




- @xziyuan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2023 年 12 月 06 日12 分钟阅读让人工智能为每个人提供更多帮助谷歌和 Alphabet 首席执行官谷歌 DeepMind 首席执行官兼联合创始人由谷歌 DeepMind 首席执行官兼联合创始人 Demis Hassabis 代表 Gemini 团队撰写和我的许多研究同事一样,人工智能一直是我毕生工作的重点。自从少年时代为电脑游戏编写人工智能程序,以及多年来作为神经科学研究员试图了解大

在 AI 大模型竞赛中,Meta 选择重押视觉模型,并在推出零样本分割一切的 SAM 后,扎克伯格亲自官宣了重量级开源项目 DINOv2。据了解,DINOv2 是计算机视觉领域的预训练大模型,拥有 10 亿级参数量,采用 Transformer 架构,可在语义分割、图像检索和深度估计等方面实现自监督训练。无需微调,即可应用于多种下游任务,从而改善医学成像、粮食作物生长、地图绘制等领域。我们想象一下

参考:https://gitee.com/mindspore/mindformers/blob/dev/docs/model_cards/glm2.md#chatglm2-6b。
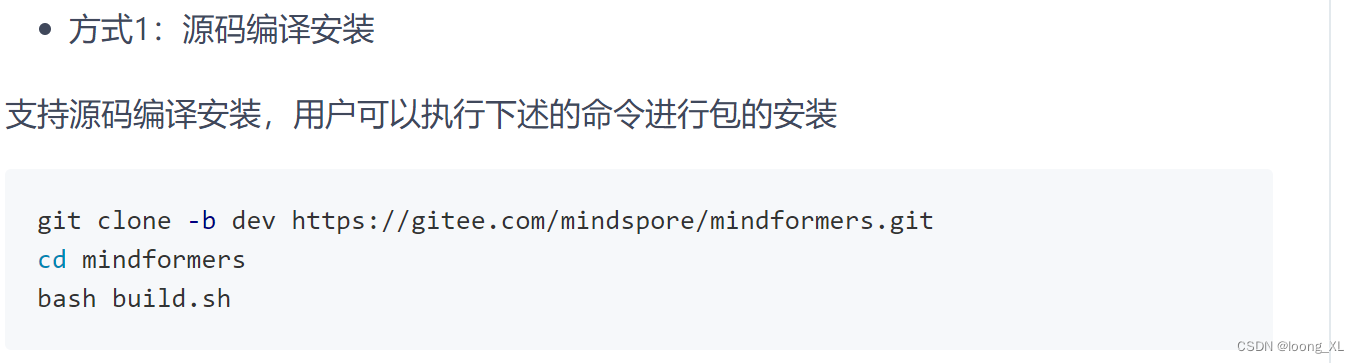
基于Langchain构建本地大型语言模型(LLM)问答系统的经验分享最近,我一直在探索如何利用Langchain来构建一个本地的大型语言模型问答系统。在这个过程中,我找到了一套源代码并进行了部署。以下是我在这个过程中的一些经验和笔记,希望对读者有所帮助。源代码已经上传,可以通过链接获取。

2023 年 12 月 06 日12 分钟阅读让人工智能为每个人提供更多帮助谷歌和 Alphabet 首席执行官谷歌 DeepMind 首席执行官兼联合创始人由谷歌 DeepMind 首席执行官兼联合创始人 Demis Hassabis 代表 Gemini 团队撰写和我的许多研究同事一样,人工智能一直是我毕生工作的重点。自从少年时代为电脑游戏编写人工智能程序,以及多年来作为神经科学研究员试图了解大
最近在研究如何使用langchain构造一个本地的大模型问答系统, 找了套源码部署,下面是一些经验, 以飨读者, 源码已经上传, 下面的是一些研究笔记和部署教程。
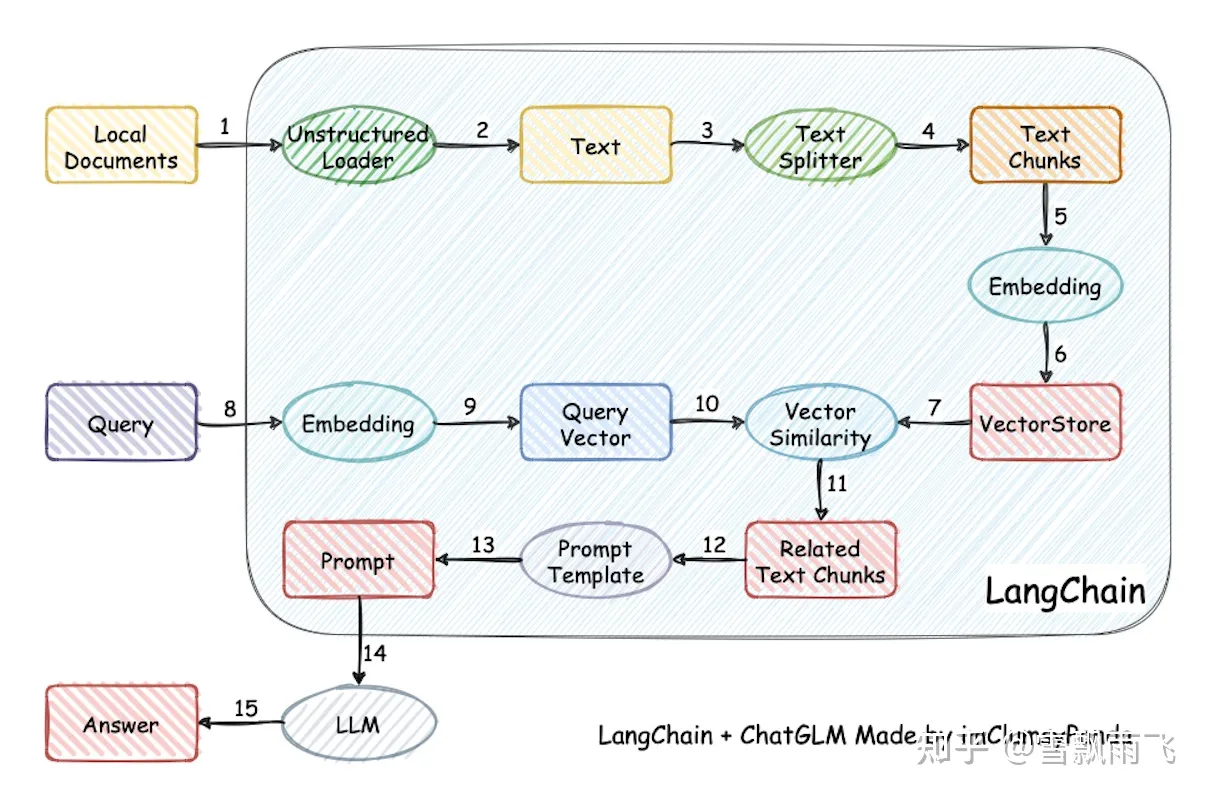
llama2-chat使用3w条高质量SFT数据,更小学习率,2epoch,user_prompt不计算loss。相比llama1,数据增加40%,长度增加一倍,使用了group-query attention。训练中logits值偏大,在推理时,对重复惩罚参数比较。损失使用的是binary ranking loss,使用了margin进一步优化。llama2-chat是在llama2基础版本的基
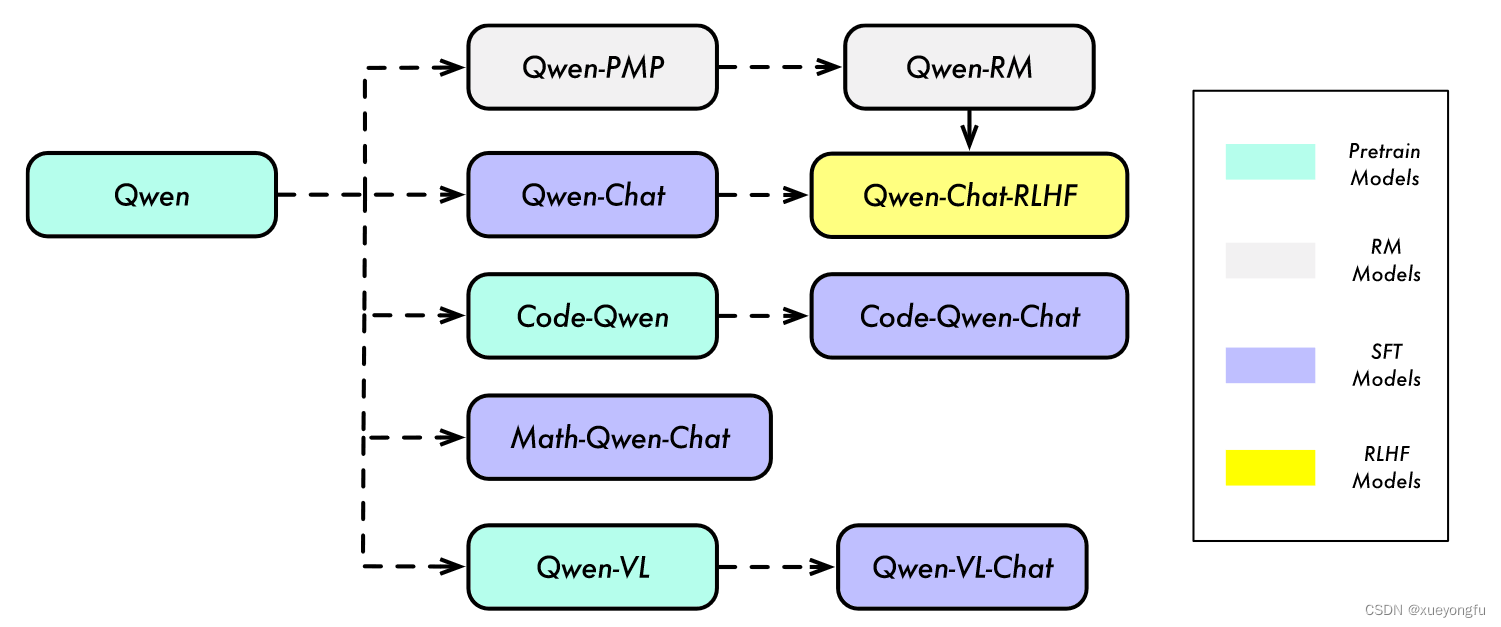
PyTorch训练模型流程图。
在 AI 大模型竞赛中,Meta 选择重押视觉模型,并在推出零样本分割一切的 SAM 后,扎克伯格亲自官宣了重量级开源项目 DINOv2。据了解,DINOv2 是计算机视觉领域的预训练大模型,拥有 10 亿级参数量,采用 Transformer 架构,可在语义分割、图像检索和深度估计等方面实现自监督训练。无需微调,即可应用于多种下游任务,从而改善医学成像、粮食作物生长、地图绘制等领域。我们想象一下
提示工程可以描述为一种艺术形式,为大型语言模型(LLMs)创建输入请求,以实现预期的输出。以下是创造单个或一系列提示的不同技巧。
