




- @xiaxianba
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
值得注意的是,根据总体的排行榜来看,其它的深度学习方法都被非神经网络方法超越。我们相信未来这一领域的研究,以及 GPU 算力和 RAM 容量的增长,将会使得深度学习算法胜过它们的传统竞争者,得到和人类艺术家相媲美的图像修复结果。然而我们强调,在目前最新的技术下,选择一个传统的图像或视频处理方法,也许会比盲目地只是因为新,而选择一个新的深度学习方法更好。虽然不规则的掩码是现实世界图像修复的典型特征,

操作系统是我们每天打开电脑的时候或者访问系统时候就接触到的,只不过由于我们没有认识到她的存在和作用,本文将从一个初学者的视角来讲解操作系统。一、操作系统什么是操作系统:管理计算机硬件与软件资源的计算机程序。操作系统有什么作用:负责设备、内存、文件、进程等资源的管理。操作系统的发展历史:单道批处理系统、多道批处理系统、分时操作系统、实时操作系统。操作系统有哪些类型:IBM OS/360、...
笔者之前写过一篇文章《工具:帆软FineReport使用指南》,是基于本地开发报表的一个基本使用指南,但实际情况是我们一般开发完报表之后,需要放到服务器上去,通过配置权限给不同的用户访问各自的报表信息,这个时候就需要掌握FineReport服务器的搭建和使用了。一、搭建服务器首先访问FineReport官网,按照官网说明配置FineReport服务器。官网配置是集成到Tomcat服务器中的。...
一、什么是大数据大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。IBM提出大数据的5V特点:Volume(大量)、V.
自从使用了Kettle工具之后,越来越发现她的强大,上篇文章主要介绍通过Kettle工具在传统数据库之间迁移数据,但很多业务场景是需要放到大数据上去的,如何通过Kettle工具把传统数据库中数据导入到Hive中,这是本文要详细讲解的。一、准备系统版本本地操作系统Windows 10 proETL工具Kettle 7.0.0数据库SQL Server 200...
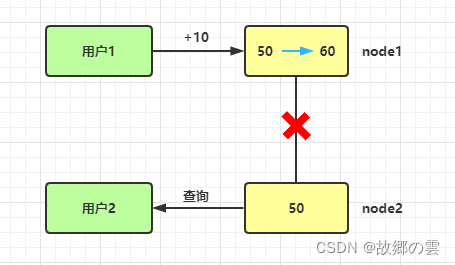
在分布式环境中,一致性是指数据在多个节点之间能够保持一致的特性。如果在某个节点上执行变更操作后,用户可以立即从其他任意节点上读取到变更后的数据,那么就认为这样的系统具备强一致性。可以性是指系统提供的服务必须一直处于可用状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。它主要强调以下两点:分区容错性指定是分布式系统在遇到网络分区时,仍需要能够对外提供一致性和可用性的服务,除非是整个网络环
随着前端开源框架越来越多,界面和可视化越来越人性化,功能也越来越强大,笔者由于要做大数据定制化项目,可视化解决方案采用的就是ECharts框架。一、安装部署版本,目前有是三个版本。完全版:echarts/dist/echarts.js常用版:echarts/dist/echarts.common.js精简版:echarts/dist/echarts.simple.js使用,echar...
华为是一家伟大的公司,不仅仅因为其本身伟大,同时还是很多伟大公司跟随的榜样。一、华为简介已经记不清人工智能还没出现的时候华为的愿景了,现在华为公司的**企业愿景–构建万物互联的智能世界。**印象中以前也是这个意思,所以说愿景是一脉相承的,可能随着世界形势变化会有不同的解释,这也是华为一直坚持和难容可贵的地方,很多企业的愿景不断变来变去,最后公司就变没了。组织和个人有很多地方是相通的,做企业和...
2015年有幸加入某大厂大数据项目,在此之前从没有接触过大数据这类高大上的技术,进入大厂之后才发现,原来大厂在做研究项目,也就是商业化前的可行性论证,也只有大厂会花这么多人力、物力做这个。当时物色了很多优秀的人才,有海龟博士、国内顶尖计算机专业硕士、资深大数据专家等等。但最终做了两年不到,项目最终被解散,回过头来总结经验,虽然时间隔得有点远,但很有必要。一、业务需求空间更小,速度更快当时做...
随着信息化时代的加深,国家人力资源和社会保障部新规定了13个新型职业,大数据工程技术人员赫然在列,下面我将从一个初学者的态度,搭建我们的大数据平台。系统和软件版本如下:软件相应版本操作系统CentOS 6.7JAVAJDK 1.8.0.131SCALASCALA 2.11.2HadoopHadoop 2.7.3SparkSpark 2.0.2...