




- @xiaojunjun200211
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在国产芯片运行GLM4-9B

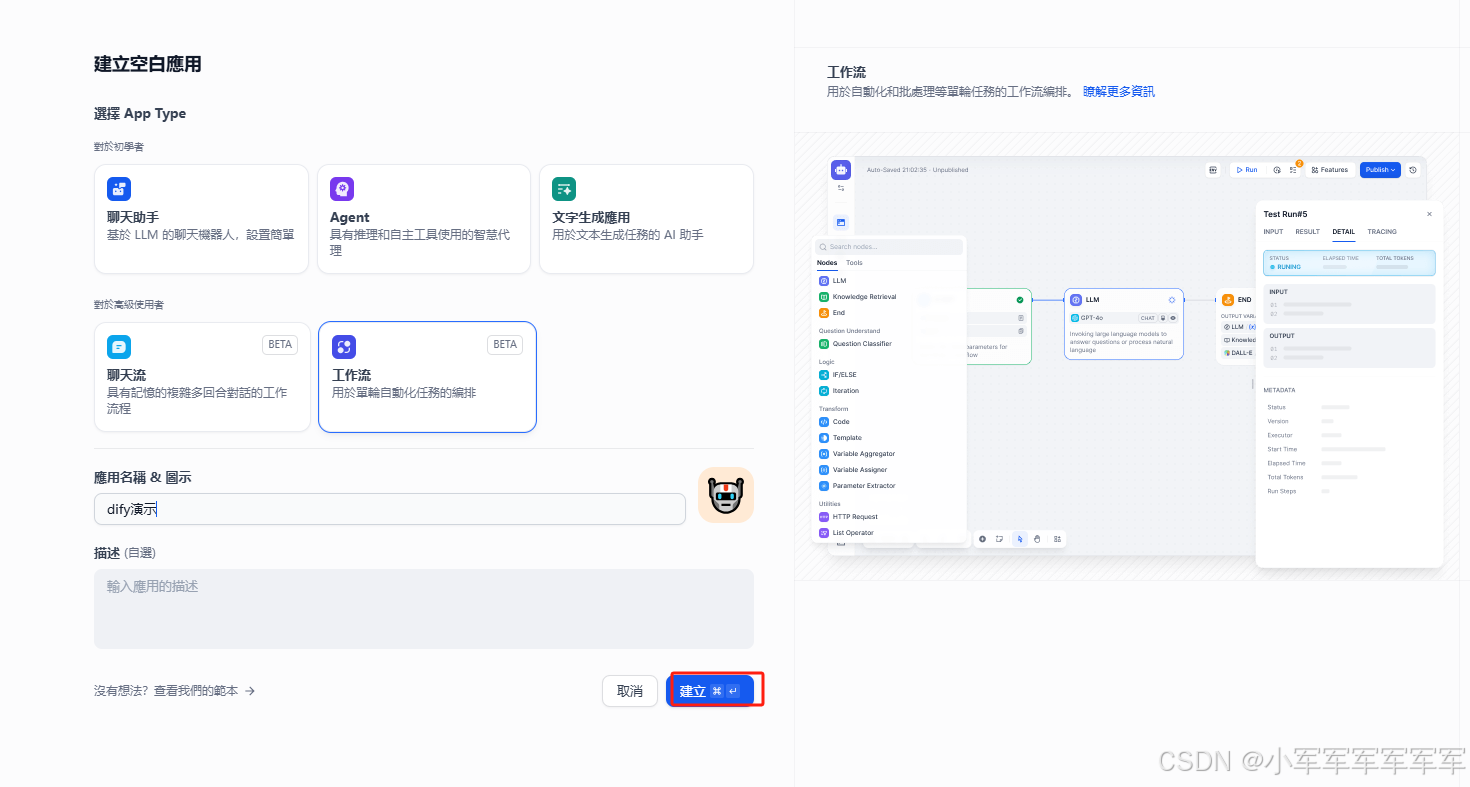
本章主要讲解如何用paas平台,实现智能体应用本章中大模型我们使用deepseek-R1-14B,当然QwQ也是可以使用的,根据您需要选择合适得模型智能体应用平台,直接调用dify,当然可以直接通过Github裸金属私有化部署也是ok得今日目标:用dify搭建一个workflow【上传文档->自动总结文档】
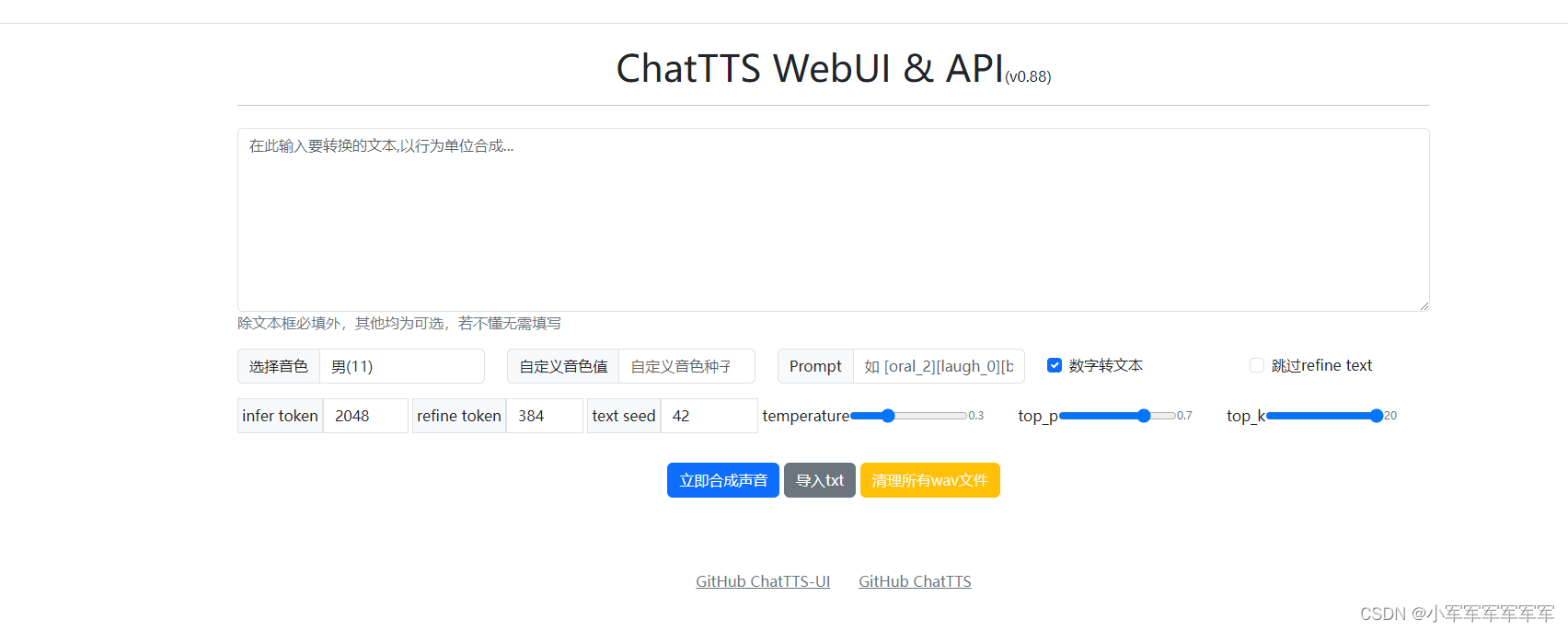
模型默认采用魔塔路径下载,这里不做模型下载教学。驱动选择:5.10.22及以上。镜像选择:pytorch2.1。MLU体验感拉满了简直。
在往后得部署手册中,即会讲到如何部署,也会讲到如何跑通,用370的可以跟着搞,不用370的也可以看下如何部署,在GPU也是通用的。
本章主要操作以yolov8为主,但是yolov10用该操作也能直接适用,开干!

海康威视调用,看了我的解决问题
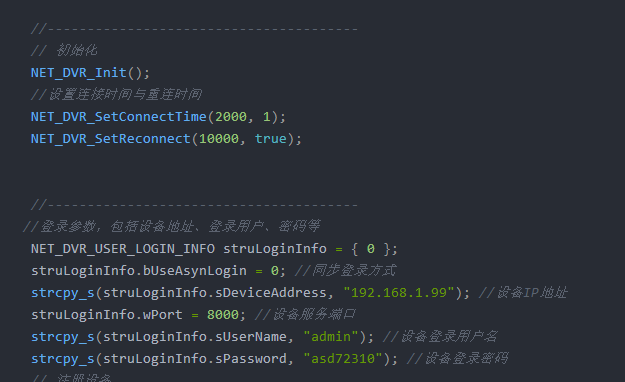
YOLOV5s 5.0 c++调用模型onnx(超精华)前展叙述概论新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出

模型默认采用魔塔路径下载,这里不做模型下载教学。驱动选择:5.10.22及以上。镜像选择:pytorch2.1。MLU体验感拉满了简直。
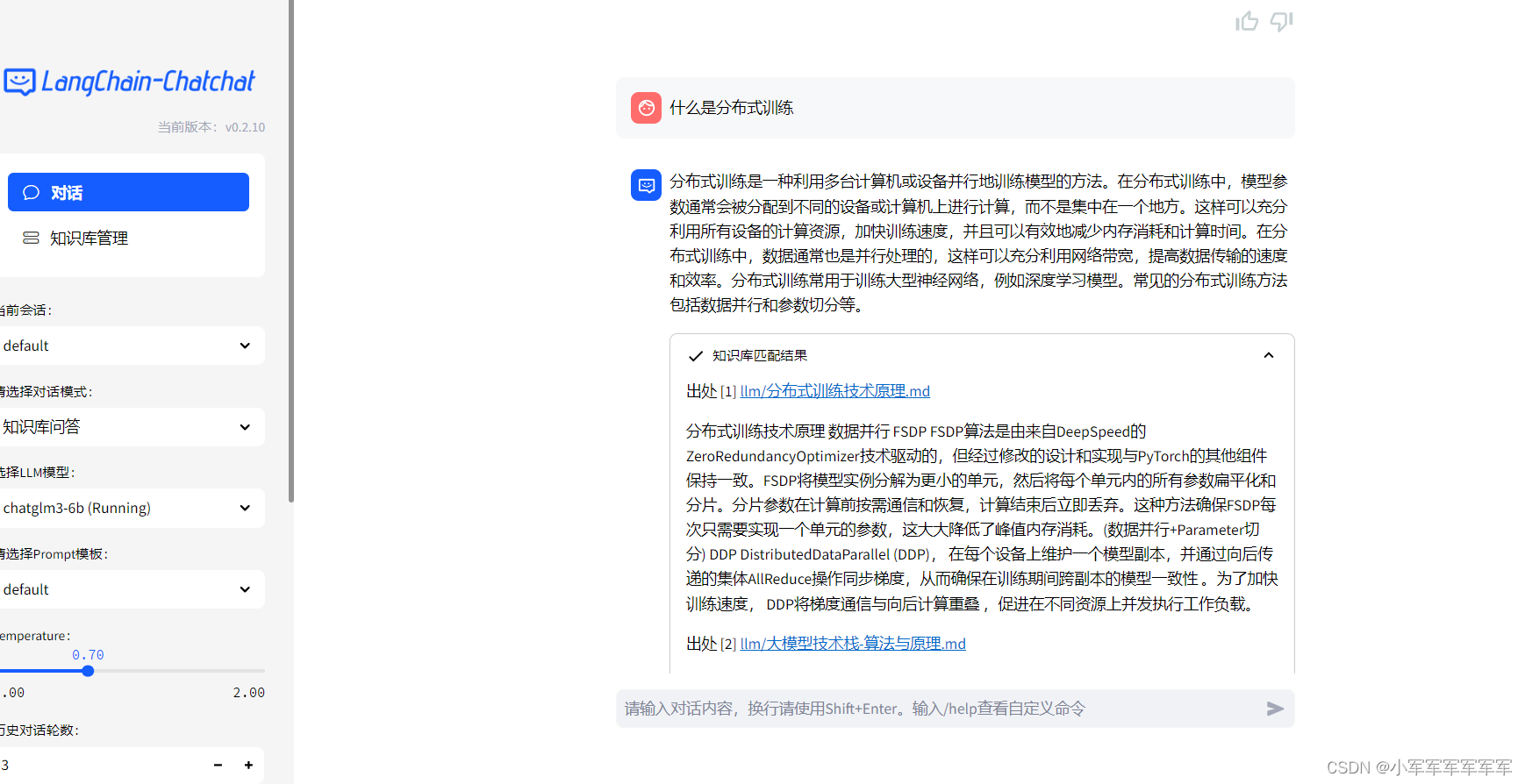
DeepSeek-R1拥有卓越的性能,在数学、代码和推理任务上可与OpenAI o1媲美。其采用的大规模强化学习技术,仅需少量标注数据即可显著提升模型性能,为大模型训练提供了新思路。此外,DeepSeek-R1构建了智能训练场,通过动态生成题目和实时验证解题过程等方式,提升模型推理能力。该模型完全开源,采用MIT许可协议,并开源了多个小型模型,进一步降低了AI应用门槛,赋能开源社区发展。

Llama 3.2-Vision多模态大型语言模型(LLM)集合是11B和90B大小(文本+图像输入/文本输出)的预训练和指令调优图像推理生成模型的集合。Llama 3.2-Vision指令调优模型针对视觉识别、图像推理、字幕和回答有关图像的一般问题进行了优化。在常见的行业基准上,这些模型的表现优于许多可用的开源和封闭式多模式模型。
