- @xiugtt6141121
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
oLink-Rag项目针对AI高速开发中的约束问题,提出了一套工程框架。核心挑战在于:当需求、代码、文档等均由大模型快速生成时,如何确保不偏离契约、不遗漏前提、不混淆临时与长期信息。解决方案包括:1)建立分层文档结构(docs/)管理长期知识,通过机器规则拦截关键契约漂移;2)使用.specs/目录管理开发期临时产物,采用spec-as-test流程将验收场景自动化;3)构建"契约层机器门禁+需求
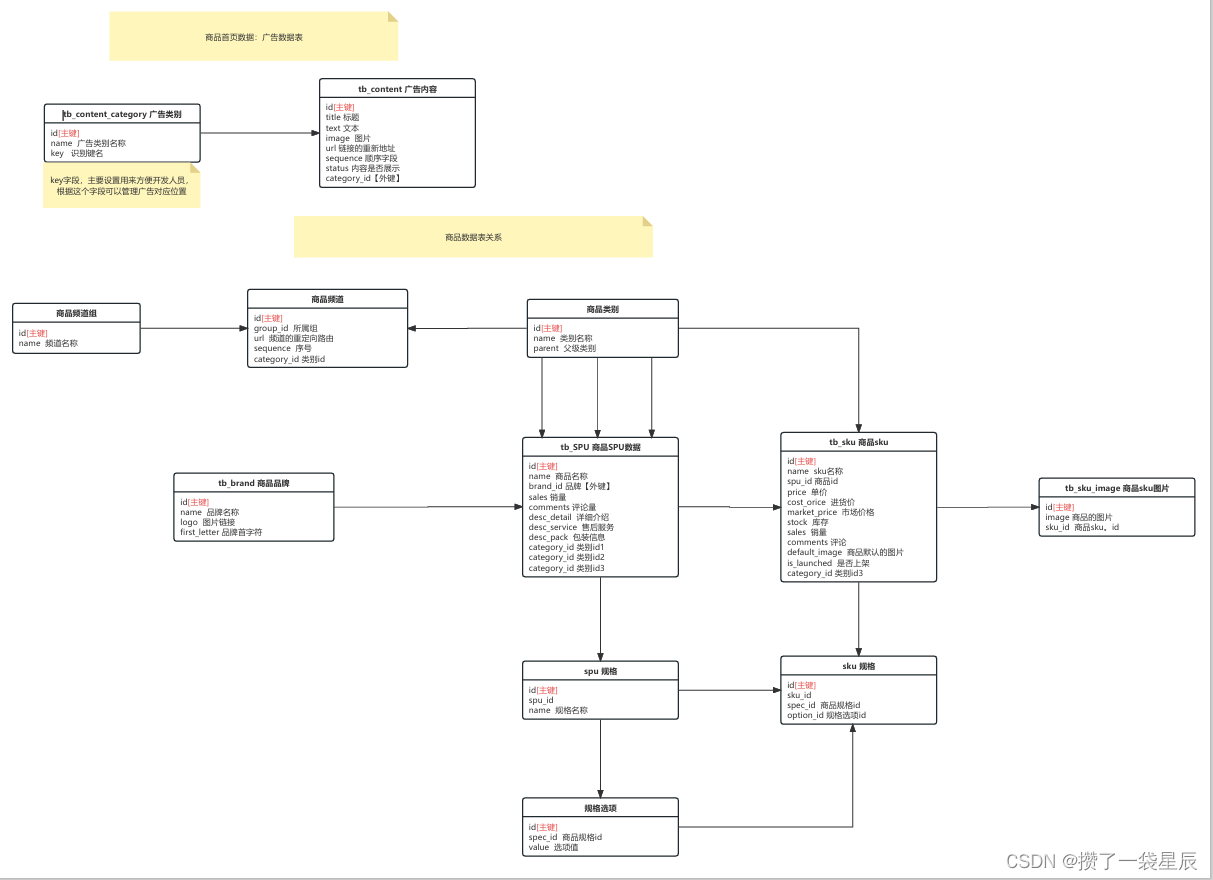
如上图所示 , 该表为商品表关系的示意图 , 气质我们要溥仪一个电视购物系统要用到的知识那就是SPU和SKU简单来说这两种就是不同的分类方式 , 我们在浏览淘宝等页面的时候也会遇见相同的情况如我们可以进行品牌的筛选 , 也可以进行商品价格的筛选 , 这些都是通过SPU和SKU相互关联组成的一个复杂的整体表关系实现的因为博主正在进行Django的项目开发所以这里直接使用Django的ORM框架进行展
在仓颉编程语言的设计理念中,与外部实体(如文件系统、网络、用户输入等)的数据交换活动被统称为I/O操作,其中“I”代表输入(Input),而“O”则代表输出(Output)。这些操作的核心在于数据流(Stream)的概念,数据流作为字节数据的连续序列,扮演着数据传输管道的角色。仓颉编程语言对I/O机制进行了高度的抽象,引入了输入流(InputStream)和输出流(OutputStream)的概念

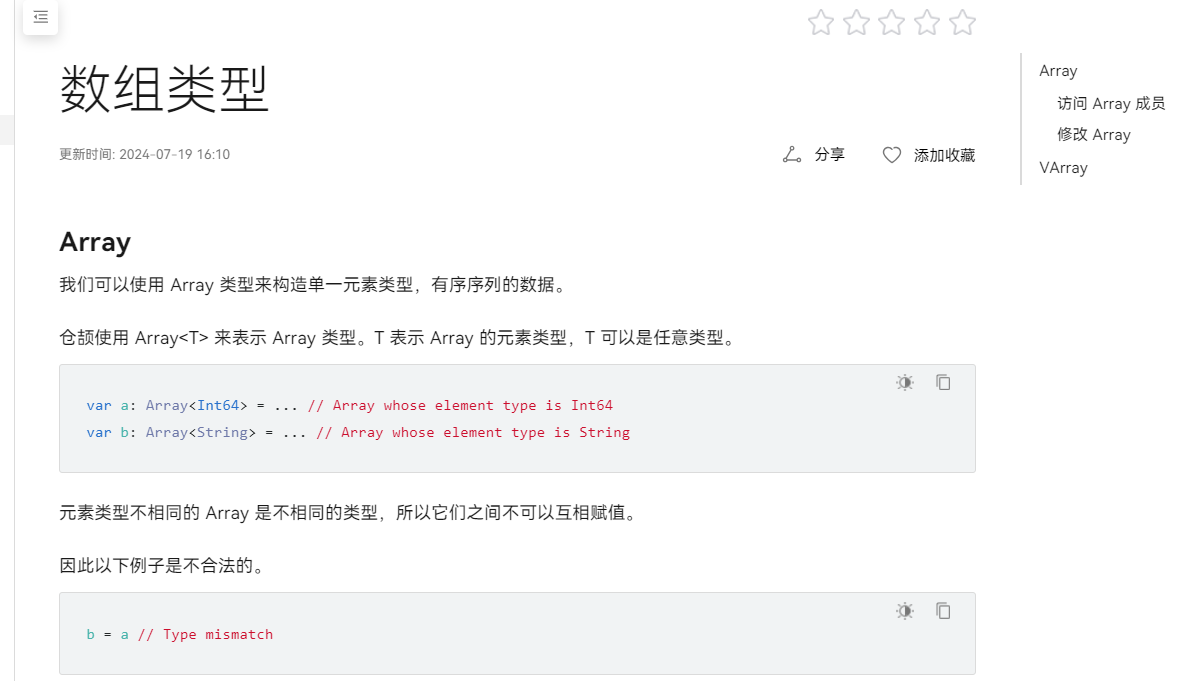
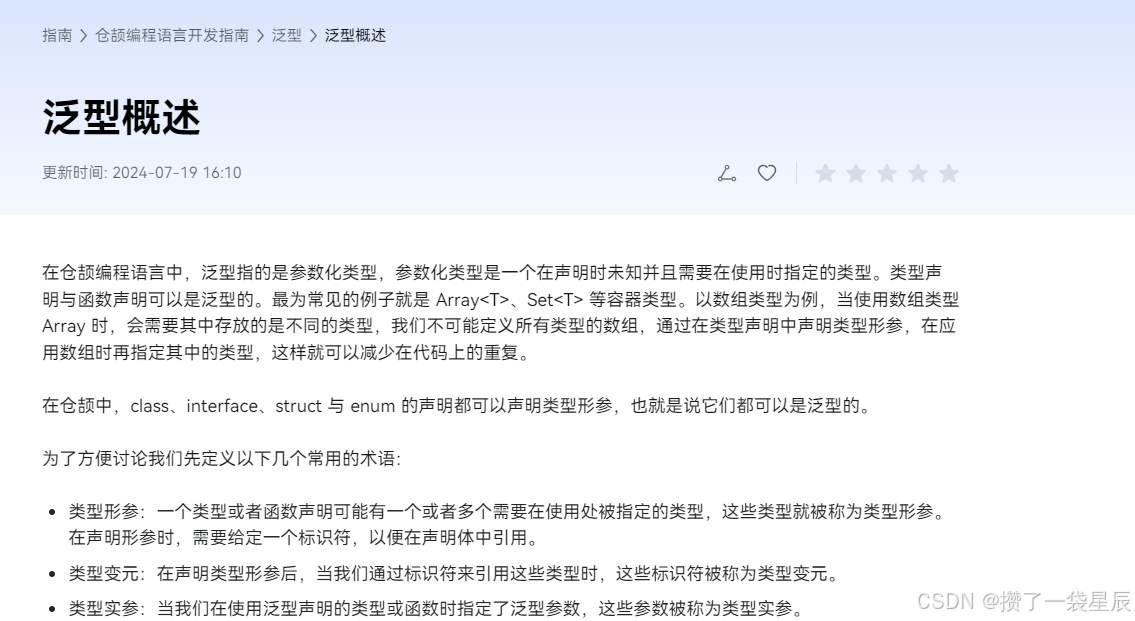
在仓颉编程语言中,泛型指的是参数化类型,参数化类型是一个在声明时未知并且需要在使用时指定的类型。类型声明与函数声明可以是泛型的。最为常见的例子就是 Array、Set 等容器类型。以数组类型为例,当使用数组类型 Array 时,会需要其中存放的是不同的类型,我们不可能定义所有类型的数组,通过在类型声明中声明类型形参,在应用数组时再指定其中的类型,这样就可以减少在代码上的重复。在仓颉中,class、
其中“条件”是布尔类型表达式,“分支 1”和“分支 2”是两个代码块。在一些场景中,我们可能只关注条件成立时该做些什么,所以 else 和对应的代码块是允许省略的在这段程序中,我们使用仓颉标准库的 random 包生成了一个随机整数,然后使用 if 表达式判断这个整数是否能被 2 整除,并在不同的条件分支中打印“偶数”或“奇数”。注意 : 仓颉编程语言是强类型的,

具体到实现上,我们首先定义一个class,然后可以通过new关键字创建该类的实例(即对象)。对象创建后,可以访问其公有成员(包括属性和方法),并进行相应的操作。如果类之间存在继承关系,子类可以重写继承自父类的虚方法,或者添加新的成员和方法。这种继承机制促进了代码的复用和扩展性。简而言之,class和struct在面向对象编程中各有其用,但class由于其支持引用传递和继承的特性,在构建复杂系统时更

摘要:针对10w用户表的标签更新与通知推送任务,提出分布式优化方案。采用批量读取+线程池处理减少RPC压力,通过熔断器(状态机机制)和指数退避重试应对服务故障。数据库更新使用批量事务保证一致性,结合Kafka实现异步通知解耦。关键设计包括:1)滑动窗口统计实现智能熔断;2)令牌桶算法进行客户端限流;3)Outbox模式确保消息可靠投递;4)bitmap防重机制。通过多级降级策略(旧数据回退/异步补

在仓颉编程语言的设计理念中,与外部实体(如文件系统、网络、用户输入等)的数据交换活动被统称为I/O操作,其中“I”代表输入(Input),而“O”则代表输出(Output)。这些操作的核心在于数据流(Stream)的概念,数据流作为字节数据的连续序列,扮演着数据传输管道的角色。仓颉编程语言对I/O机制进行了高度的抽象,引入了输入流(InputStream)和输出流(OutputStream)的概念
具体到实现上,我们首先定义一个class,然后可以通过new关键字创建该类的实例(即对象)。对象创建后,可以访问其公有成员(包括属性和方法),并进行相应的操作。如果类之间存在继承关系,子类可以重写继承自父类的虚方法,或者添加新的成员和方法。这种继承机制促进了代码的复用和扩展性。简而言之,class和struct在面向对象编程中各有其用,但class由于其支持引用传递和继承的特性,在构建复杂系统时更
本文详细介绍了仓颉数组的创建 , 获取与修改等方法可供大家参考