




- @xiaoweite1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目前,本源量子计算系统包括了三种构造控制指令的方法,如下图所示,分别为可视化线路的设计、量子语言和量子软件开发套件QPanda,其中可视化编程和量子语言衣托在量子云平台上,用户在进行量子程序设计的时候可以相互转化:对于功能完整的QPanda,则使用c++为宿主语言开发的SDK,用户可以使用c++直接开发量子程序。从上述两例可以知道,用户只需要关注量子程序的构建,其他的部分,如量子虚拟机的构建、申请

对于一个非物理专业的人而言,量子力学概念晦涩难懂。鉴于此,本文仅介绍量子力学的一些基础概念加之部分数学的相关知识,甚至不涉及薛定谔方程,就足够开始量子计算机的应用。这如同不需去了解CPU的工作原理以及经典计算机的组成原理,但仍能在日常生活中使用经典计算机或者编写经典程序一样。在接下系列文章里,彻底抛却数学公式,纯粹去介绍宽泛的概念,目的仅仅想让读者都能了解这个问题——量子究竟是什么。如果不想被量子

当传统计算模式趋近瓶颈时,下一代计算模式的重大变革也即将来临。在不久的将来,量子计算可以改变世界已经成为了共识。一些大公司已经开始将量子计算研究视为一场竞赛。谷歌、IBM、英特尔和微软都在持续的扩大他们的量子计算研究团队,国内阿里、百度、本源量子等一批企业也在飞速成长中。要成为科技强国不是一代人的事,必须要有传承,这离不开量子信息人才的教育和培养。希望这个栏目能给大家科普关于量子计算的基础知识,能

因此,这个领域成为了量子计算研究的热门。绝大多数量子经典混合算法中都会存在一个类似于机器学习中的参数优化过程,其中,量子计算机处理一个包含多个参数的量子线路,并且对这些参数进行随机的初始化,量子计算机执行的结果会进一步被计算成一个损失函数,这个损失函数被输入到经典计算机的优化器中,从而修改这些参数,之后再通过量子计算机进行计算,如此循环,直到达到优化终止条件。虽然所有经典算法都可以在量子计算机上实

训练Tesseract大多数其他的验证码都是比较简单的。例如,流行的 PHP 内容管理系统 Drupal 有一个著 名的验证码模块(https://www.drupal.org/project/captcha),可以生成不同难度的验证码。那么与其他验证码相比,究竟是什么让这个验证码更容易被人类和机器读懂呢?字母没有相互叠加在一起,在水平方向上也没有彼此交叉。也就是说,可以在每...
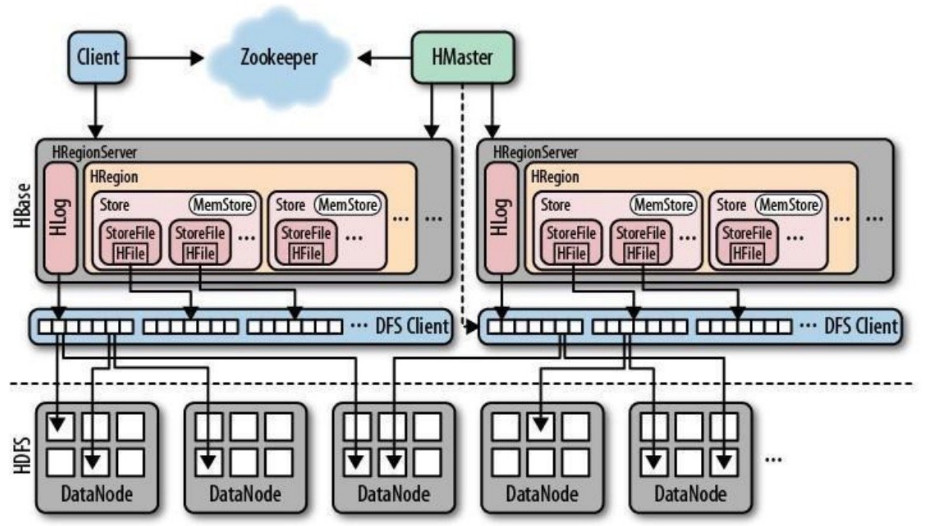
HBase是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式 NOSQL 数据库。当你需要随机、实时读/写访问大数据时,请使用 Apache HBase。
在该量子线路中,初始态q[1]、q[0]代表量子比特的初始态均为|0〉,因此该系统的复合量子态为|00〉,这里复合量子态|00〉的从左到右依次对应高位比特到低位比特。在真实的量子计算机上,最后要对量子系统末态进行测量操作,才能得到末态的信息,因此也把测量操作作为量子线路的一部分,测量操作有时也称为测量门。由于在真实的量子计算机上面,测量会对量子态有影响,所以只能够通过新制备初始量子态,让它重新演化

相同数量的量子比特对于不同的量子芯片结构,可执行两量子比特逻辑门的量子比持对可能完全不同。如果量子高级语言描述的量子程序中包含量子芯片不可直接执行的两量子比特逻辑门,量子程序编译器会根据量子芯片的连通性,利用交换门和可执行的两比特门的序列,取代量子程序中的两量子比特逻辑门。量子芯片提供的可直接执行的逻辑门是完备的,即可以表征所有的量子比特逻辑门,因此,如果量子高级语言描述的量子程序中包含了量子芯片

文章目录常见逻辑门以及含义一、Hadamard(H)门二、Pauli-X 门三、Pauli-Y 门四、Pauli-Z 门五、旋转门(rotation operators)1、RX(θ)门2、RY(θ)门3、RZ(θ)门六、多量子比特逻辑门七、CNOT 门八、CR 门九、iSWAP 门Hadamard门是一种可将基态变为叠加态的量子逻辑门,有时简称为H门。Hadamard门作用在单比特上,它将基态|

经典计算中,最基本的单元是比特,而最基本的控制模式是逻辑门,可以通过逻辑门的组合来达到控制电路的目的。类似地,处理量子比特的方式就是量子逻辑门,使用量子逻辑门,有意识的使量子态发生演化,所以量子逻辑门是构成量子算法的基础。
