




- @yilvqingtai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ACT_RU_TASK简介:运行时任务节点表详细说明:操作数据库的act_ru_execution表,如果是用户任务节点,同时也会在act_ru_task添加一条记录对于执行完的任务,activiti将从act_ru_task表中删除该任务,下一个任务会被插入进来。表结构:mysql>5定义字段字段名称字段描述数据类型主键为空取值说明ID_ID_varchar(64)√...
ACT_RU_JOB简介:运行时定时任务数据表详细说明:定时任务都存储在act_ru_job表中,时间到了就会执行表结构:mysql>5定义字段字段名称字段描述数据类型主键为空取值说明ID_ID_varchar(64)√ID_REV_乐观锁int√乐观锁PROC_INST_ID_流程实例IDvarchar(...
ACT_HI_ACTINST简介:历史节点表详细说明:存放历史所有完成的活动 ,查询历史流程实例表结构:mysql>5定义字段字段名称字段描述数据类型主键为空取值说明ID_ID_varchar(64)√PROC_DEF_ID_流程定义IDvarchar(64)PROC_INST_ID_流程实例IDva...
ACT_HI_VARINST简介:历史变量表详细说明:里会记录详细记录流程中的每个变量,包括他的名字、类型,值是多少、什么时候创建的,什么时候更新的;不管是流程启动的时候传入的变量,还是表单中的字段等。表结构:mysql>5定义字段字段名称字段描述数据类型主键为空取值说明ID_ID_varchar(64)√ID_PROC_INST_ID_流程实例IDva..
本文探讨了企业级Ollama模型服务的性能评估方法。文章首先介绍了企业级应用需要考虑的响应速度、稳定性等关键指标,并对比了Ollama的两种启动方式:手动启动(ollamaserve)适合调试,而systemd服务管理更适合生产环境。重点阐述了压力测试方案,包括测试指标设定、环境配置和代码参数说明,通过REST API接口模拟真实场景,评估系统吞吐量和并发能力。测试结果显示,在4张NVIDIA A

高效的大型语言模型推理和部署框架,由加州大学伯克利分校开发,采用 Apache 2.0 许可,以 Python/PyTorch 为基础,优化了显存管理与批处理。基于PagedAttention技术的高吞吐推理框架,在NVIDIA/AMD GPU集群上展现卓越性能,支持多节点张量并行。百万并发不是梦!GPU榨干指南# 创建专用环境 conda create -n vllm python=3.12 -
keep_alive 在工程化的项目中,往往需要根据请求的频率来设置,如果请求不频繁,可以使用默认值或较短的时间,以便在不使用时释放内存。而如果应用程序需要频繁调用模型,可以设置较长的keep_alive 时间,以减少加载时间。很关键,非常影响服务器的性能和应用程序的用户体验。大家一定要注意。

openwebui+deepseek+comfyUI搭建文生图效果
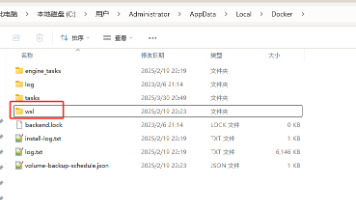
Windows下Docker虚拟机文件迁移到D盘方法 首先关闭WSL:wsl --shutdown 查看当前安装的WSL系统:wsl --list -v 备份Docker虚拟文件到D盘: wsl --export docker-desktop D:\DockerData\docker-desktop.tar wsl --export docker-desktop-data D:\DockerDat
GitHub Container Registry 是 GitHub 提供的容器镜像注册表服务,允许开发者在 GitHub 上存储、管理和分享 Docker 镜像。它与 GitHub 代码仓库紧密集成,可以使用相同的权限管理、团队协作和版本控制工具来管理容器镜像。通过 GitHub Container Registry,开发者可以方便地将他们的容器镜像与代码仓库关联起来,这样就可以在同一个平台上管
