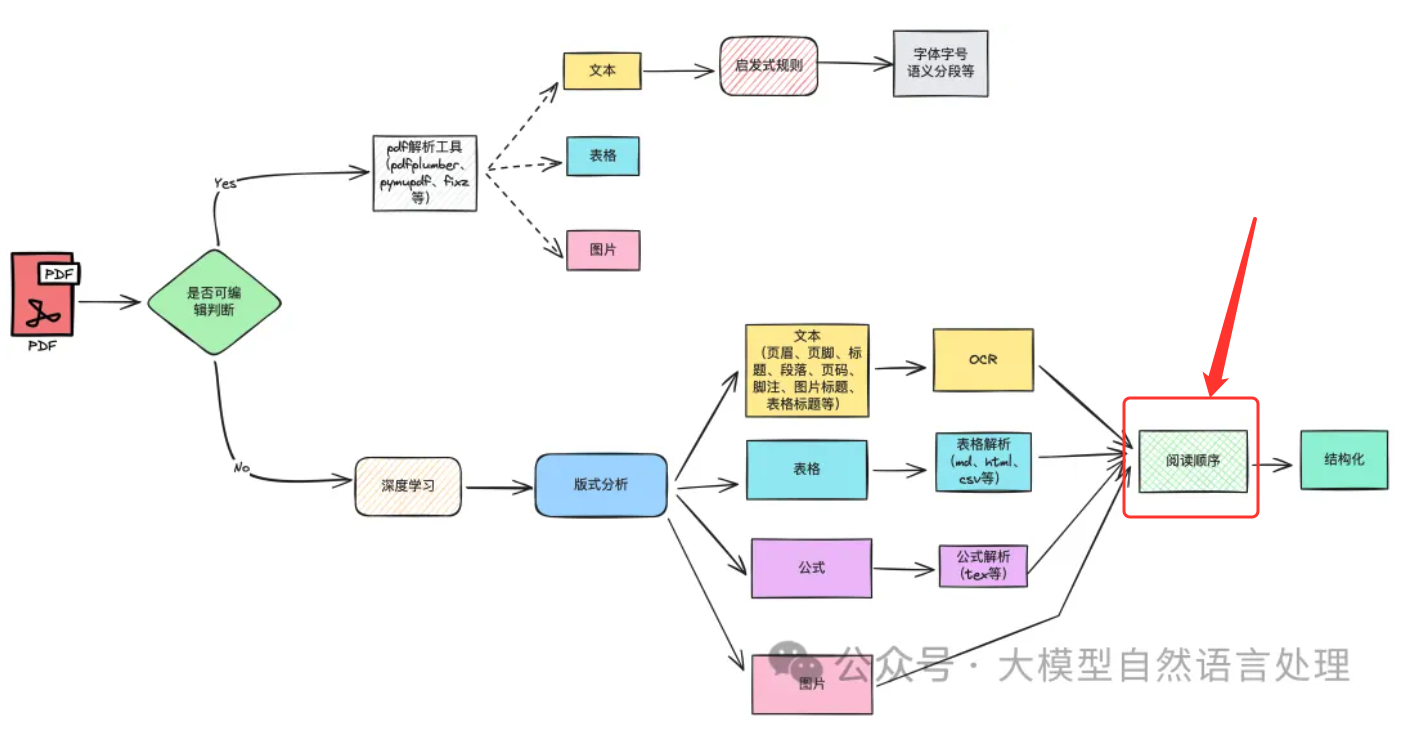
阅读顺序检测旨在捕获人类读者能够自然理解的单词序列。现有的OCR引擎通常按照从上到下、从左到右的方式排列识别到的文本行,但这并不适用于某些文档类型,如多栏模板、表格等。LayoutReader模型使用seq2seq模型捕获文本和布局信息,用于阅读顺序预测,在实验中表现出色,并显著提高了开源和商业OCR引擎在文本行排序方面的表现。详细代码已上传:https://github.com/yujunhui