




- @xian_wwq
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了大语言模型推理优化中的「投机解码」(Speculative Decoding)技术,通过让小模型草拟候选token再由大模型验证的方式,实现单序列生成速度2-3倍提升且数学无损。文章分析了decode阶段的显存带宽瓶颈与GPU算力闲置问题,详细拆解了经典投机解码、Medusa、EAGLE和LookupDecoding四种变种的原理与适用场景,并给出vLLM框架的实践配置。

垂直大模型就是为了解决这三个痛点。但做不做、怎么做、做了值不值——这是一系列复杂的工程决策。

本文深入解析了Transformer架构及其在大模型时代的核心地位。文章首先回顾了RNN的局限性(无法并行、长程依赖丢失、状态压缩瓶颈),并指出2017年Transformer通过Self-Attention机制解决了这些问题,实现了完全并行计算和长序列直接关联。核心内容包括: 架构原理:详细拆解Self-Attention、多头注意力、位置编码(重点分析RoPE优势)和完整Transformer
本文深入解析了大模型参数量的工程意义及其实际影响。文章指出,参数量并非简单的数字,其背后涉及架构类型(Dense/MoE)、激活参数、数据精度等关键维度。通过拆解Transformer参数构成,推导出参数估算公式(以Llama-3-8B/70B为例验证),并对比了Dense与MoE模型的差异:MoE通过专家机制实现"大容量知识库+小计算量"的特性,但面临显存占用高、部署复杂等挑
本文系统分析了大模型全生命周期的成本构成与优化策略。文章指出,技术决策需转化为财务视角,强调总拥有成本(TCO)应包含硬件、人力、运维等全部支出,揭示常见误区如仅计算GPU单价、忽视利用率等。通过DeepSeek V3等案例,详细拆解训练成本(完整TCO可达狭义成本的10-20倍)和推理成本(自部署与API的临界点约800M tokens/月),并提出量化压缩、模型分级等优化方法。

本文是大模型技术系列的开篇,系统梳理了大模型从训练到部署的全景知识体系。文章首先指出当前工程师面临的技术选型困境——闭源与开源模型、推理框架、微调方法的爆炸式增长,强调了构建系统化工程视角的必要性。

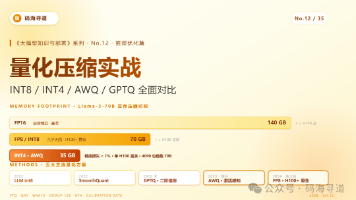
本文介绍了大模型部署中的量化技术,重点分析了其原理、方法及实践应用。量化通过将高精度权重压缩至低精度(如INT8/INT4),显著降低显存占用(最高达75%)、提升推理速度(30-150%)并减少能耗(40-60%)。文章对比了主流方案: INT8方案(LLM.int8/SmoothQuant)几乎无损,但性能提升有限; INT4方案(GPTQ/AWQ)通过校准数据和优化算法实现1%以内的精度损失
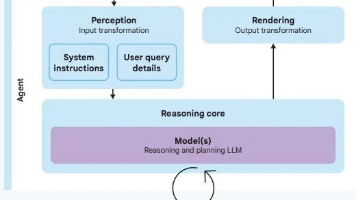
Google提出AIAgent安全框架,聚焦两大风险(异常行为与数据泄露),通过三大原则(人类控制、权限限制、行为可观测)与两层防御策略(确定性规则+AI推理防护)构建纵深防御体系。该方案结合传统安全机制与智能模型能力,在保障安全性的同时兼顾实用性,为AI代理的可靠应用提供系统化保障。
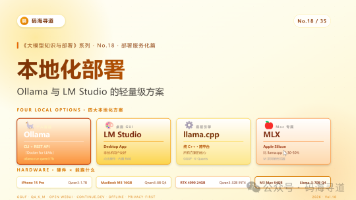
读完本文你将能:区分 4 大本地化方案的差异和适用场景;用 Ollama / LM Studio / llama.cpp 跑起本地模型;配置 VS Code / Cursor 用本地模型当 Copilot;在 Mac M 系列上充分利用 MLX 跑大模型;给小团队搭一个内网 LLM 服务。
本文介绍了大模型部署中的量化技术,重点分析了其原理、方法及实践应用。量化通过将高精度权重压缩至低精度(如INT8/INT4),显著降低显存占用(最高达75%)、提升推理速度(30-150%)并减少能耗(40-60%)。文章对比了主流方案: INT8方案(LLM.int8/SmoothQuant)几乎无损,但性能提升有限; INT4方案(GPTQ/AWQ)通过校准数据和优化算法实现1%以内的精度损失