- @yd778473278
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
KeSpeech数据集覆盖普通话及北京、西南、中原、东北、兰银、江淮、冀鲁、胶辽宫8 种方言。在开源 ASR 模型测试中,中文以字错误率(CER)为指标,FireRedASR 表现最优,总 CER 仅 4.7511,显著优于其他模型;Qwen2-Audio、Paraformer、Dolphin 性能相近,总 WER 在 11-13 区间;Whisper 与 PaddleSpeech 表现较弱,总

vLLM最新版(V0.6.1.post1)beam search方式的使用教程,介绍BeamSearchParams,BeamSearchOutput,BeamSearchSequence,并给出sampling和beam search的示例程序
LLaMa-Factory环境搭建与运行示例

本文对比了豆包和讯飞两大实时语音转写大模型API,从准确率、功能、费用等方面进行分析。测试结果显示豆包准确率最高(4.8分),支持中英+5种方言,价格2.4-4元/小时,企业用户享有20小时免费时长;讯飞支持更多方言但准确率较低(1分),价格2-4.95元/小时。功能上讯飞支持角色分离和16个领域,豆包不支持。综合推荐豆包API,其流式异步模式识别效果稳定,更适合企业应用场景。
本文介绍 vLLM v0.10.2 版本通过 Docker 运行 OpenAI 服务及 GGUF 量化的使用方式,明确该量化不支持多模态模型,且仅节约显存、不提升速度。GGUF 量化需要 llama.cpp 环境,接着将 Hugging Face 模型转为 FP16 格式 GGUF,再量化为 Q4_0 等类型(文中列多种支持的量化类型),最后通过 Docker 启动量化后的模型,同样提供了测试请求
Google Stitch是由Google实验室开发的AI原生设计工具,旨在简化UI设计流程。它通过自然语言输入快速生成高保真网页或移动应用界面,并支持导出可交互原型和生产级代码。核心功能包括AI原生无限画布、多模态输入、智能设计助手、一键生成原型与代码,以及自动设计系统管理。Stitch适合产品经理、开发者、创业者等非设计专业人士快速验证想法,也为设计师提供高效初稿生成工具。目前完全免费,用户只

Google Stitch是由Google实验室开发的AI原生设计工具,旨在简化UI设计流程。它通过自然语言输入快速生成高保真网页或移动应用界面,并支持导出可交互原型和生产级代码。核心功能包括AI原生无限画布、多模态输入、智能设计助手、一键生成原型与代码,以及自动设计系统管理。Stitch适合产品经理、开发者、创业者等非设计专业人士快速验证想法,也为设计师提供高效初稿生成工具。目前完全免费,用户只
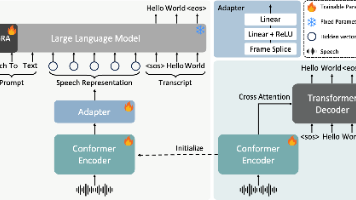
FireRedASR-AED是一款高性能开源中文语音识别模型,采用Conformer编码器和Transformer解码器的混合架构。其编码器通过下采样模块和16个Conformer块处理语音特征,结合多头自注意力与相对位置编码;解码器使用标准Transformer结构实现序列转换。该模型在普通话ASR基准测试中达到SOTA水平,同时支持方言和英语识别,兼具计算效率与识别性能优势,适合工业级应用。相
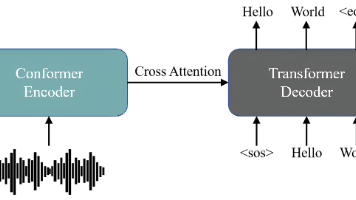
FireRedASR是一个开源工业级自动语音识别模型家族,支持多种语言和方言。其中FireRedASR-AED模型采用注意力编码器-解码器架构,在中文ASR基准测试中达到SOTA水平。项目对原始模型进行了ONNX转换和优化,通过实现完整的Beam Search缓存机制,显著提升了CPU推理速度(提升38.7%),同时保持识别准确率。优化后的模型在AISHELL-1测试集上CER为0.5527%,推
FireRedASR2S是一款先进的工业级一体化语音识别系统,整合了语音识别(ASR)、语音活动检测(VAD)、语种识别(LID)和标点预测(Punc)功能。该系统在多项测试中表现优异:ASR模块支持中文(含20+方言)、英语及混语识别,普通话平均错误率2.89%;VAD模块支持100+语言检测,F1分数达97.57%;LID模块准确率97.18%;Punc模块平均F1分数78.90%。提供LLM